8.2 KiB
NVMe offload
Author: Hongxin Liu
Prerequisite:
Related Paper
- ZeRO-Offload: Democratizing Billion-Scale Model Training
- ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
Introduction
If a model has N parameters, when using Adam, it has 8N optimizer states. For billion-scale models, optimizer states take at least 32 GB memory. GPU memory limits the model scale we can train, which is called GPU memory wall. If we offload optimizer states to the disk, we can break through GPU memory wall.
We implement a user-friendly and efficient asynchronous Tensor I/O library: TensorNVMe. With this library, we can simply implement NVMe offload.
This library is compatible with all kinds of disk (HDD, SATA SSD, and NVMe SSD). As I/O bandwidth of HDD or SATA SSD is low, it's recommended to use this lib only on NVMe disk.
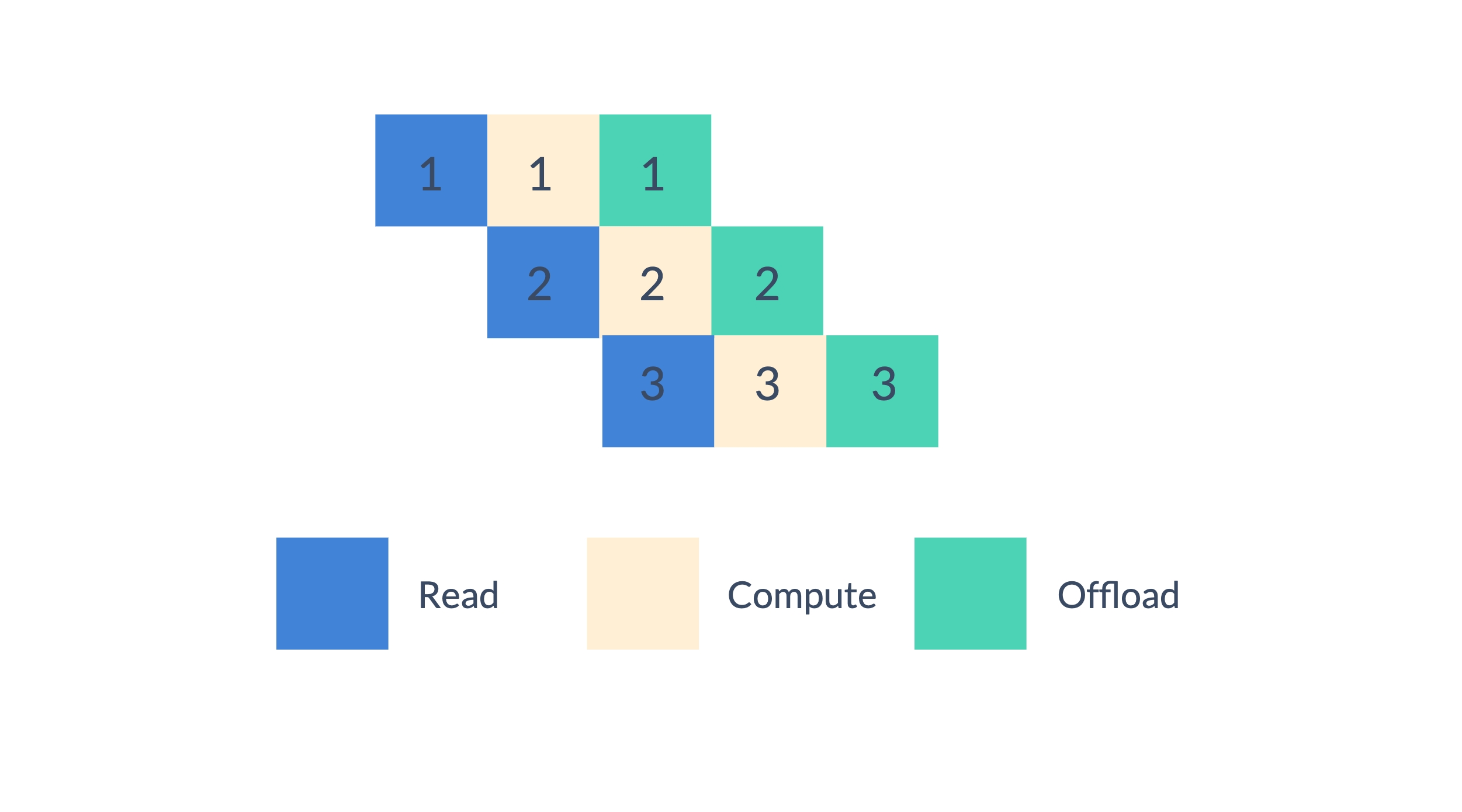
When optimizing a parameter, we can divide the optimization process into three stages: read, compute and offload. We perform the optimization process in a pipelined fashion, which can overlap computation and I/O.
Usage
First, please make sure you installed TensorNVMe:
pip install packaging
pip install tensornvme
We implement NVMe offload of optimizer states for Adam (CPUAdam and HybridAdam).
from colossalai.nn.optimizer import CPUAdam, HybridAdam
optimizer = HybridAdam(model.parameters(), lr=1e-3, nvme_offload_fraction=1.0, nvme_offload_dir='./')
nvme_offload_fraction is the fraction of optimizer states to be offloaded to NVMe. nvme_offload_dir is the directory to save NVMe offload files. If nvme_offload_dir is None, a random temporary directory will be used.
It's compatible with all parallel methods in ColossalAI.
⚠ It only offloads optimizer states on CPU. This means it only affects CPU training or Zero/Gemini with offloading.
Examples
Let's start from two simple examples -- training GPT with different methods. These examples relies on transformers.
We should install dependencies first:
pip install psutil transformers
First, we import essential packages and modules:
import os
import time
from typing import Dict, Optional
import psutil
import torch
import torch.nn as nn
from transformers.models.gpt2.configuration_gpt2 import GPT2Config
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
from colossalai.utils.model.colo_init_context import ColoInitContext
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin
Then we define a loss function:
class GPTLMLoss(nn.Module):
def __init__(self):
super().__init__()
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, logits, labels):
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
return self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1))
And we define some utility functions, which generates random data, computes the number of parameters of a model and get memory usage of current process:
def get_data(batch_size: int, seq_len: int,
vocab_size: int, device: Optional[str] = None) -> Dict[str, torch.Tensor]:
device = torch.cuda.current_device() if device is None else device
input_ids = torch.randint(vocab_size, (batch_size, seq_len),
device=device)
attn_mask = torch.ones_like(input_ids)
return dict(input_ids=input_ids, attention_mask=attn_mask)
def get_model_numel(model: nn.Module) -> int:
return sum(p.numel() for p in model.parameters())
def get_mem_usage() -> int:
proc = psutil.Process(os.getpid())
return proc.memory_info().rss
We first try to train GPT model on CPU:
def train_cpu(nvme_offload_fraction: float = 0.0):
config = GPT2Config()
model = GPT2LMHeadModel(config)
criterion = GPTLMLoss()
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size, device='cpu')
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
print(f'Time: {time.time() - start:.3f} s')
print(f'Mem usage: {get_mem_usage() / 1024**2:.3f} MB')
Run without NVME offload:
train_cpu(0.0)
We may get below output:
Model numel: 0.116 B
[0] loss: 10.953
[1] loss: 10.974
[2] loss: 10.965
Time: 7.739 s
Mem usage: 5966.445 MB
And then run with (full) NVME offload:
train_cpu(1.0)
We may get:
Model numel: 0.116 B
[0] loss: 10.951
[1] loss: 10.994
[2] loss: 10.984
Time: 8.527 s
Mem usage: 4968.016 MB
For GPT2-S, which has 0.116 billion parameters, its optimizer states take about 0.928 GB memory. And NVME offload saves about 998 MB memory, which meets our expectations.
Then we can train GPT model with Gemini. The placement policy of Gemini should be "auto", "cpu" or "const".
def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
colossalai.launch_from_torch()
config = GPT2Config()
with ColoInitContext(device=torch.cuda.current_device()):
model = GPT2LMHeadModel(config)
criterion = GPTLMLoss()
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
plugin = GeminiPlugin(
strict_ddp_mode=True,
device=torch.cuda.current_device(),
placement_policy='cpu',
pin_memory=True,
hidden_dim=config.n_embd,
initial_scale=2**5
)
booster = Booster(plugin)
model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
print(f'Time: {time.time() - start:.3f} s')
print(f'Mem usage: {get_mem_usage() / 1024**2:.3f} MB')
Run without NVME offload:
train_gemini_cpu(0.0)
We may get:
Model numel: 0.116 B
searching chunk configuration is completed in 0.27 s.
used number: 118.68 MB, wasted number: 0.75 MB
total wasted percentage is 0.63%
[0] loss: 10.953
[1] loss: 10.938
[2] loss: 10.969
Time: 2.997 s
Mem usage: 5592.227 MB
And run with (full) NVME offload:
train_gemini_cpu(1.0)
We may get:
Model numel: 0.116 B
searching chunk configuration is completed in 0.27 s.
used number: 118.68 MB, wasted number: 0.75 MB
total wasted percentage is 0.63%
[0] loss: 10.953
[1] loss: 10.938
[2] loss: 10.969
Time: 3.691 s
Mem usage: 5298.344 MB
NVME offload saves about 294 MB memory. Note that enabling pin_memory of Gemini can accelerate training but increase memory usage. So this result also meets our expectation. If we disable pin_memory, we can also observe a memory usage drop about 900 MB.
API Reference
{{ autodoc:colossalai.nn.optimizer.HybridAdam }}
{{ autodoc:colossalai.nn.optimizer.CPUAdam }}