3.0 KiB
Gradient Clipping (Outdated)
Author: Boxiang Wang, Haichen Huang, Yongbin Li
Prerequisite
Example Code
Related Paper
Introduction
In order to speed up training process and seek global optimum for better performance, more and more learning rate schedulers have been proposed. People turn to control learning rate to adjust descent pace during training, which makes gradient vector better to be uniformed in every step. In that case, the descent pace can be controlled as expected. As a result, gradient clipping, a technique which can normalize the gradient vector to circumscribe it in a uniformed length, becomes indispensable for those who desire their better performance of their models.
You do not have to worry about implementing gradient clipping when using Colossal-AI, we support gradient clipping in a powerful and convenient way. All you need is just an additional command in your configuration file.
Why you should use gradient clipping provided by Colossal-AI
The reason of why we do not recommend users to write gradient clipping by themselves is that naive gradient clipping may fail when applying tensor parallelism, pipeline parallelism or MoE.
According to the illustration below, each GPU only owns a portion of parameters of the weight in a linear layer. To get correct norm of gradient vector of the weight of the linear layer, the norm of every gradient vector in each GPU should be summed together. More complicated thing is that the distribution of bias is different from the distribution of the weight. The communication group is different in the sum operation.
(PS: This situation is an old version of 2D parallelism, the implementation in the code is not the same. But it is a good example about the difficulty to unify all communication in gradient clipping.)
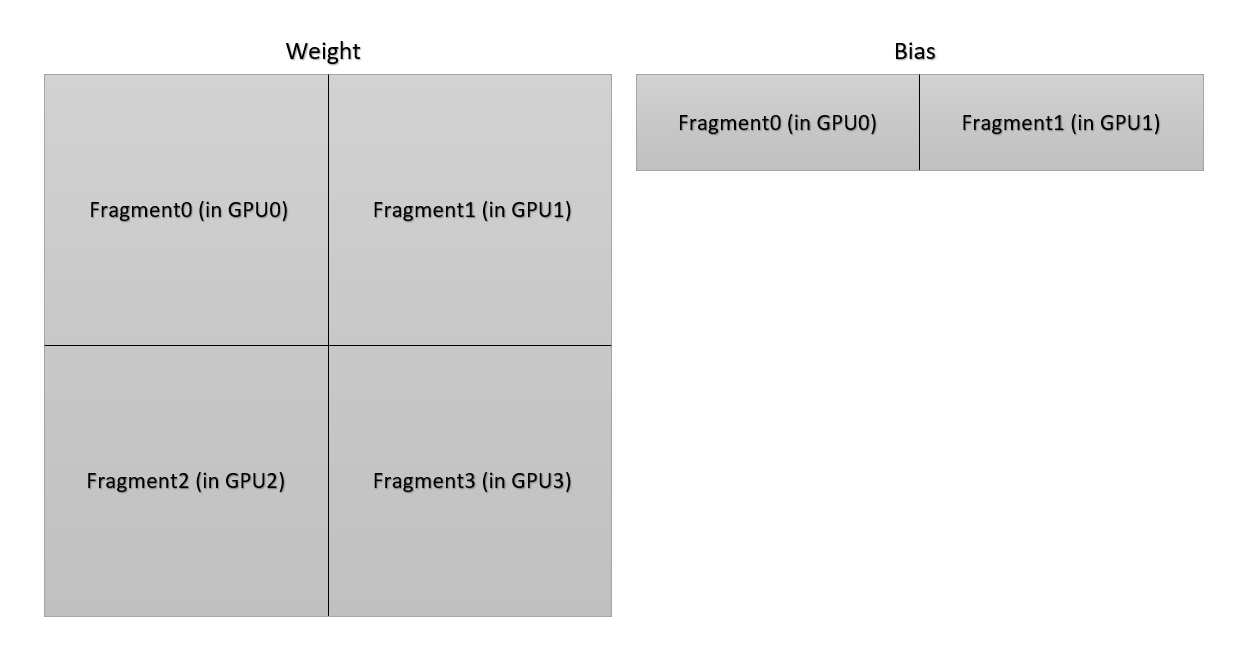
Do not worry about it, since Colossal-AI have handled it for you.
Usage
To use gradient clipping, you can just simply add gradient clipping norm in your configuration file.
clip_grad_norm = 1.0
Hands-On Practice
We provide a runnable example to demonstrate gradient clipping. In this example, we set the gradient clipping vector norm to be 1.0. You can run the script using this command:
python -m torch.distributed.launch --nproc_per_node 1 --master_addr localhost --master_port 29500 train_with_engine.py