mirror of https://github.com/hpcaitech/ColossalAI
[example] integrate autoparallel demo with CI (#2466)
* [example] integrate autoparallel demo with CI * polish code * polish code * polish code * polish codepull/2471/head
parent
14d9299360
commit
e6943e2d11
|
|
@ -1,15 +1,45 @@
|
|||
# Auto-Parallelism with ResNet
|
||||
# Auto-Parallelism
|
||||
|
||||
## Table of contents
|
||||
|
||||
- [Auto-Parallelism](#auto-parallelism)
|
||||
- [Table of contents](#table-of-contents)
|
||||
- [📚 Overview](#-overview)
|
||||
- [🚀 Quick Start](#-quick-start)
|
||||
- [Setup](#setup)
|
||||
- [Auto-Parallel Tutorial](#auto-parallel-tutorial)
|
||||
- [Auto-Checkpoint Tutorial](#auto-checkpoint-tutorial)
|
||||
|
||||
|
||||
## 📚 Overview
|
||||
|
||||
This tutorial folder contains a simple demo to run auto-parallelism with ResNet. Meanwhile, this diretory also contains demo scripts to run automatic activation checkpointing, but both features are still experimental for now and no guarantee that they will work for your version of Colossal-AI.
|
||||
|
||||
## 🚀 Quick Start
|
||||
|
||||
### Setup
|
||||
|
||||
1. Create a conda environment
|
||||
|
||||
## 🚀Quick Start
|
||||
### Auto-Parallel Tutorial
|
||||
1. Install `pulp` and `coin-or-cbc` for the solver.
|
||||
```bash
|
||||
pip install pulp
|
||||
conda create -n auto python=3.8
|
||||
conda activate auto
|
||||
```
|
||||
|
||||
2. Install `requirements` and `coin-or-cbc` for the solver.
|
||||
|
||||
```bash
|
||||
pip install -r requirements.txt
|
||||
conda install -c conda-forge coin-or-cbc
|
||||
```
|
||||
2. Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
|
||||
|
||||
|
||||
### Auto-Parallel Tutorial
|
||||
|
||||
Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
|
||||
|
||||
```bash
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py -s
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
|
||||
```
|
||||
|
||||
You should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, `layer1_0_conv1 S01R = S01R X RR` means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
|
||||
|
|
@ -17,57 +47,6 @@ You should expect to the log like this. This log shows the edge cost on the comp
|
|||
|
||||
|
||||
### Auto-Checkpoint Tutorial
|
||||
1. Stay in the `auto_parallel` folder.
|
||||
2. Install the dependencies.
|
||||
```bash
|
||||
pip install matplotlib transformers
|
||||
```
|
||||
3. Run a simple resnet50 benchmark to automatically checkpoint the model.
|
||||
```bash
|
||||
python auto_ckpt_solver_test.py --model resnet50
|
||||
```
|
||||
|
||||
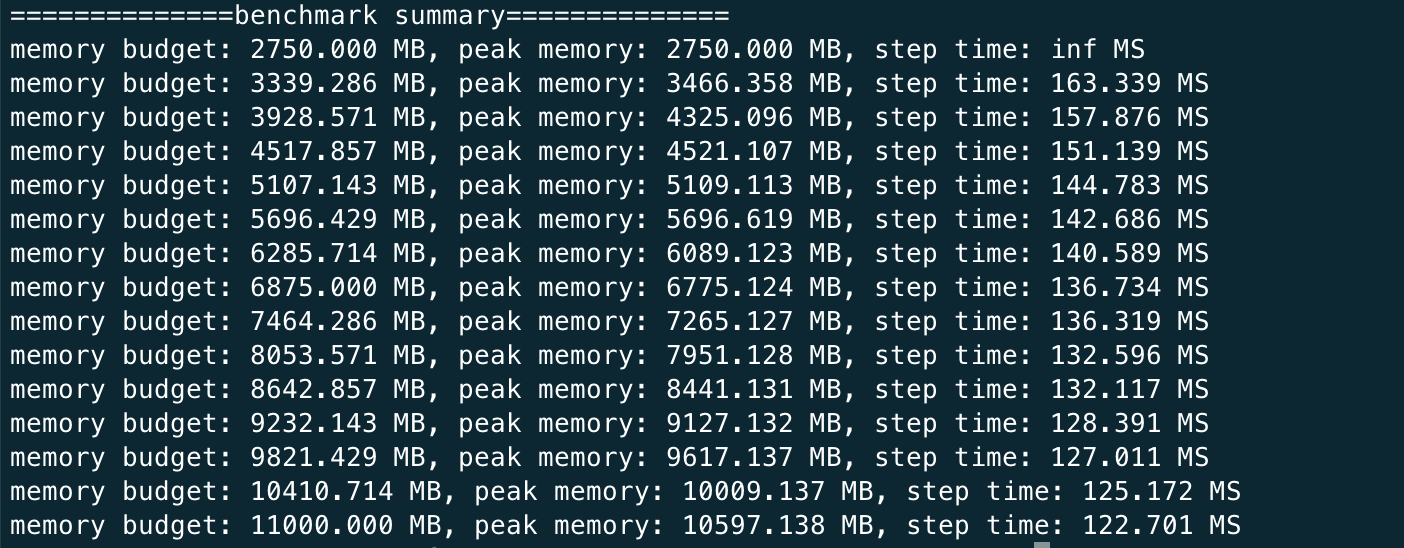
You should expect the log to be like this
|
||||
|
||||
|
||||
This shows that given different memory budgets, the model is automatically injected with activation checkpoint and its time taken per iteration. You can run this benchmark for GPT as well but it can much longer since the model is larger.
|
||||
```bash
|
||||
python auto_ckpt_solver_test.py --model gpt2
|
||||
```
|
||||
|
||||
4. Run a simple benchmark to find the optimal batch size for checkpointed model.
|
||||
```bash
|
||||
python auto_ckpt_batchsize_test.py
|
||||
```
|
||||
|
||||
You can expect the log to be like
|
||||

|
||||
|
||||
|
||||
## Prepare Dataset
|
||||
|
||||
We use CIFAR10 dataset in this example. You should invoke the `donwload_cifar10.py` in the tutorial root directory or directly run the `auto_parallel_with_resnet.py`.
|
||||
The dataset will be downloaded to `colossalai/examples/tutorials/data` by default.
|
||||
If you wish to use customized directory for the dataset. You can set the environment variable `DATA` via the following command.
|
||||
|
||||
```bash
|
||||
export DATA=/path/to/data
|
||||
```
|
||||
|
||||
## extra requirements to use autoparallel
|
||||
|
||||
```bash
|
||||
pip install pulp
|
||||
conda install coin-or-cbc
|
||||
```
|
||||
|
||||
## Run on 2*2 device mesh
|
||||
|
||||
```bash
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
|
||||
```
|
||||
|
||||
## Auto Checkpoint Benchmarking
|
||||
|
||||
We prepare two bechmarks for you to test the performance of auto checkpoint
|
||||
|
||||
|
|
@ -86,21 +65,3 @@ python auto_ckpt_solver_test.py --model resnet50
|
|||
# tun auto_ckpt_batchsize_test.py
|
||||
python auto_ckpt_batchsize_test.py
|
||||
```
|
||||
|
||||
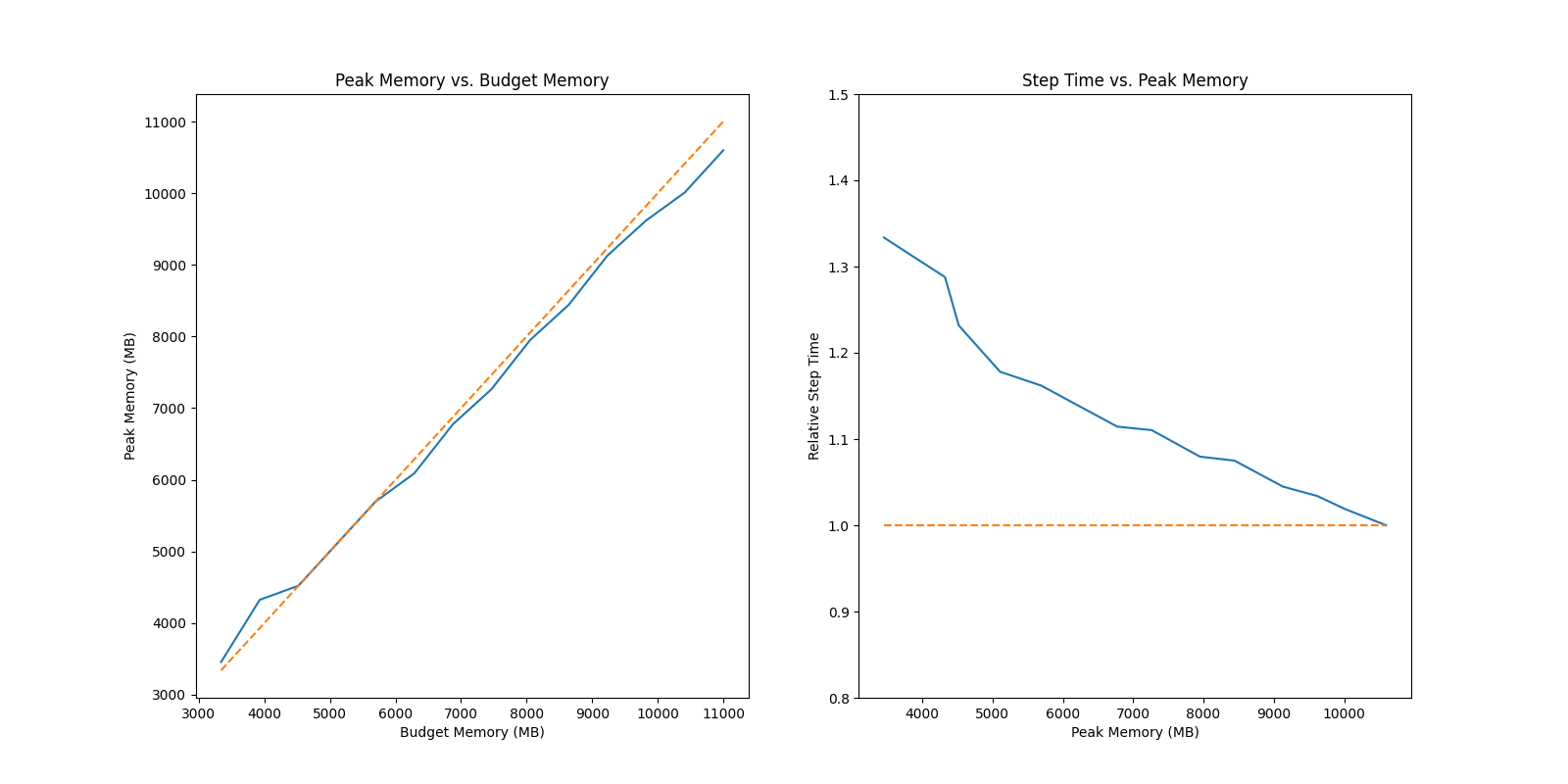
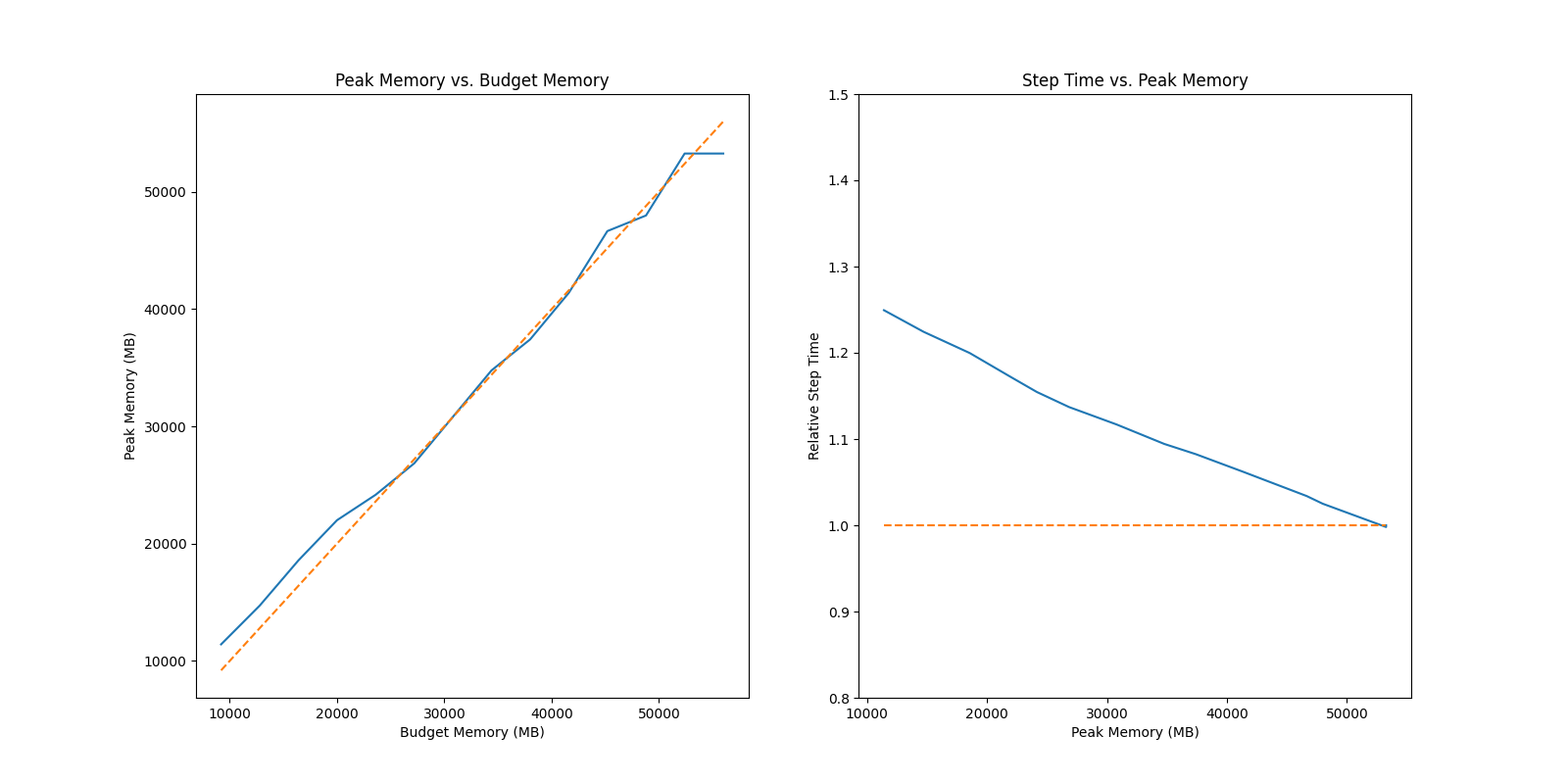
There are some results for your reference
|
||||
|
||||
## Auto Checkpoint Solver Test
|
||||
|
||||
### ResNet 50
|
||||
|
||||
|
||||
### GPT2 Medium
|
||||
|
||||
|
||||
## Auto Checkpoint Batch Size Test
|
||||
```bash
|
||||
===============test summary================
|
||||
batch_size: 512, peak memory: 73314.392 MB, through put: 254.286 images/s
|
||||
batch_size: 1024, peak memory: 73316.216 MB, through put: 397.608 images/s
|
||||
batch_size: 2048, peak memory: 72927.837 MB, through put: 277.429 images/s
|
||||
```
|
||||
|
|
|
|||
|
|
@ -1,11 +1,4 @@
|
|||
import argparse
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
from titans.utils import barrier_context
|
||||
from torchvision import transforms
|
||||
from torchvision.datasets import CIFAR10
|
||||
from torchvision.models import resnet50
|
||||
from tqdm import tqdm
|
||||
|
||||
|
|
@ -14,9 +7,6 @@ from colossalai.auto_parallel.tensor_shard.initialize import autoparallelize
|
|||
from colossalai.core import global_context as gpc
|
||||
from colossalai.logging import get_dist_logger
|
||||
from colossalai.nn.lr_scheduler import CosineAnnealingLR
|
||||
from colossalai.utils import get_dataloader
|
||||
|
||||
DATA_ROOT = Path(os.environ.get('DATA', '../data')).absolute()
|
||||
|
||||
|
||||
def synthesize_data():
|
||||
|
|
@ -48,9 +38,8 @@ def main():
|
|||
model.train()
|
||||
|
||||
# if we use synthetic data
|
||||
# we assume it only has 30 steps per epoch
|
||||
num_steps = range(30)
|
||||
|
||||
# we assume it only has 10 steps per epoch
|
||||
num_steps = range(10)
|
||||
progress = tqdm(num_steps)
|
||||
|
||||
for _ in progress:
|
||||
|
|
@ -73,8 +62,7 @@ def main():
|
|||
|
||||
# if we use synthetic data
|
||||
# we assume it only has 10 steps for evaluation
|
||||
num_steps = range(30)
|
||||
|
||||
num_steps = range(10)
|
||||
progress = tqdm(num_steps)
|
||||
|
||||
for _ in progress:
|
||||
|
|
|
|||
|
|
@ -1,2 +1,2 @@
|
|||
BATCH_SIZE = 128
|
||||
NUM_EPOCHS = 10
|
||||
BATCH_SIZE = 32
|
||||
NUM_EPOCHS = 2
|
||||
|
|
|
|||
|
|
@ -1,32 +0,0 @@
|
|||
name: auto
|
||||
channels:
|
||||
- pytorch
|
||||
- conda-forge
|
||||
- defaults
|
||||
dependencies:
|
||||
- _libgcc_mutex=0.1=conda_forge
|
||||
- _openmp_mutex=4.5=2_kmp_llvm
|
||||
- blas=1.0=mkl
|
||||
- brotlipy=0.7.0=py38h27cfd23_1003
|
||||
- bzip2=1.0.8=h7b6447c_0
|
||||
- ca-certificates=2022.12.7=ha878542_0
|
||||
- certifi=2022.12.7=pyhd8ed1ab_0
|
||||
- cffi=1.15.1=py38h74dc2b5_0
|
||||
- charset-normalizer=2.0.4=pyhd3eb1b0_0
|
||||
- coin-or-cbc=2.10.8=h3786ebc_0
|
||||
- coin-or-cgl=0.60.6=h6f57e76_2
|
||||
- coin-or-clp=1.17.7=hc56784d_2
|
||||
- coin-or-osi=0.108.7=h2720bb7_2
|
||||
- coin-or-utils=2.11.6=h202d8b1_2
|
||||
- python=3.8.13
|
||||
- pip=22.2.2
|
||||
- cudatoolkit=11.3
|
||||
- pytorch=1.12.1
|
||||
- torchvision=0.13.1
|
||||
- numpy=1.23.1
|
||||
- pip:
|
||||
- titans
|
||||
- torch==1.12.1
|
||||
- pulp==2.7.0
|
||||
- datasets
|
||||
- colossalai
|
||||
|
|
@ -1,2 +1,7 @@
|
|||
colossalai >= 0.1.12
|
||||
torch >= 1.8.1
|
||||
torch
|
||||
colossalai
|
||||
titans
|
||||
pulp
|
||||
datasets
|
||||
matplotlib
|
||||
transformers
|
||||
|
|
|
|||
|
|
@ -1,11 +1,6 @@
|
|||
#!/bin/bash
|
||||
set -euxo pipefail
|
||||
|
||||
conda init bash
|
||||
conda env create -f environment.yaml
|
||||
conda activate auto
|
||||
cd ../../..
|
||||
pip uninstall colossalai
|
||||
pip install -v .
|
||||
cd ./examples/tutorial/auto_parallel
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py -s
|
||||
pip install -r requirements.txt
|
||||
conda install -c conda-forge coin-or-cbc
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
|
||||
|
|
|
|||
Loading…
Reference in New Issue