14 KiB
Auto Mixed Precision Training
Author: Chuanrui Wang, Shenggui Li, Yongbin Li
Prerequisite
Example Code
Related Paper
Introduction
AMP stands for automatic mixed precision training. In Colossal-AI, we have incorporated different implementations of mixed precision training:
- torch.cuda.amp
- apex.amp
- naive amp
| Colossal-AI | support tensor parallel | support pipeline parallel | fp16 extent |
|---|---|---|---|
| AMP_TYPE.TORCH | ✅ | ❌ | Model parameters, activation, gradients are downcast to fp16 during forward and backward propagation |
| AMP_TYPE.APEX | ❌ | ❌ | More fine-grained, we can choose opt_level O0, O1, O2, O3 |
| AMP_TYPE.NAIVE | ✅ | ✅ | Model parameters, forward and backward operations are all downcast to fp16 |
The first two rely on the original implementation of PyTorch (version 1.6 and above) and NVIDIA Apex. The last method is similar to Apex O2 level. Among these methods, apex AMP is not compatible with tensor parallelism. This is because that tensors are split across devices in tensor parallelism, thus, it is required to communicate among different processes to check if inf or nan occurs in the whole model weights. We modified the torch amp implementation so that it is compatible with tensor parallelism now.
❌️ fp16 and zero configuration are not compatible
⚠️ Pipeline only support naive AMP currently
We recommend you to use torch AMP as it generally gives better accuracy than naive AMP if no pipeline is used.
Table of Contents
In this tutorial we will cover:
- AMP introduction
- AMP in Colossal-AI
- Hands-on Practice
AMP Introduction
Automatic Mixed Precision training is a mixture of FP16 and FP32 training.
Half-precision float point format (FP16) has lower arithmetic complexity and higher compute efficiency. Besides, fp16 requires half of the storage needed by fp32 and saves memory & network bandwidth, which makes more memory available for large batch size and model size.
However, there are other operations, like reductions, which require the dynamic range of fp32 to avoid numeric overflow/underflow. That's the reason why we introduce automatic mixed precision, attempting to match each operation to its appropriate data type, which can reduce the memory footprint and augment training efficiency.
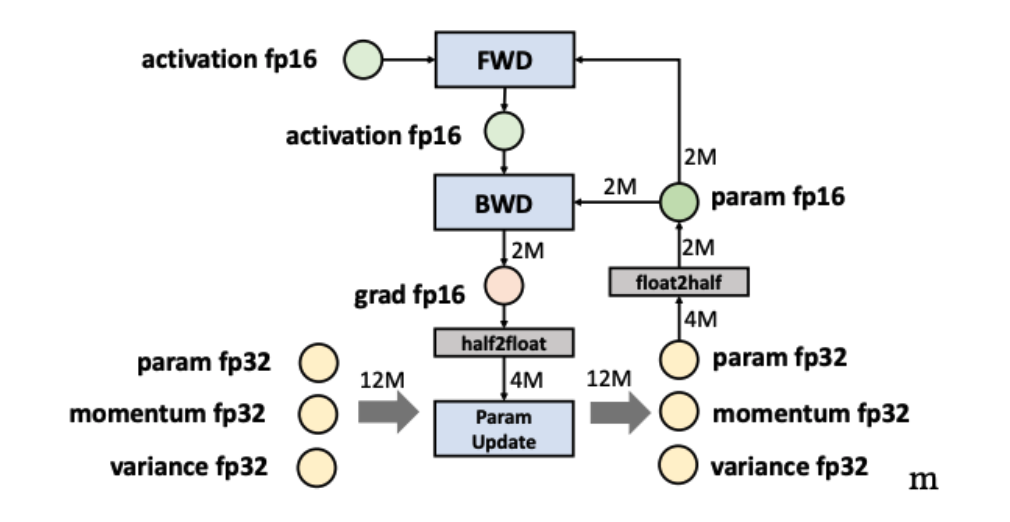
AMP in Colossal-AI
We supported three AMP training methods and allowed the user to train with AMP with no code. You can just simply add fp16
configuration in your configuration file to use AMP.
from colossalai.amp import AMP_TYPE
# use Torch AMP
fp16=dict(
mode = AMP_TYPE.TORCH
)
# use naive AMP
fp16=dict(
mode = AMP_TYPE.NAIVE
)
# use NVIDIA Apex AMP
fp16=dict(
mode = AMP_TYPE.APEX
)
These are the minimum configuration, full configuration are stated in the section later
AMP Modularity
AMP module is designed to be completely modular and can be used independently.
If you wish to only use AMP in your code base without colossalai.initialize,
you can use colossalai.amp.convert_to_amp.
from colossalai.amp import AMP_TYPE
# example of using torch amp
model, optimizer, criterion = colossalai.amp.convert_to_amp(model,
optimizer,
criterion,
AMP_TYPE.TORCH)
Torch AMP Configuration
from colossalai.amp import AMP_TYPE
fp16=dict(
mode=AMP_TYPE.TORCH,
# below are default values for grad scaler
init_scale=2.**16,
growth_factor=2.0,
backoff_factor=0.5,
growth_interval=2000,
enabled=True
)
With optional arguments:
- init_scale(float, optional, default=2.**16): Initial scale factor
- growth_factor(float, optional, default=2.0): Factor by which the scale is multiplied during
updateif no inf/NaN gradients occur forgrowth_intervalconsecutive iterations. - backoff_factor(float, optional, default=0.5): Factor by which the scale is multiplied during
updateif inf/NaN gradients occur in an iteration. - growth_interval(int, optional, default=2000): Number of consecutive iterations without inf/NaN gradients that must occur for the scale to be multiplied by
growth_factor. - enabled(bool, optional, default=True): If
False, disables gradient scaling.stepsimply invokes the underlyingoptimizer.step(), and other methods become no-ops.
Apex AMP Configuration
For this mode, we rely on the Apex implementation for mixed precision training. We support this plugin because it allows for finer control on the granularity of mixed precision. For example, O2 level (optimization level 2) will keep batch normalization in fp32.
If you look for more details, please refer to Apex Documentation.
from colossalai.amp import AMP_TYPE
fp16 = dict(
mode=AMP_TYPE.APEX,
# below are the default values
enabled=True,
opt_level='O1',
cast_model_type=None,
patch_torch_functions=None,
keep_batchnorm_fp32=None,
master_weights=None,
loss_scale=None,
cast_model_outputs=None,
num_losses=1,
verbosity=1,
min_loss_scale=None,
max_loss_scale=16777216.0
)
Parameters:
-
enabled(bool, optional, default=True): If False, renders all AMP calls no-ops, so your script should run as if Amp were not present.
-
opt_level(str, optional, default="O1" ): Pure or mixed precision optimization level. Accepted values are “O0”, “O1”, “O2”, and “O3”, explained in detail above Apex AMP Documentation.
-
num_losses(int, optional, default=1): Option to tell AMP in advance how many losses/backward passes you plan to use. When used in conjunction with the loss_id argument to
amp.scale_loss, enables Amp to use a different loss scale per loss/backward pass, which can improve stability. If num_losses is left to 1, Amp will still support multiple losses/backward passes, but use a single global loss scale for all of them. -
verbosity(int, default=1): Set to 0 to suppress Amp-related output.
-
min_loss_scale(float, default=None): Sets a floor for the loss scale values that can be chosen by dynamic loss scaling. The default value of None means that no floor is imposed. If dynamic loss scaling is not used, min_loss_scale is ignored.
-
max_loss_scale(float, default=2.**24 ): Sets a ceiling for the loss scale values that can be chosen by dynamic loss scaling. If dynamic loss scaling is not used, max_loss_scale is ignored.
Currently, the under-the-hood properties that govern pure or mixed precision training are the following: cast_model_type, patch_torch_functions, keep_batchnorm_fp32, master_weights, loss_scale. They are optional properties override once opt_level is determined
- cast_model_type: Casts your model’s parameters and buffers to the desired type.
- patch_torch_functions: Patch all Torch functions and Tensor methods to perform Tensor Core-friendly ops like GEMMs and convolutions in FP16, and any ops that benefit from FP32 precision in FP32.
- keep_batchnorm_fp32: To enhance precision and enable cudnn batchnorm (which improves performance), it’s often beneficial to keep batchnorm weights in FP32 even if the rest of the model is FP16.
- master_weights: Maintain FP32 master weights to accompany any FP16 model weights. FP32 master weights are stepped by the optimizer to enhance precision and capture small gradients.
- loss_scale: If loss_scale is a float value, use this value as the static (fixed) loss scale. If loss_scale is the string "dynamic", adaptively adjust the loss scale over time. Dynamic loss scale adjustments are performed by Amp automatically.
Naive AMP Configuration
In Naive AMP mode, we achieved mixed precision training while maintaining compatibility with complex tensor and pipeline parallelism.
This AMP mode will cast all operations into fp16.
The following code block shows the config.py file for this mode.
from colossalai.amp import AMP_TYPE
fp16 = dict(
mode=AMP_TYPE.NAIVE,
# below are the default values
log_num_zeros_in_grad=False,
initial_scale=2 ** 32,
min_scale=1,
growth_factor=2,
backoff_factor=0.5,
growth_interval=1000,
hysteresis=2
)
The default parameters of Naive AMP:
- log_num_zeros_in_grad(bool): return number of zeros in the gradients.
- initial_scale(int): initial scale of gradient scaler
- growth_factor(int): the growth rate of loss scale
- backoff_factor(float): the decrease rate of loss scale
- hysteresis(int): delay shift in dynamic loss scaling
- max_scale(int): maximum loss scale allowed
- verbose(bool): if set to
True, will print debug info
When using colossalai.initialize, you are required to first instantiate a model, an optimizer and a criterion.
The output model is converted to AMP model of smaller memory consumption.
If your input model is already too large to fit in a GPU, please instantiate your model weights in dtype=torch.float16.
Otherwise, try smaller models or checkout more parallelization training techniques!
Hands-on Practice
We provide a runnable example which demonstrates the use of AMP with Colossal-AI. In this practice, we will use Torch AMP as an example, but do note that config files are provided for all AMP modes.
Step 1. Create a config file
Create a config.py and add the fp16 configuration.
# in config.py
from colossalai.amp import AMP_TYPE
BATCH_SIZE = 128
DROP_RATE = 0.1
NUM_EPOCHS = 300
fp16 = dict(
mode=AMP_TYPE.TORCH,
)
clip_grad_norm = 1.0
Step 2. Import libraries in train_with_engine.py
Create a train_with_engine.py and import the necessary dependencies. Remember to install scipy and timm by running
pip install timm scipy.
import os
import colossalai
import torch
from pathlib import Path
from colossalai.core import global_context as gpc
from colossalai.logging import get_dist_logger
from colossalai.utils import get_dataloader
from colossalai.trainer import Trainer, hooks
from colossalai.nn.lr_scheduler import LinearWarmupLR
from timm.models import vit_base_patch16_224
from torchvision import datasets, transforms
Step 3. Initialize Distributed Environment
We then need to initialize distributed environment. For demo purpose, we uses launch_from_torch. You can refer to Launch Colossal-AI
for other initialization methods.
# initialize distributed setting
parser = colossalai.get_default_parser()
args = parser.parse_args()
# launch from torch
colossalai.launch_from_torch(config=args.config)
Step 4. Create training components
Build your model, optimizer, loss function, lr scheduler and dataloaders. Note that the root path of the dataset is
obtained from the environment variable DATA. You may export DATA=/path/to/data or change Path(os.environ['DATA'])
to a path on your machine. Data will be automatically downloaded to the root path.
# build model
model = vit_base_patch16_224(drop_rate=0.1)
# build dataloader
train_dataset = datasets.Caltech101(
root=Path(os.environ['DATA']),
download=True,
transform=transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
Gray2RGB(),
transforms.Normalize([0.5, 0.5, 0.5],
[0.5, 0.5, 0.5])
]))
train_dataloader = get_dataloader(dataset=train_dataset,
shuffle=True,
batch_size=gpc.config.BATCH_SIZE,
num_workers=1,
pin_memory=True,
)
# build optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, weight_decay=0.1)
# build loss
criterion = torch.nn.CrossEntropyLoss()
# lr_scheduler
lr_scheduler = LinearWarmupLR(optimizer, warmup_steps=50, total_steps=gpc.config.NUM_EPOCHS)
Step 5. Inject AMP Feature
Call colossalai.initialize to convert the training components to be running with FP16.
engine, train_dataloader, _, _ = colossalai.initialize(
model, optimizer, criterion, train_dataloader,
)
Step 6. Train with Engine
Use engine in a normal training loops.
engine.train()
for epoch in range(gpc.config.NUM_EPOCHS):
for img, label in enumerate(train_dataloader):
img = img.cuda()
label = label.cuda()
engine.zero_grad()
output = engine(img)
loss = engine.criterion(output, label)
engine.backward(loss)
engine.step()
lr_scheduler.step()
Step 7. Invoke Training Scripts
Use the following command to start the training scripts. You can change --nproc_per_node to use a different number of GPUs.
python -m torch.distributed.launch --nproc_per_node 4 --master_addr localhost --master_port 29500 train_with_engine.py --config config/config_AMP_torch.py