15 KiB
ColossalQA - Langchain-based Document Retrieval Conversation System
Table of Contents
- Table of Contents
- Overall Implementation
- Install
- How to Use
- Examples
- Use cases
As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.
Overall Implementation
Highlevel Design

Fig.1. Design of the document retrieval conversation system
Retrieval-based Question Answering (QA) is a crucial application of natural language processing that aims to find the most relevant answers based on the information from a corpus of text documents in response to user queries. Vector stores, which represent documents and queries as vectors in a high-dimensional space, have gained popularity for their effectiveness in retrieval QA tasks.
Step 1: Collect Data
A successful retrieval QA system starts with high-quality data. You need a collection of text documents that's related to your application. You may also need to manually design how your data will be presented to the language model.
Step 2: Split Data
Document data is usually too long to fit into the prompt due to the context length limitation of LLMs. Supporting documents need to be split into short chunks before constructing vector stores. In this demo, we use neural text splitter for better performance.
Step 3: Construct Vector Stores
Choose a embedding function and embed your text chunk into high dimensional vectors. Once you have vectors for your documents, you need to create a vector store. The vector store should efficiently index and retrieve documents based on vector similarity. In this demo, we use Chroma and incrementally update indexes of vector stores. Through incremental update, one can update and maintain a vector store without recalculating every embedding. You are free to choose any vector store from a variety of vector stores supported by Langchain. However, the incremental update only works with LangChain vector stores that support:
- Document addition by id (add_documents method with ids argument)
- Delete by id (delete method with)
Step 4: Retrieve Relative Text
Upon querying, we will run a reference resolution on user's input, the goal of this step is to remove ambiguous reference in user's query such as "this company", "him". We then embed the query with the same embedding function and query the vector store to retrieve the top-k most similar documents.
Step 5: Format Prompt
The prompt carries essential information including task description, conversation history, retrieved documents, and user's query for the LLM to generate a response. Please refer to this README for more details.
Step 6: Inference
Pass the prompt to the LLM with additional generation arguments to get agent response. You can control the generation with additional arguments such as temperature, top_k, top_p, max_new_tokens. You can also define when to stop by passing the stop substring to the retrieval QA chain.
Step 7: Update Memory
We designed a memory module that automatically summarize overlength conversation to fit the max context length of LLM. In this step, we update the memory with the newly generated response. To fix into the context length of a given LLM, we summarize the overlength part of historical conversation and present the rest in round-based conversation format. Fig.2. shows how the memory is updated. Please refer to this README for dialogue format.

Fig.2. Design of the memory module
Supported Language Models (LLMs) and Embedding Models
Our platform accommodates two kinds of LLMs: API-accessible and locally run models. For the API-style LLMs, we support ChatGPT, Pangu, and models deployed through the vLLM API Server. For locally operated LLMs, we are compatible with any language model that can be initiated using transformers.AutoModel.from_pretrained. However, due to the dependence of retrieval-based QA on the language model's abilities in zero-shot learning, instruction following, and logical reasoning, smaller models are typically not advised. In our local demo, we utilize ChatGLM2 for Chinese and LLaMa2 for English. Modifying the base LLM requires corresponding adjustments to the prompts.
Here are some sample codes to load different types of LLM.
# For locally-run LLM
from colossalqa.local.llm import ColossalAPI, ColossalLLM
api = ColossalAPI('chatglm2', 'path_to_chatglm2_checkpoint')
llm = ColossalLLM(n=1, api=api)
# For LLMs running on the vLLM API Server
from colossalqa.local.llm import VllmAPI, VllmLLM
vllm_api = VllmAPI("Your_vLLM_Host", "Your_vLLM_Port")
llm = VllmLLM(n=1, api=vllm_api)
# For ChatGPT LLM
from langchain.llms import OpenAI
llm = OpenAI(openai_api_key="YOUR_OPENAI_API_KEY")
# For Pangu LLM
# set up your authentication info
from colossalqa.local.pangu_llm import Pangu
os.environ["URL"] = ""
os.environ["URLNAME"] = ""
os.environ["PASSWORD"] = ""
os.environ["DOMAIN_NAME"] = ""
llm = Pangu(id=1)
llm.set_auth_config()
Regarding embedding models, we support all models that can be loaded via "langchain.embeddings.HuggingFaceEmbeddings". The default embedding model used in this demo is "moka-ai/m3e-base", which enables consistent text similarity computations in both Chinese and English.
In the future, supported LLM will also include models running on colossal inference and serving framework.
Install
Install colossalqa
# python==3.8.17
cd ColossalAI/applications/ColossalQA
pip install -e .
To use the vLLM for providing LLM services via an API, please consult the official guide here to start the API server. It's important to set up a new virtual environment for installing vLLM, as there are currently some dependency conflicts between vLLM and ColossalQA when installed on the same machine.
How to Use
Collect Your Data
For ChatGPT based Agent we support document retrieval and simple sql search. If you want to run the demo locally, we provided document retrieval based conversation system built upon langchain. It accept a wide range of documents. After collecting your data, put your data under a folder.
Read comments under ./colossalqa/data_loader for more detail regarding supported data formats.
Run The Script
We provide a simple Web UI demo of ColossalQA, enabling you to upload your files as a knowledge base and interact with them through a chat interface in your browser. More details can be found here
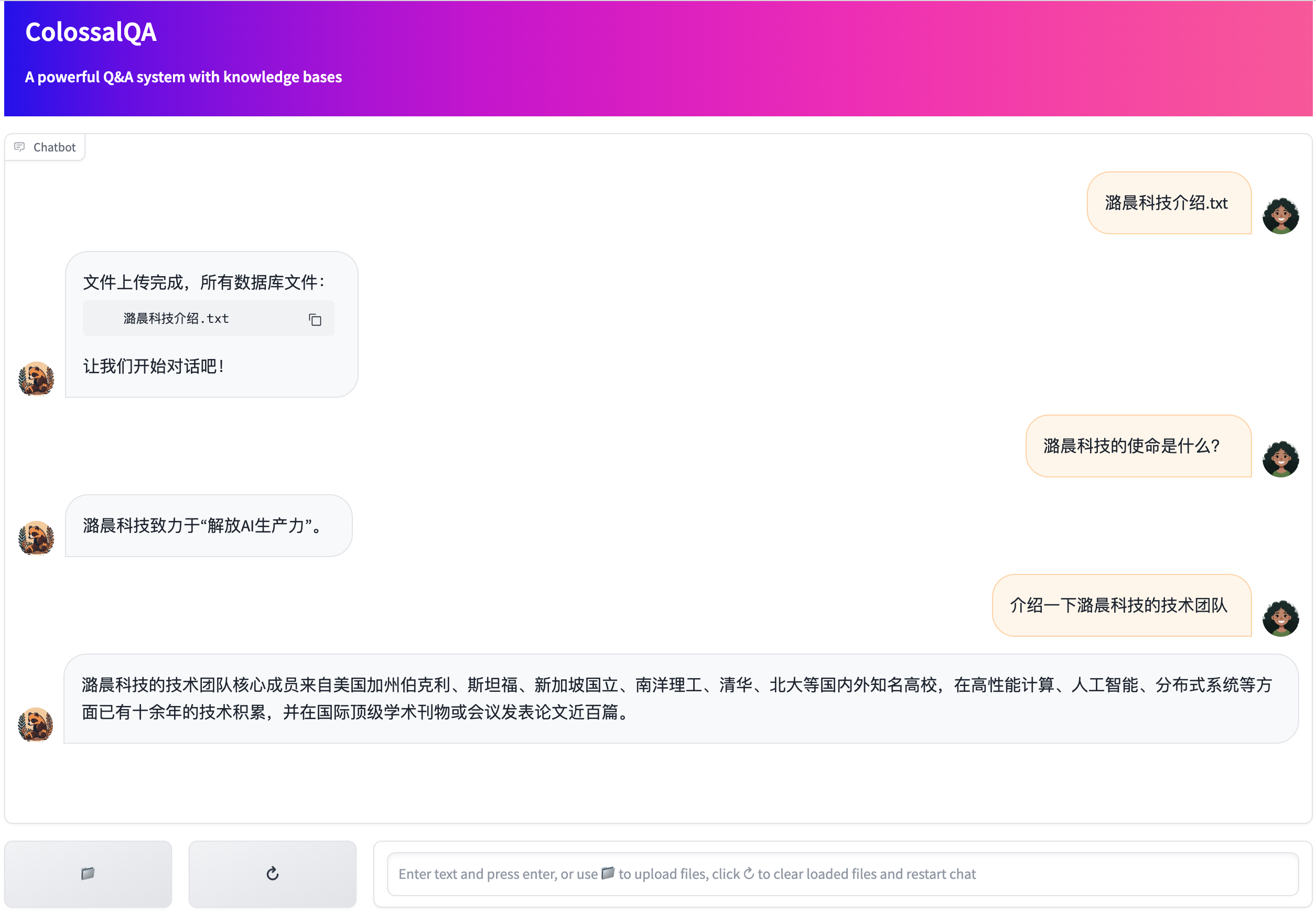
We also provided some scripts for Chinese document retrieval based conversation system, English document retrieval based conversation system, Bi-lingual document retrieval based conversation system and an experimental AI agent with document retrieval and SQL query functionality. The Bi-lingual one is a high-level wrapper for the other two classes. We write different scripts for different languages because retrieval QA requires different embedding models, LLMs, prompts for different language setting. For now, we use LLaMa2 for English retrieval QA and ChatGLM2 for Chinese retrieval QA for better performance.
To run the bi-lingual scripts.
python retrieval_conversation_universal.py \
--en_model_path /path/to/Llama-2-7b-hf \
--zh_model_path /path/to/chatglm2-6b \
--zh_model_name chatglm2 \
--en_model_name llama \
--sql_file_path /path/to/any/folder
To run retrieval_conversation_en.py.
python retrieval_conversation_en.py \
--model_path /path/to/Llama-2-7b-hf \
--model_name llama \
--sql_file_path /path/to/any/folder
To run retrieval_conversation_zh.py.
python retrieval_conversation_zh.py \
--model_path /path/to/chatglm2-6b \
--model_name chatglm2 \
--sql_file_path /path/to/any/folder
To run retrieval_conversation_chatgpt.py.
python retrieval_conversation_chatgpt.py \
--open_ai_key_path /path/to/plain/text/openai/key/file \
--sql_file_path /path/to/any/folder
To run conversation_agent_chatgpt.py.
python conversation_agent_chatgpt.py \
--open_ai_key_path /path/to/plain/text/openai/key/file
After running the script, it will ask you to provide the path to your data during the execution of the script. You can also pass a glob path to load multiple files at once. Please read this guide on how to define glob path. Follow the instruction and provide all files for your retrieval conversation system then type "ESC" to finish loading documents. If csv files are provided, please use "," as delimiter and """ as quotation mark. For json and jsonl files. The default format is
{
"data":[
{"content":"XXX"},
{"content":"XXX"}
...
]
}
For other formats, please refer to this document on how to define schema for data loading. There are no other formatting constraints for loading documents type files. For loading table type files, we use pandas, please refer to Pandas-Input/Output for file format details.
We also support another kay-value mode that utilizes a user-defined key to calculate the embeddings of the vector store. If a query matches a specific key, the value corresponding to that key will be used to generate the prompt. For instance, in the document below, "My coupon isn't working." will be employed during indexing, whereas "Question: My coupon isn't working.\nAnswer: We apologize for ... apply it to?" will appear in the final prompt. This format is typically useful when the task involves carrying on a conversation with readily accessible conversation data, such as customer service, question answering.
Document(page_content="My coupon isn't working.", metadata={'is_key_value_mapping': True, 'seq_num': 36, 'source': 'XXX.json', 'value': "Question: My coupon isn't working.\nAnswer:We apologize for the inconvenience. Can you please provide the coupon code and the product name or SKU you're trying to apply it to?"})
For now, we only support the key-value mode for json data files. You can run the script retrieval_conversation_en_customer_service.py by the following command.
python retrieval_conversation_en_customer_service.py \
--model_path /path/to/Llama-2-7b-hf \
--model_name llama \
--sql_file_path /path/to/any/folder
The Plan
- build document retrieval QA tool
- Add memory
- Add demo for AI agent with SQL query
- Add customer retriever for fast construction and retrieving (with incremental update)
Reference
@software{Chase_LangChain_2022,
author = {Chase, Harrison},
month = oct,
title = {{LangChain}},
url = {https://github.com/hwchase17/langchain},
year = {2022}
}
@inproceedings{DBLP:conf/asru/ZhangCLLW21,
author = {Qinglin Zhang and
Qian Chen and
Yali Li and
Jiaqing Liu and
Wen Wang},
title = {Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken
Document Segmentation},
booktitle = {{IEEE} Automatic Speech Recognition and Understanding Workshop, {ASRU}
2021, Cartagena, Colombia, December 13-17, 2021},
pages = {411--418},
publisher = {{IEEE}},
year = {2021},
url = {https://doi.org/10.1109/ASRU51503.2021.9688078},
doi = {10.1109/ASRU51503.2021.9688078},
timestamp = {Wed, 09 Feb 2022 09:03:04 +0100},
biburl = {https://dblp.org/rec/conf/asru/ZhangCLLW21.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{zeng2022glm,
title={Glm-130b: An open bilingual pre-trained model},
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
journal={arXiv preprint arXiv:2210.02414},
year={2022}
}
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}