mirror of https://github.com/InternLM/InternLM
3.7 KiB
3.7 KiB
训练性能
InternLM 深度整合了 Flash-Attention, Apex 等高性能模型算子,提高了训练效率。通过构建 Hybrid Zero 技术,实现计算和通信的高效重叠,大幅降低了训练过程中的跨节点通信流量。InternLM 支持 7B 模型从 8 卡扩展到 1024 卡,千卡规模下加速效率可高达 90%,训练吞吐超过 180TFLOPS,平均单卡每秒处理的 token 数量超过3600。下表为 InternLM 在不同配置下的扩展性测试数据:
| InternLM | 8卡 | 16卡 | 32卡 | 64卡 | 128卡 | 256卡 | 512卡 | 1024卡 |
|---|---|---|---|---|---|---|---|---|
| TKS (Tokens/GPU/Second) | 4078 | 3939 | 3919 | 3944 | 3928 | 3920 | 3835 | 3625 |
| TFLOPS | 192 | 192 | 186 | 186 | 185 | 185 | 186 | 182 |
我们在GPU集群上测试了多种并行配置下,InternLM训练7B模型的性能。在每组测试中,每张GPU在单次迭代中处理的token数量一致。测试使用的硬件和参数配置如下表所示:
| 硬件 | 硬件型号 |
|---|---|
| GPU | nvidia_a100-sxm4-80gb |
| Memory | 2TB |
| Inter-machine bandwidth | 4 * 100Gb RoCE |
| CPU | 128 core Intel(R) Xeon(R) CPU |
| 超参 | tp=1 | tp=2 |
|---|---|---|
| micro_num | 4 | 4 |
| micro_bsz | 2 | 4 |
| seq_len | 2048 | 2048 |
InternLM中zero1的配置决定了优化器状态的分配范围。
zero1=-1表明优化器状态分布在全部数据并行节点(等同于Deepspeed Zero-1的效果)zero1=8,tp=1的情况下,优化器状态分布在单节点8张GPU内,并且不同节点上的优化器状态保持一致。
吞吐量测量
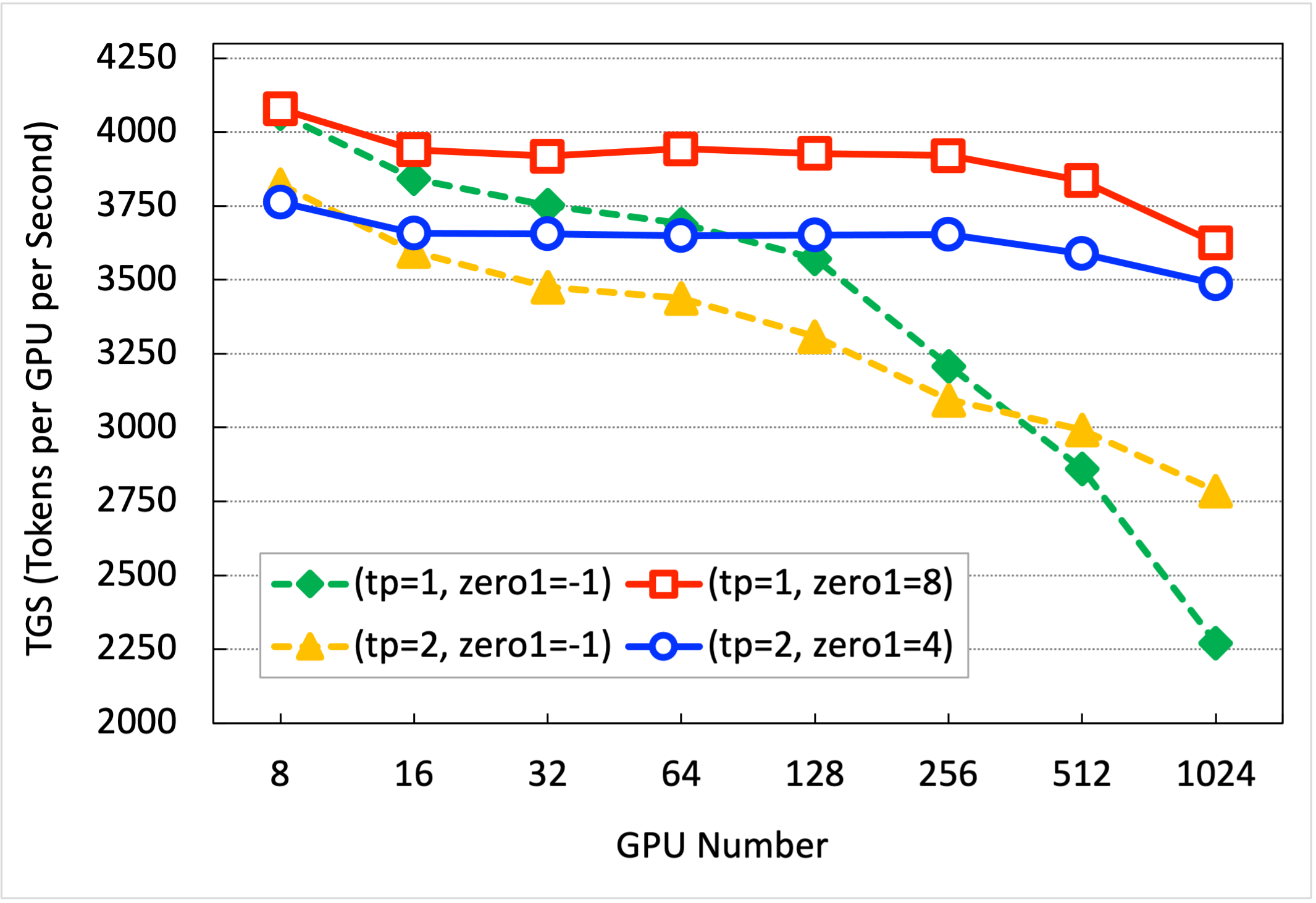
吞吐量定义为TGS,平均每GPU每秒处理的token的数量(Tokens per GPU per Second)。在该项测试的训练配置中,pack_sample_into_one=False,checkpoint=False。测试结果如下表所示。采用zero1=8,tp=1,InternLM针对7B模型训练的扩展性,在千卡训练的加速效率可以达到88%。
| 并行配置 | 8卡 | 16卡 | 32卡 | 64卡 | 128卡 | 256卡 | 512卡 | 1024卡 |
|---|---|---|---|---|---|---|---|---|
| (tp=1, zero1=-1) | 4062 | 3842 | 3752 | 3690 | 3571 | 3209 | 2861 | 2271 |
| (tp=1, zero1=8) | 4078 | 3939 | 3919 | 3944 | 3928 | 3920 | 3835 | 3625 |
| (tp=2, zero1=-1) | 3822 | 3595 | 3475 | 3438 | 3308 | 3094 | 2992 | 2785 |
| (tp=2, zero1=4) | 3761 | 3658 | 3655 | 3650 | 3651 | 3653 | 3589 | 3486 |
FLOPS测试
模型训练的计算量参考 Megatron 论文中FLOPS计算方式。为了保证训练过程中的FLOPS恒定,在该项测试的训练配置中,pack_sample_into_one=True,其余超参设置如下所示:
| activation checkpoint | tp | zero-1 | seq_len | micro_num | micro_bsz |
|---|---|---|---|---|---|
| 关闭 | 1 | 8 | 2048 | 4 | 2 |
| 开启 | 1 | 8 | 2048 | 1 | 8 |
测试结果如下表所示,InternLM针对7B模型的千卡训练,可以达到 >180 TFLOPS:
| activation checkpoint | 8卡 | 16卡 | 32卡 | 64卡 | 128卡 | 256卡 | 512卡 | 1024卡 |
|---|---|---|---|---|---|---|---|---|
| 关闭 | 183 | 177 | 176 | 174 | 173 | 173 | 173 | 160 |
| 开启 | 192 | 192 | 186 | 186 | 185 | 185 | 186 | 182 |
