13 KiB
自动混合精度训练 (旧版本)
作者: Chuanrui Wang, Shenggui Li, Yongbin Li
前置教程
示例代码
相关论文
引言
AMP 代表自动混合精度训练。 在 Colossal-AI 中, 我们结合了混合精度训练的不同实现:
- torch.cuda.amp
- apex.amp
- naive amp
| Colossal-AI | 支持张量并行 | 支持流水并行 | fp16范围 |
|---|---|---|---|
| AMP_TYPE.TORCH | ✅ | ❌ | 在前向和反向传播期间,模型参数、激活和梯度向下转换至fp16 |
| AMP_TYPE.APEX | ❌ | ❌ | 更细粒度,我们可以选择 opt_level O0, O1, O2, O3 |
| AMP_TYPE.NAIVE | ✅ | ✅ | 模型参数、前向和反向操作,全都向下转换至fp16 |
前两个依赖于 PyTorch (1.6及以上) 和 NVIDIA Apex 的原始实现。最后一种方法类似 Apex O2。在这些方法中,Apex-AMP 与张量并行不兼容。这是因为张量是以张量并行的方式在设备之间拆分的,因此,需要在不同的进程之间进行通信,以检查整个模型权重中是否出现inf或nan。我们修改了torch amp实现,使其现在与张量并行兼容。
❌️ fp16与ZeRO配置不兼容
⚠️ 流水并行目前仅支持naive amp
我们建议使用 torch AMP,因为在不使用流水并行时,它通常比 NVIDIA AMP 提供更好的准确性。
目录
在本教程中,我们将介绍:
- AMP 介绍
- Colossal-AI 中的 AMP
- 练习实例
AMP 介绍
自动混合精度训练是混合 FP16 和 FP32 训练。
半精度浮点格式(FP16)具有较低的算法复杂度和较高的计算效率。此外,FP16 仅需要 FP32 所需的一半存储空间,并节省了内存和网络带宽,从而为大 batch size 和大模型提供了更多内存。
然而,还有其他操作,如缩减,需要 FP32 的动态范围,以避免数值溢出/下溢。因此,我们引入自动混合精度,尝试将每个操作与其相应的数据类型相匹配,这可以减少内存占用并提高训练效率。
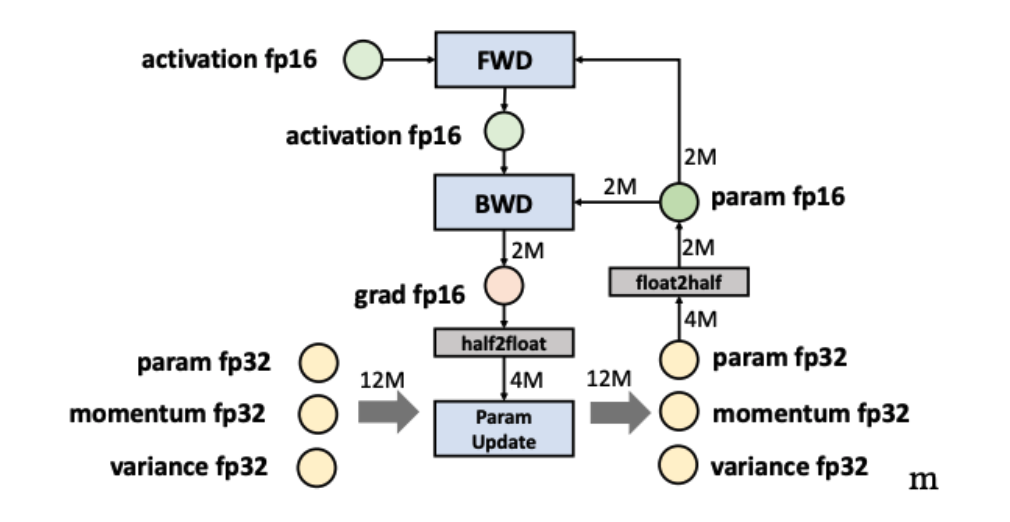
Colossal-AI 中的 AMP
我们支持三种 AMP 训练方法,并允许用户在没有改变代码的情况下使用 AMP 进行训练。只需在配置文件中添加'fp16'配置即可使用 AMP。
from colossalai.amp import AMP_TYPE
# 使用 Torch AMP
fp16=dict(
mode = AMP_TYPE.TORCH
)
# 使用 naive AMP
fp16=dict(
mode = AMP_TYPE.NAIVE
)
# 使用 Nvidia Apex AMP
fp16=dict(
mode = AMP_TYPE.APEX
)
这些是最低配置,完整配置将在后面的部分中说明
AMP 模块化
AMP 模块设计为完全模块化,可以独立使用。如果你想在你的代码库中只使用 AMP 而不使用colossalai.initialize,你可以导入colossalai.amp.convert_to_amp。
from colossalai.amp import AMP_TYPE
# 使用torch amp的例子
model, optimizer, criterion = colossalai.amp.convert_to_amp(model,
optimizer,
criterion,
AMP_TYPE.TORCH)
Torch AMP 配置
from colossalai.amp import AMP_TYPE
fp16=dict(
mode=AMP_TYPE.TORCH,
# 下列是grad scaler的默认值
init_scale=2.**16,
growth_factor=2.0,
backoff_factor=0.5,
growth_interval=2000,
enabled=True
)
可选参数:
- init_scale(float, optional, default=2.**16): 初始缩放因子;
- growth_factor(float, optional, default=2.0): 如果在
growth_interval连续迭代过程中没有出现 inf/NaN 梯度,则在update中乘以比例系数; - backoff_factor(float, optional, default=0.5): 如果在迭代中出现 inf/NaN 梯度,则在
update中乘以比例系数; - growth_interval(int, optional, default=2000): 在指定次数的连续迭代中,若没有出现 inf/NaN 梯度,则乘以
growth_factor. - enabled(bool, optional, default=True):
False则使梯度缩放无效,step仅调用底层的optimizer.step(), 其他方法成为空操作。
Apex AMP 配置
对于这种模式,我们依靠 Apex 实现混合精度训练。我们支持这个插件,因为它允许对混合精度的粒度进行更精细的控制。 例如, O2 水平 (优化器水平2) 将保持 batch normalization 为 FP32。
如果你想了解更多细节,请参考 Apex Documentation。
from colossalai.amp import AMP_TYPE
fp16 = dict(
mode=AMP_TYPE.APEX,
# 下列是默认值
enabled=True,
opt_level='O1',
cast_model_type=None,
patch_torch_functions=None,
keep_batchnorm_fp32=None,
master_weights=None,
loss_scale=None,
cast_model_outputs=None,
num_losses=1,
verbosity=1,
min_loss_scale=None,
max_loss_scale=16777216.0
)
参数:
-
enabled(bool, optional, default=True): False 会使所有 AMP 调用成为空操作, 程序将会像没有使用 AMP 一样运行。
-
opt_level(str, optional, default="O1" ): 纯精度或混合精度优化水平。可选值 “O0”, “O1”, “O2”, and “O3”, 详细解释见上方 Apex AMP 文档。
-
num_losses(int, optional, default=1): 选择提前告知 AMP 您计划使用多少次损失/反向计算。 当
amp.scale_loss与 loss_id 参数一起使用时,使 AMP 在每次损失/反向计算时使用不同的损失比例,这可以提高稳定性。如果 num_losses 被设置为1,AMP 仍支持多次损失/反向计算,但对他们都使用同一个全局损失比例。 -
verbosity(int, default=1): 设置为0抑制 AMP 相关输出。
-
min_loss_scale(float, default=None): 为可通过动态损耗比例选择的损耗比例值设置下限。 默认值“None”意味着不设置任何下限。如果不使用动态损耗比例,则忽略 min_loss_scale 。
-
max_loss_scale(float, default=2.**24 ): 为可通过动态损耗比例选择的损耗比例值设置上限。如果不使用动态损耗比例,则 max_loss_scale 被忽略.
目前,管理纯精度或混合精度训练的幕后属性有以下几种: cast_model_type, patch_torch_functions, keep_batchnorm_fp32, master_weights, loss_scale. 一旦 opt_level 被确定,它们是可选的可覆盖属性
- cast_model_type: 将模型的参数和缓冲区强制转换为所需的类型。
- patch_torch_functions: 补全所有的 Torch 函数和张量方法,以便在FP16中执行张量核心友好的操作,如 GEMMs 和卷积,以及在 FP32 中执行任何受益于 FP32 精度的操作。
- keep_batchnorm_fp32: 为了提高精度并启用 cudnn batchnorm (这会提高性能),在 FP32 中保留 batchnorm 权重通常是有益的,即使模型的其余部分是 FP16。
- master_weights: 保持 FP32 主权重以配合任何 FP16 模型权重。 FP32 主权重由优化器分级,以提高精度和捕捉小梯度。
- loss_scale: 如果 loss_scale 是一个浮点数,则使用这个值作为静态(固定)的损失比例。如果 loss_scale 是字符串 "dynamic",则随着时间的推移自适应地调整损失比例。动态损失比例调整由 AMP 自动执行。
Naive AMP 配置
在 Naive AMP 模式中, 我们实现了混合精度训练,同时保持了与复杂张量和流水并行的兼容性。该 AMP 模式将所有操作转为 FP16 。下列代码块展示了该模式的config.py。
from colossalai.amp import AMP_TYPE
fp16 = dict(
mode=AMP_TYPE.NAIVE,
# below are the default values
log_num_zeros_in_grad=False,
initial_scale=2 ** 32,
min_scale=1,
growth_factor=2,
backoff_factor=0.5,
growth_interval=1000,
hysteresis=2
)
Naive AMP 的默认参数:
- log_num_zeros_in_grad(bool): 返回0值梯度的个数.
- initial_scale(int): gradient scaler 的初始值
- growth_factor(int): loss scale 的增长率
- backoff_factor(float): loss scale 的下降率
- hysteresis(int): 动态 loss scaling 的延迟偏移
- max_scale(int): loss scale 的最大允许值
- verbose(bool): 如果被设为
True,将打印调试信息
当使用colossalai.initialize时, 首先需要实例化一个模型、一个优化器和一个标准。将输出模型转换为内存消耗较小的 AMP 模型。如果您的输入模型已经太大,无法放置在 GPU 中,请使用dtype=torch.float16实例化你的模型。或者请尝试更小的模型,或尝试更多的并行化训练技术!
实例
我们提供了一个 运行实例 展现如何在 Colossal-AI 使用 AMP。在该例程中,我们使用 Torch AMP, 但提供的配置文件也适用于所有 AMP 模式.
步骤 1. 创建配置文件
创建一个config.py文件并添加fp16配置.
# in config.py
from colossalai.amp import AMP_TYPE
BATCH_SIZE = 128
DROP_RATE = 0.1
NUM_EPOCHS = 300
fp16 = dict(
mode=AMP_TYPE.TORCH,
)
clip_grad_norm = 1.0
步骤 2. 在 train_with_engine.py 导入相关库
创建train_with_engine.py并导入必要依赖. 请记得通过命令pip install timm scipy安装scipy和timm。
import os
import colossalai
import torch
from pathlib import Path
from colossalai.core import global_context as gpc
from colossalai.logging import get_dist_logger
from colossalai.utils import get_dataloader
from colossalai.trainer import Trainer, hooks
from colossalai.nn.lr_scheduler import LinearWarmupLR
from timm.models import vit_base_patch16_224
from torchvision import datasets, transforms
步骤 3. 初始化分布式环境
我们需要初始化分布式环境。为了快速演示,我们使用launch_from_torch。你可以参考 Launch Colossal-AI
使用其他初始化方法。
# 初始化分布式设置
parser = colossalai.get_default_parser()
args = parser.parse_args()
# launch from torch
colossalai.launch_from_torch(config=args.config)
步骤 4. 创建训练组件
构建你的模型、优化器、损失函数、学习率调整器和数据加载器。注意数据集的路径从环境变量DATA获得。你可以通过 export DATA=/path/to/data 或 Path(os.environ['DATA'])
在你的机器上设置路径。数据将会被自动下载到该路径。
# build model
model = vit_base_patch16_224(drop_rate=0.1)
# build dataloader
train_dataset = datasets.Caltech101(
root=Path(os.environ['DATA']),
download=True,
transform=transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
Gray2RGB(),
transforms.Normalize([0.5, 0.5, 0.5],
[0.5, 0.5, 0.5])
]))
train_dataloader = get_dataloader(dataset=train_dataset,
shuffle=True,
batch_size=gpc.config.BATCH_SIZE,
num_workers=1,
pin_memory=True,
)
# build optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
# build loss
criterion = torch.nn.CrossEntropyLoss()
# lr_scheduelr
lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=gpc.config.NUM_EPOCHS)
步骤 5. 插入 AMP
调用 colossalai.initialize 将所有训练组件转为为FP16模式.
engine, train_dataloader, _, _ = colossalai.initialize(
model, optimizer, criterion, train_dataloader,
)
步骤 6. 使用 Engine 训练
使用Engine构建一个普通的训练循环
engine.train()
for epoch in range(gpc.config.NUM_EPOCHS):
for img, label in enumerate(train_dataloader):
img = img.cuda()
label = label.cuda()
engine.zero_grad()
output = engine(img)
loss = engine.criterion(output, label)
engine.backward(loss)
engine.step()
lr_scheduler.step()
步骤 7. 启动训练脚本
使用下列命令启动训练脚本,你可以改变 --nproc_per_node 以使用不同数量的 GPU。
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py