* [misc] remove config arg from initialize * [misc] remove old tensor contrusctor * [plugin] add npu support for ddp * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [devops] fix doc test ci * [test] fix test launch * [doc] update launch doc --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> |
||
|---|---|---|
| .. | ||
| README.md | ||
| grok1_policy.py | ||
| inference.py | ||
| inference_tp.py | ||
| requirements.txt | ||
| run_inference_fast.sh | ||
| run_inference_slow.sh | ||
| test_ci.sh | ||
| utils.py | ||
README.md
Grok-1 Inference
- 314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, an easy-to-use Python + PyTorch + HuggingFace version for Inference.
[code] [blog] [HuggingFace Grok-1 PyTorch model weights] [ModelScope Grok-1 PyTorch model weights]
Installation
# Make sure you install colossalai from the latest source code
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
pip install .
cd examples/language/grok-1
pip install -r requirements.txt
Inference
You need 8x A100 80GB or equivalent GPUs to run the inference.
We provide two scripts for inference. run_inference_fast.sh uses tensor parallelism provided by ColossalAI, which is faster for generation, while run_inference_slow.sh uses auto device provided by transformers, which is relatively slower.
Command example:
./run_inference_fast.sh <MODEL_NAME_OR_PATH>
./run_inference_slow.sh <MODEL_NAME_OR_PATH>
MODEL_NAME_OR_PATH can be a model name from Hugging Face model hub or a local path to PyTorch-version model checkpoints. We have provided pytorch-version checkpoint on HuggingFace model hub, named hpcai-tech/grok-1. And you could also download the weights in advance using git:
git lfs install
git clone https://huggingface.co/hpcai-tech/grok-1
It will take, depending on your Internet speed, several hours to tens of hours to download checkpoints (about 600G!), and 5-10 minutes to load checkpoints when it's ready to launch the inference. Don't worry, it's not stuck.
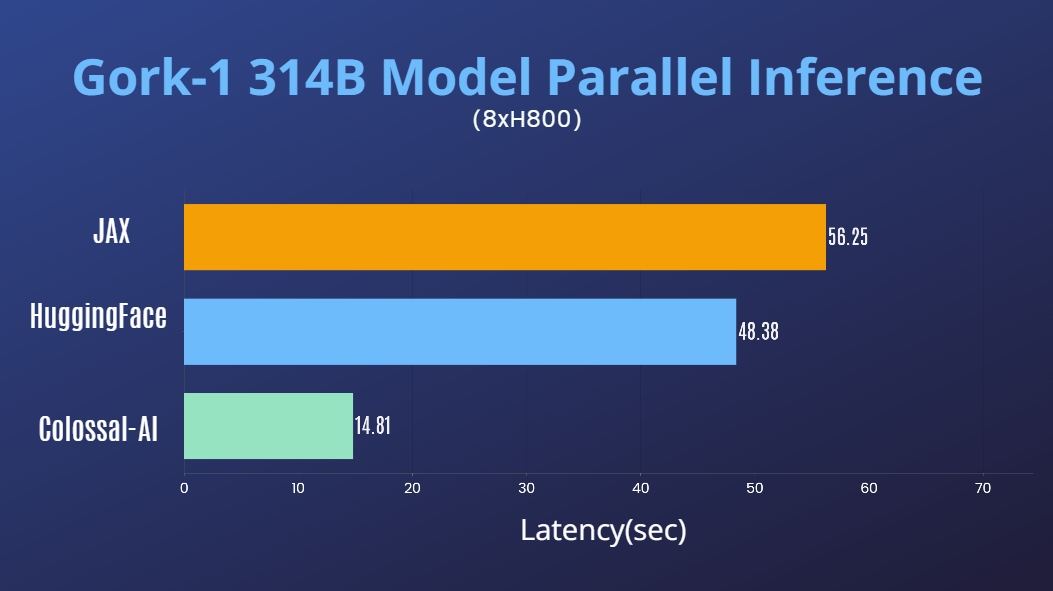
Performance
For request of batch size set to 1 and maximum length set to 100:
| Method | Initialization-Duration(sec) | Average-Generation-Latency(sec) |
|---|---|---|
| ColossalAI | 431.45 | 14.92 |
| HuggingFace Auto-Device | 426.96 | 48.38 |
| JAX | 147.61 | 56.25 |
Tested on 8x80G NVIDIA H800.