|
|
8 months ago | |
|---|---|---|
| .. | ||
| community | 8 months ago | |
| data_preparation_scripts | 8 months ago | |
| inference | 8 months ago | |
| ray | 8 months ago | |
| training_scripts | 8 months ago | |
| README.md | 8 months ago | |
| requirements.txt | 8 months ago | |
README.md
Examples
Table of Contents
- Examples
- Table of Contents
- Install Requirements
- Get Start with ColossalRun
- Training Configuration
- RLHF Stage 1: Supervised Instruction Tuning
- RLHF Stage 2: Training Reward Model
- RLHF Stage 3: Proximal Policy Optimization
- PPO Training Results
- Note on PPO Training
- Alternative Option For RLHF: Direct Preference Optimization
- Hardware Requirements
- Inference example
- Attention
Install requirements
pip install -r requirements.txt
Get Start with ColossalRun
You can use colossalai run to launch multi-nodes training:
colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
train.py --OTHER_CONFIGURATIONS
Here is a sample hostfile:
hostname1
hostname2
hostname3
hostname4
Make sure master node can access all nodes (including itself) by ssh without password. Here are some other arguments.
- nnodes: number of nodes used in the training
- nproc-per-node: specifies the number of processes to be launched per node
- rdzv-endpoint: address of the host node
Training Configuration
This section gives a simple introduction on different training strategies that you can use and how to use them with our boosters and plugins to reduce training time and VRAM consumption. For more detail regarding training strategies, please refer to here. For details regarding boosters and plugins, please refer to here.
Gemini
This plugin implements Zero-3 with chunk-based and heterogeneous memory management. It can train large models without much loss in speed. It also does not support local gradient accumulation. More details can be found in Gemini Doc.
Below shows how to use the gemini in SFT training.
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
--pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--dataset ${dataset[@]} \
--save_interval 5000 \
--save_path $SAVE_DIR \
--config_file $CONFIG_FILE \
--plugin gemini \
--batch_size 4 \
--max_epochs 1 \
--accumulation_steps 1 \ # the gradient accumulation has to be disabled
--lr 2e-5 \
--max_len 2048 \
--use_wandb
Gemini-Auto
This option use gemini and will automatically offload tensors with low priority to cpu. It also does not support local gradient accumulation. More details can be found in Gemini Doc.
Below shows how to use the gemin-auto in SFT training.
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
--pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--dataset ${dataset[@]} \
--save_interval 5000 \
--save_path $SAVE_DIR \
--config_file $CONFIG_FILE \
--plugin gemini_auto \
--batch_size 4 \
--max_epochs 1 \
--accumulation_steps 1 \ # the gradient accumulation has to be disabled
--lr 2e-5 \
--max_len 2048 \
--use_wandb
Zero2
This option will distribute the optimizer parameters and the gradient to multiple GPUs and won't offload weights to cpu. It uses reduce and gather to synchronize gradients and weights. It does not support local gradient accumulation. Though you can accumulate gradient if you insist, it cannot reduce communication cost. That is to say, it's not a good idea to use Zero-2 with pipeline parallelism.
Below shows how to use the zero2 in SFT training.
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
--pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--dataset ${dataset[@]} \
--save_interval 5000 \
--save_path $SAVE_DIR \
--config_file $CONFIG_FILE \
--plugin zero2 \
--batch_size 4 \
--max_epochs 1 \
--accumulation_steps 4 \
--lr 2e-5 \
--max_len 2048 \
--use_wandb
Zero2CPU
This option will distribute the optimizer parameters and the gradient to multiple GPUs as well as offload parameters to cpu. It does not support local gradient accumulation. Though you can accumulate gradient if you insist, it cannot reduce communication cost.
Below shows how to use the zero2-cpu in SFT training.
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
--pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--dataset ${dataset[@]} \
--save_interval 5000 \
--save_path $SAVE_DIR \
--config_file $CONFIG_FILE \
--plugin zero2_cpu \
--batch_size 4 \
--max_epochs 1 \
--accumulation_steps 4 \
--lr 2e-5 \
--max_len 2048 \
--use_wandb
Tensor Parallelism
This option support Tensor Parallelism (TP). Note that if you want to use TP, zero and pipeline parallelism will be disabled. TP split large model weights/optimizer parameters/gradients into multiple small ones and distributes them to multiple GPUs, hence it is recommended to use TP when your model is large (e.g. 20B and above) or your training algorithm consumes a lot of memory (e.g. PPO).
Below shows how to use the TP in PPO training.
colossalai run --nproc_per_node 4 --hostfile hostfile --master_port 30039 train_ppo.py \
--pretrain $PRETRAINED_MODEL_PATH \
--rm_pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--rm_checkpoint_path $REWARD_MODEL_PATH \
--prompt_dataset ${prompt_dataset[@]} \
--pretrain_dataset ${ptx_dataset[@]} \
--ptx_batch_size 1 \
--ptx_coef 0.0 \
--plugin "zero2" \
--save_interval 200 \
--save_path $SAVE_DIR \
--num_episodes 2000 \
--num_collect_steps 4 \
--num_update_steps 1 \
--experience_batch_size 8 \
--train_batch_size 4 \
--accumulation_steps 8 \
--tp 4 \ # TP size, nproc_per_node must be divisible by it
--lr 9e-6 \
--mixed_precision "bf16" \
--grad_clip 1.0 \
--weight_decay 0.01 \
--warmup_steps 100 \
--grad_checkpoint \
--use_wandb
Gradient Checkpointing
This option saves VRAM consumption by selectively recomputing some of the intermediate value on-the-fly during the backward pass, rather than storing them in memory.
To enable gradient checkpointing, add --grad_checkpoint to your training script.
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
--pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--dataset ${dataset[@]} \
--save_interval 5000 \
--save_path $SAVE_DIR \
--config_file $CONFIG_FILE \
--plugin zero2_cpu \
--batch_size 4 \
--max_epochs 1 \
--accumulation_steps 4 \
--lr 2e-5 \
--max_len 2048 \
--grad_checkpoint \ # This enables gradient checkpointing
--use_wandb
Flash Attention
Details about flash attention can be found in the paper: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.
To enable flash attention, add --use_flash_attn to your training script.
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
--pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--dataset ${dataset[@]} \
--save_interval 5000 \
--save_path $SAVE_DIR \
--config_file $CONFIG_FILE \
--plugin zero2_cpu \
--batch_size 4 \
--max_epochs 1 \
--accumulation_steps 4 \
--lr 2e-5 \
--max_len 2048 \
--use_flash_attn \ # This enables flash attention
--use_wandb
Low Rank Adaption
Details about Low Rank Adaption (LoRA) can be found in the paper: LoRA: Low-Rank Adaptation of Large Language Models. It dramatically reduce the VRAM consumption at the cost of sacrifice model capability. It is suitable for training LLM with constrained resources.
To enable LoRA, set --lora_rank to a positive value (usually between 20 and 64).
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
--pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--dataset ${dataset[@]} \
--save_interval 5000 \
--save_path $SAVE_DIR \
--config_file $CONFIG_FILE \
--plugin zero2_cpu \
--batch_size 4 \
--max_epochs 1 \
--accumulation_steps 4 \
--lr 2e-5 \
--max_len 2048 \
--lora_rank 32 \ # This enables LoRA
--use_wandb
Other Training Arguments
- grad_clip: gradient larger than this value will be clipped.
- weight_decay: weight decay hyper-parameter.
- warmup_steps: number of warmup steps used in setting up the learning rate scheduler.
- pretrain: pretrain model path, weights will be loaded from this pretrained model unless checkpoint_path is provided.
- tokenizer_dir: specify where to load the tokenizer, if not provided, tokenizer will be loaded from pretrain model path.
- dataset: a list of strings, each is a path to a folder contains buffered dataset files in arrow format.
- checkpoint_path: if provided, will load weights from the checkpoint_path.
- config_file: path to store the training config file.
- save_dir: path to store the model checkpoints.
- max_length: input will be padded/truncate to max_length before feeding to the model.
- max_epochs: number of epoch to train.
- batch_size: training batch size.
- mixed_precision: precision to use in training. Support 'fp16' and 'bf16'. Note that some device may not support the 'bf16' option, please refer to Nvidia to check compatibility.
- save_interval: save the model weights as well as optimizer/scheduler states every save_interval steps/episodes.
- merge_lora_weights: whether to merge lora weights before saving the model
- lr: the learning rate used in training.
- accumulation_steps: accumulate gradient every accumulation_steps.
- log_dir: path to store the log.
- use_wandb: if this flag is up, you can view logs on wandb.
RLHF Training Stage1 - Supervised Instructs Tuning
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. Here's a detailed guide on how to SFT your LLM with ColossalChat:
Step 1: Data Collection
The first step in Stage 1 is to collect a dataset of human demonstrations of the following format.
[
{"messages":
[
{
"from": "human",
"content": "what are some pranks with a pen i can do?"
},
{
"from": "assistant",
"content": "Are you looking for practical joke ideas?"
},
...
]
},
...
]
Step 2: Preprocessing
Once you have collected your SFT dataset, you will need to preprocess it. This involves four steps: data cleaning, data deduplication, formatting and tokenization. In this section, we will focus on formatting and tokenization.
In this code we provide a flexible way for users to set the conversation template for formatting chat data using Huggingface's newest feature--- chat template. Please follow the following steps to define your chat template and preprocess your data.
-
Step 1: (Optional). Define your conversation template. You need to provide a conversation template config file similar to the config files under the ./config/conversation_template directory. This config should include the following fields.
{ "chat_template": (Optional), A string of chat_template used for formatting chat data. If not set (None), will use the default chat template of the provided tokenizer. If a path to a huggingface model or local model is provided, will use the chat_template of that model. To use a custom chat template, you need to manually set this field. For more details on how to write a chat template in Jinja format, please read https://huggingface.co/docs/transformers/main/chat_templating, "system_message": A string of system message to be added at the beginning of the prompt. If no is provided (None), no system message will be added, "stop_ids": (Optional), A list of string indicating the end of assistant's response during the rollout stage of PPO training. It's recommended to set this manually for PPO training. If not set, will set to tokenizer.eos_token_ids automatically, }On your first run of the data preparation script, you only need to define the "chat_template" (if you want to use custom chat template) and the "system message" (if you want to use a custom system message),
-
Step 2: Run the data preparation script--- prepare_sft_dataset.sh. Note that whether or not you have skipped the first step, you need to provide the path to the conversation template config file (via the conversation_template_config arg). If you skipped the first step, an auto-generated conversation template will be stored at the designated file path.
-
Step 3: (Optional) Check the correctness of the processed data. We provided an easy way for you to do a manual checking on the processed data by checking the "$SAVE_DIR/jsonl/part-XXXX.jsonl" files.
Finishing the above steps, you have converted the raw conversation to the designated chat format and tokenized the formatted conversation, calculate input_ids, labels, attention_masks and buffer those into binary dataset files under "$SAVE_DIR/arrow/part-XXXX" folders.
For example, our Colossal-LLaMA-2 format looks like,
<s> A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.
Human: <s> what are some pranks with a pen i can do?</s> Assistant: <s> Are you looking for practical joke ideas?</s>
...
Step 3: Training
Choose a suitable model architecture for your task. Note that your model should be compatible with the tokenizer that you used to tokenize the SFT dataset. You can run train_sft.sh to start a supervised instructs fine-tuning. Please refer to the training configuration section for details regarding supported training options.
RLHF Training Stage2 - Training Reward Model
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
Step 1: Data Collection
Below shows the preference dataset format used in training the reward model.
[
{"context": [
{
"from": "human",
"content": "Introduce butterflies species in Oregon."
}
]
"chosen": [
{
"from": "assistant",
"content": "About 150 species of butterflies live in Oregon, with about 100 species are moths..."
},
...
],
"rejected": [
{
"from": "assistant",
"content": "Are you interested in just the common butterflies? There are a few common ones which will be easy to find..."
},
...
]
},
...
]
Step 2: Preprocessing
Similar to the second step in the previous stage, we format the reward data into the same structured format as used in step 2 of the SFT stage. You can run prepare_preference_dataset.sh to prepare the preference data for reward model training.
Step 3: Training
You can run train_rm.sh to start the reward model training. Please refer to the training configuration section for details regarding supported training options.
Features and Tricks in RM Training
- We recommend using the Anthropic/hh-rlhfandrm-static datasets for training the reward model.
- We support 2 kinds of loss function named
log_sig(used by OpenAI) andlog_exp(used by Anthropic). - We log the training accuracy
train/acc,reward_chosenandreward_rejectedto monitor progress during training. - We use cosine-reducing lr-scheduler for RM training.
- We set value_head as 1 liner layer and initialize the weight of value_head using N(0,1/(d_model + 1)) distribution.
Note on Reward Model Training
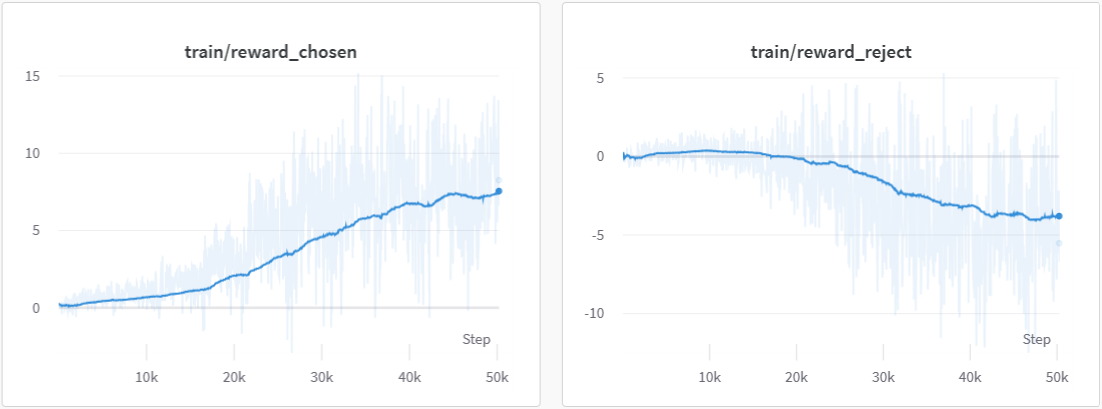
Before you move on the next stage, please check the following list to ensure that your reward model is stable and robust. You can check the reward chart and the accuracy chart on wandb.
- The mean reward for chosen data is much higher than those for rejected data
- The accuracy is larger than 0.5 by a significant margin (usually should be greater than 0.6)
- Optional:check the reward is positive for chosen data vice versa
Your training reward curves should look similar to the following charts.
RLHF Training Stage3 - Proximal Policy Optimization
In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimization (PPO), which is the most complex part of the training process:
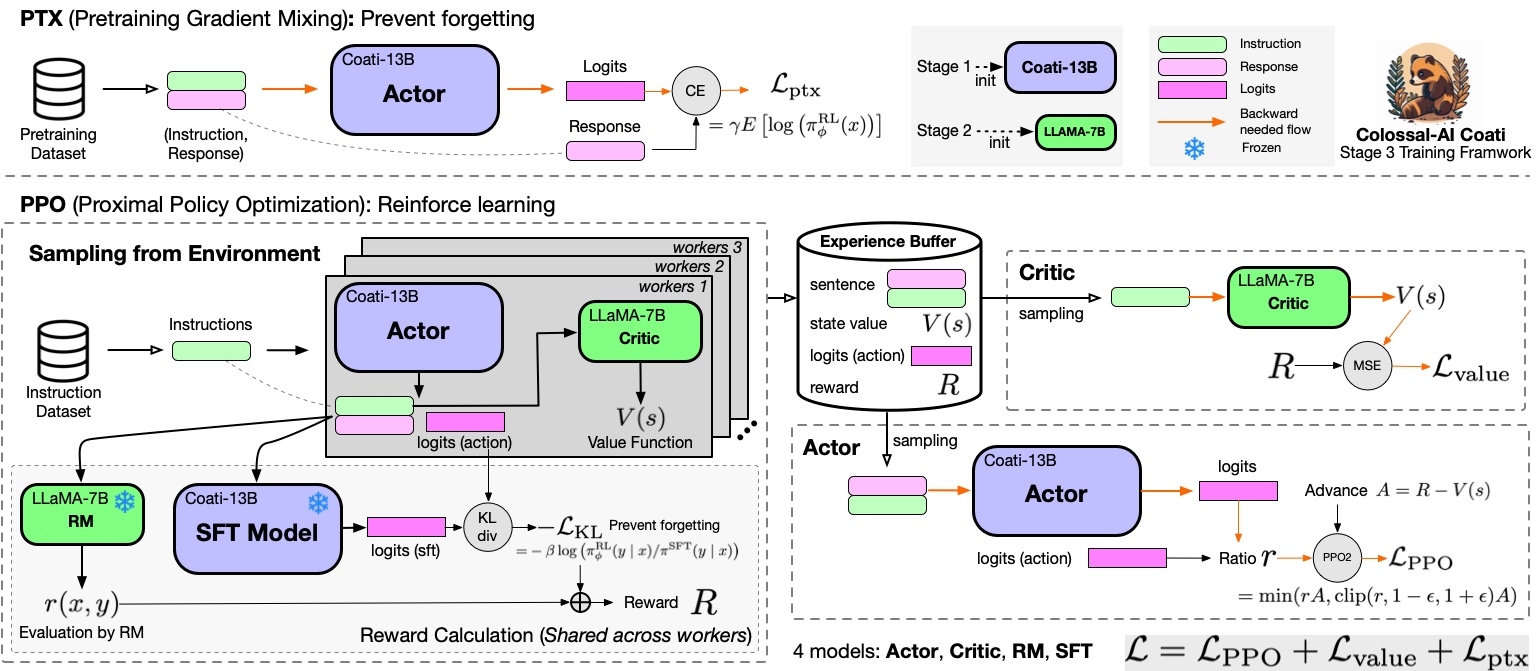
Step 1: Data Collection
PPO uses two kind of training data--- the prompt data and the pretrain data (optional). The first dataset is mandatory, data samples within the prompt dataset ends with a line from "human" and thus the "assistant" needs to generate a response to answer to the "human". Note that you can still use conversation that ends with a line from the "assistant", in that case, the last line will be dropped. Here is an example of the prompt dataset format.
[
{"messages":
[
{
"from": "human",
"content": "what are some pranks with a pen i can do?"
}
...
]
},
]
The second dataset--- pretrained dataset is optional, provide it if you want to use the ptx loss introduced in the InstructGPT paper. It follows the following format.
[
{
"source": "", # system instruction
"Target": "Provide a list of the top 10 most popular mobile games in Asia\nThe top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved",
},
...
]
Step 2: Preprocessing
To prepare the prompt dataset for PPO training, simply run prepare_prompt_dataset.sh
You can use the SFT dataset you prepared in the SFT stage or prepare a new one from different source for the ptx dataset. The ptx data is used to calculate ptx loss, which stablize the training according to the InstructGPT paper.
Step 3: Training
You can run the train_ppo.sh to start PPO training. Here are some unique arguments for PPO, please refer to the training configuration section for other training configuration. Please refer to the training configuration section for details regarding supported training options.
--pretrain $PRETRAINED_MODEL_PATH \
--rm_pretrain $PRETRAINED_MODEL_PATH \ # reward model architectural
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--rm_checkpoint_path $REWARD_MODEL_PATH \ # reward model checkpoint path
--prompt_dataset ${prompt_dataset[@]} \ # List of string, prompt dataset
--conversation_template_config $CONVERSATION_TEMPLATE_CONFIG_PATH \ # path to the conversation template config file
--pretrain_dataset ${ptx_dataset[@]} \ # List of string, the sft dataset
--ptx_batch_size 1 \ # batch size for calculate ptx loss
--ptx_coef 0.0 \ # none-zero if ptx loss is enable
--num_episodes 2000 \ # number of episodes to train
--num_collect_steps 1 \
--num_update_steps 1 \
--experience_batch_size 8 \
--train_batch_size 4 \
--accumulation_steps 2
Each episode has two phases, the collect phase and the update phase. During the collect phase, we will collect experiences (answers generated by actor), store those in ExperienceBuffer. Then data in ExperienceBuffer is used during the update phase to update parameter of actor and critic.
- Without tensor parallelism,
experience buffer size
= num_process * num_collect_steps * experience_batch_size
= train_batch_size * accumulation_steps * num_process
- With tensor parallelism,
num_tp_group = num_process / tp
experience buffer size
= num_tp_group * num_collect_steps * experience_batch_size
= train_batch_size * accumulation_steps * num_tp_group
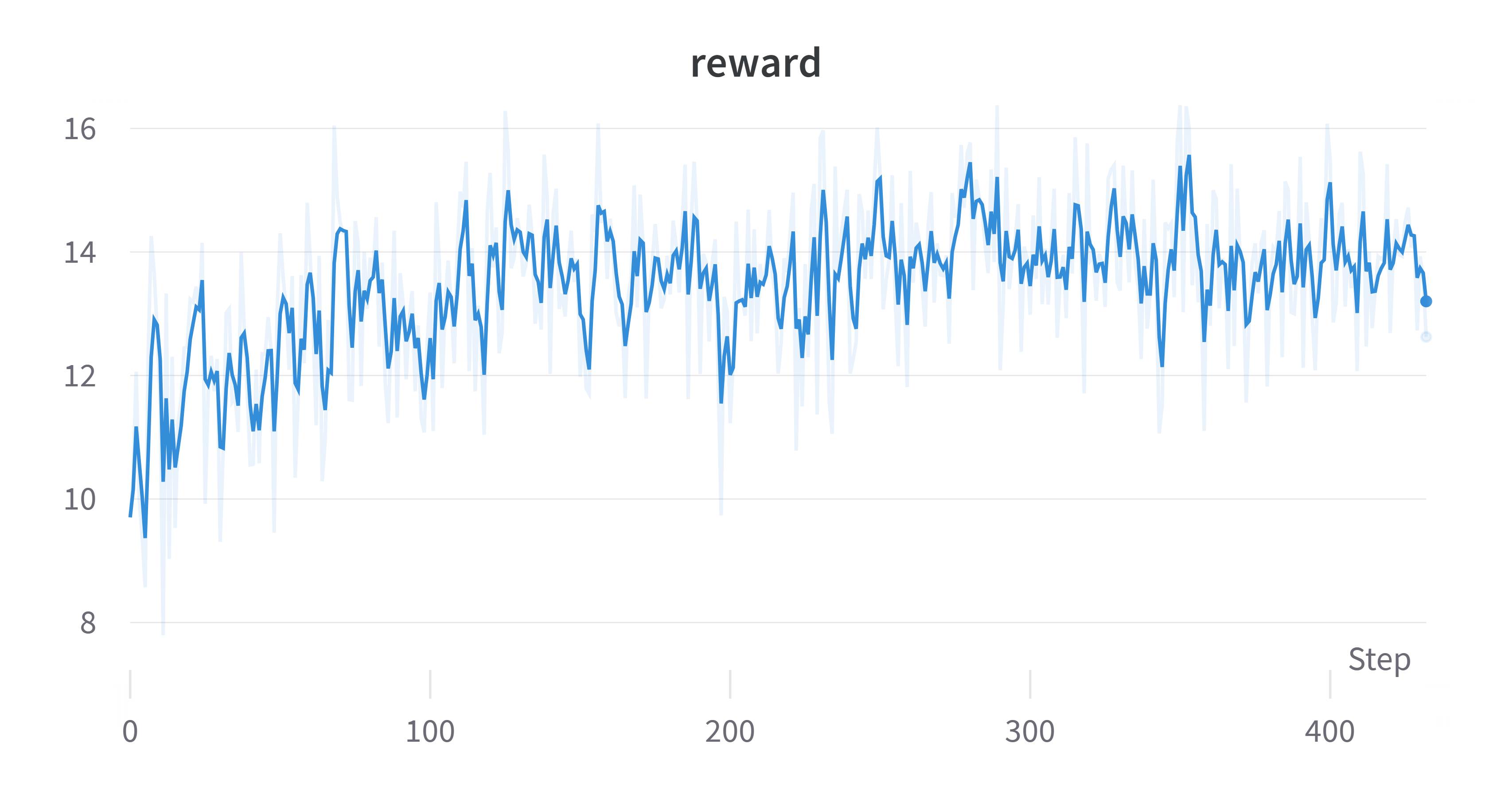
Sample Training Results Using Default Script
Reward
Note on PPO Training
Q1: My reward is negative
Answer: Check your reward model trained in stage 1. If the reward model only generate negative reward, we actually will expect a negative reward. However, even though the reward is negative, the reward should go up.
Q2: My actor loss is negative
Answer: This is normal for actor loss as PPO doesn't restrict the actor loss to be positive.
Q3: My reward doesn't go up (decreases)
Answer: The causes to this problem are two-fold. Check your reward model, make sure that it gives positive and strong reward for good cases and negative, strong reward for bad responses. You should also try different hyperparameter settings.
Q4: Generation is garbage
Answer: Yes, this happens and is well documented by other implementations. After training for too many episodes, the actor gradually deviate from its original state, which may leads to decrease in language modeling capabilities. A way to fix this is to add supervised loss during PPO. Set ptx_coef to a none-zero value (between 0 and 1), which balances PPO loss and sft loss.
Alternative Option For RLHF: Direct Preference Optimization
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in the paper (available at https://arxiv.org/abs/2305.18290), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO.
DPO Training Stage1 - Supervised Instructs Tuning
Please refer the sft section in the PPO part.
DPO Training Stage2 - DPO Training
Step 1: Data Collection & Preparation
For DPO training, you only need the preference dataset. Please follow the instruction in the preference dataset preparation section to prepare the preference data for DPO training.
Step 2: Training
You can run the train_dpo.sh to start DPO training. Please refer to the training configuration section for details regarding supported training options.
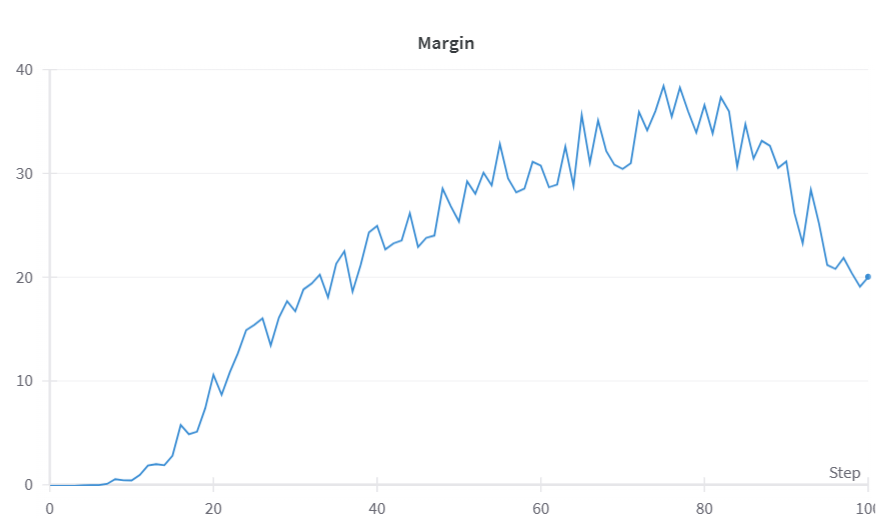
DPO Result
Hardware Requirements
For PPO, we suggest using Tensor Parallelism. The following table shows the VRAM consumption of training a 7B model on a dummy dataset with 2048 sequence length and 512 layout length with different tp_size (equal to the number of GPUs). In this experiment, we use H800 GPU with 80GB VRAM.
| PPO | tp=8 | tp=4 |
|---|---|---|
| bs=1 | 18485.19 MB | 42934.45 MB |
| bs=4 | 25585.65 MB | 42941.93 MB |
| bs=16 | 41408.28 MB | 56778.97 MB |
| bs=30 | 64047.42 MB | failed |
For DPO, we recommend using zero2 or zero2-cpu. We tested the VRAM consumption on a dummy dataset with 2048 sequence length.
- 1 H800 GPU
- zero2-cpu, batch size=2, VRAM Usage=49873.90 MB
- zero2-cpu, batch size=4, VRAM Usage=60998.22 MB
- 4 H800 GPUs
- zero2, batch size=4, VRAM Usage=67544.47 MB
Inference example
We support different inference options, including int8 and int4 quantization.
For details, see inference/.
Attention
The examples are demos for the whole training process. You need to change the hyper-parameters to reach great performance.