7.3 KiB
ColoTensor Concepts
Author: Jiarui Fang, Hongxin Liu and Haichen Huang
⚠️ The information on this page is outdated and will be deprecated.
Prerequisite:
Introduction
After ColossalAI version 0.1.8, ColoTensor becomes the basic data structure for tensors in ColossalAI. It is a subclass of torch.Tensor and can be used as a PyTorch Tensor. Additionally, some unique features make it possible to represent a Global Tensor with a payload distributed across multiple GPU devices. With the help of ColoTensor, the users can write distributed DNN training program similar to a serial one.support the following features.
ColoTensor contains extra attributes capsuled in a ColoTensorSpec instance to describe the tensor's payload distribution and computing pattern.
- ProcessGroup: how processes are organized as communication groups.
- Distributed Spec: how tensor is distributed among process groups.
- Compute Spec: how the tensor is used during computation.
We elaborate on them one by one.
ProcessGroup
An instance of class ProcessGroup describes how processes are organized in process groups. Processes in a process group can participate in the same collective communication operations together, such as allgather, allreduce, etc. The way the process group is organized is dominated by the Tensor's parallelism strategy. For example, if the user defines the tensor parallel (TP) and data parallel (DP) modes of a tensor, then the process organization of the process group will be automatically deduced. The process group settings can vary among different tensors. Therefore, it enables us to support more complicated hybrid parallel. The pipeline parallel (PP) definition is not in the ProcessGroup, it needs another set of mechanisms . We will supplement the related content of ColoTensor applied to PP in the future.
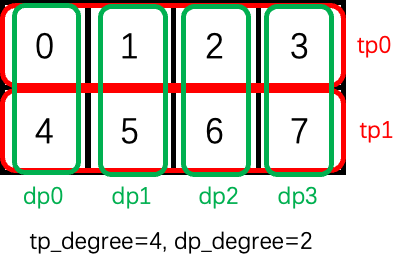
Currently, a process group of ColoTensor is defined by two configurations, i.e. tp_degree and dp_degree. In the case of DP+TP hybrid parallelism, the device can be viewed as a 2D mesh. We place TP communication groups on the leading low dimension of the device mesh and then place the data parallel groups along the high dimension of the device mesh. The reason is that tensor parallelism has a larger communication overhead than data parallelism. Neighboring devices are placed inside a TP process group and are often placed in the same node.
Considering that 8 processes are configured as tp_degree=4, and dp_degree=2, the layout is shown below. Process group tp0 contains gpu 0,1,2,3. Process dp1 contains gpu 1 and 5.
Distributed Spec
An instance of Distributed Spec describes how a ColoTensor is distributed among the ProcessGroup.
How tensors are distributed among DP process groups is automatically derived and does not need to be manually specified by the user. If this tensor is a model parameter, it is replicated within the DP process group. If it is an activation tensor, it is split along the process with the highest dimension and evenly distributed the tensor payload among processes in the DP process group.
Therefore, when using Distributed Spec, we only need to describe the way that the tensor is distributed among TP process groups. There are currently two ways to distribute among TP process group, i.e. ShardSpec and ReplicaSpec. ShardSpec needs to specify the dimension index dim of the partition and the number of partitions num_partitions. Currently, we only support the split on a single dim. Different dist specs on the TP process groups can be converted to each other through the set_dist_spec() interface. The spec conversions are recorded by the autograd mechanism and it will trigger corresponding reverse operations during backward propagation.
Compute Spec
An instance of class ComputeSpec describes how a Colotensor be used in DNN training. Currently, we will set the correct Compute Pattern for the ColoTensor as the parameters of the module. The specific application scenarios will be shown in the next document.
ColoParameter
ColoParameter is a subclass of ColoTensor. Used to define a Global Parameter tensor. Its relationship with ColoTensor is consistent with Torch.Tensor and torch.Parameter. The latter allows the tensor to appear in the return values of the module's parameters() and name_parameters() methods.
Example
Let's see an example. A ColoTensor is initialized and sharded on 8 GPUs using tp_degree=4, dp_dgree=2. And then the tensor is sharded along the last dim among the TP process groups. Finally, we reshard it along the first dim (0 dim) among the TP process groups. We encourage users to run the code and observe the shape of each tensor.
import torch
import torch.multiprocessing as mp
from colossalai.utils import print_rank_0
from functools import partial
import colossalai
from colossalai.tensor import ProcessGroup, ColoTensor, ColoTensorSpec, ShardSpec, ComputeSpec, ComputePattern
from colossalai.testing import spawn
import torch
def run_dist_tests(rank, world_size, port):
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
pg = ProcessGroup(tp_degree=2, dp_degree=2)
torch.manual_seed(0)
local_tensor = torch.randn(2, 3, 1).cuda()
print_rank_0(f"shape {local_tensor.shape}, {local_tensor.data}")
spec = ColoTensorSpec(pg, ShardSpec(dims=[-1], num_partitions=[pg.tp_world_size()]), ComputeSpec(ComputePattern.TP1D))
t1 = ColoTensor.from_torch_tensor(local_tensor, spec)
t1 = t1.to_replicate()
print_rank_0(f"shape {t1.shape}, {t1.data}")
spec2 = ShardSpec([0], [pg.tp_world_size()])
t1.set_dist_spec(spec2)
print_rank_0(f"shape {t1.shape}, {t1.data}")
def test_dist_cases(world_size):
spawn(run_dist_tests, world_size)
if __name__ == '__main__':
test_dist_cases(4)
:::caution
The ColoTensor is an experimental feature and may be updated.
:::