2.3 KiB
Colossal-AI Overview
Author: Shenggui Li, Siqi Mai
About Colossal-AI
With the development of deep learning model size, it is important to shift to a new training paradigm. The traditional training method with no parallelism and optimization became a thing of the past and new training methods are the key to make training large-scale models efficient and cost-effective.
Colossal-AI is designed to be a unified system to provide an integrated set of training skills and utilities to the user. You can find the common training utilities such as mixed precision training and gradient accumulation. Besides, we provide an array of parallelism including data, tensor and pipeline parallelism. We optimize tensor parallelism with different multi-dimensional distributed matrix-matrix multiplication algorithm. We also provided different pipeline parallelism methods to allow the user to scale their model across nodes efficiently. More advanced features such as offloading can be found in this tutorial documentation in detail as well.
General Usage
We aim to make Colossal-AI easy to use and non-intrusive to user code. There is a simple general workflow if you want to use Colossal-AI.
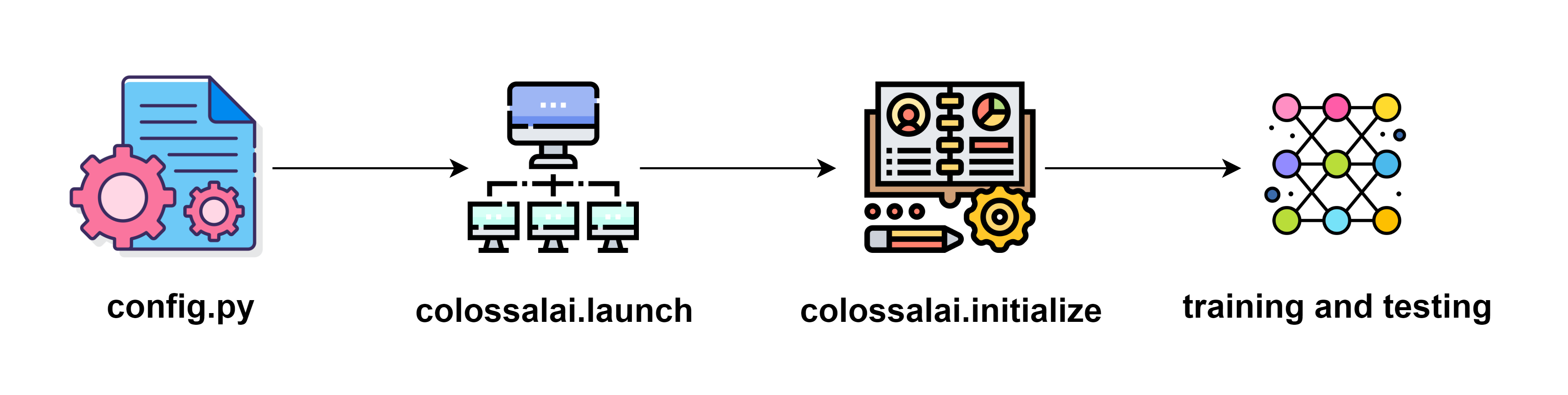
- Prepare a configuration file where specifies the features you want to use and your parameters.
- Initialize distributed backend with
colossalai.launch - Inject the training features into your training components (e.g. model, optimizer) with
colossalai.booster. - Run training and testing
We will cover the whole workflow in the basic tutorials section.
Future Development
The Colossal-AI system will be expanded to include more training skills, these new developments may include but are not limited to:
- optimization of distributed operations
- optimization of training on heterogenous system
- implementation of training utilities to reduce model size and speed up training while preserving model performance
- expansion of existing parallelism methods
We welcome ideas and contribution from the community and you can post your idea for future development in our forum.