27 KiB
Colossal-AI


新闻
- [2024/04] Open-Sora Unveils Major Upgrade: Embracing Open Source with Single-Shot 16-Second Video Generation and 720p Resolution
- [2024/04] Most cost-effective solutions for inference, fine-tuning and pretraining, tailored to LLaMA3 series
- [2024/03] 314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, Efficient and Easy-to-Use PyTorch+HuggingFace version is Here
- [2024/03] Open-Sora: Revealing Complete Model Parameters, Training Details, and Everything for Sora-like Video Generation Models
- [2024/03] Open-Sora:Sora Replication Solution with 46% Cost Reduction, Sequence Expansion to Nearly a Million
- [2024/01] Inference Performance Improved by 46%, Open Source Solution Breaks the Length Limit of LLM for Multi-Round Conversations
- [2024/01] Construct Refined 13B Private Model With Just $5000 USD, Upgraded Colossal-AI Llama-2 Open Source
- [2023/11] Enhanced MoE Parallelism, Open-source MoE Model Training Can Be 9 Times More Efficient
- [2023/09] One Half-Day of Training Using a Few Hundred Dollars Yields Similar Results to Mainstream Large Models, Open-Source and Commercial-Free Domain-Specific LLM Solution
- [2023/09] 70 Billion Parameter LLaMA2 Model Training Accelerated by 195%
- [2023/07] HPC-AI Tech Raises 22 Million USD in Series A Funding
目录
为何选择 Colossal-AI

James Demmel 教授 (加州大学伯克利分校): Colossal-AI 让分布式训练高效、易用、可扩展。
(返回顶端)
特点
Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的分布式 AI 模型像构建普通的单 GPU 模型一样简单。我们提供的友好工具可以让您在几行代码内快速开始分布式训练和推理。
- 并行化策略
- 异构内存管理
- 使用友好
- 基于参数文件的并行化
(返回顶端)
Colossal-AI 成功案例
Open-Sora
Open-Sora:全面开源类Sora模型参数和所有训练细节 [代码] [博客] [模型权重] [演示样例]

Colossal-LLaMA-2
-
13B: 万元预算打造高质量13B私有模型 [代码] [博客] [HuggingFace 模型权重] [Modelscope 模型权重]
| Model | Backbone | Tokens Consumed | MMLU (5-shot) | CMMLU (5-shot) | AGIEval (5-shot) | GAOKAO (0-shot) | CEval (5-shot) |
|---|---|---|---|---|---|---|---|
| Baichuan-7B | - | 1.2T | 42.32 (42.30) | 44.53 (44.02) | 38.72 | 36.74 | 42.80 |
| Baichuan-13B-Base | - | 1.4T | 50.51 (51.60) | 55.73 (55.30) | 47.20 | 51.41 | 53.60 |
| Baichuan2-7B-Base | - | 2.6T | 46.97 (54.16) | 57.67 (57.07) | 45.76 | 52.60 | 54.00 |
| Baichuan2-13B-Base | - | 2.6T | 54.84 (59.17) | 62.62 (61.97) | 52.08 | 58.25 | 58.10 |
| ChatGLM-6B | - | 1.0T | 39.67 (40.63) | 41.17 (-) | 40.10 | 36.53 | 38.90 |
| ChatGLM2-6B | - | 1.4T | 44.74 (45.46) | 49.40 (-) | 46.36 | 45.49 | 51.70 |
| InternLM-7B | - | 1.6T | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 |
| Qwen-7B | - | 2.2T | 54.29 (56.70) | 56.03 (58.80) | 52.47 | 56.42 | 59.60 |
| Llama-2-7B | - | 2.0T | 44.47 (45.30) | 32.97 (-) | 32.60 | 25.46 | - |
| Linly-AI/Chinese-LLaMA-2-7B-hf | Llama-2-7B | 1.0T | 37.43 | 29.92 | 32.00 | 27.57 | - |
| wenge-research/yayi-7b-llama2 | Llama-2-7B | - | 38.56 | 31.52 | 30.99 | 25.95 | - |
| ziqingyang/chinese-llama-2-7b | Llama-2-7B | - | 33.86 | 34.69 | 34.52 | 25.18 | 34.2 |
| TigerResearch/tigerbot-7b-base | Llama-2-7B | 0.3T | 43.73 | 42.04 | 37.64 | 30.61 | - |
| LinkSoul/Chinese-Llama-2-7b | Llama-2-7B | - | 48.41 | 38.31 | 38.45 | 27.72 | - |
| FlagAlpha/Atom-7B | Llama-2-7B | 0.1T | 49.96 | 41.10 | 39.83 | 33.00 | - |
| IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | Llama-13B | 0.11T | 50.25 | 40.99 | 40.04 | 30.54 | - |
| Colossal-LLaMA-2-7b-base | Llama-2-7B | 0.0085T | 53.06 | 49.89 | 51.48 | 58.82 | 50.2 |
ColossalChat

ColossalChat: 完整RLHF流程0门槛克隆 ChatGPT [代码] [博客] [在线样例] [教程]
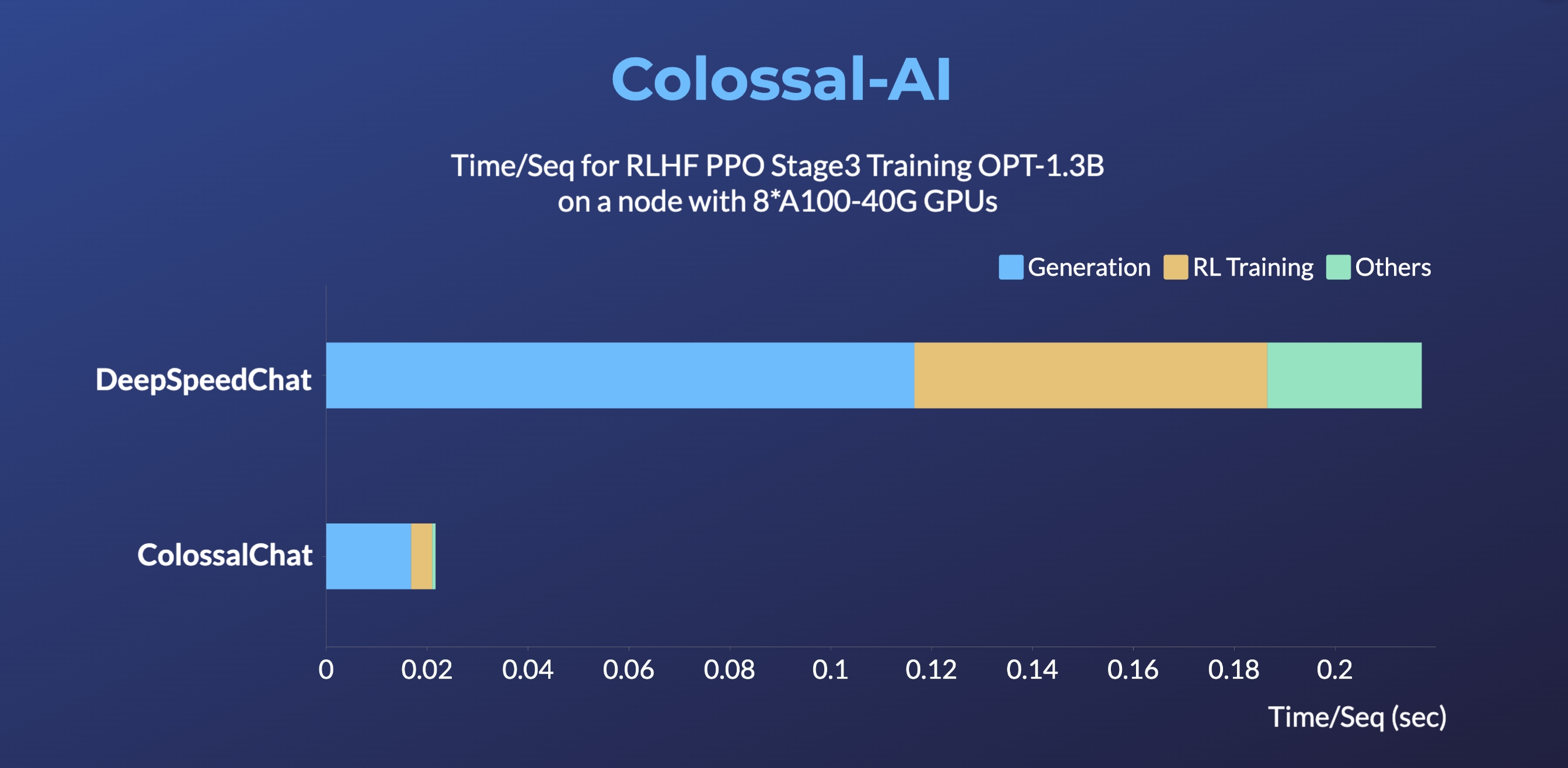
- 最高可提升RLHF PPO阶段3训练速度10倍

- 最高可提升单机训练速度7.73倍,单卡推理速度1.42倍
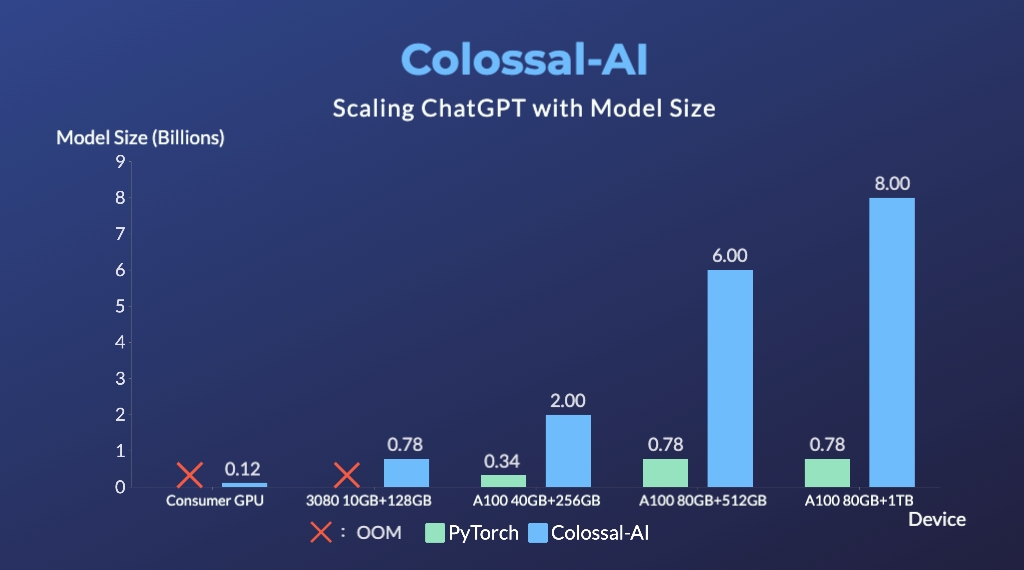
- 单卡模型容量最多提升10.3倍
- 最小demo训练流程最低仅需1.62GB显存 (任意消费级GPU)
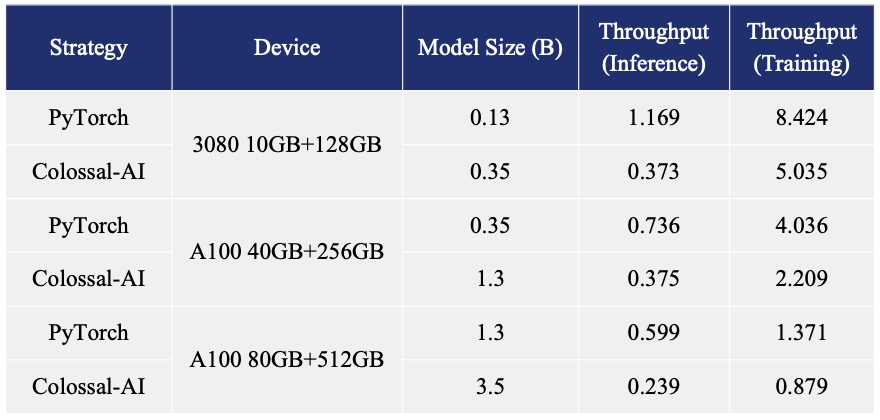
- 提升单卡的微调模型容量3.7倍
- 同时保持高速运行
AIGC
加速AIGC(AI内容生成)模型,如Stable Diffusion v1 和 Stable Diffusion v2
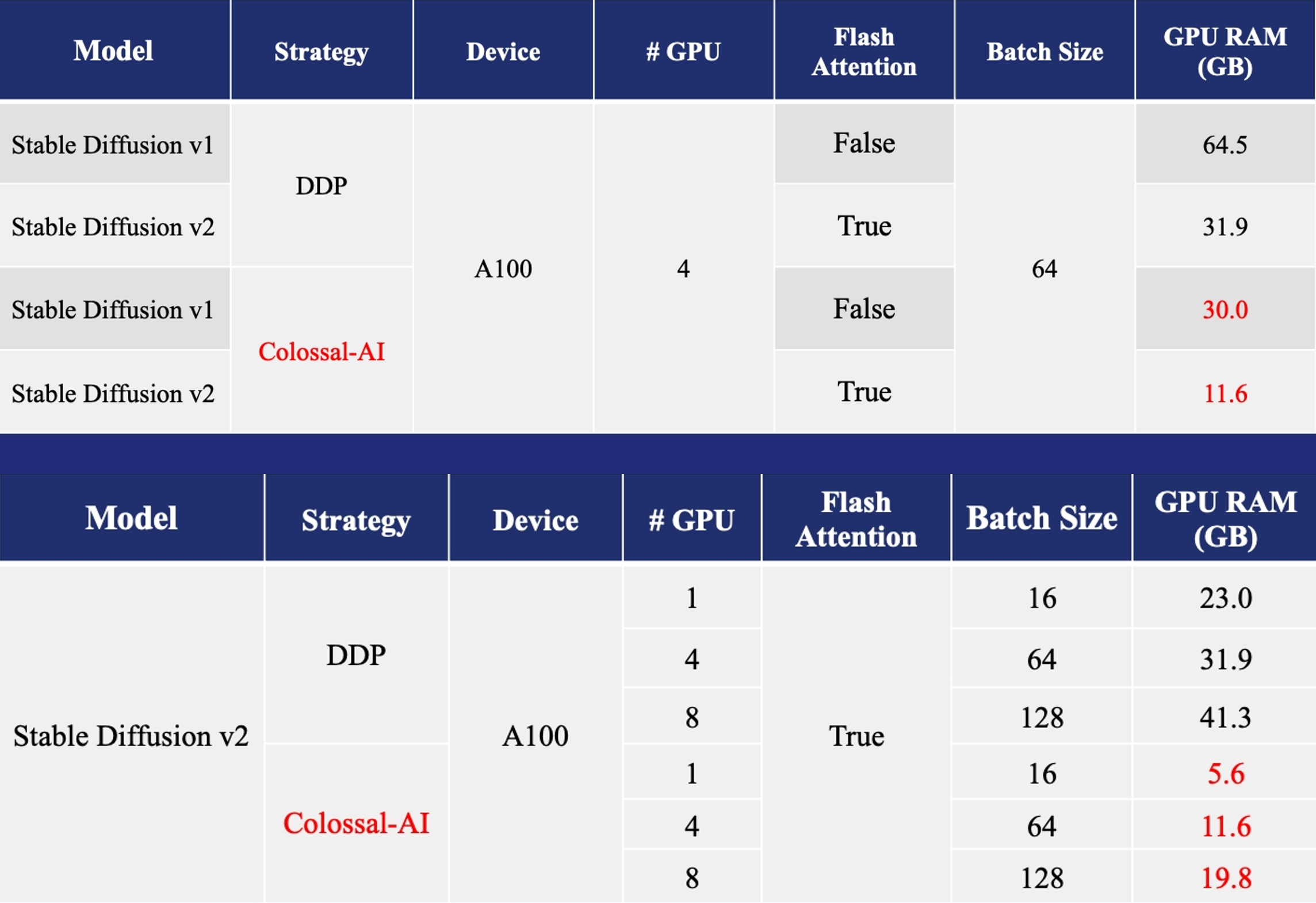
- 训练: 减少5.6倍显存消耗,硬件成本最高降低46倍(从A100到RTX3060)

- DreamBooth微调: 仅需3-5张目标主题图像个性化微调

- 推理: GPU推理显存消耗降低2.5倍
(返回顶端)
生物医药
加速 AlphaFold 蛋白质结构预测

- FastFold: 加速AlphaFold训练与推理、数据前处理、推理序列长度超过10000残基
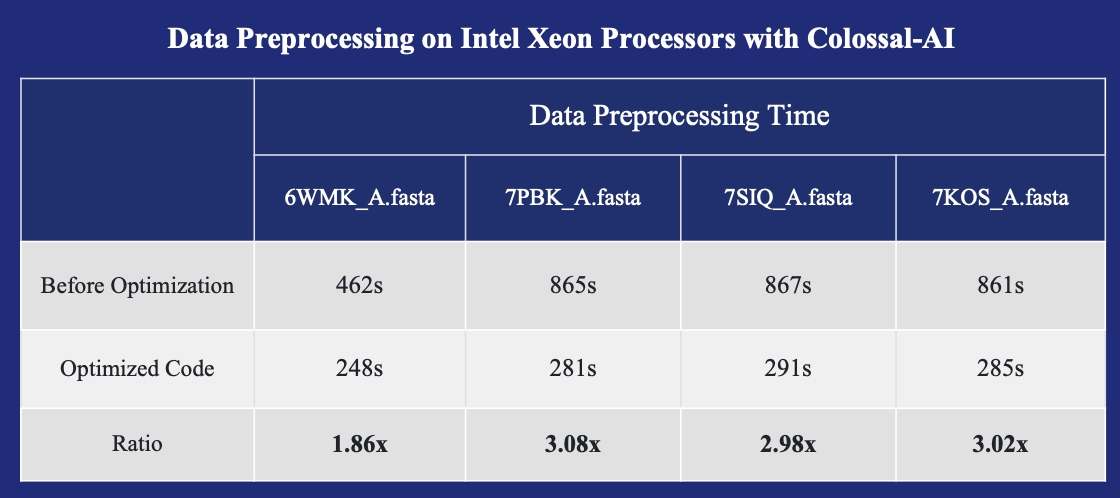
- FastFold with Intel: 3倍推理加速和39%成本节省
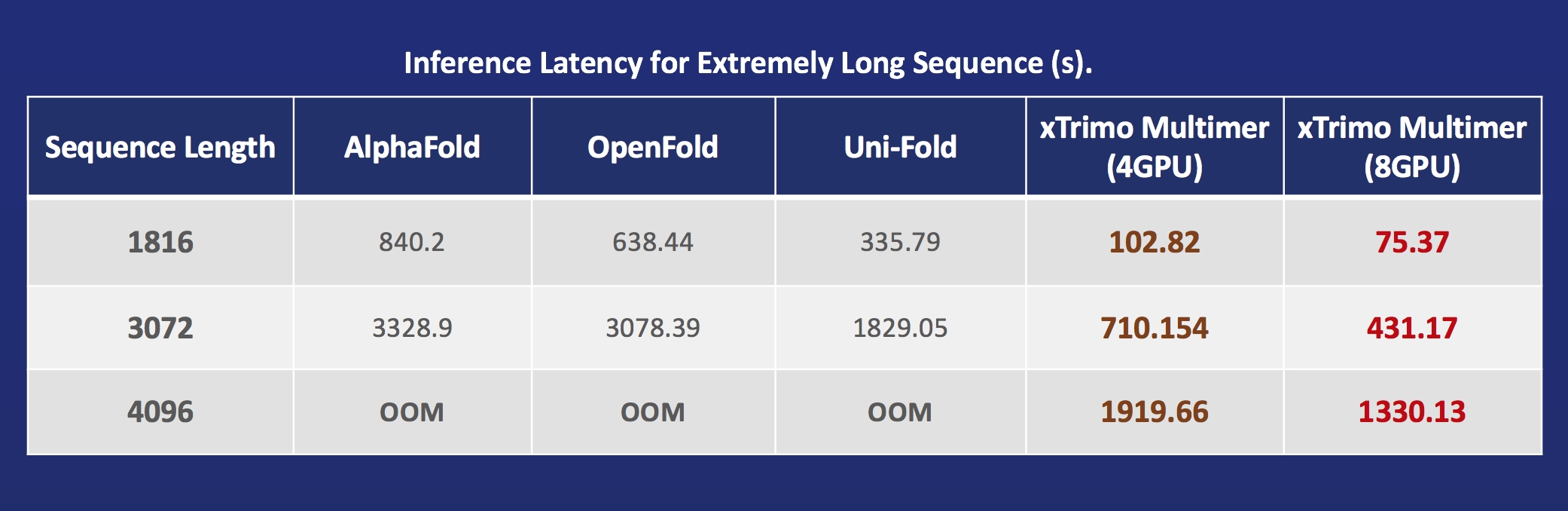
- xTrimoMultimer: 11倍加速蛋白质单体与复合物结构预测
(返回顶端)
并行训练样例展示
LLaMA3
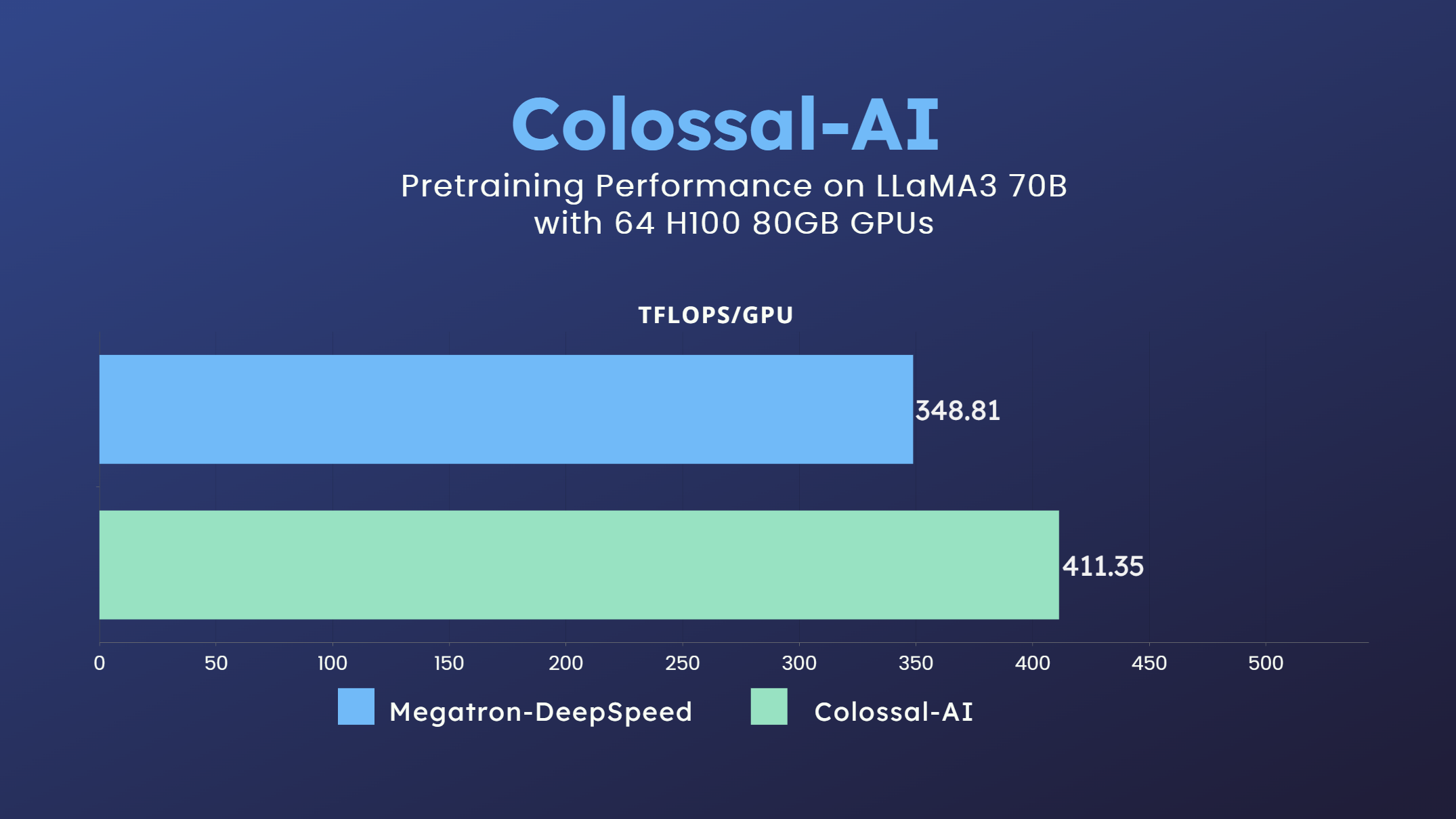
- 700亿参数LLaMA3训练加速18% [code]
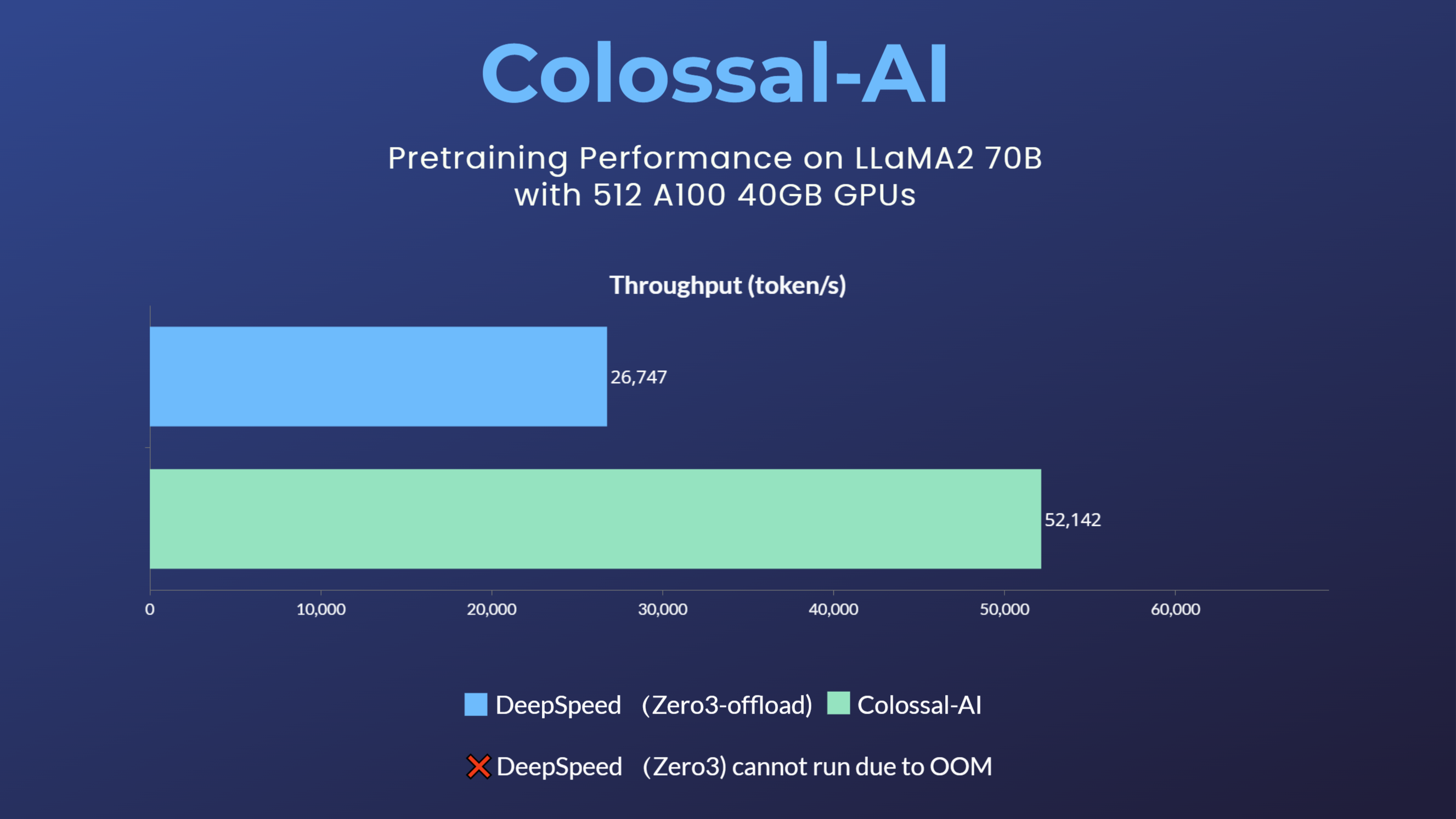
LLaMA2
LLaMA1
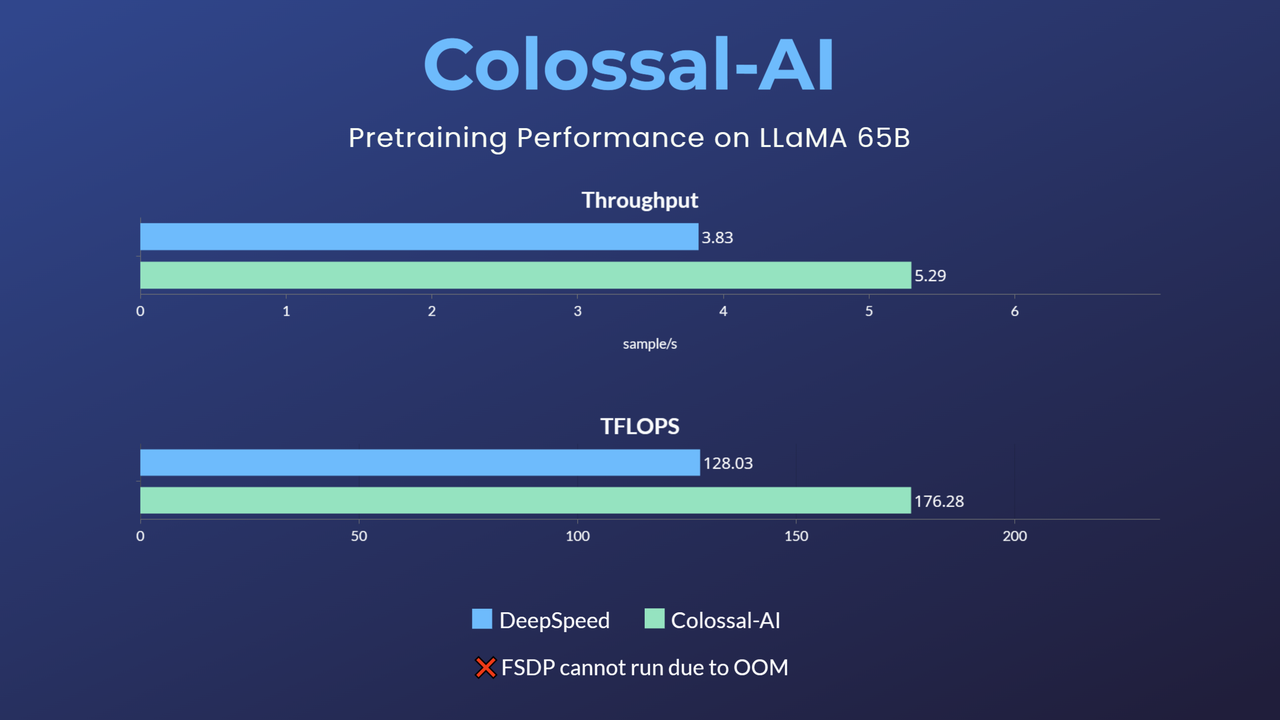
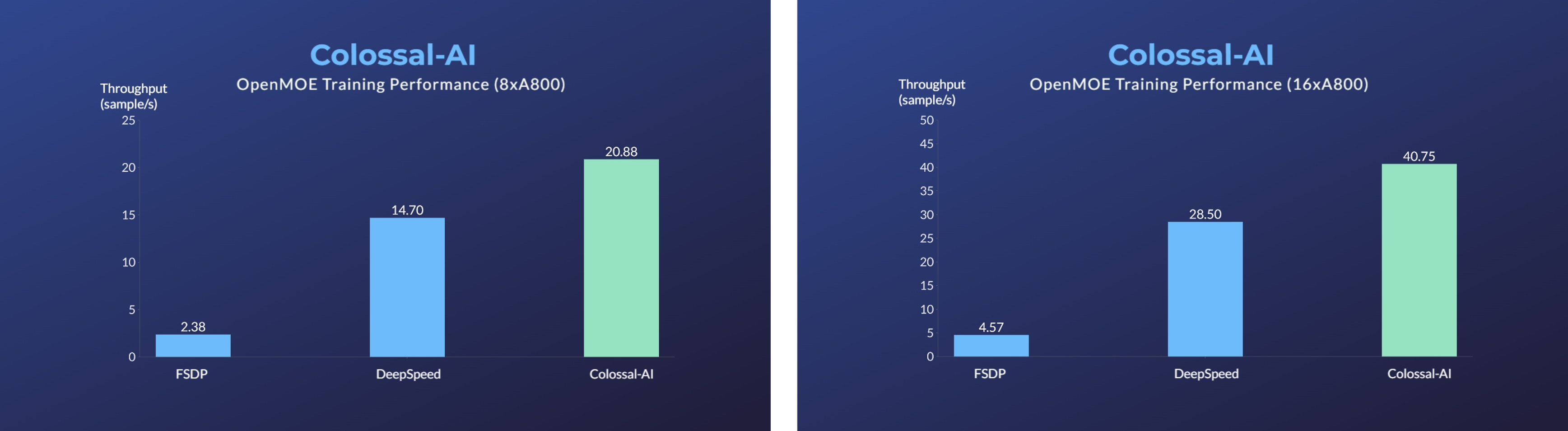
MoE
GPT-3
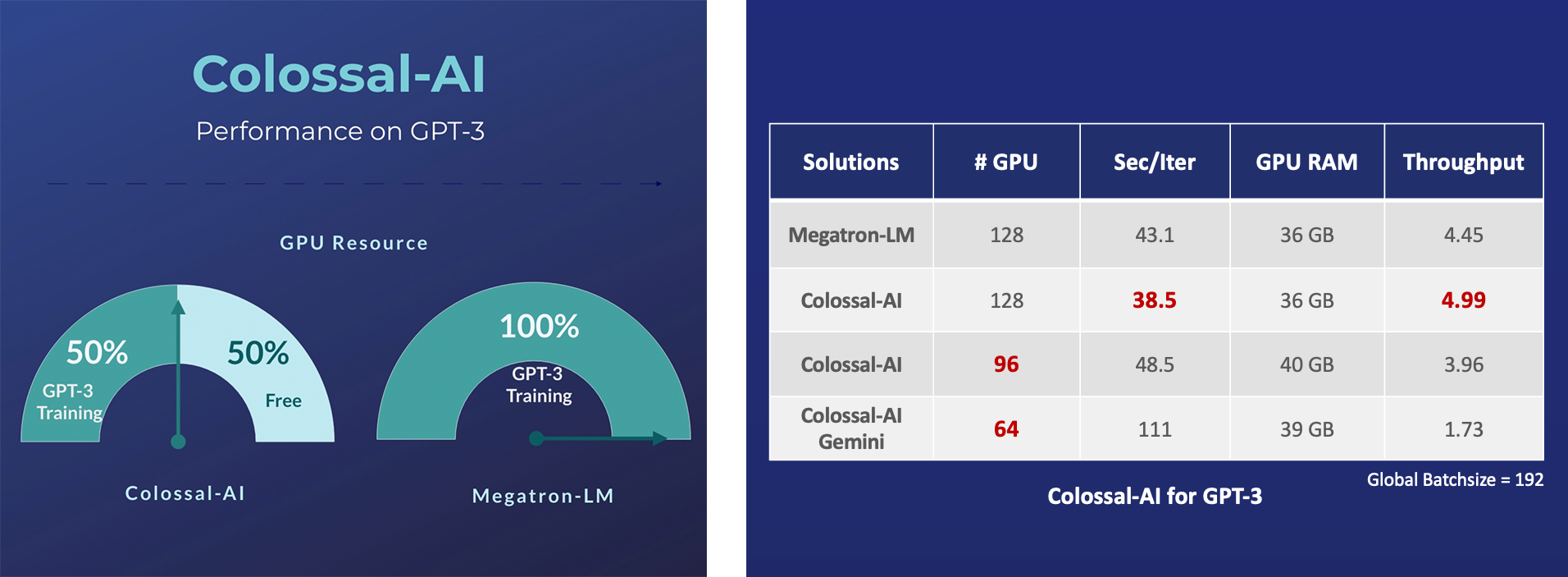
- 释放 50% GPU 资源占用, 或 10.7% 加速
GPT-2
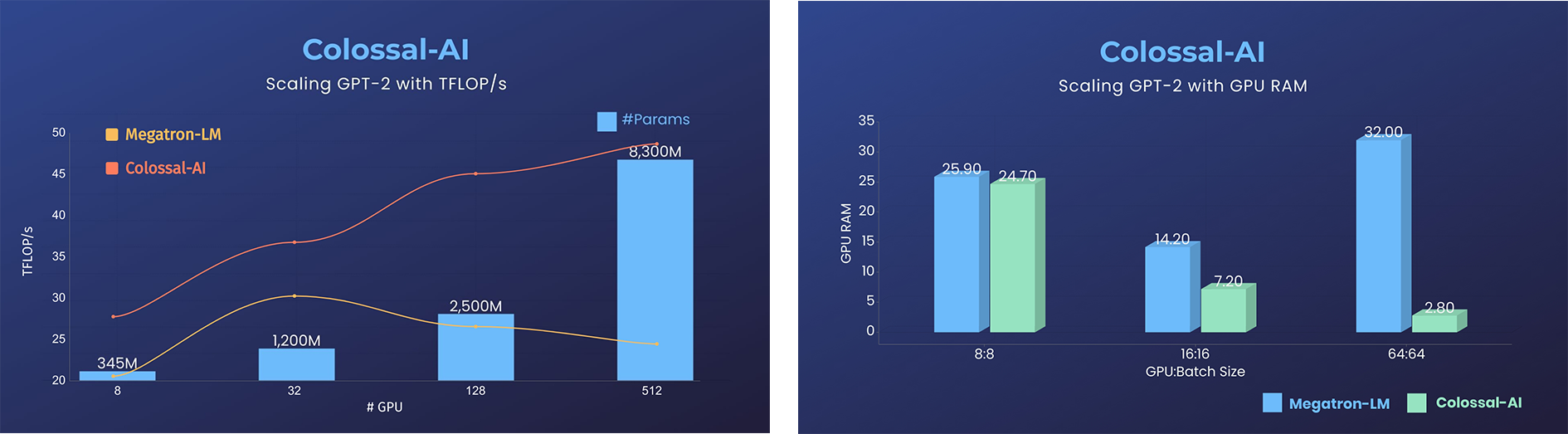
- 降低11倍 GPU 显存占用,或超线性扩展(张量并行)
GPT-2.png)
- 用相同的硬件训练24倍大的模型
- 超3倍的吞吐量
BERT
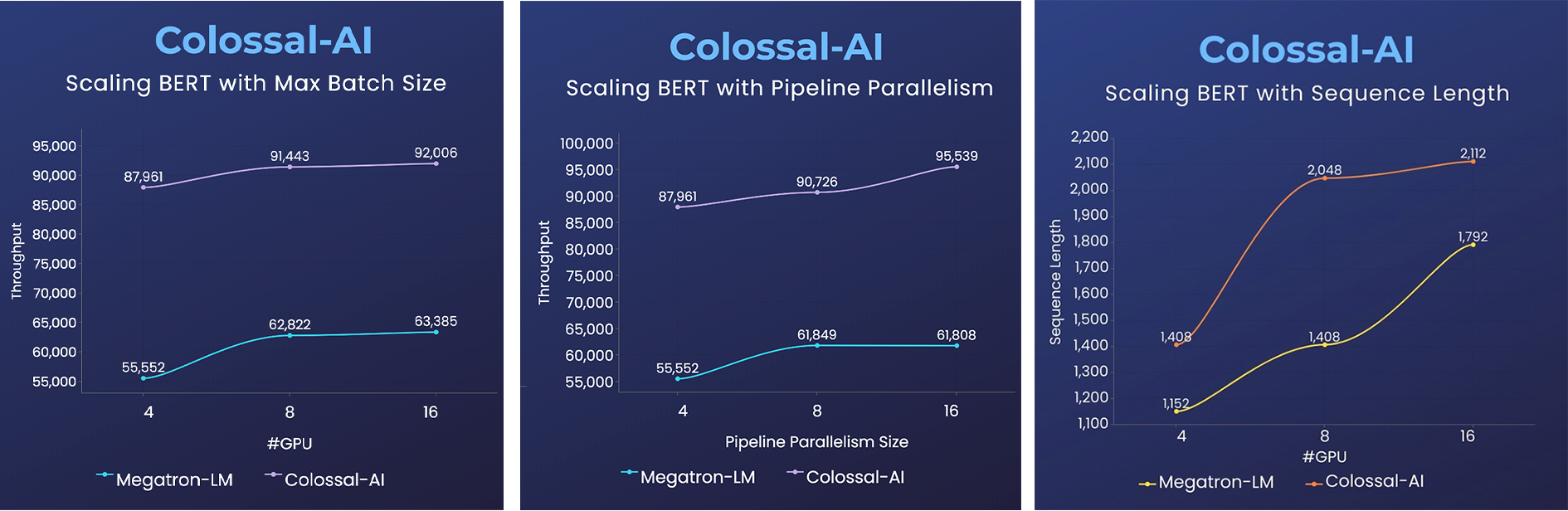
- 2倍训练速度,或1.5倍序列长度
PaLM
- PaLM-colossalai: 可扩展的谷歌 Pathways Language Model (PaLM) 实现。
OPT
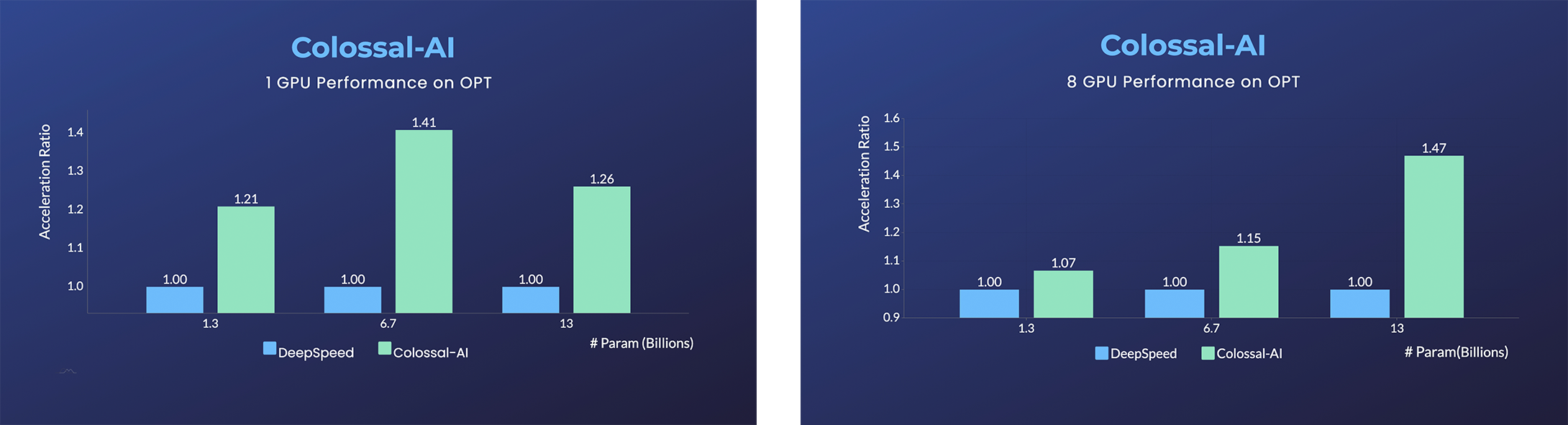
- Open Pretrained Transformer (OPT), 由Meta发布的1750亿语言模型,由于完全公开了预训练参数权重,因此促进了下游任务和应用部署的发展。
- 加速45%,仅用几行代码以低成本微调OPT。[样例] [在线推理]
ViT
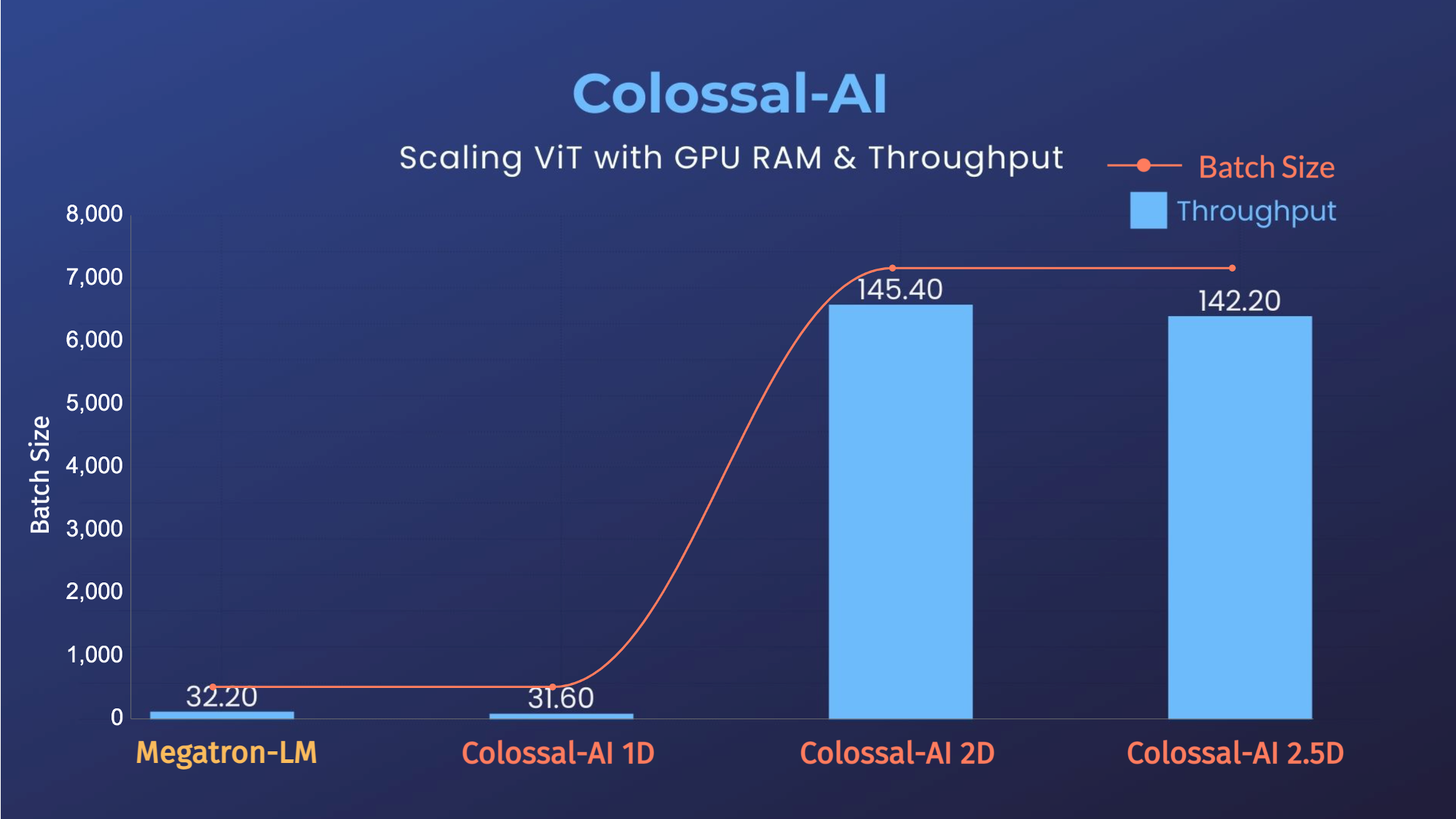
- 14倍批大小和5倍训练速度(张量并行=64)
推荐系统模型
- Cached Embedding, 使用软件Cache实现Embeddings,用更少GPU显存训练更大的模型。
(返回顶端)
单GPU训练样例展示
GPT-2
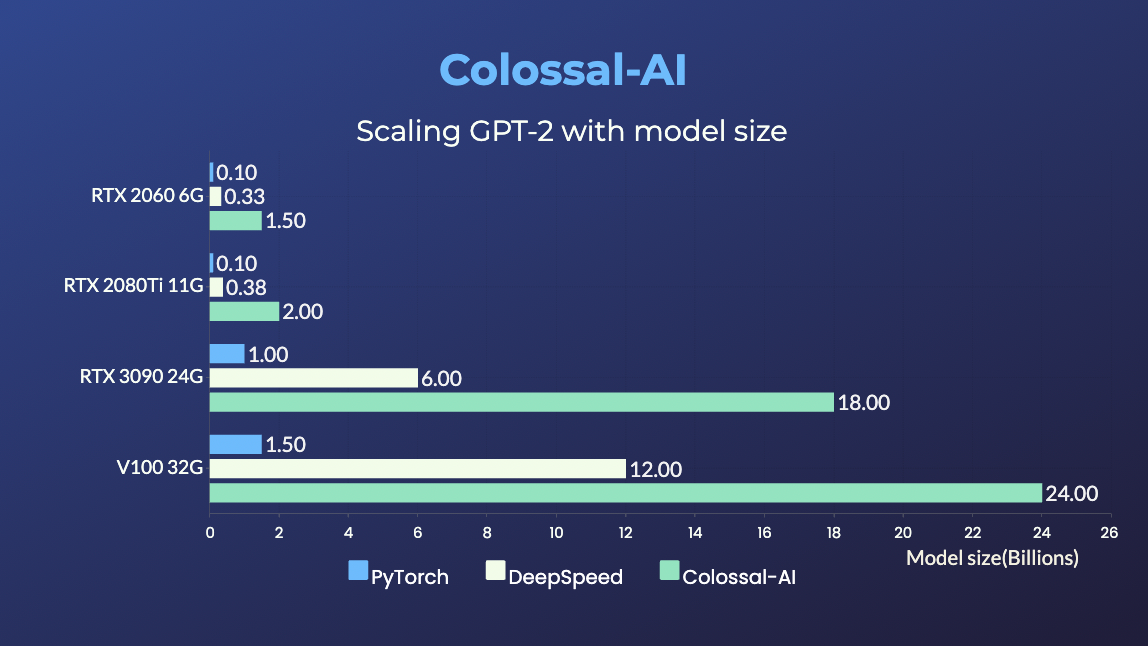
- 用相同的硬件训练20倍大的模型
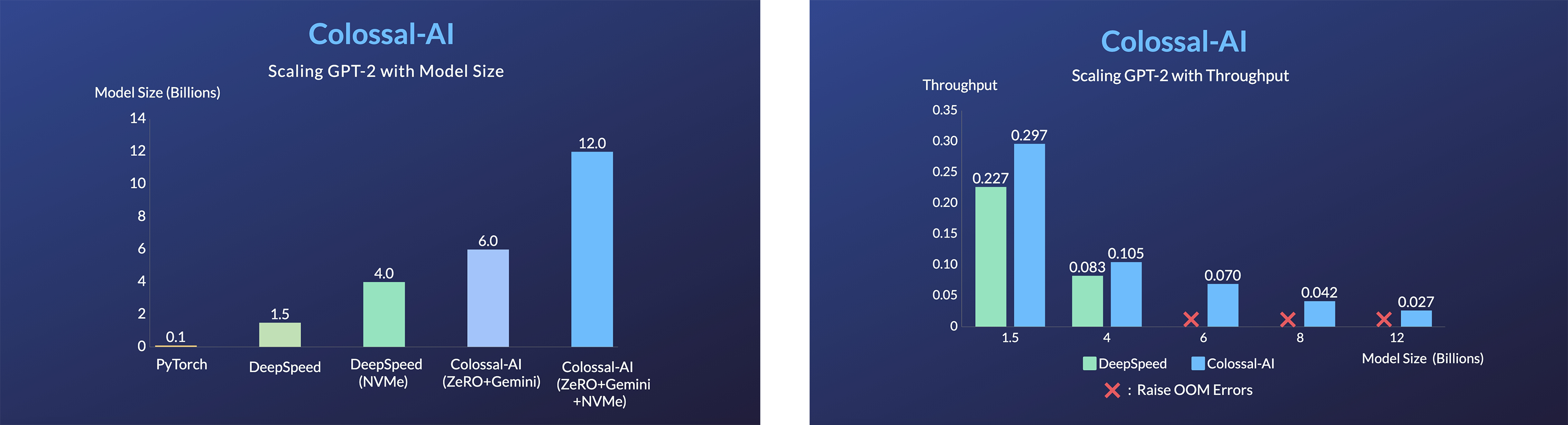
- 用相同的硬件训练120倍大的模型 (RTX 3080)
PaLM
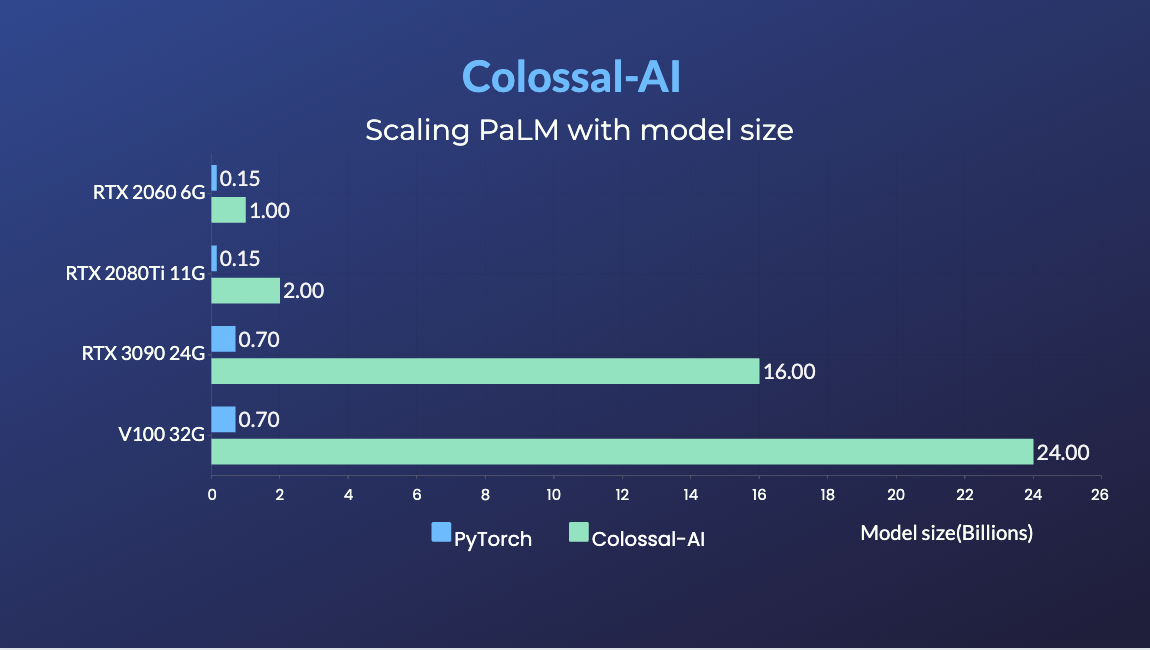
- 用相同的硬件训练34倍大的模型
(返回顶端)
推理
Grok-1
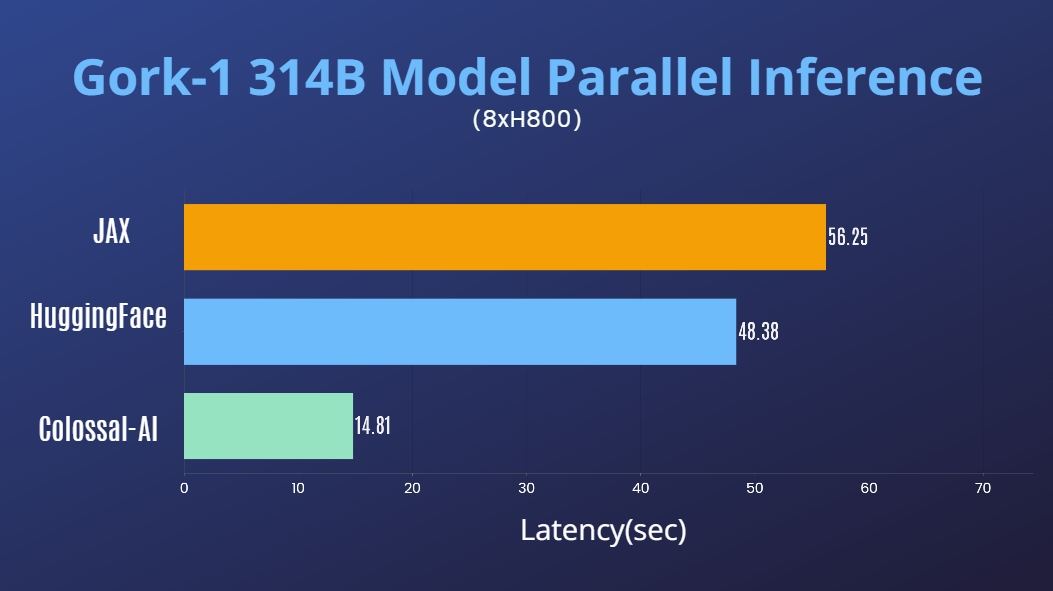
- 3140亿参数Grok-1推理加速3.8倍,高效易用的PyTorch+HuggingFace版
[代码] [博客] [HuggingFace Grok-1 PyTorch 模型权重] [ModelScope Grok-1 PyTorch 模型权重]
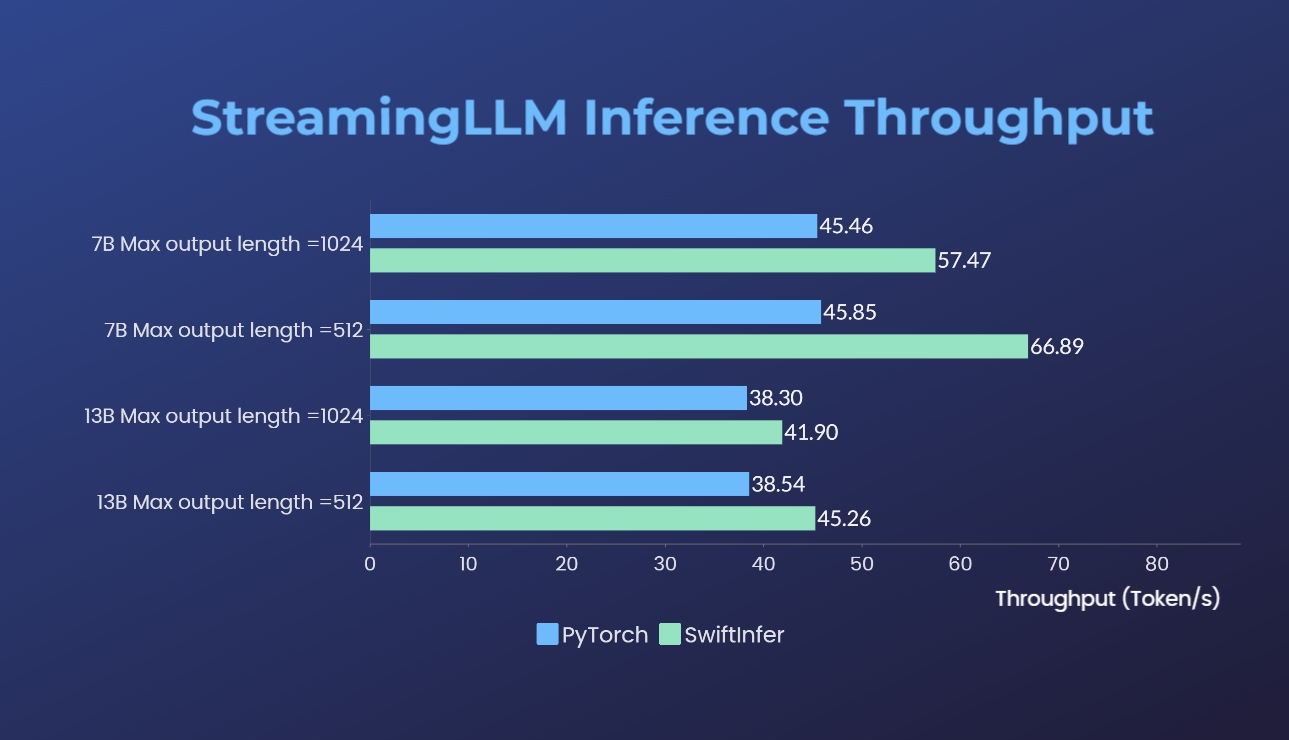
- SwiftInfer: 开源解决方案打破了多轮对话的 LLM 长度限制,推理性能提高了46%
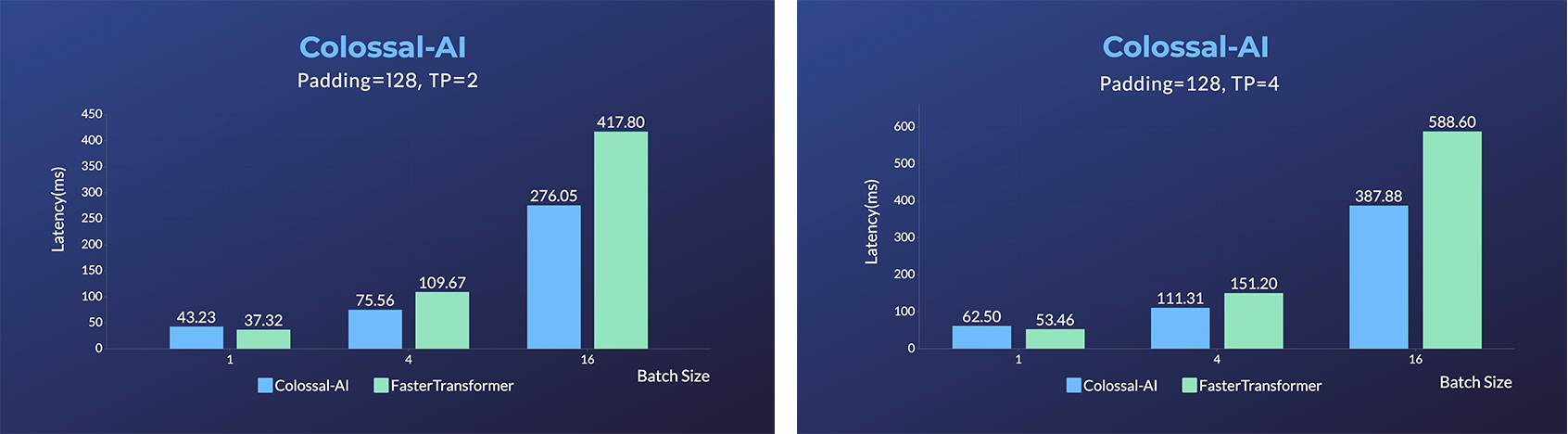
- Energon-AI :用相同的硬件推理加速50%
- OPT推理服务: 体验1750亿参数OPT在线推理服务
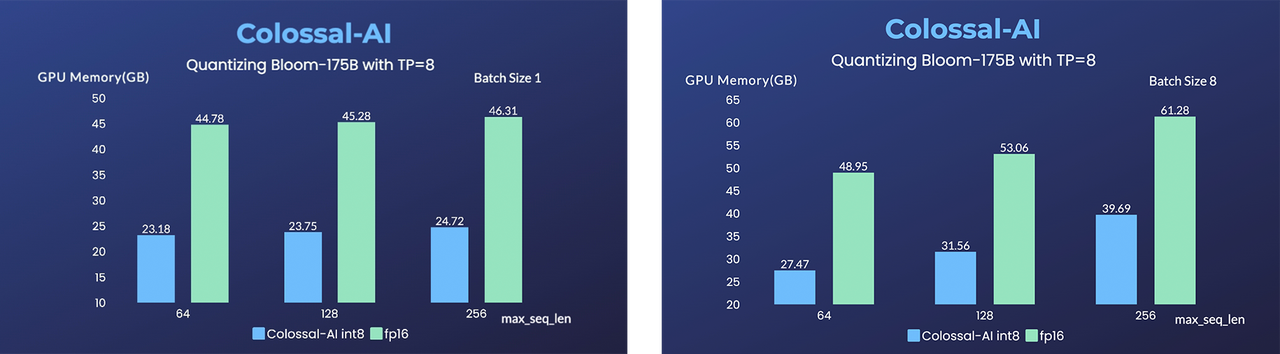
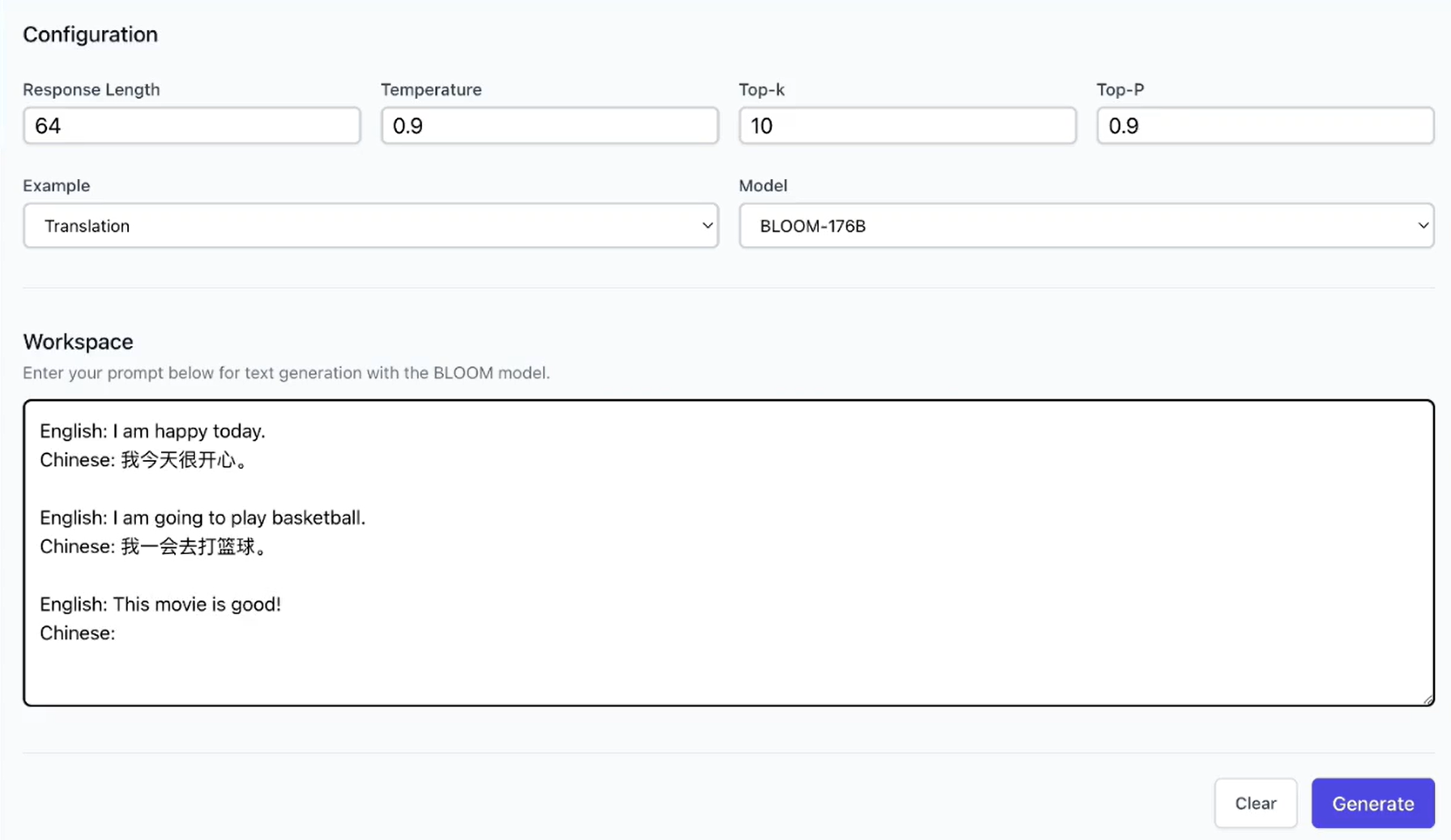
- BLOOM: 降低1760亿参数BLOOM模型部署推理成本超10倍
(返回顶端)
安装
环境要求:
- PyTorch >= 2.1
- Python >= 3.7
- CUDA >= 11.0
- NVIDIA GPU Compute Capability >= 7.0 (V100/RTX20 and higher)
- Linux OS
如果你遇到安装问题,可以向本项目 反馈。
从PyPI安装
您可以用下面的命令直接从PyPI上下载并安装Colossal-AI。我们默认不会安装PyTorch扩展包。
pip install colossalai
注:目前只支持Linux。
但是,如果你想在安装时就直接构建PyTorch扩展,您可以设置环境变量BUILD_EXT=1.
BUILD_EXT=1 pip install colossalai
否则,PyTorch扩展只会在你实际需要使用他们时在运行时里被构建。
与此同时,我们也每周定时发布Nightly版本,这能让你提前体验到新的feature和bug fix。你可以通过以下命令安装Nightly版本。
pip install colossalai-nightly
从源码安装
此文档将与版本库的主分支保持一致。如果您遇到任何问题,欢迎给我们提 issue :)
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# install dependency
pip install -r requirements/requirements.txt
# install colossalai
pip install .
我们默认在pip install时不安装PyTorch扩展,而是在运行时临时编译,如果你想要提前安装这些扩展的话(在使用融合优化器时会用到),可以使用一下命令。
BUILD_EXT=1 pip install .
(返回顶端)
使用 Docker
从DockerHub获取镜像
您可以直接从我们的DockerHub主页获取最新的镜像,每一次发布我们都会自动上传最新的镜像。
本地构建镜像
运行以下命令从我们提供的 docker 文件中建立 docker 镜像。
在Dockerfile里编译Colossal-AI需要有GPU支持,您需要将Nvidia Docker Runtime设置为默认的Runtime。更多信息可以点击这里。 我们推荐从项目主页直接下载Colossal-AI.
cd ColossalAI
docker build -t colossalai ./docker
运行以下命令从以交互式启动 docker 镜像.
docker run -ti --gpus all --rm --ipc=host colossalai bash
(返回顶端)
社区
欢迎通过论坛, Slack, 或微信加入 Colossal-AI 社区,与我们分享你的建议和问题。
做出贡献
参考社区的成功案例,如 BLOOM and Stable Diffusion 等, 无论是个人开发者,还是算力、数据、模型等可能合作方,都欢迎参与参与共建 Colossal-AI 社区,拥抱大模型时代!
您可通过以下方式联系或参与:
- 留下Star ⭐ 展现你的喜爱和支持,非常感谢!
- 发布 issue, 或者在GitHub根据贡献指南 提交一个 PR。
- 发送你的正式合作提案到 contact@hpcaitech.com
真诚感谢所有贡献者!
(返回顶端)
CI/CD
我们使用GitHub Actions来自动化大部分开发以及部署流程。如果想了解这些工作流是如何运行的,请查看这个文档.
引用我们
Colossal-AI项目受一些相关的项目启发而成立,一些项目是我们的开发者的科研项目,另一些来自于其他组织的科研工作。我们希望. 我们希望在参考文献列表中列出这些令人称赞的项目,以向开源社区和研究项目致谢。
你可以通过以下格式引用这个项目。
@article{bian2021colossal,
title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
journal={arXiv preprint arXiv:2110.14883},
year={2021}
}
Colossal-AI 已被NeurIPS, SC, AAAI, PPoPP, CVPR, ISC, NVIDIA GTC ,等顶级会议录取为官方教程。
(返回顶端)