14 KiB
Pre-training and Fine-tuning Tutorial for InternLM
To start a demo model training, you need to prepare three things: installation, dataset preparation, and model training configuration. In this guide, we will first cover the steps for dataset preparation and then briefly describe the model training configuration.
Installation
Please refer to the installation guide for instructions on how to install the necessary dependencies.
Dataset Preparation (Pre-training)
The dataset for InternLM training consists of a series of bin and meta files. To generate the training dataset, you need to use the tokenizer tool to tokenize the raw text data. The tokenizer model can be imported by specifying the model path in the tools/tokenizer.py script. The current provided model is V7.model. If you want to use a different model, you can modify the model path directly in the tokenizer.py script.
You can generate the bin and meta files for your raw data by running the following command, where the raw_data_name parameter represents the name of your raw data file, input_file_type represents the format of your raw data file (currently supports txt, json, and jsonl), and bin represents the path to save the generated bin files.
$ python tools/tokenizer.py --raw_data_name your_raw_data_file_name(without suffix) --input_file_type 'txt' or 'json' or 'jsonl' --bin your_output_bin_path
Here is an example of data processing (only the data processing example for the txt format is provided here, the data processing process for json and jsonl is exactly the same as for txt):
Given a file raw_data.txt containing the raw dataset, the raw dataset is shown below:
Appreciate every detail in life to truly taste the flavor of happiness.
Dreams are the source of life’s motivation. Pursue them diligently to achieve your goals.
Learn to be tolerant and understanding to establish truly harmonious interpersonal relationships.
You can generate the bin and meta files by running the following command:
$ python tools/tokenizer.py --raw_data_name raw_data --input_file_type 'text' --bin cn/output.bin
It should be noted that the generated bin files need to be saved in one of the following directories: cn, en, code, ja, ar, or kaoshi, depending on the type of dataset.
Here, cn represents the Chinese dataset, en represents the English dataset, code represents the code dataset, ja represents the Japanese dataset, ar represents the Arabic dataset, and kaoshi represents the exam dataset.
The format of the generated bin files is as follows:
{"tokens": [98655, 2317, 2922, 6649, 1595, 7856, 435, 2424, 442, 9556, 12807, 410, 17313, 446, 23331, 95746]}
{"tokens": [98655, 302, 1383, 269, 657, 410, 2687, 446, 2424, 98667, 269, 25220, 281, 523, 1874, 492, 1248, 38127, 4563, 442, 11227, 829, 8980, 95746]}
{"tokens": [98655, 24190, 442, 517, 15013, 649, 454, 8793, 442, 5849, 9556, 17917, 1369, 1084, 29890, 12021, 95746]}
Each line in the bin file corresponds to each sentence in the original dataset, representing the tokens of each sentence (referred to as sequence below).
The format of the generated meta file is as follows:
(0, 16), (110, 24), (262, 17)
Each tuple in the meta file represents the meta information of each sequence, where the first element in the tuple indicates the starting index of each sequence among all sequences, and the second element indicates the number of tokens for each sequence.
For example, the first sequence starts at index 0 and has 16 tokens. The second sequence starts at index 110 and has 24 tokens.
The bin and meta file formats for json and jsonl type files are the same as for txt, so we won't go over them here.
Data Preparation (Fine-tuning)
The data format for fine-tuning tasks is the same as for pre-training tasks, which consists of a series of bin and meta files. Let's take the Alpaca dataset as an example to explain the data preparation process for fine-tuning.
-
Download the Alpaca dataset.
-
Tokenize the Alpaca dataset using the following command:
python tools/alpaca_tokenizer.py /path/to/alpaca_dataset /path/to/output_dataset /path/to/tokenizer --split_ratio 0.1
It is recommended that users refer to alpaca_tokenizer.py to write new scripts to tokenize their own datasets
Training Configuration
Taking the configuration file configs/7B_sft.py for the 7B demo as an example, let's discuss the data, model, and parallel configurations required to start a model training.
Data Configuration
Here are the key parameters and their explanations for data configuration:
TRAIN_FOLDER = "/path/to/dataset"
SEQ_LEN = 2048
data = dict(
seq_len=SEQ_LEN, # Length of the data samples, default value is 2048
micro_num=1, # Number of micro_batches processed in one model parameter update, default value is 1
micro_bsz=1, # Packed_length = micro_bsz * SEQ_LEN, the size of data processed in one micro_batch, default value is 1
total_steps=50000, # Total number of steps to be executed, default value is 50000
min_length=50, # If the number of lines in the dataset file is less than 50, it will be discarded
train_folder=TRAIN_FOLDER, # Dataset file path, default value is None; if train_folder is empty, training will be done using randomly generated datasets
pack_sample_into_one=False, # Logic for data arrangement, determines whether to calculate attention based on the seq_len dimension or the actual length of the sequence
)
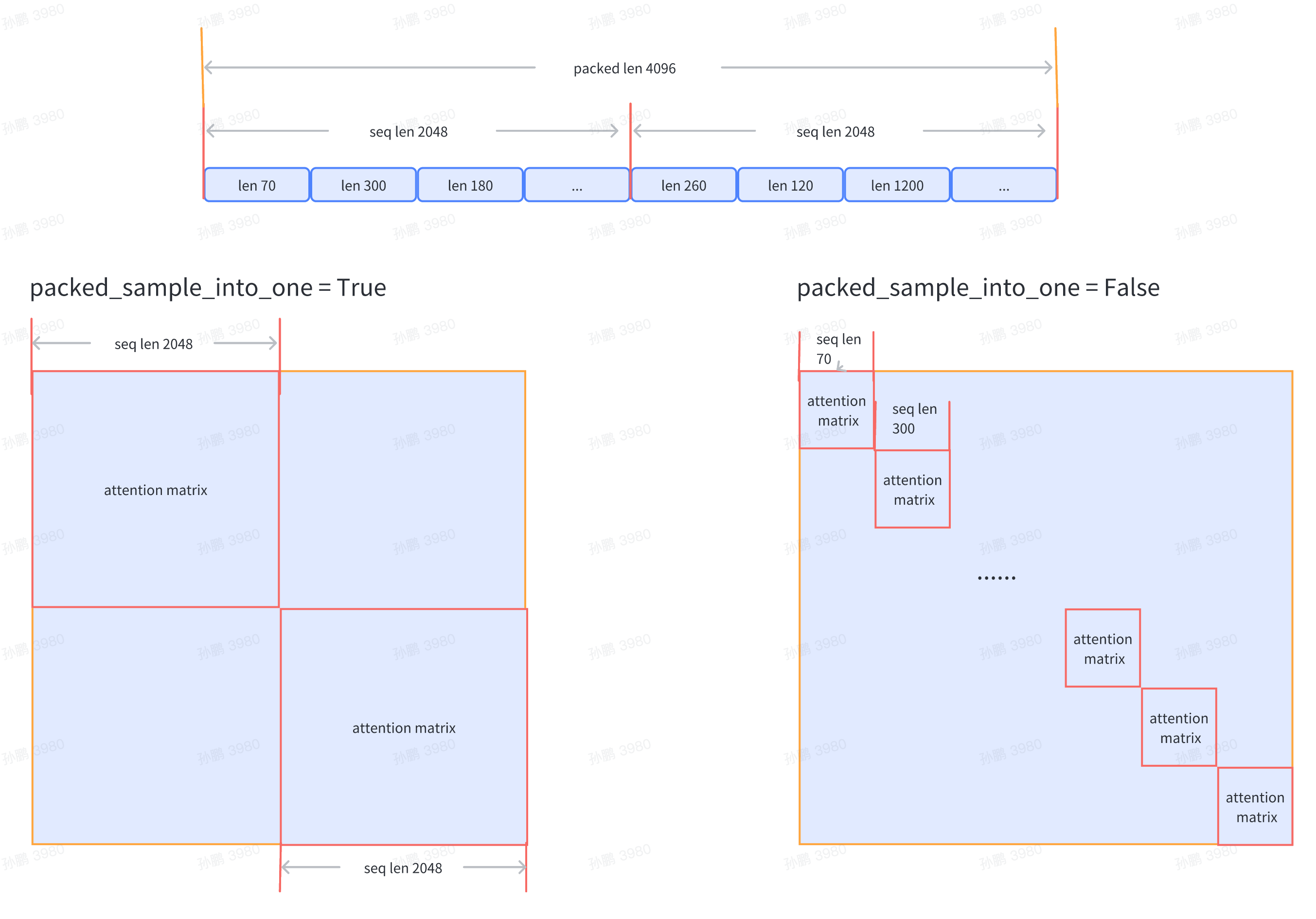
Currently, it supports passing the dataset file path train_folder, and the file format is required to be as follows:
- folder
- code
train_000.bin
train_000.bin.meta
For detailed information about the dataset, please refer to the "Data Preparation" section.
Model Configuration
If you want to load a model checkpoint when starting the training, you can configure it as follows:
SAVE_CKPT_FOLDER = "local:/path/to/save/ckpt"
MODEL_ONLY_FOLDER = "local:/path/to/load/init/model/ckpt"
LOAD_CKPT_FOLDER = "local:/path/to/load/resume/ckpt"
ckpt = dict(
save_ckpt_folder=SAVE_CKPT_FOLDER, # Path to save the model and optimizer checkpoints
checkpoint_every=float("inf"), # Save a checkpoint every specified number of steps, default value is inf
load_model_only_folder=MODEL_ONLY_FOLDER, # Path to load the initial model weights, only load model weights without loading optimizer weights, training will start from the first step
load_ckpt_folder=LOAD_CKPT_FOLDER, # Path to load the weights of the model and optimizer for resuming training, training will resume from the specified step
load_optimizer=True, # Whether to load optimizer weights when resuming training, default value is True
)
Note:
load_model_only_folderandload_ckpt_foldercannot be set at the same time.- If the path starts with
local:, it means the file is stored in the local file system. If it starts withboto3:, it means the file is stored in the remote OSS.
The configuration for the model is as follows:
model_type = "INTERNLM" # Model type, default value is "INTERNLM", corresponding to the model structure initialization interface function
NUM_ATTENTION_HEAD = 32
VOCAB_SIZE = 103168
HIDDEN_SIZE = 4096
NUM_LAYER = 32
MLP_RATIO = 8 / 3
model = dict(
checkpoint=False,
num_attention_heads=NUM_ATTENTION_HEAD,
embed_split_hidden=True,
vocab_size=VOCAB_SIZE,
embed_grad_scale=1,
parallel_output=True,
hidden_size=HIDDEN_SIZE,
num_layers=NUM_LAYER,
mlp_ratio=MLP_RATIO,
apply_post_layer_norm=False,
dtype="torch.bfloat16",
norm_type="rmsnorm",
layer_norm_epsilon=1e-5,
)
Note: Users can customize the model type name and model structure, and configure the corresponding model parameters. The model initialization function interface can be registered through the MODEL_INITIALIZER object in utils/registry.py. When initializing the model in the training main function train.py, the specified model initialization interface function can be obtained through the model_type configuration.
Parallel Configuration
Training parallel configuration example:
parallel = dict(
zero1=8,
pipeline=1,
tensor=1,
)
- zero1: zero parallel strategy, divided into the following three cases, default value is -1
- When
size <= 0, the size of the zero1 process group is equal to the size of the data parallel process group, so the optimizer state parameters will be split within the data parallel range. - When
size == 1, zero1 is not used, and all data parallel groups retain the complete optimizer state parameters. - When
size > 1andsize <= data_parallel_world_size, the zero1 process group is a subset of the data parallel process group.
- When
- pipeline: pipeline parallel size, currently only supports 1, default value is 1
- tensor: tensor parallel size, usually the number of GPUs per node, default value is 1
Note: Data parallel size = Total number of GPUs / Pipeline parallel size / Tensor parallel size
Start Training
After completing the data preparation and relevant training configurations mentioned above, you can start the demo training. The following examples demonstrate how to start the training in both slurm and torch environments.
If you want to start distributed training on slurm with 16 GPUs across multiple nodes, use the following command:
$ srun -p internllm -N 2 -n 16 --ntasks-per-node=8 --gpus-per-task=1 python train.py --config ./configs/7B_sft.py
If you want to start distributed training on torch with 8 GPUs on a single node, use the following command:
$ torchrun --nnodes=1 --nproc_per_node=8 train.py --config ./configs/7B_sft.py
Training Results
Taking the configuration of the demo training on a single machine with 8 GPUs on slurm as an example, the training result log is shown below:
2023-07-07 12:26:58,293 INFO launch.py:228 in launch -- Distributed environment is initialized, data parallel size: 8, pipeline parallel size: 1, tensor parallel size: 1
2023-07-07 12:26:58,293 INFO parallel_context.py:535 in set_seed -- initialized seed on rank 2, numpy: 1024, python random: 1024, ParallelMode.DATA: 1024, ParallelMode.TENSOR: 1024,the default parallel seed is ParallelMode.DATA.
2023-07-07 12:26:58,295 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=0===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=5===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=1===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=6===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=7===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=2===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=4===========
2023-07-07 12:26:58,296 INFO train.py:378 in main -- ===========New Run Jul07_12-26-58 on host:SH-IDC1-10-140-0-135,tp:0,pp=0,dp=3===========
2023-07-07 12:28:27,826 INFO hybrid_zero_optim.py:295 in _partition_param_list -- Number of elements on ranks: [907415552, 907411456, 910163968, 910163968, 921698304, 921698304, 921698304, 921698304], rank:0
2023-07-07 12:28:57,802 INFO train.py:323 in record_current_batch_training_metrics -- tflops=63.27010355651958,step=0,loss=11.634403228759766,tgs (tokens/gpu/second)=1424.64,lr=4.0000000000000003e-07,loss_scale=65536.0,grad_norm=63.672620777841004,micro_num=4,num_consumed_tokens=131072,inf_nan_skip_batches=0,num_samples_in_batch=19,largest_length=2048,largest_batch=5,smallest_batch=4,adam_beta2=0.95,fwd_bwd_time=6.48
2023-07-07 12:29:01,636 INFO train.py:323 in record_current_batch_training_metrics -- tflops=189.83371103277346,step=1,loss=11.613704681396484,tgs (tokens/gpu/second)=4274.45,lr=6.000000000000001e-07,loss_scale=65536.0,grad_norm=65.150786641452,micro_num=4,num_consumed_tokens=262144,inf_nan_skip_batches=0,num_samples_in_batch=16,largest_length=2048,largest_batch=5,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.67
2023-07-07 12:29:05,451 INFO train.py:323 in record_current_batch_training_metrics -- tflops=190.99928472960033,step=2,loss=11.490386962890625,tgs (tokens/gpu/second)=4300.69,lr=8.000000000000001e-07,loss_scale=65536.0,grad_norm=61.57798028719357,micro_num=4,num_consumed_tokens=393216,inf_nan_skip_batches=0,num_samples_in_batch=14,largest_length=2048,largest_batch=4,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.66
2023-07-07 12:29:09,307 INFO train.py:323 in record_current_batch_training_metrics -- tflops=188.8613541410694,step=3,loss=11.099515914916992,tgs (tokens/gpu/second)=4252.55,lr=1.0000000000000002e-06,loss_scale=65536.0,grad_norm=63.5478796484391,micro_num=4,num_consumed_tokens=524288,inf_nan_skip_batches=0,num_samples_in_batch=16,largest_length=2048,largest_batch=5,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.7
2023-07-07 12:29:13,147 INFO train.py:323 in record_current_batch_training_metrics -- tflops=189.65918563194305,step=4,loss=10.149517059326172,tgs (tokens/gpu/second)=4270.52,lr=1.2000000000000002e-06,loss_scale=65536.0,grad_norm=51.582841631508145,micro_num=4,num_consumed_tokens=655360,inf_nan_skip_batches=0,num_samples_in_batch=19,largest_length=2048,largest_batch=6,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.68
2023-07-07 12:29:16,994 INFO train.py:323 in record_current_batch_training_metrics -- tflops=189.3109313713174,step=5,loss=9.822169303894043,tgs (tokens/gpu/second)=4262.67,lr=1.4000000000000001e-06,loss_scale=65536.0,grad_norm=47.10386835560855,micro_num=4,num_consumed_tokens=786432,inf_nan_skip_batches=0,num_samples_in_batch=17,largest_length=2048,largest_batch=6,smallest_batch=3,adam_beta2=0.95,fwd_bwd_time=3.69