6.8 KiB
Booster Plugins
Author: Hongxin Liu, Baizhou Zhang, Pengtai Xu
Prerequisite:
Introduction
As mentioned in Booster API, we can use booster plugins to customize the parallel training. In this tutorial, we will introduce how to use booster plugins.
We currently provide the following plugins:
- Torch DDP Plugin: It is a wrapper of
torch.nn.parallel.DistributedDataParalleland can be used to train models with data parallelism. - Torch FSDP Plugin: It is a wrapper of
torch.distributed.fsdp.FullyShardedDataParalleland can be used to train models with zero-dp. - Low Level Zero Plugin: It wraps the
colossalai.zero.low_level.LowLevelZeroOptimizerand can be used to train models with zero-dp. It only supports zero stage-1 and stage-2. - Gemini Plugin: It wraps the Gemini which implements Zero-3 with chunk-based and heterogeneous memory management.
- Hybrid Parallel Plugin: It provides a tidy interface that integrates the power of Shardformer, pipeline manager, mixied precision training, TorchDDP and Zero stage 1/2 feature. With this plugin, transformer models can be easily trained with any combination of tensor parallel, pipeline parallel and data parallel (DDP/Zero) efficiently, along with various kinds of optimization tools for acceleration and memory saving. Detailed information about supported parallel strategies and optimization tools is explained in the section below.
More plugins are coming soon.
Choosing Your Plugin
Generally only one plugin is used to train a model. Our recommended use case for each plugin is as follows.
- Torch DDP Plugin: It is suitable for models with less than 2 billion parameters (e.g. Bert-3m, GPT2-1.5b).
- Torch FSDP Plugin / Low Level Zero Plugin: It is suitable for models with less than 10 billion parameters (e.g. GPTJ-6b, MegatronLM-8b).
- Gemini Plugin: It is suitable for models with more than 10 billion parameters (e.g. TuringNLG-17b) and is ideal for scenarios with high cross-node bandwidth and medium to small-scale clusters (below a thousand cards) (e.g. Llama2-70b).
- Hybrid Parallel Plugin: It is suitable for models with more than 60 billion parameters, or special models such as those with exceptionally long sequences, very large vocabularies, and is best suited for scenarios with low cross-node bandwidth and large-scale clusters (a thousand cards or more) (e.g. GPT3-175b, Bloom-176b).
Plugins
Low Level Zero Plugin
This plugin implements Zero-1 and Zero-2 (w/wo CPU offload), using reduce and gather to synchronize gradients and weights.
Zero-1 can be regarded as a better substitute of Torch DDP, which is more memory efficient and faster. It can be easily used in hybrid parallelism.
Zero-2 does not support local gradient accumulation. Though you can accumulate gradient if you insist, it cannot reduce communication cost. That is to say, it's not a good idea to use Zero-2 with pipeline parallelism.
{{ autodoc:colossalai.booster.plugin.LowLevelZeroPlugin }}
We've tested compatibility on some famous models, following models may not be supported:
timm.models.convit_base- dlrm and deepfm models in
torchrec
Compatibility problems will be fixed in the future.
Gemini Plugin
This plugin implements Zero-3 with chunk-based and heterogeneous memory management. It can train large models without much loss in speed. It also does not support local gradient accumulation. More details can be found in Gemini Doc.
{{ autodoc:colossalai.booster.plugin.GeminiPlugin }}
Hybrid Parallel Plugin
This plugin implements the combination of various parallel training strategies and optimization tools. The features of HybridParallelPlugin can be generally divided into four parts:
- Shardformer: This plugin provides an entrance to Shardformer, which controls model sharding under tensor parallel and pipeline parallel setting. Shardformer also overloads the logic of model's forward/backward process to ensure the smooth working of tp/pp. Also, optimization tools including fused normalization, flash attention (xformers), JIT and sequence parallel are injected into the overloaded forward/backward method by Shardformer. More details can be found in chapter Shardformer Doc. The diagram below shows the features supported by shardformer together with hybrid parallel plugin.
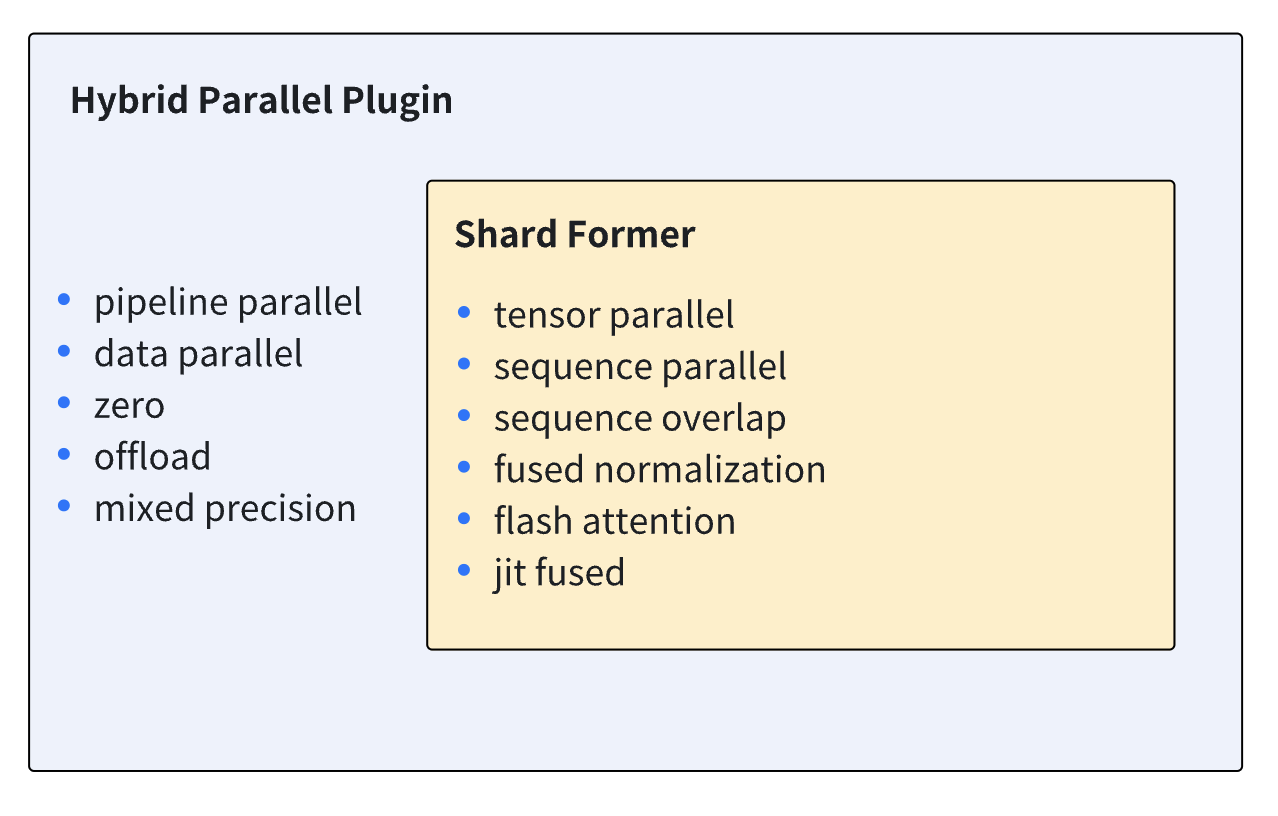
-
Mixed Precision Training: Support for fp16/bf16 mixed precision training. More details about its arguments configuration can be found in Mixed Precision Training Doc.
-
Torch DDP: This plugin will automatically adopt Pytorch DDP as data parallel strategy when pipeline parallel and Zero is not used. More details about its arguments configuration can be found in Pytorch DDP Docs.
-
Zero: This plugin can adopt Zero 1/2 as data parallel strategy through setting the
zero_stageargument as 1 or 2 when initializing plugin. Zero 1 is compatible with pipeline parallel strategy, while Zero 2 is not. More details about its argument configuration can be found in Low Level Zero Plugin.
⚠ When using this plugin, only the subset of Huggingface transformers supported by Shardformer are compatible with tensor parallel, pipeline parallel and optimization tools. Mainstream transformers such as Llama 1, Llama 2, OPT, Bloom, Bert and GPT2 etc. are all supported by Shardformer.
{{ autodoc:colossalai.booster.plugin.HybridParallelPlugin }}
Torch DDP Plugin
More details can be found in Pytorch Docs.
{{ autodoc:colossalai.booster.plugin.TorchDDPPlugin }}
Torch FSDP Plugin
⚠ This plugin is not available when torch version is lower than 1.12.0.
⚠ This plugin does not support save/load sharded model checkpoint now.
⚠ This plugin does not support optimizer that use multi params group.
More details can be found in Pytorch Docs.
{{ autodoc:colossalai.booster.plugin.TorchFSDPPlugin }}