mirror of https://github.com/hpcaitech/ColossalAI
2.0 KiB
2.0 KiB
NVMe offload
作者: Hongxin Liu
前置教程:
引言
如果模型具有N个参数,在使用 Adam 时,优化器状态具有8N个参数。对于十亿规模的模型,优化器状态至少需要 32 GB 内存。 GPU显存限制了我们可以训练的模型规模,这称为GPU显存墙。如果我们将优化器状态 offload 到磁盘,我们可以突破 GPU 内存墙。
我们实现了一个用户友好且高效的异步 Tensor I/O 库:TensorNVMe。有了这个库,我们可以简单地实现 NVMe offload。
该库与各种磁盘(HDD、SATA SSD 和 NVMe SSD)兼容。由于 HDD 或 SATA SSD 的 I/O 带宽较低,建议仅在 NVMe 磁盘上使用此库。
在优化参数时,我们可以将优化过程分为三个阶段:读取、计算和 offload。我们以流水线的方式执行优化过程,这可以重叠计算和 I/O。
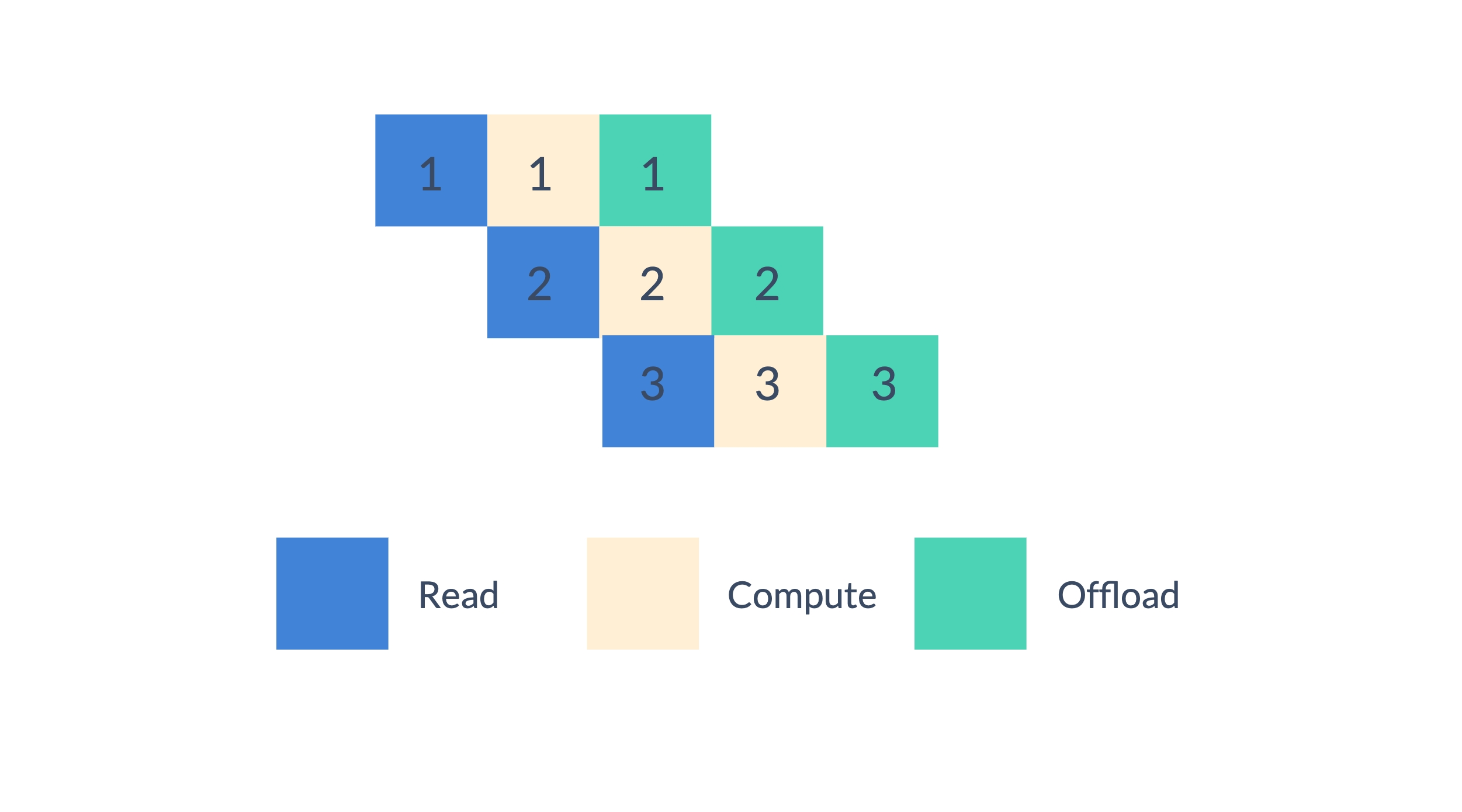
使用
首先,请确保您安装了 TensorNVMe:
pip install packaging
pip install tensornvme
我们为 Adam (CPUAdam 和 HybridAdam) 实现了优化器状态的 NVMe offload。
from colossalai.nn.optimizer import CPUAdam, HybridAdam
optimizer = HybridAdam(model.parameters(), lr=1e-3, nvme_offload_fraction=1.0, nvme_offload_dir='./')
nvme_offload_fraction 是要 offload 到 NVMe 的优化器状态的比例。 nvme_offload_dir 是保存 NVMe offload 文件的目录。如果 nvme_offload_dir 为 None,将使用随机临时目录。
它与 ColossalAI 中的所有并行方法兼容。