2.9 KiB
OPT
Meta recently released Open Pretrained Transformer (OPT), a 175-Billion parameter AI language model, which stimulates AI programmers to perform various downstream tasks and application deployments.
The following example of Colossal-AI demonstrates fine-tuning Casual Language Modelling at low cost.
We are using the pre-training weights of the OPT model provided by Hugging Face Hub on the raw WikiText-2 (no tokens were replaced before the tokenization). This training script is adapted from the HuggingFace Language Modelling examples.
Quick Start
You can launch training by using the following bash script
bash ./run_clm.sh <batch-size-per-gpu> <mem-cap> <model> <gpu-num>
- batch-size-per-gpu: number of samples fed to each GPU, default is 16
- mem-cap: limit memory usage within a value in GB, default is 0 (no limit)
- model: the size of the OPT model, default is
6.7b. Acceptable values include125m,350m,1.3b,2.7b,6.7,13b,30b,66b. For175b, you can request the pretrained weights from OPT weight downloading page. - gpu-num: the number of GPUs to use, default is 1.
Remarkable Performance
On a single GPU, Colossal-AI’s automatic strategy provides remarkable performance gains from the ZeRO Offloading strategy by Microsoft DeepSpeed. Users can experience up to a 40% speedup, at a variety of model scales. However, when using a traditional deep learning training framework like PyTorch, a single GPU can no longer support the training of models at such a scale.
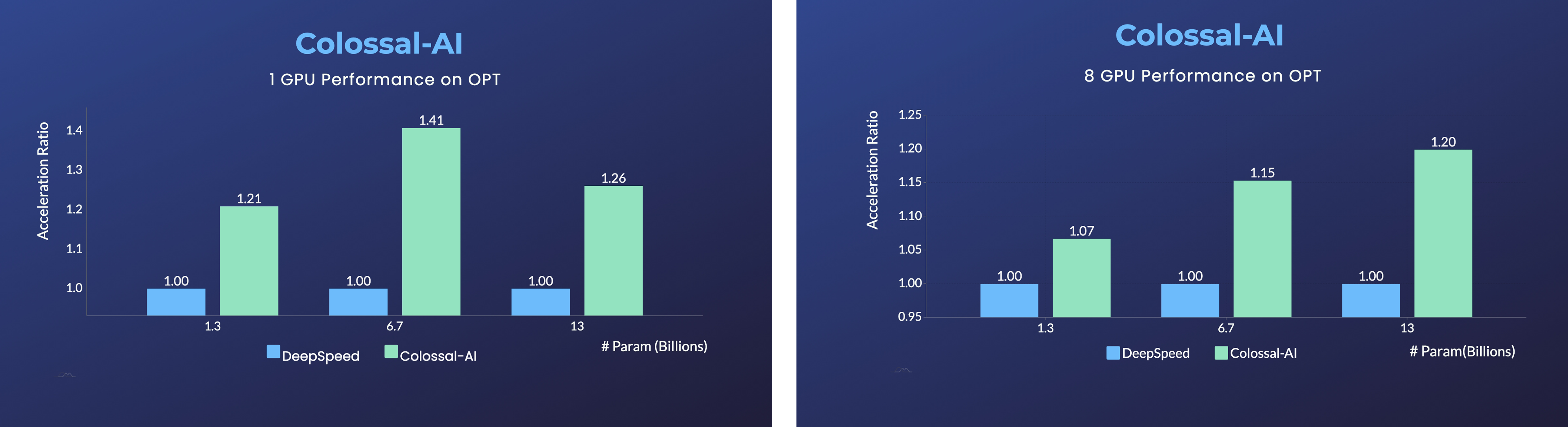
Adopting the distributed training strategy with 8 GPUs is as simple as adding a -nprocs 8 to the training command of Colossal-AI!
More details about behind the scenes can be found on the corresponding blog, and a detailed tutorial will be added in Documentation very soon.