8.1 KiB
认识Gemini:ColossalAI的异构内存空间管理器
作者: Jiarui Fang
简介
在GPU数量不足情况下,想要增加模型规模,异构训练是最有效的手段。它通过在 CPU 和 GPU 中容纳模型数据,并仅在必要时将数据移动到当前设备,可以同时利用 GPU 内存、CPU 内存(由 CPU DRAM 或 NVMe SSD内存组成)来突破单GPU内存墙的限制。并行,在大规模训练下,其他方案如数据并行、模型并行、流水线并行都可以在异构训练基础上进一步扩展GPU规模。这篇文章描述ColossalAI的异构内存空间管理模块Gemini的设计细节,它的思想来源于PatrickStar,ColossalAI根据自身情况进行了重新实现。
用法
目前Gemini支持和ZeRO并行方式兼容,它的使用方法很简单,在训练策略的配置文件里设置zero的model_config属性tensor_placement_policy='auto'
zero = dict(
model_config=dict(
reduce_scatter_bucket_size_mb=25,
fp32_reduce_scatter=False,
gradient_predivide_factor=1.0,
tensor_placement_policy="auto",
shard_strategy=TensorShardStrategy(),
...
),
optimizer_config=dict(
...
)
)
注意,Gemini和并行策略,如Tensor Parallelism,Data Parallelism,Pipeline Parallelism,ZeRO是解耦合的。对TP,PP的支持还在开发中。
术语
算子(OPerator):一个神经网络层的计算操作,比如Linear,LayerNorm等。算子可以是正向传播的计算,也可以是反向传播的计算。
神经网络在训练期间必须管理的两种类型的训练数据。
模型数据(model data): 由参数、梯度和优化器状态组成,其规模与模型结构定义相关
非模型数据(non-model data): 主要由算子生成的中间张量和算子的临时变量组成。非模型数据根据训练任务的配置动态变化,例如批量大小。模型数据和非模型数据相互竞争 GPU 内存。
设计
目前的一些解决方案,DeepSpeed采用的Zero-offload在CPU和GPU内存之间静态划分模型数据,并且它们的内存布局对于不同的训练配置是恒定的。如下图左边所示,当 GPU 内存不足以满足其相应的模型数据要求时,即使当时CPU上仍有可用内存,系统也会崩溃。而ColossalAI可以通过将一部分模型数据换出到CPU上来完成训练。
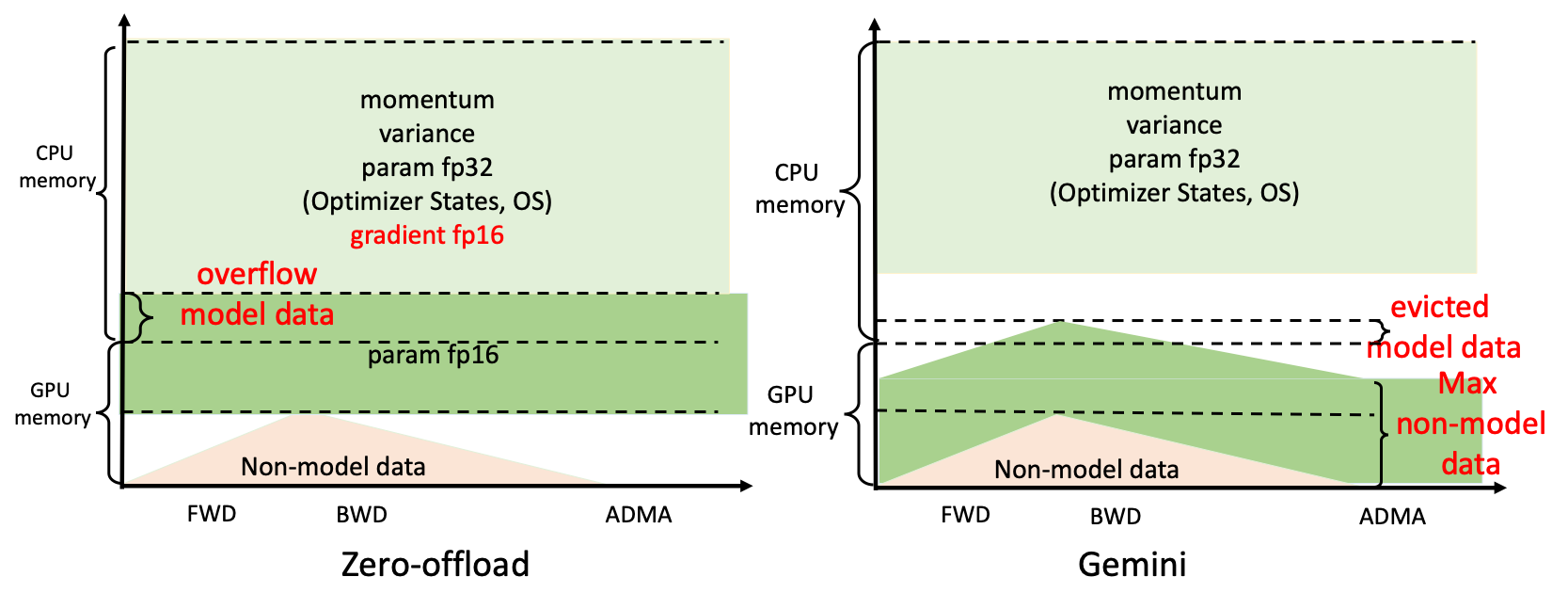
ColossalAI设计了Gemini,就像双子星一样,它管理CPU和GPU二者内存空间。它可以让张量在训练过程中动态分布在CPU-GPU的存储空间内,从而让模型训练突破GPU的内存墙。内存管理器由两部分组成,分别是MemStatsCollector(MSC)和StatefuleTensorMgr(STM)。
我们利用了深度学习网络训练过程的迭代特性。我们将迭代分为warmup和non-warmup两个阶段,开始时的一个或若干迭代步属于预热阶段,其余的迭代步属于正式阶段。在warmup阶段我们为MSC收集信息,而在non-warmup阶段STM入去MSC收集的信息来移动tensor,以达到最小化CPU-GPU数据移动volume的目的。
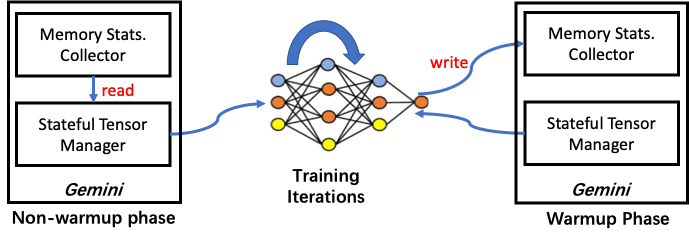
StatefulTensorMgr
STM管理所有model data tensor的信息。在模型的构造过程中,ColossalAI把所有model data张量注册给STM。内存管理器给每个张量标记一个状态信息。状态集合包括HOLD,COMPUTE,FREE三种状态。STM的功能如下:
**查询内存使用:**通过遍历所有tensor的在异构空间的位置,获取模型数据对CPU和GPU的内存占用。
**转换张量状态:**它在每个模型数据张量参与算子计算之前,将张量标记为COMPUTE状态,在计算之后标记为HOLD状态。如果张量不再使用则标记的FREE状态。
**调整张量位置:**张量管理器保证COMPUTE状态的张量被放置在计算设备上,如果计算设备的存储空间不足,则需要移动出一些HOLD状态的张量到其他设备上存储。Tensor eviction strategy需要MSC的信息,我们将在后面介绍。
MemStatsCollector
在预热阶段,内存信息统计器监测CPU和GPU中模型数据和非模型数据的内存使用情况,供正式训练阶段参考。我们通过查询STM可以获得模型数据在某个时刻的内存使用。但是非模型的内存使用却难以获取。因为非模型数据的生存周期并不归用户管理,现有的深度学习框架没有暴露非模型数据的追踪接口给用户。MSC通过采样方式在预热阶段获得非模型对CPU和GPU内存的使用情况。具体方法如下:
我们在算子的开始和结束计算时,触发内存采样操作,我们称这个时间点为采样时刻(sampling moment),两个采样时刻之间的时间我们称为period。计算过程是一个黑盒,由于可能分配临时buffer,内存使用情况很复杂。但是,我们可以较准确的获取period的系统最大内存使用。非模型数据的使用可以通过两个统计时刻之间系统最大内存使用-模型内存使用获得。
我们如何设计采样时刻呢。我们选择preOp的model data layout adjust之前。如下图所示。我们采样获得上一个period的system memory used,和下一个period的model data memoy used。并行策略会给MSC的工作造成障碍。如图所示,比如对于ZeRO或者Tensor Parallel,由于Op计算前需要gather模型数据,会带来额外的内存需求。因此,我们要求在模型数据变化前进行采样系统内存,这样在一个period内,MSC会把preOp的模型变化内存捕捉。比如在period 2-3内,我们考虑的tensor gather和shard带来的内存变化。 尽管可以将采样时刻放在其他位置,比如排除gather buffer的变动新信息,但是会给造成麻烦。不同并行方式Op的实现有差异,比如对于Linear Op,Tensor Parallel中gather buffer的分配在Op中。而对于ZeRO,gather buffer的分配是在PreOp中。将放在PreOp开始时采样有利于将两种情况统一。
尽管可以将采样时刻放在其他位置,比如排除gather buffer的变动新信息,但是会给造成麻烦。不同并行方式Op的实现有差异,比如对于Linear Op,Tensor Parallel中gather buffer的分配在Op中。而对于ZeRO,gather buffer的分配是在PreOp中。将放在PreOp开始时采样有利于将两种情况统一。
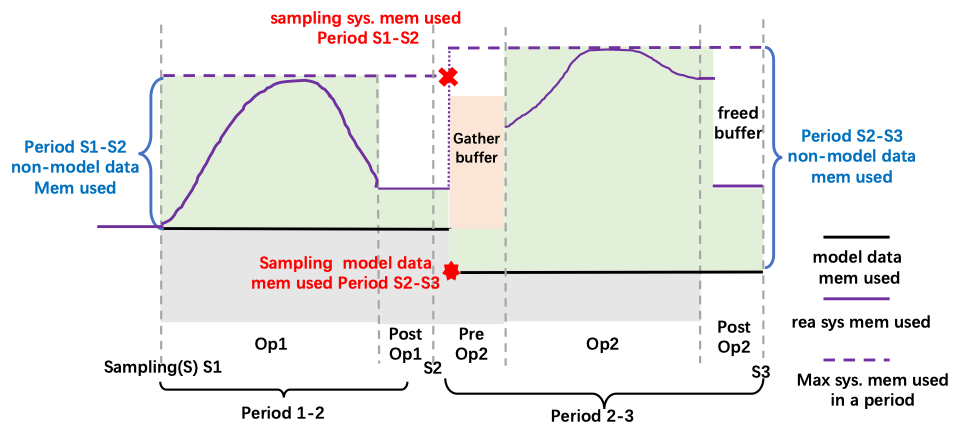
Tensor Eviction Strategy
MSC的重要职责是在调整tensor layout位置,比如在上图S2时刻,我们减少设备上model data数据,Period 2-3计算的峰值内存得到满足。
在warmup阶段,由于还没执行完毕一个完整的迭代,我们对内存的真实使用情况尚一无所知。我们此时限制模型数据的内存使用上限,比如只使用30%的GPU内存。这样保证我们可以顺利完成预热状态。
在non-warmup阶段,我们需要利用预热阶段采集的非模型数据内存信息,预留出下一个Period在计算设备上需要的峰值内存,这需要我们移动出一些模型张量。 为了避免频繁在CPU-GPU换入换出相同的tensor,引起类似cache thrashing的现象。我们利用DNN训练迭代特性,设计了OPT cache换出策略。具体来说,在warmup阶段,我们记录每个tensor被计算设备需要的采样时刻。如果我们需要驱逐一些HOLD tensor,那么我们选择在本设备上最晚被需要的tensor作为受害者。