mirror of https://github.com/hpcaitech/ColossalAI
704 B
704 B
Pretraining LLaMA: best practices for building LLaMA-like base models
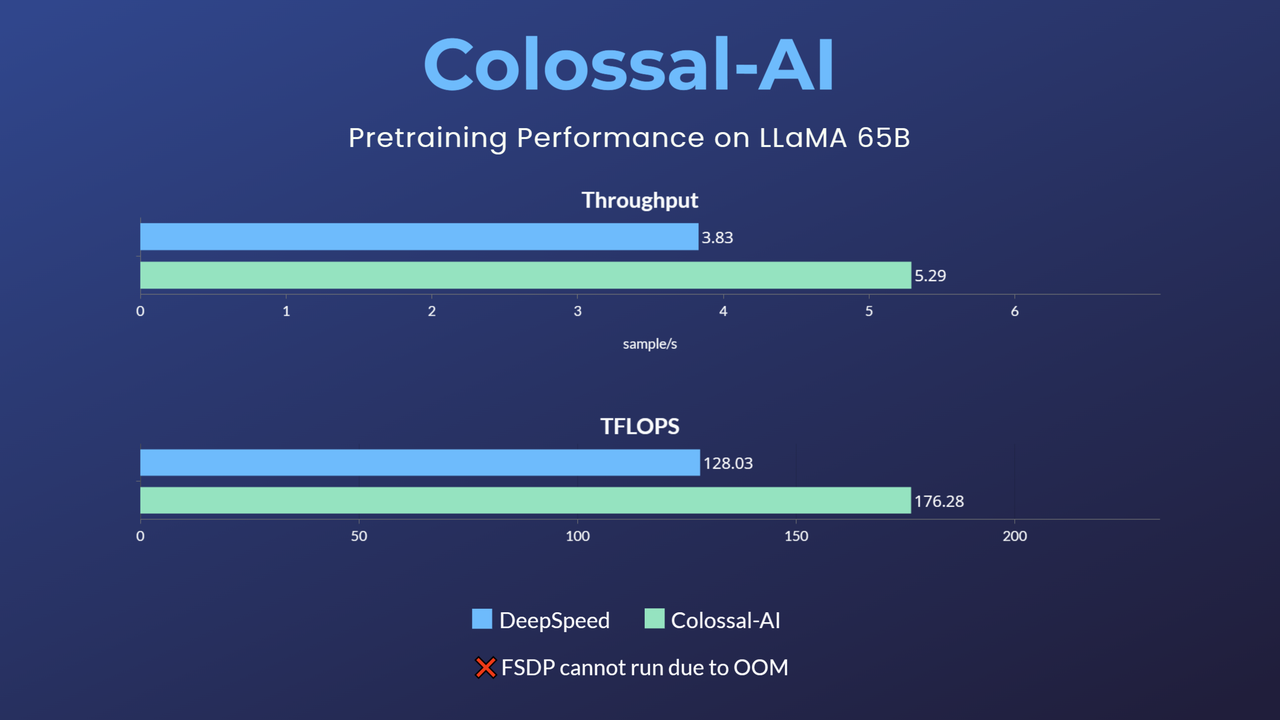
Since the main branch is being updated, in order to maintain the stability of the code, this example is temporarily kept as an independent branch.