|
|
7 months ago | |
|---|---|---|
| .. | ||
| benchmark | 7 months ago | |
| model | 7 months ago | |
| README.md | 9 months ago | |
| infer.py | 8 months ago | |
| infer.sh | 1 year ago | |
| requirements.txt | 1 year ago | |
| test_ci.sh | 1 year ago | |
| train.py | 7 months ago | |
| train.sh | 1 year ago | |
README.md
OpenMoE
OpenMoE is the open-source community's first decoder-only MoE transformer. OpenMoE is implemented in Jax, and Colossal-AI has pioneered an efficient open-source support for this model in PyTorch, enabling a broader range of users to participate in and use this model. The following example of Colossal-AI demonstrates finetune and inference methods.
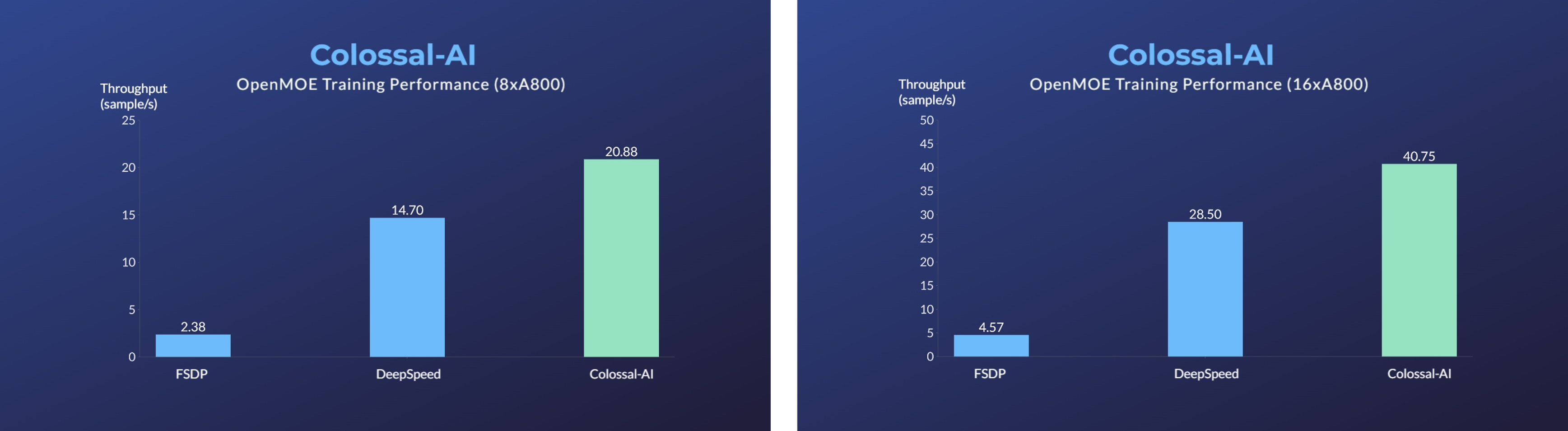
- [2023/11] Enhanced MoE Parallelism, Open-source MoE Model Training Can Be 9 Times More Efficient [code] [blog]
Usage
1. Installation
Please install the latest ColossalAI from source.
BUILD_EXT=1 pip install -U git+https://github.com/hpcaitech/ColossalAI
Then install dependencies.
cd ColossalAI/examples/language/openmoe
pip install -r requirements.txt
Additionally, we recommend you to use torch 1.13.1. We've tested our code on torch 1.13.1 and found it's compatible with our code and flash attention.
2. Install kernels (Optional)
We have utilized Triton, FlashAttention and Apex kernel for better performance. They are not necessary but we recommend you to install them to fully utilize your hardware.
# install triton via pip
pip install triton
# install flash attention via pip
pip install flash-attn==2.0.5
# install apex from source
git clone https://github.com/NVIDIA/apex.git
cd apex
git checkout 741bdf50825a97664db08574981962d66436d16a
pip install -v --disable-pip-version-check --no-cache-dir --no-build-isolation --config-settings "--build-option=--cpp_ext" --config-settings "--build-option=--cuda_ext" ./ --global-option="--cuda_ext"
3. Train
Yon can use colossalai run to launch single-node training:
colossalai run --standalone --nproc_per_node YOUR_GPU_PER_NODE train.py --OTHER_CONFIGURATIONS
Yon can also use colossalai run to launch multi-nodes training:
colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE train.py --OTHER_CONFIGURATIONS
Here is a sample hostfile:
hostname1
hostname2
hostname3
hostname4
The hostname refers to the ip address of your nodes. Make sure master node can access all nodes (including itself) by ssh without password.
Here is details about CLI arguments:
- Model configuration:
--model_name.baseand8bare supported for OpenMoE. - Booster plugin:
--plugin.ep,ep_zeroandhybridare supported.ep_zerois recommended for general cases.epcan provides least memory consumption andhybridsuits large scale training. - Output path:
--output_path. The path to save your model. The default value is./outputs. - Number of epochs:
--num_epochs. The default value is 1. - Local batch size:
--batch_size. Batch size per GPU. The default value is 1. - Save interval:
-i,--save_interval. The interval (steps) of saving checkpoints. The default value is 1000. - Mixed precision:
--precision. The default value is "bf16". "fp16", "bf16" and "fp32" are supported. - Max length:
--max_length. Max sequence length. Default to 2048. - Dataset:
-d,--dataset. The default dataset isyizhongw/self_instruct. It support any dataset fromdatasetswith the same data format as it. - Task Name:
--task_name. Task of corresponding dataset. Default tosuper_natural_instructions. - Learning rate:
--lr. The default value is 1e-5. - Weight decay:
--weight_decay. The default value is 0. - Zero stage:
--zero_stage. Zero stage. Recommend 2 for ep and 1 for ep zero. - Extra dp size:
--extra_dp_size. Extra moe param dp size for ep_zero plugin. Recommended to be 2 or 4. - Use kernel:
--use_kernel. Use kernel optim. Need to install flash attention and triton to enable all kernel optimizations. Skip if not installed. - Use layernorm kernel:
--use_layernorm_kernel. Use layernorm kernel. Need to install apex. Raise error if not installed. - Router aux loss factor:
--router_aux_loss_factor. Moe router z loss factor. You can refer to STMoE for details. - Router z loss factor:
--router_z_loss_factor. Moe router aux loss factor. You can refer to STMoE for details. - Label smoothing:
--label_smoothing. Label smoothing. - Z loss factor:
--z_loss_factor. The final outputs' classification z loss factor. Load balance:--load_balance. Expert load balance. Defaults to False. Recommend enabling. - Load balance interval:
--load_balance_interval. Expert load balance interval. - Communication overlap:
--comm_overlap. Use communication overlap for MoE. Recommended to enable for multi-node training.
4. Shell Script Examples
For your convenience, we provide some shell scripts to train with various configurations. Here we will show an example of how to run training OpenMoE.
a. Running environment
This experiment was performed on a single computing nodes with 8 A800 80GB GPUs in total for OpenMoE-8B. The GPUs are fully connected with NVLink.
b. Running command
We demonstrate how to run three plugins in train.sh. You can choose anyone and use your own args.
bash train.sh
c. Multi-Nodes Training
To run on multi-nodes, you can modify the script as:
colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
train.py --OTHER_CONFIGURATIONS
Reference
@article{bian2021colossal,
title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
journal={arXiv preprint arXiv:2110.14883},
year={2021}
}
@misc{openmoe2023,
author = {Fuzhao Xue, Zian Zheng, Yao Fu, Jinjie Ni, Zangwei Zheng, Wangchunshu Zhou and Yang You},
title = {OpenMoE: Open Mixture-of-Experts Language Models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/XueFuzhao/OpenMoE}},
}