9.3 KiB
Auto Mixed Precision Training (Latest)
Author: Mingyan Jiang
Prerequisite
Related Paper
Introduction
AMP stands for automatic mixed precision training. In Colossal-AI, we have incorporated different implementations of mixed precision training:
- torch.cuda.amp
- apex.amp
- naive amp
| Colossal-AI | support tensor parallel | support pipeline parallel | fp16 extent |
|---|---|---|---|
| AMP_TYPE.TORCH | ✅ | ❌ | Model parameters, activation, gradients are downcast to fp16 during forward and backward propagation |
| AMP_TYPE.APEX | ❌ | ❌ | More fine-grained, we can choose opt_level O0, O1, O2, O3 |
| AMP_TYPE.NAIVE | ✅ | ✅ | Model parameters, forward and backward operations are all downcast to fp16 |
The first two rely on the original implementation of PyTorch (version 1.6 and above) and NVIDIA Apex. The last method is similar to Apex O2 level. Among these methods, apex AMP is not compatible with tensor parallelism. This is because that tensors are split across devices in tensor parallelism, thus, it is required to communicate among different processes to check if inf or nan occurs in the whole model weights. We modified the torch amp implementation so that it is compatible with tensor parallelism now.
❌️ fp16 and zero are not compatible
⚠️ Pipeline only support naive AMP currently
We recommend you to use torch AMP as it generally gives better accuracy than naive AMP if no pipeline is used.
Table of Contents
In this tutorial we will cover:
AMP Introduction
Automatic Mixed Precision training is a mixture of FP16 and FP32 training.
Half-precision float point format (FP16) has lower arithmetic complexity and higher compute efficiency. Besides, fp16 requires half of the storage needed by fp32 and saves memory & network bandwidth, which makes more memory available for large batch size and model size.
However, there are other operations, like reductions, which require the dynamic range of fp32 to avoid numeric overflow/underflow. That's the reason why we introduce automatic mixed precision, attempting to match each operation to its appropriate data type, which can reduce the memory footprint and augment training efficiency.
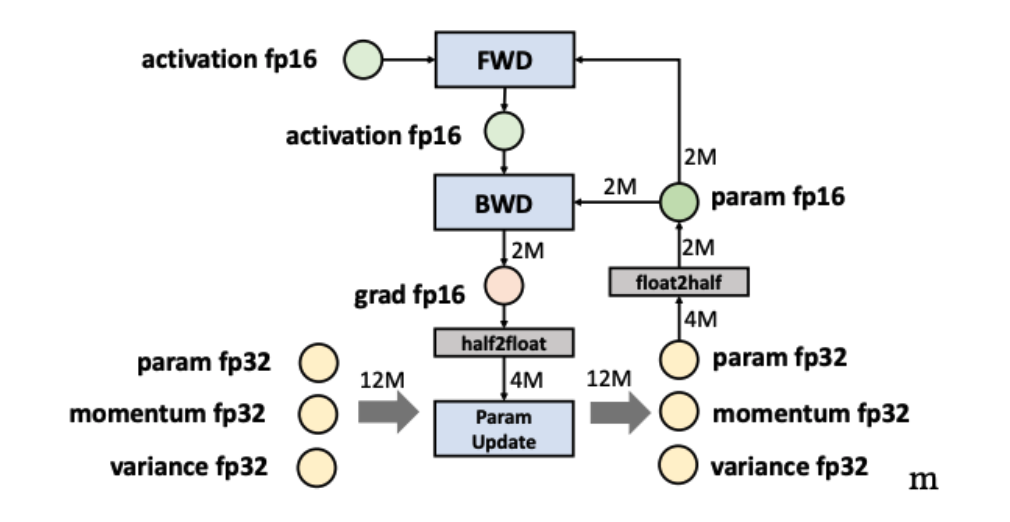
AMP in Colossal-AI
We supported three AMP training methods and allowed the user to train with AMP with no code. If you want to train with amp, just assign mixed_precision with fp16 when you instantiate the Booster. Now booster support torch amp, the other two(apex amp, naive amp) are still started by colossalai.initialize, if needed, please refer to this. Next we will support bf16, fp8.
Start with Booster
instantiate Booster with mixed_precision="fp16", then you can train with torch amp.
"""
Mapping:
'fp16': torch amp
'fp16_apex': apex amp,
'bf16': bf16,
'fp8': fp8,
'fp16_naive': naive amp
"""
from colossalai import Booster
booster = Booster(mixed_precision='fp16',...)
or you can create a FP16TorchMixedPrecision object, such as:
from colossalai.mixed_precision import FP16TorchMixedPrecision
mixed_precision = FP16TorchMixedPrecision(
init_scale=2.**16,
growth_factor=2.0,
backoff_factor=0.5,
growth_interval=2000)
booster = Booster(mixed_precision=mixed_precision,...)
The same goes for other types of amps.
Torch AMP Configuration
{{ autodoc:colossalai.booster.mixed_precision.FP16TorchMixedPrecision }}
Apex AMP Configuration
For this mode, we rely on the Apex implementation for mixed precision training. We support this plugin because it allows for finer control on the granularity of mixed precision. For example, O2 level (optimization level 2) will keep batch normalization in fp32.
If you look for more details, please refer to Apex Documentation.
{{ autodoc:colossalai.booster.mixed_precision.FP16ApexMixedPrecision }}
Naive AMP Configuration
In Naive AMP mode, we achieved mixed precision training while maintaining compatibility with complex tensor and pipeline parallelism. This AMP mode will cast all operations into fp16. The following code block shows the mixed precision api for this mode.
{{ autodoc:colossalai.booster.mixed_precision.FP16NaiveMixedPrecision }}
When using colossalai.booster, you are required to first instantiate a model, an optimizer and a criterion.
The output model is converted to AMP model of smaller memory consumption.
If your input model is already too large to fit in a GPU, please instantiate your model weights in dtype=torch.float16.
Otherwise, try smaller models or checkout more parallelization training techniques!
Hands-on Practice
Now we will introduce the use of AMP with Colossal-AI. In this practice, we will use Torch AMP as an example.
Step 1. Import libraries in train.py
Create a train.py and import the necessary dependencies. Remember to install scipy and timm by running
pip install timm scipy.
import os
from pathlib import Path
import torch
from timm.models import vit_base_patch16_224
from titans.utils import barrier_context
from torchvision import datasets, transforms
import colossalai
from colossalai.booster import Booster
from colossalai.booster.plugin import TorchDDPPlugin
from colossalai.logging import get_dist_logger
from colossalai.nn.lr_scheduler import LinearWarmupLR
Step 2. Initialize Distributed Environment
We then need to initialize distributed environment. For demo purpose, we uses launch_from_torch. You can refer to Launch Colossal-AI
for other initialization methods.
# initialize distributed setting
parser = colossalai.get_default_parser()
args = parser.parse_args()
# launch from torch
colossalai.launch_from_torch(config=dict())
Step 3. Create training components
Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
obtained from the environment variable DATA. You may export DATA=/path/to/data or change Path(os.environ['DATA'])
to a path on your machine. Data will be automatically downloaded to the root path.
# define the constants
NUM_EPOCHS = 2
BATCH_SIZE = 128
# build model
model = vit_base_patch16_224(drop_rate=0.1)
# build dataloader
train_dataset = datasets.Caltech101(
root=Path(os.environ['DATA']),
download=True,
transform=transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
Gray2RGB(),
transforms.Normalize([0.5, 0.5, 0.5],
[0.5, 0.5, 0.5])
]))
# build optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
# build loss
criterion = torch.nn.CrossEntropyLoss()
# lr_scheduler
lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=NUM_EPOCHS)
Step 4. Inject AMP Feature
Create a MixedPrecision(if needed) and TorchDDPPlugin object, call colossalai.boost convert the training components to be running with FP16.
plugin = TorchDDPPlugin()
train_dataloader = plugin.prepare_dataloader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
booster = Booster(mixed_precision='fp16', plugin=plugin)
# if you need to customize the config, do like this
# >>> from colossalai.mixed_precision import FP16TorchMixedPrecision
# >>> mixed_precision = FP16TorchMixedPrecision(
# >>> init_scale=2.**16,
# >>> growth_factor=2.0,
# >>> backoff_factor=0.5,
# >>> growth_interval=2000)
# >>> plugin = TorchDDPPlugin()
# >>> booster = Booster(mixed_precision=mixed_precision, plugin=plugin)
# boost model, optimizer, criterion, dataloader, lr_scheduler
model, optimizer, criterion, dataloader, lr_scheduler = booster.boost(model, optimizer, criterion, dataloader, lr_scheduler)
Step 5. Train with Booster
Use booster in a normal training loops.
model.train()
for epoch in range(NUM_EPOCHS):
for img, label in enumerate(train_dataloader):
img = img.cuda()
label = label.cuda()
optimizer.zero_grad()
output = model(img)
loss = criterion(output, label)
booster.backward(loss, optimizer)
optimizer.step()
lr_scheduler.step()
Step 6. Invoke Training Scripts
Use the following command to start the training scripts. You can change --nproc_per_node to use a different number of GPUs.
colossalai run --nproc_per_node 1 train.py