* [test] added spawn decorator * polish code * polish code * polish code * polish code * polish code * polish code |
||
|---|---|---|
| .. | ||
| README.md | ||
| auto_ckpt_batchsize_test.py | ||
| auto_ckpt_solver_test.py | ||
| auto_parallel_with_resnet.py | ||
| bench_utils.py | ||
| config.py | ||
| requirements.txt | ||
| setup.py | ||
| test_ci.sh | ||
README.md
Auto-Parallelism
Table of contents
📚 Overview
This tutorial folder contains a simple demo to run auto-parallelism with ResNet. Meanwhile, this diretory also contains demo scripts to run automatic activation checkpointing, but both features are still experimental for now and no guarantee that they will work for your version of Colossal-AI.
🚀 Quick Start
Setup
- Create a conda environment
conda create -n auto python=3.8
conda activate auto
- Install
requirementsandcoin-or-cbcfor the solver.
pip install -r requirements.txt
conda install -c conda-forge coin-or-cbc
Auto-Parallel Tutorial
Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
You should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, layer1_0_conv1 S01R = S01R X RR means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
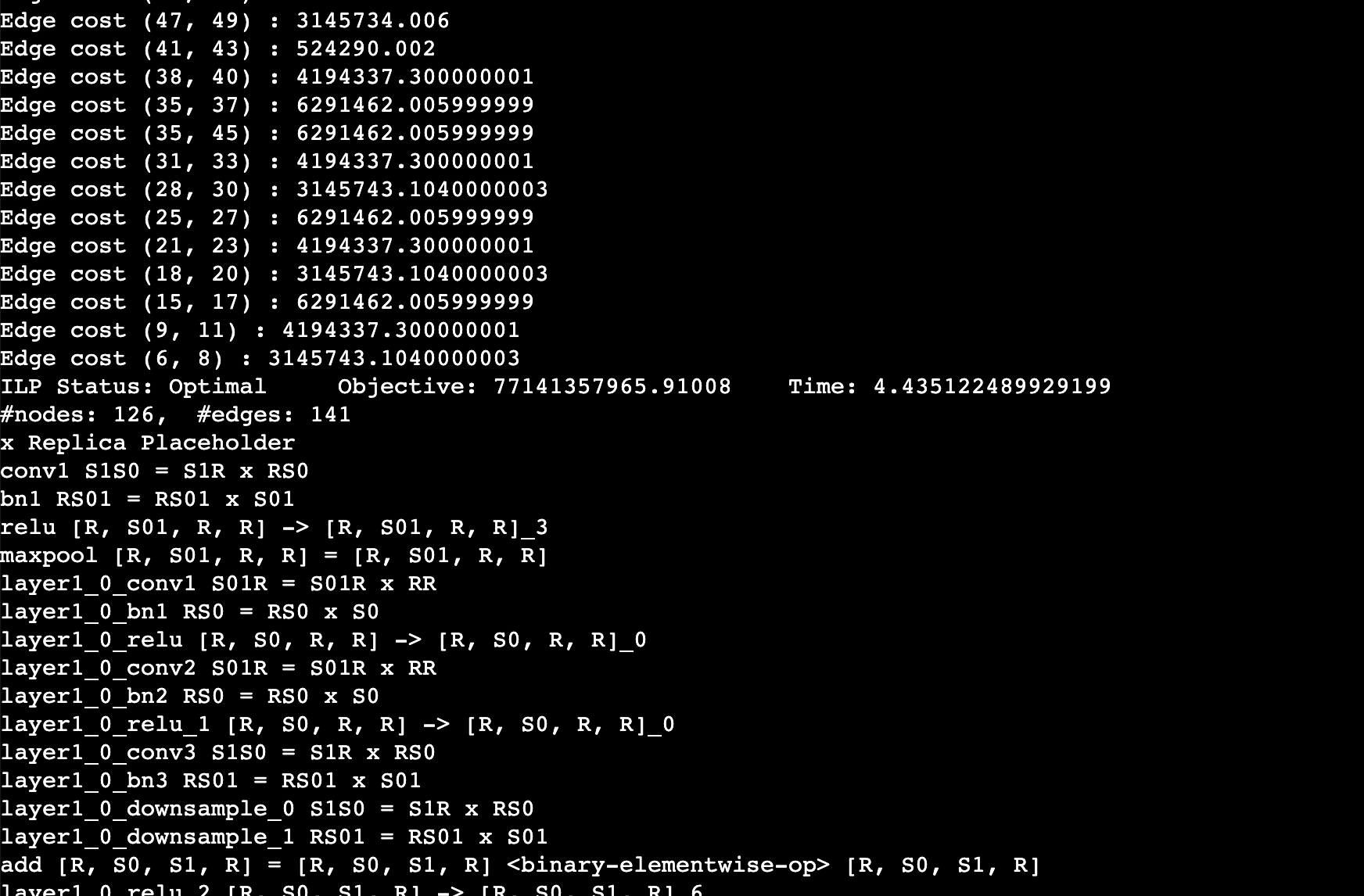
Note: This experimental feature has been tested on torch 1.12.1 and transformer 4.22.2. If you are using other versions, you may need to modify the code to make it work.
Auto-Checkpoint Tutorial
We prepare two bechmarks for you to test the performance of auto checkpoint
The first test auto_ckpt_solver_test.py will show you the ability of solver to search checkpoint strategy that could fit in the given budget (test on GPT2 Medium and ResNet 50). It will output the benchmark summary and data visualization of peak memory vs. budget memory and relative step time vs. peak memory.
The second test auto_ckpt_batchsize_test.py will show you the advantage of fitting larger batchsize training into limited GPU memory with the help of our activation checkpoint solver (test on ResNet152). It will output the benchmark summary.
The usage of the above two test
# run auto_ckpt_solver_test.py on gpt2 medium
python auto_ckpt_solver_test.py --model gpt2
# run auto_ckpt_solver_test.py on resnet50
python auto_ckpt_solver_test.py --model resnet50
# tun auto_ckpt_batchsize_test.py
python auto_ckpt_batchsize_test.py