|
|
||
|---|---|---|
| .. | ||
| configs | ||
| ldm | ||
| scripts | ||
| LICENSE | ||
| README.md | ||
| environment.yaml | ||
| main.py | ||
| requirements.txt | ||
| setup.py | ||
| train.sh | ||
README.md
Stable Diffusion with Colossal-AI
Colosssal-AI provides a faster and lower cost solution for pretraining and fine-tuning for AIGC (AI-Generated Content) applications such as the model stable-diffusion from Stability AI.
We take advantage of Colosssal-AI to exploit multiple optimization strategies , e.g. data parallelism, tensor parallelism, mixed precision & ZeRO, to scale the training to multiple GPUs.
Stable Diffusion
Stable Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database. Similar to Google's Imagen, this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
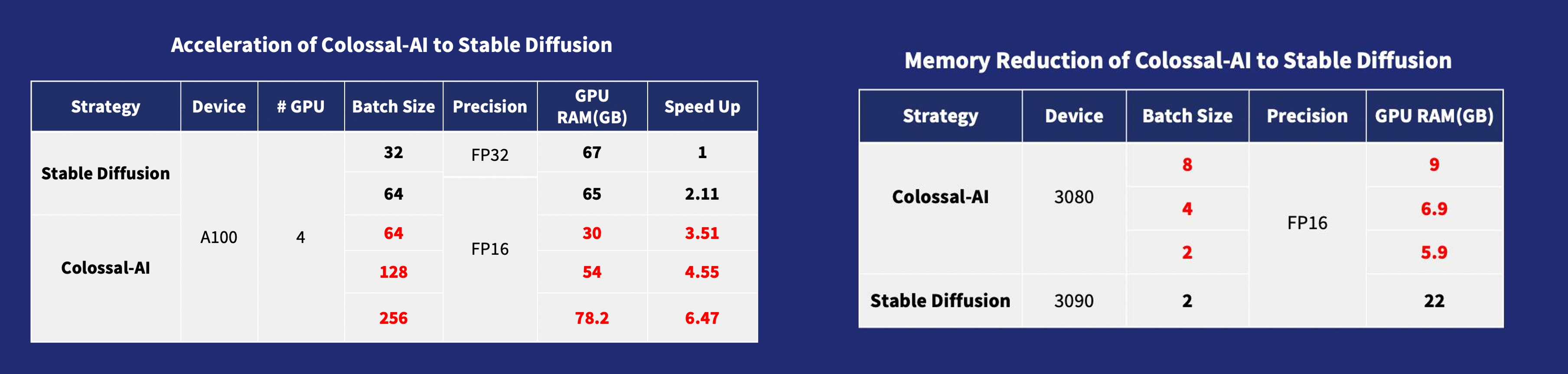
Stable Diffusion with Colossal-AI provides 6.5x faster training and pretraining cost saving, the hardware cost of fine-tuning can be almost 7X cheaper (from RTX3090/4090 24GB to RTX3050/2070 8GB).

Requirements
A suitable conda environment named ldm can be created
and activated with:
conda env create -f environment.yaml
conda activate ldm
You can also update an existing latent diffusion environment by running
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Install Colossal-AI v0.1.10 From Our Official Website
pip install colossalai==0.1.10+torch1.11cu11.3 -f https://release.colossalai.org
The specified version is due to the interface incompatibility caused by the latest update of Lightning, which will be fixed in the near future.
Download the model checkpoint from pretrained
stable-diffusion-v1-4
Our default model config use the weight from CompVis/stable-diffusion-v1-4
git lfs install
git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
stable-diffusion-v1-5 from runway
If you want to useed the Last stable-diffusion-v1-5 wiegh from runwayml
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
Dataset
The dataSet is from LAION-5B, the subset of LAION,
you should the change the data.file_path in the config/train_colossalai.yaml
Training
We provide the script train.sh to run the training task , and two Stategy in configs:train_colossalai.yaml
For example, you can run the training from colossalai by
python main.py --logdir /tmp -t --postfix test -b configs/train_colossalai.yaml
- you can change the
--logdirthe save the log information and the last checkpoint
Training config
You can change the trainging config in the yaml file
- accelerator: acceleratortype, default 'gpu'
- devices: device number used for training, default 4
- max_epochs: max training epochs
- precision: usefp16 for training or not, default 16, you must use fp16 if you want to apply colossalai
Example
Training on cifar10
We provide the finetuning example on CIFAR10 dataset
You can run by config train_colossalai_cifar10.yaml
python main.py --logdir /tmp -t --postfix test -b configs/train_colossalai_cifar10.yaml
Inference
you can get yout training last.ckpt and train config.yaml in your --logdir, and run by
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
--outdir ./output \
--config path/to/logdir/checkpoints/last.ckpt \
--ckpt /path/to/logdir/configs/project.yaml \
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Comments
-
Our codebase for the diffusion models builds heavily on OpenAI's ADM codebase , lucidrains, Stable Diffusion, Lightning and Hugging Face. Thanks for open-sourcing!
-
The implementation of the transformer encoder is from x-transformers by lucidrains.
-
The implementation of flash attention is from HazyResearch.
BibTeX
@article{bian2021colossal,
title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
journal={arXiv preprint arXiv:2110.14883},
year={2021}
}
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{dao2022flashattention,
title={FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
journal={arXiv preprint arXiv:2205.14135},
year={2022}
}