mirror of https://github.com/hpcaitech/ColossalAI
9.0 KiB
9.0 KiB
Colossal-AI

目录
为何选择 Colossal-AI

James Demmel 教授 (加州大学伯克利分校): Colossal-AI 让分布式训练高效、易用、可扩展。
(返回顶端)
特点
Colossal-AI 为您提供了一系列并行训练组件。我们的目标是让您的分布式 AI 模型训练像普通的单 GPU 模型一样简单。我们提供的友好工具可以让您在几行代码内快速开始分布式训练。
- 数据并行
- 流水线并行
- 1维, 2维, 2.5维, 3维张量并行
- 序列并行
- 友好的 trainer 和 engine
- 可扩展新的并行方式
- 混合精度
- 零冗余优化器 (ZeRO)
(返回顶端)
展示样例
ViT
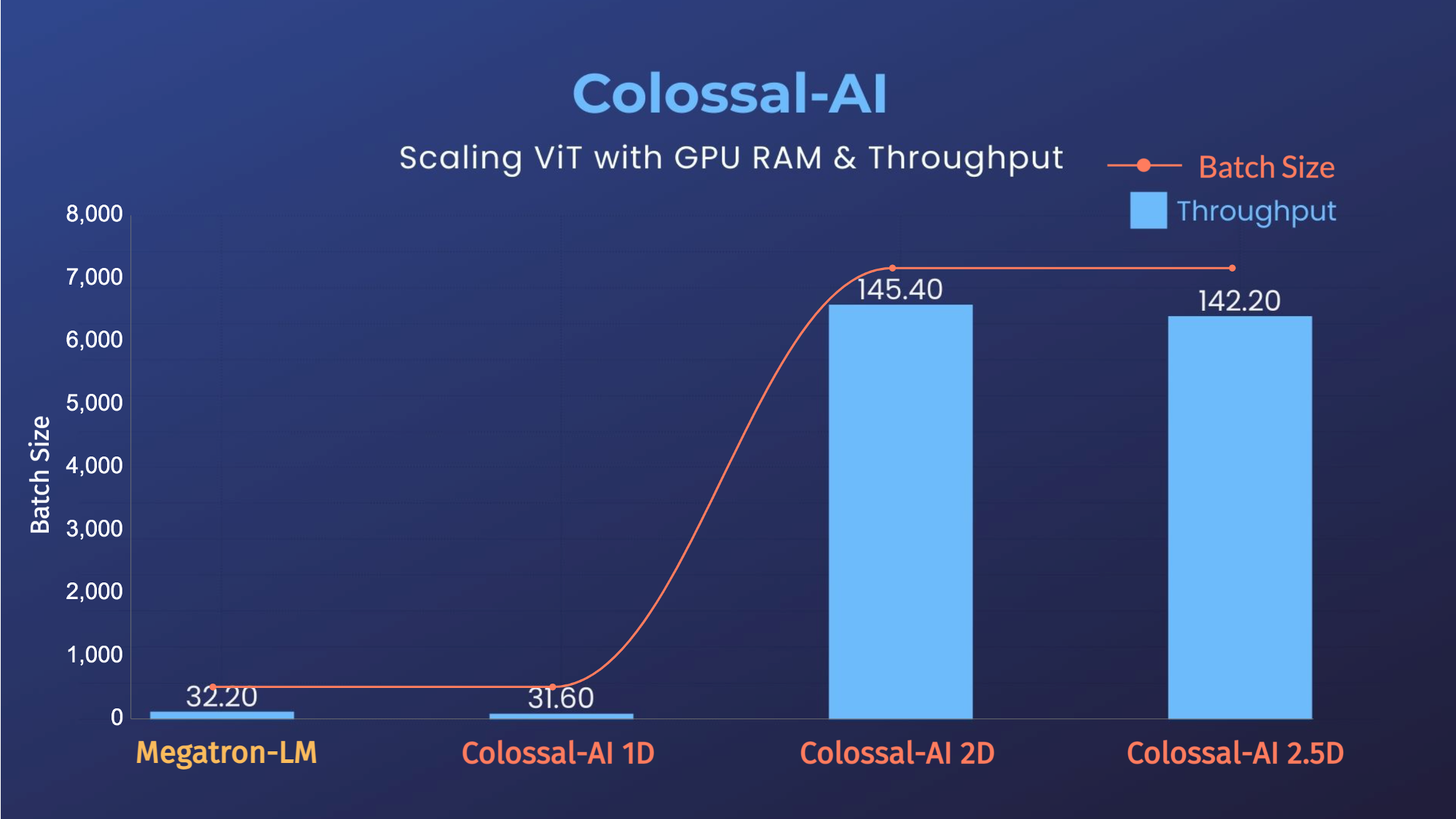
- 14倍批大小和5倍训练速度(张量并行=64)
GPT-3

- 释放 50% GPU 资源占用, 或 10.7% 加速
GPT-2
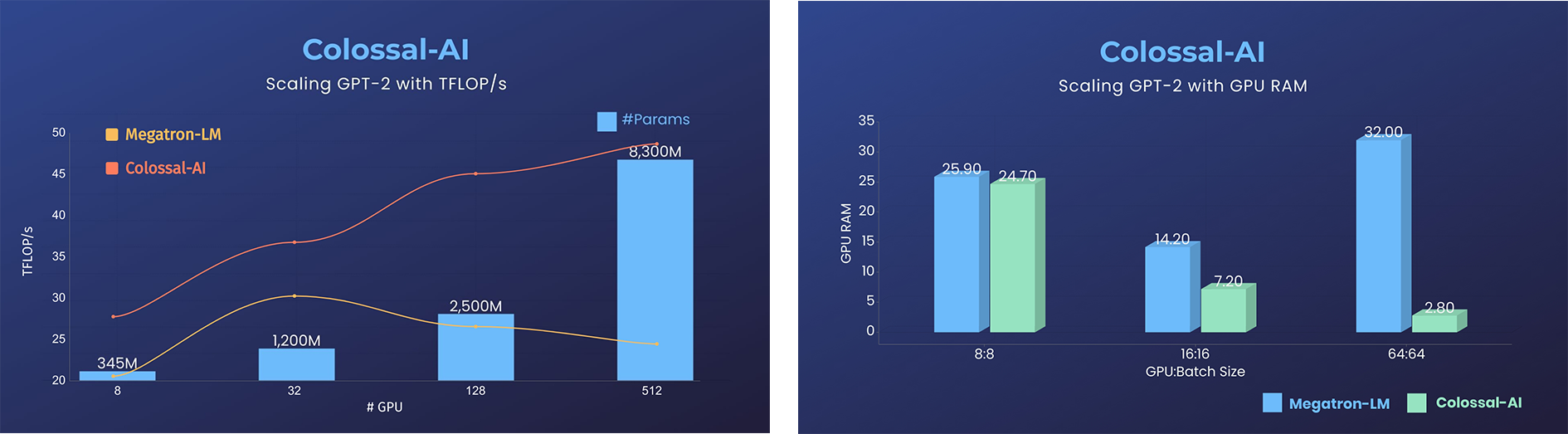
- 降低11倍 GPU 显存占用,或超线性扩展(张量并行)
GPT-2.png)
- 用相同的硬件条件训练24倍大的模型
- 超3倍的吞吐量
BERT
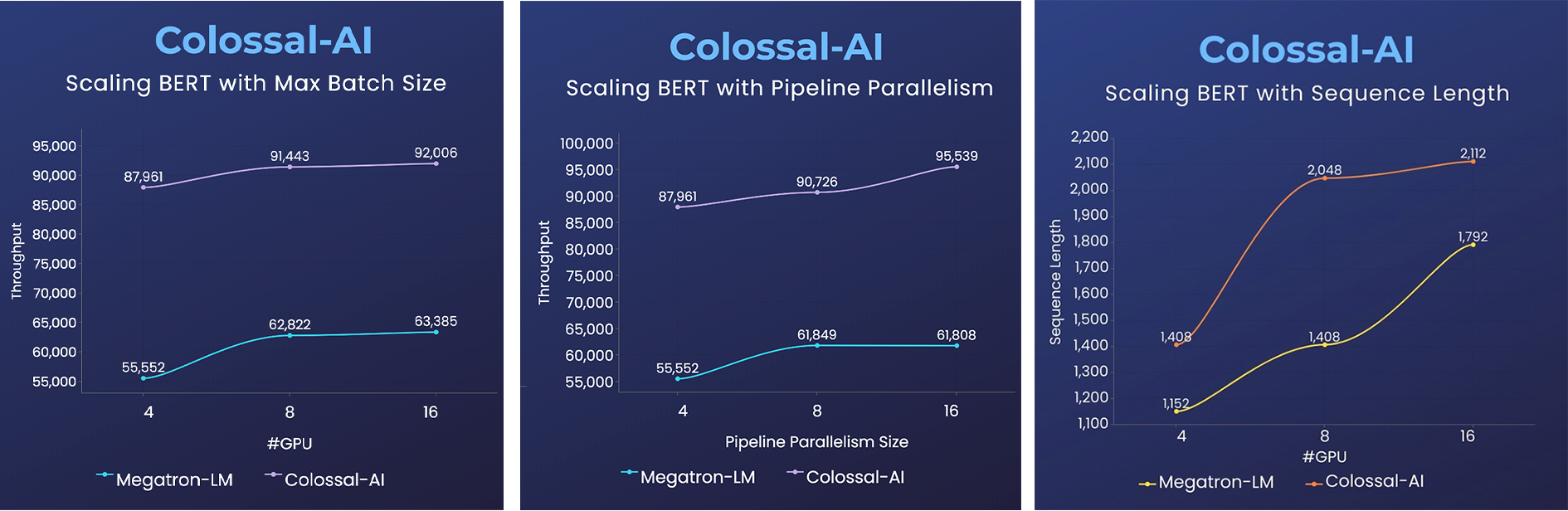
- 2倍训练速度,或1.5倍序列长度
PaLM
- PaLM-colossalai: 可扩展的谷歌 Pathways Language Model (PaLM) 实现。
请访问我们的文档和教程以了解详情。
(返回顶端)
安装
PyPI
pip install colossalai
该命令将会安装 CUDA extension, 如果你已安装 CUDA, NVCC 和 torch。
如果你不想安装 CUDA extension, 可在命令中添加--global-option="--no_cuda_ext", 例如:
pip install colossalai --global-option="--no_cuda_ext"
如果你想使用 ZeRO, 你可以使用:
pip install colossalai[zero]
从源代码安装
Colossal-AI 的版本将与该项目的主分支保持一致。欢迎通过 issue 反馈你遇到的任何问题 :)
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# 安装依赖
pip install -r requirements/requirements.txt
# 安装 colossalai
pip install .
如果你不想安装和使用 CUDA kernel fusion (使用 fused 优化器需安装):
pip install --global-option="--no_cuda_ext" .
(返回顶端)
使用 Docker
运行以下命令从我们提供的 docker 文件中建立 docker 镜像。
cd ColossalAI
docker build -t colossalai ./docker
运行以下命令从以交互式启动 docker 镜像.
docker run -ti --gpus all --rm --ipc=host colossalai bash
(返回顶端)
社区
欢迎通过论坛, Slack, 或微信加入 Colossal-AI 社区,与我们分享你的建议和问题。
做出贡献
欢迎为该项目做出贡献,请参阅贡献指南。
真诚感谢所有贡献者!
![]()
贡献者头像的展示顺序是随机的。
(返回顶端)
快速预览
几行代码开启分布式训练
import colossalai
from colossalai.utils import get_dataloader
# my_config 可以是 config 文件的路径或字典对象
# 'localhost' 仅适用于单节点,在多节点时需指明节点名
colossalai.launch(
config=my_config,
rank=rank,
world_size=world_size,
backend='nccl',
port=29500,
host='localhost'
)
# 构建模型
model = ...
# 构建数据集, dataloader 会默认处理分布式数据 sampler
train_dataset = ...
train_dataloader = get_dataloader(dataset=dataset,
shuffle=True
)
# 构建优化器
optimizer = ...
# 构建损失函数
criterion = ...
# 初始化 colossalai
engine, train_dataloader, _, _ = colossalai.initialize(
model=model,
optimizer=optimizer,
criterion=criterion,
train_dataloader=train_dataloader
)
# 开始训练
engine.train()
for epoch in range(NUM_EPOCHS):
for data, label in train_dataloader:
engine.zero_grad()
output = engine(data)
loss = engine.criterion(output, label)
engine.backward(loss)
engine.step()
构建一个简单的2维并行模型
假设我们有一个非常巨大的 MLP 模型,它巨大的 hidden size 使得它难以被单个 GPU 容纳。我们可以将该模型的权重以二维网格的形式分配到多个 GPU 上,且保持你熟悉的模型构建方式。
from colossalai.nn import Linear2D
import torch.nn as nn
class MLP_2D(nn.Module):
def __init__(self):
super().__init__()
self.linear_1 = Linear2D(in_features=1024, out_features=16384)
self.linear_2 = Linear2D(in_features=16384, out_features=1024)
def forward(self, x):
x = self.linear_1(x)
x = self.linear_2(x)
return x
(返回顶端)
引用我们
@article{bian2021colossal,
title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
journal={arXiv preprint arXiv:2110.14883},
year={2021}
}
(返回顶端)