mirror of https://github.com/hpcaitech/ColossalAI
5.0 KiB
5.0 KiB
Examples
Install requirements
pip install -r requirements.txt
Train the reward model (Stage 2)
Use these code to train your reward model.
# Take naive reward model training with opt-350m as example
python train_reward_model.py --pretrain "facebook/opt-350m" --model 'opt' --strategy naive
# use colossalai_zero2
torchrun --standalone --nproc_per_node=2 train_reward_model.py --pretrain "facebook/opt-350m" --model 'opt' --strategy colossalai_zero2
Features and tricks in RM training
- We support Anthropic/hh-rlhfandrm-static datasets.
- We support 2 kinds of loss_function named 'log_sig'(used by OpenAI) and 'log_exp'(used by Anthropic).
- We change the loss to valid_acc and pair_dist to monitor progress during training.
- We add special token to the end of the sequence to get better result.
- We use cosine-reducing lr-scheduler for RM training.
- We set value_head as 1 liner layer and initialize the weight of value_head using N(0,1/(d_model + 1)) distribution.
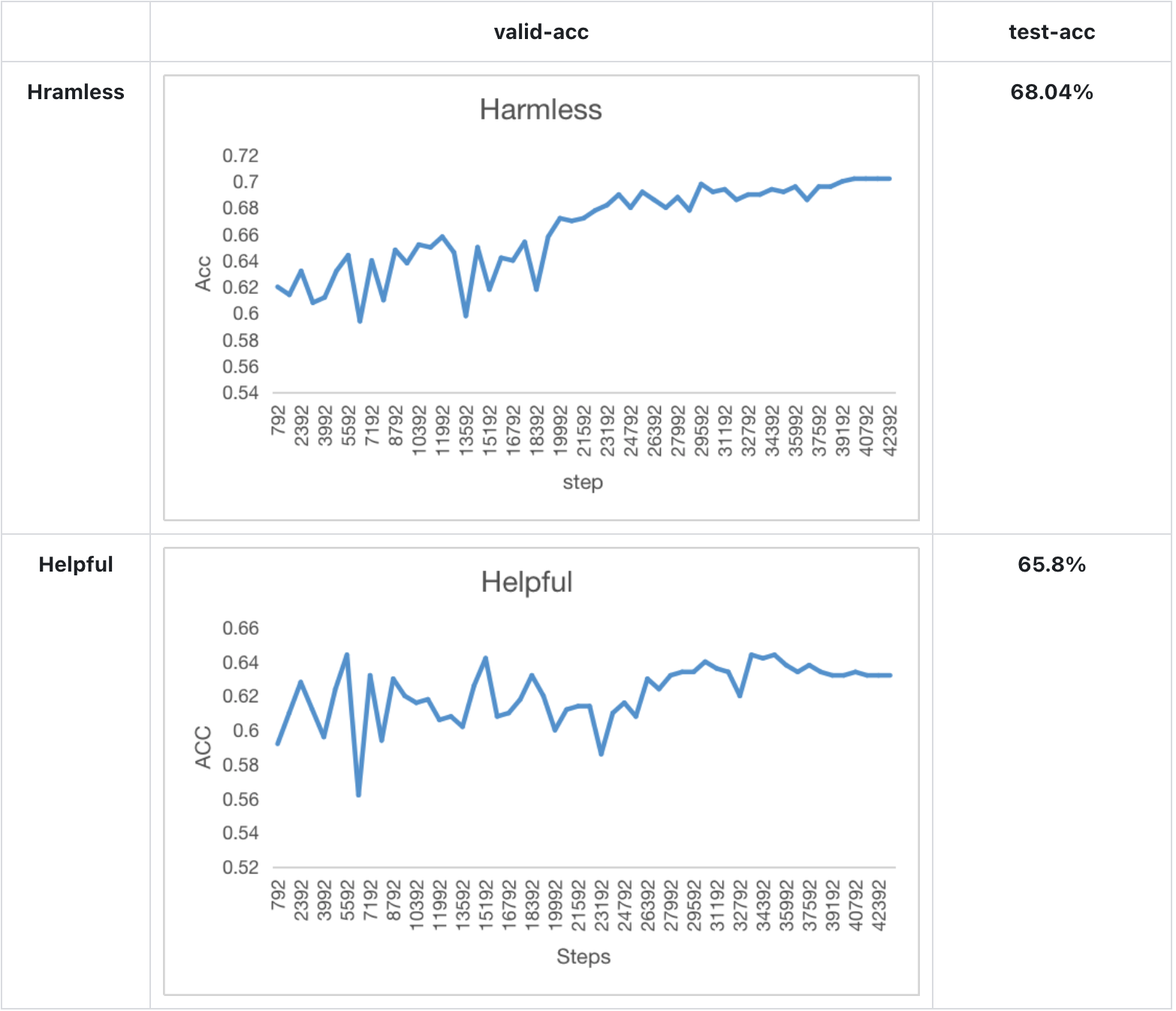
- We train a Bloom-560m reward model for 1 epoch and find the test acc of the model achieve the performance mentions in Anthropics paper.
Experiment result
Model performance in Anthropics paper:

Our training & test result of bloom-560m for 1 epoch:
Train with dummy prompt data (Stage 3)
This script supports 4 kinds of strategies:
- naive
- ddp
- colossalai_zero2
- colossalai_gemini
It uses random generated prompt data.
Naive strategy only support single GPU training:
python train_dummy.py --strategy naive
# display cli help
python train_dummy.py -h
DDP strategy and ColossalAI strategy support multi GPUs training:
# run DDP on 2 GPUs
torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy ddp
# run ColossalAI on 2 GPUs
torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
Train with real prompt data (Stage 3)
We use awesome-chatgpt-prompts as example dataset. It is a small dataset with hundreds of prompts.
You should download prompts.csv first.
This script also supports 4 strategies.
# display cli help
python train_dummy.py -h
# run naive on 1 GPU
python train_prompts.py prompts.csv --strategy naive
# run DDP on 2 GPUs
torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy ddp
# run ColossalAI on 2 GPUs
torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
Inference example(After Stage3)
We support naive inference demo after training.
# inference, using pretrain path to configure model
python inference.py --model_path <your actor model path> --model <your model type> --pretrain <your pretrain model name/path>
# example
python inference.py --model_path ./actor_checkpoint_prompts.pt --pretrain bigscience/bloom-560m --model bloom
Attention
The examples is just a demo for testing our progress of RM and PPO training.
data
- rm-static
- hh-rlhf
- openai/summarize_from_feedback
- openai/webgpt_comparisons
- Dahoas/instruct-synthetic-prompt-responses
Support Model
GPT
- GPT2-S (s)
- GPT2-M (m)
- GPT2-L (l)
- GPT2-XL (xl)
- GPT2-4B (4b)
- GPT2-6B (6b)
- GPT2-8B (8b)
- GPT2-10B (10b)
- GPT2-12B (12b)
- GPT2-15B (15b)
- GPT2-18B (18b)
- GPT2-20B (20b)
- GPT2-24B (24b)
- GPT2-28B (28b)
- GPT2-32B (32b)
- GPT2-36B (36b)
- GPT2-40B (40b)
- GPT3 (175b)
BLOOM
- BLOOM-560m
- BLOOM-1b1
- BLOOM-3b
- BLOOM-7b
- BLOOM-175b