2.1 KiB
NVMe offload
Author: Hongxin Liu
Prerequisite:
Introduction
If a model has N parameters, when using Adam, it has 8N optimizer states. For billion-scale models, optimizer states take at least 32 GB memory. GPU memory limits the model scale we can train, which is called GPU memory wall. If we offload optimizer states to the disk, we can break through GPU memory wall.
We implement a user-friendly and efficient asynchronous Tensor I/O library: TensorNVMe. With this library, we can simply implement NVMe offload.
This library is compatible with all kinds of disk (HDD, SATA SSD, and NVMe SSD). As I/O bandwidth of HDD or SATA SSD is low, it's recommended to use this lib only on NVMe disk.
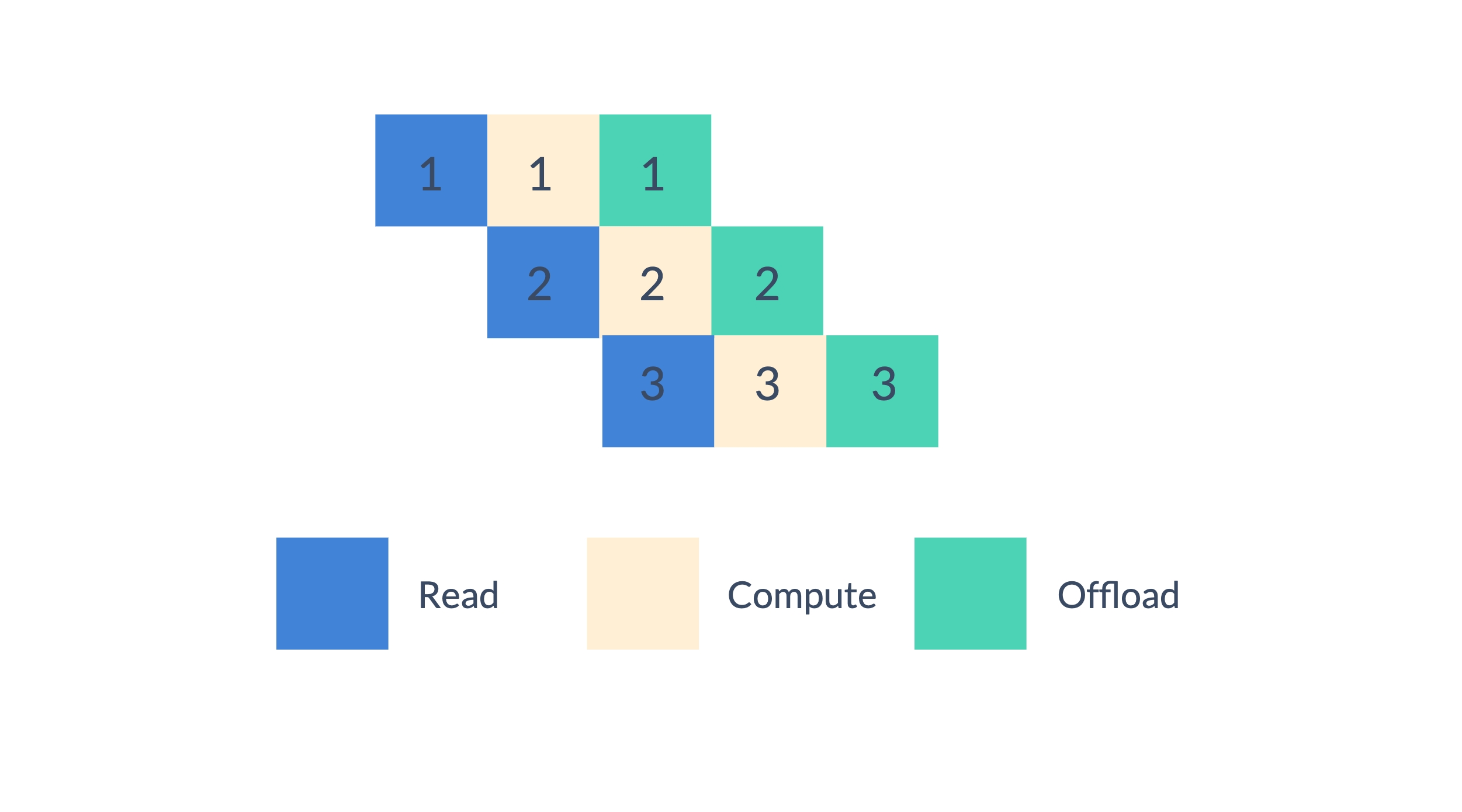
When optimizing a parameter, we can divide the optimization process into three stages: read, compute and offload. We perform the optimization process in a pipelined fashion, which can overlap computation and I/O.
Usage
First, please make sure you installed TensorNVMe:
pip install packaging
pip install tensornvme
We implement NVMe offload of optimizer states for Adam (CPUAdam and HybridAdam).
from colossalai.nn.optimizer import CPUAdam, HybridAdam
optimizer = HybridAdam(model.parameters(), lr=1e-3, nvme_offload_fraction=1.0, nvme_offload_dir='./')
nvme_offload_fraction is the fraction of optimizer states to be offloaded to NVMe. nvme_offload_dir is the directory to save NVMe offload files. If nvme_offload_dir is None, a random temporary directory will be used.
It's compatible with all parallel methods in ColossalAI.