mirror of https://github.com/hpcaitech/ColossalAI
[Feature] The first PR to Add TP inference engine, kv-cache manager and related kernels for our inference system (#4577)
* [infer] Infer/llama demo (#4503)
* add
* add infer example
* finish
* finish
* stash
* fix
* [Kernels] add inference token attention kernel (#4505)
* add token forward
* fix tests
* fix comments
* add try import triton
* add adapted license
* add tests check
* [Kernels] add necessary kernels (llama & bloom) for attention forward and kv-cache manager (#4485)
* added _vllm_rms_norm
* change place
* added tests
* added tests
* modify
* adding kernels
* added tests:
* adding kernels
* modify
* added
* updating kernels
* adding tests
* added tests
* kernel change
* submit
* modify
* added
* edit comments
* change name
* change commnets and fix import
* add
* added
* combine codes (#4509)
* [feature] add KV cache manager for llama & bloom inference (#4495)
* add kv cache memory manager
* add stateinfo during inference
* format
* format
* rename file
* add kv cache test
* revise on BatchInferState
* file dir change
* [Bug FIx] import llama context ops fix (#4524)
* added _vllm_rms_norm
* change place
* added tests
* added tests
* modify
* adding kernels
* added tests:
* adding kernels
* modify
* added
* updating kernels
* adding tests
* added tests
* kernel change
* submit
* modify
* added
* edit comments
* change name
* change commnets and fix import
* add
* added
* fix
* add ops into init.py
* add
* [Infer] Add TPInferEngine and fix file path (#4532)
* add engine for TP inference
* move file path
* update path
* fix TPInferEngine
* remove unused file
* add engine test demo
* revise TPInferEngine
* fix TPInferEngine, add test
* fix
* Add Inference test for llama (#4508)
* add kv cache memory manager
* add stateinfo during inference
* add
* add infer example
* finish
* finish
* format
* format
* rename file
* add kv cache test
* revise on BatchInferState
* add inference test for llama
* fix conflict
* feature: add some new features for llama engine
* adapt colossalai triton interface
* Change the parent class of llama policy
* add nvtx
* move llama inference code to tensor_parallel
* fix __init__.py
* rm tensor_parallel
* fix: fix bugs in auto_policy.py
* fix:rm some unused codes
* mv colossalai/tpinference to colossalai/inference/tensor_parallel
* change __init__.py
* save change
* fix engine
* Bug fix: Fix hang
* remove llama_infer_engine.py
---------
Co-authored-by: yuanheng-zhao <jonathan.zhaoyh@gmail.com>
Co-authored-by: CjhHa1 <cjh18671720497@outlook.com>
* [infer] Add Bloom inference policy and replaced methods (#4512)
* add bloom inference methods and policy
* enable pass BatchInferState from model forward
* revise bloom infer layers/policies
* add engine for inference (draft)
* add test for bloom infer
* fix bloom infer policy and flow
* revise bloom test
* fix bloom file path
* remove unused codes
* fix bloom modeling
* fix dir typo
* fix trivial
* fix policy
* clean pr
* trivial fix
* Revert "[infer] Add Bloom inference policy and replaced methods (#4512)" (#4552)
This reverts commit 17cfa57140.
* [Doc] Add colossal inference doc (#4549)
* create readme
* add readme.md
* fix typos
* [infer] Add Bloom inference policy and replaced methods (#4553)
* add bloom inference methods and policy
* enable pass BatchInferState from model forward
* revise bloom infer layers/policies
* add engine for inference (draft)
* add test for bloom infer
* fix bloom infer policy and flow
* revise bloom test
* fix bloom file path
* remove unused codes
* fix bloom modeling
* fix dir typo
* fix trivial
* fix policy
* clean pr
* trivial fix
* trivial
* Fix Bugs In Llama Model Forward (#4550)
* add kv cache memory manager
* add stateinfo during inference
* add
* add infer example
* finish
* finish
* format
* format
* rename file
* add kv cache test
* revise on BatchInferState
* add inference test for llama
* fix conflict
* feature: add some new features for llama engine
* adapt colossalai triton interface
* Change the parent class of llama policy
* add nvtx
* move llama inference code to tensor_parallel
* fix __init__.py
* rm tensor_parallel
* fix: fix bugs in auto_policy.py
* fix:rm some unused codes
* mv colossalai/tpinference to colossalai/inference/tensor_parallel
* change __init__.py
* save change
* fix engine
* Bug fix: Fix hang
* remove llama_infer_engine.py
* bug fix: fix bugs about infer_state.is_context_stage
* remove pollcies
* fix: delete unused code
* fix: delete unused code
* remove unused coda
* fix conflict
---------
Co-authored-by: yuanheng-zhao <jonathan.zhaoyh@gmail.com>
Co-authored-by: CjhHa1 <cjh18671720497@outlook.com>
* [doc] add colossal inference fig (#4554)
* create readme
* add readme.md
* fix typos
* upload fig
* [NFC] fix docstring for colossal inference (#4555)
Fix docstring and comments in kv cache manager and bloom modeling
* fix docstring in llama modeling (#4557)
* [Infer] check import vllm (#4559)
* change import vllm
* import apply_rotary_pos_emb
* change import location
* [DOC] add installation req (#4561)
* add installation req
* fix
* slight change
* remove empty
* [Feature] rms-norm transfer into inference llama.py (#4563)
* add installation req
* fix
* slight change
* remove empty
* add rmsnorm polciy
* add
* clean codes
* [infer] Fix tp inference engine (#4564)
* fix engine prepare data
* add engine test
* use bloom for testing
* revise on test
* revise on test
* reset shardformer llama (#4569)
* [infer] Fix engine - tensors on different devices (#4570)
* fix diff device in engine
* [codefactor] Feature/colossal inference (#4579)
* code factors
* remove
* change coding (#4581)
* [doc] complete README of colossal inference (#4585)
* complete fig
* Update README.md
* [doc]update readme (#4586)
* update readme
* Update README.md
* bug fix: fix bus in llama and bloom (#4588)
* [BUG FIX]Fix test engine in CI and non-vllm kernels llama forward (#4592)
* fix tests
* clean
* clean
* fix bugs
* add
* fix llama non-vllm kernels bug
* modify
* clean codes
* [Kernel]Rmsnorm fix (#4598)
* fix tests
* clean
* clean
* fix bugs
* add
* fix llama non-vllm kernels bug
* modify
* clean codes
* add triton rmsnorm
* delete vllm kernel flag
* [Bug Fix]Fix bugs in llama (#4601)
* fix tests
* clean
* clean
* fix bugs
* add
* fix llama non-vllm kernels bug
* modify
* clean codes
* bug fix: remove rotary_positions_ids
---------
Co-authored-by: cuiqing.li <lixx3527@gmail.com>
* [kernel] Add triton layer norm & replace norm for bloom (#4609)
* add layernorm for inference
* add test for layernorm kernel
* add bloom layernorm replacement policy
* trivial: path
* [Infer] Bug fix rotary embedding in llama (#4608)
* fix rotary embedding
* delete print
* fix init seq len bug
* rename pytest
* add benchmark for llama
* refactor codes
* delete useless code
* [bench] Add bloom inference benchmark (#4621)
* add bloom benchmark
* readme - update benchmark res
* trivial - uncomment for testing (#4622)
* [Infer] add check triton and cuda version for tests (#4627)
* fix rotary embedding
* delete print
* fix init seq len bug
* rename pytest
* add benchmark for llama
* refactor codes
* delete useless code
* add check triton and cuda
* Update sharder.py (#4629)
* [Inference] Hot fix some bugs and typos (#4632)
* fix
* fix test
* fix conflicts
* [typo]Comments fix (#4633)
* fallback
* fix commnets
* bug fix: fix some bugs in test_llama and test_bloom (#4635)
* [Infer] delete benchmark in tests and fix bug for llama and bloom (#4636)
* fix rotary embedding
* delete print
* fix init seq len bug
* rename pytest
* add benchmark for llama
* refactor codes
* delete useless code
* add check triton and cuda
* delete benchmark and fix infer bugs
* delete benchmark for tests
* delete useless code
* delete bechmark function in utils
* [Fix] Revise TPInferEngine, inference tests and benchmarks (#4642)
* [Fix] revise TPInferEngine methods and inference tests
* fix llama/bloom infer benchmarks
* fix infer tests
* trivial fix: benchmakrs
* trivial
* trivial: rm print
* modify utils filename for infer ops test (#4657)
* [Infer] Fix TPInferEngine init & inference tests, benchmarks (#4670)
* fix engine funcs
* TPInferEngine: receive shard config in init
* benchmarks: revise TPInferEngine init
* benchmarks: remove pytest decorator
* trivial fix
* use small model for tests
* [NFC] use args for infer benchmarks (#4674)
* revise infer default (#4683)
* [Fix] optimize/shard model in TPInferEngine init (#4684)
* remove using orig model in engine
* revise inference tests
* trivial: rename
---------
Co-authored-by: Jianghai <72591262+CjhHa1@users.noreply.github.com>
Co-authored-by: Xu Kai <xukai16@foxmail.com>
Co-authored-by: Yuanheng Zhao <54058983+yuanheng-zhao@users.noreply.github.com>
Co-authored-by: yuehuayingxueluo <867460659@qq.com>
Co-authored-by: yuanheng-zhao <jonathan.zhaoyh@gmail.com>
Co-authored-by: CjhHa1 <cjh18671720497@outlook.com>
pull/4686/head
parent
eedaa3e1ef
commit
bce0f16702
32
LICENSE
32
LICENSE
|
|
@ -396,3 +396,35 @@ Copyright 2021- HPC-AI Technology Inc. All rights reserved.
|
|||
CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
|
||||
ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
|
||||
POSSIBILITY OF SUCH DAMAGE.
|
||||
|
||||
---------------- LICENSE FOR VLLM TEAM ----------------
|
||||
|
||||
from VLLM TEAM:
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
https://github.com/vllm-project/vllm/blob/main/LICENSE
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
||||
---------------- LICENSE FOR LIGHTLLM TEAM ----------------
|
||||
|
||||
from LIGHTLLM TEAM:
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
https://github.com/ModelTC/lightllm/blob/main/LICENSE
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
|
|
|||
|
|
@ -0,0 +1,117 @@
|
|||
# 🚀 Colossal-Inference
|
||||
|
||||
## Table of contents
|
||||
|
||||
## Introduction
|
||||
|
||||
`Colossal Inference` is a module that contains colossal-ai designed inference framework, featuring high performance, steady and easy usability. `Colossal Inference` incorporated the advantages of the latest open-source inference systems, including TGI, vLLM, FasterTransformer, LightLLM and flash attention. while combining the design of Colossal AI, especially Shardformer, to reduce the learning curve for users.
|
||||
|
||||
## Design
|
||||
|
||||
Colossal Inference is composed of two main components:
|
||||
|
||||
1. High performance kernels and ops: which are inspired from existing libraries and modified correspondingly.
|
||||
2. Efficient memory management mechanism:which includes the key-value cache manager, allowing for zero memory waste during inference.
|
||||
1. `cache manager`: serves as a memory manager to help manage the key-value cache, it integrates functions such as memory allocation, indexing and release.
|
||||
2. `batch_infer_info`: holds all essential elements of a batch inference, which is updated every batch.
|
||||
3. High-level inference engine combined with `Shardformer`: it allows our inference framework to easily invoke and utilize various parallel methods.
|
||||
1. `engine.TPInferEngine`: it is a high level interface that integrates with shardformer, especially for multi-card (tensor parallel) inference:
|
||||
2. `modeling.llama.LlamaInferenceForwards`: contains the `forward` methods for llama inference. (in this case : llama)
|
||||
3. `policies.llama.LlamaModelInferPolicy` : contains the policies for `llama` models, which is used to call `shardformer` and segmentate the model forward in tensor parallelism way.
|
||||
|
||||
## Pipeline of inference:
|
||||
|
||||
In this section we discuss how the colossal inference works and integrates with the `Shardformer` . The details can be found in our codes.
|
||||
|
||||
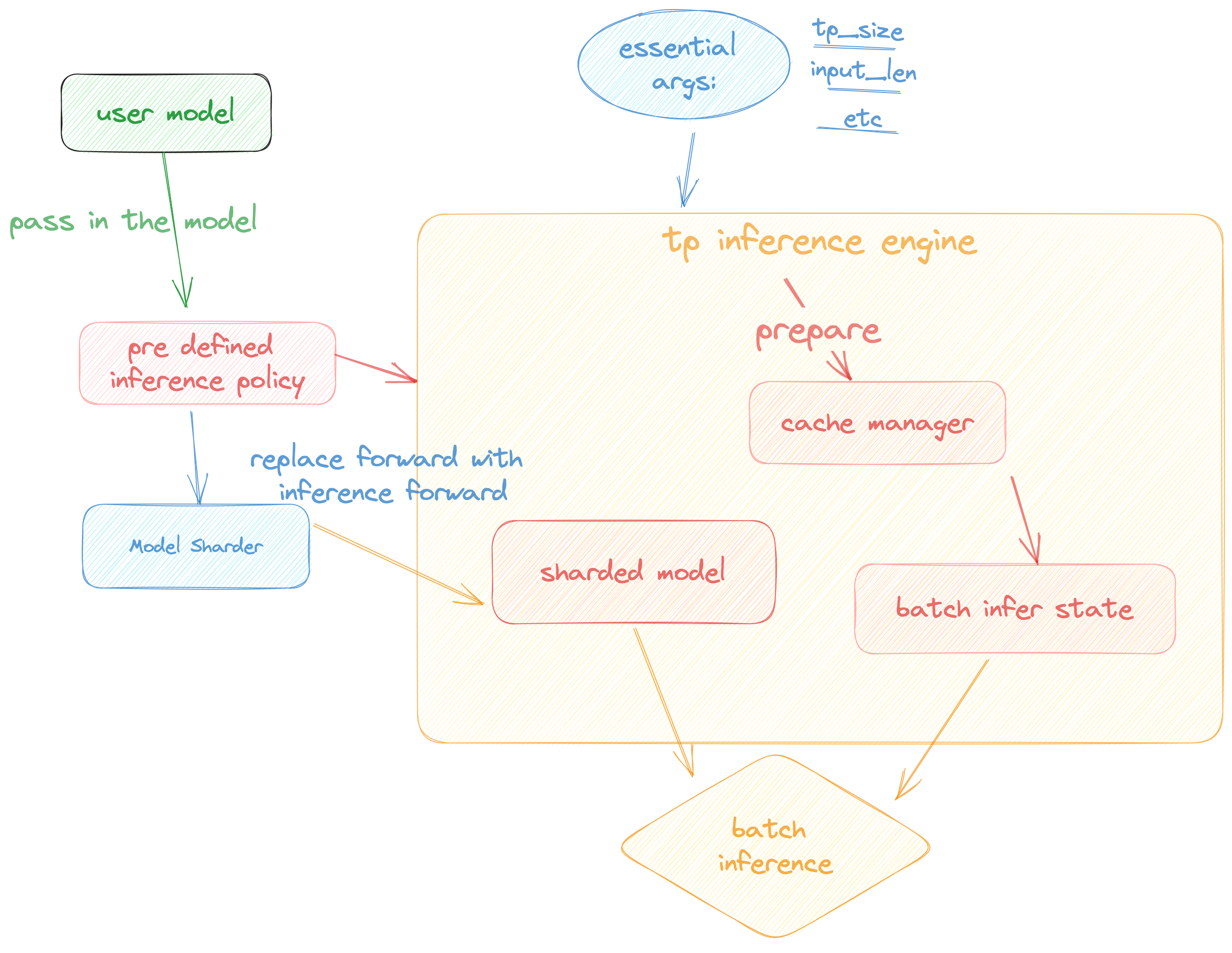
|
||||
|
||||
## Roadmap of our implementation
|
||||
|
||||
- [x] Design cache manager and batch infer state
|
||||
- [x] Design TpInference engine to integrates with `Shardformer`
|
||||
- [x] Register corresponding high-performance `kernel` and `ops`
|
||||
- [x] Design policies and forwards (e.g. `Llama` and `Bloom`)
|
||||
- [x] policy
|
||||
- [x] context forward
|
||||
- [x] token forward
|
||||
- [ ] Replace the kernels with `faster-transformer` in token-forward stage
|
||||
- [ ] Support all models
|
||||
- [x] Llama
|
||||
- [x] Bloom
|
||||
- [ ] Chatglm2
|
||||
- [ ] Benchmarking for all models
|
||||
|
||||
## Get started
|
||||
|
||||
### Installation
|
||||
|
||||
```bash
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
### Requirements
|
||||
|
||||
dependencies
|
||||
|
||||
```bash
|
||||
pytorch= 1.13.1 (gpu)
|
||||
cuda>= 11.6
|
||||
transformers= 4.30.2
|
||||
triton==2.0.0.dev20221202
|
||||
# for install vllm, please use this branch to install https://github.com/tiandiao123/vllm/tree/setup_branch
|
||||
vllm
|
||||
# for install flash-attention, please use commit hash: 67ae6fd74b4bc99c36b2ce524cf139c35663793c
|
||||
flash-attention
|
||||
```
|
||||
|
||||
### Docker
|
||||
|
||||
You can use docker run to use docker container to set-up environment
|
||||
|
||||
```
|
||||
# env: python==3.8, cuda 11.6, pytorch == 1.13.1 triton==2.0.0.dev20221202, vllm kernels support, flash-attention-2 kernels support
|
||||
docker pull hpcaitech/colossalai-inference:v2
|
||||
docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcaitech/colossalai-inference:v2 /bin/bash
|
||||
|
||||
```
|
||||
|
||||
### Dive into fast-inference!
|
||||
|
||||
example files are in
|
||||
|
||||
```bash
|
||||
cd colossalai.examples
|
||||
python xx
|
||||
```
|
||||
|
||||
## Performance
|
||||
|
||||
### environment:
|
||||
|
||||
We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `colossal-inference` and original `hugging-face torch fp16`.
|
||||
|
||||
For various models, experiments were conducted using multiple batch sizes under the consistent model configuration of `7 billion(7b)` parameters, `1024` input length, and 128 output length. The obtained results are as follows (due to time constraints, the evaluation has currently been performed solely on the `A100` single GPU performance; multi-GPU performance will be addressed in the future):
|
||||
|
||||
### Single GPU Performance:
|
||||
|
||||
Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to furthur optimize the performance of LLM models. Please stay tuned.
|
||||
|
||||
#### Llama
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
| hugging-face torch fp16 | 199.12 | 246.56 | 278.4 |
|
||||
| colossal-inference | 326.4 | 582.72 | 816.64 |
|
||||
|
||||
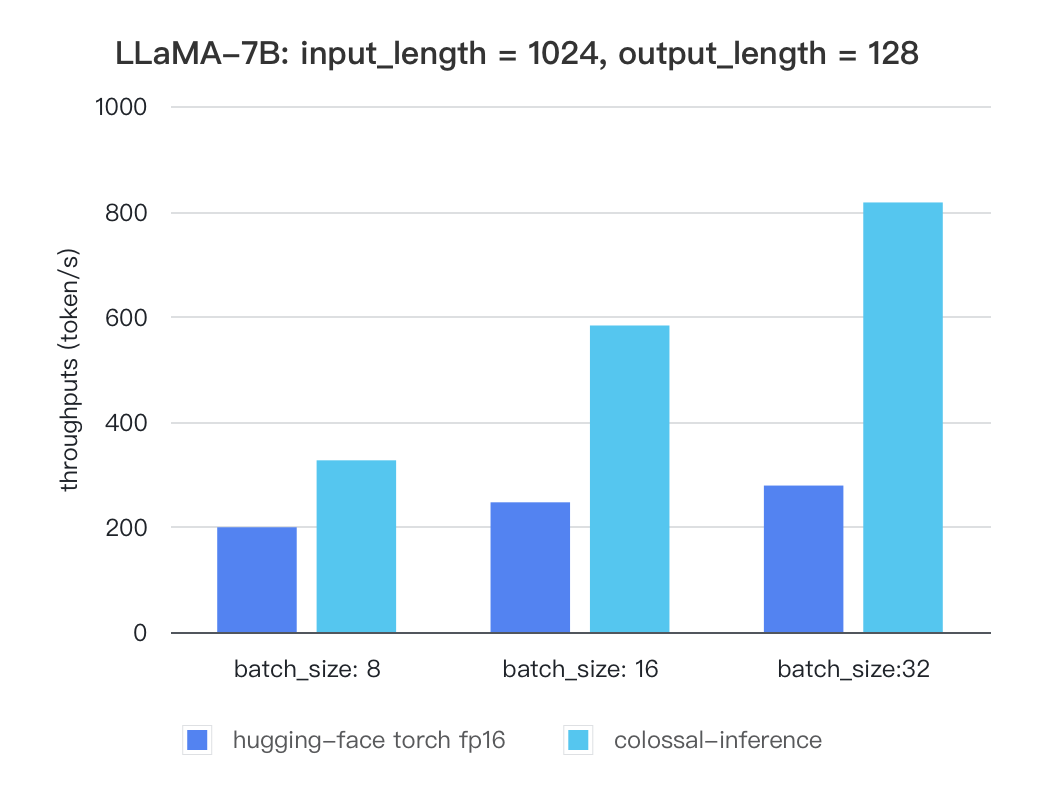
|
||||
|
||||
### Bloom
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
| hugging-face torch fp16 | 189.68 | 226.66 | 249.61 |
|
||||
| colossal-inference | 323.28 | 538.52 | 611.64 |
|
||||
|
||||
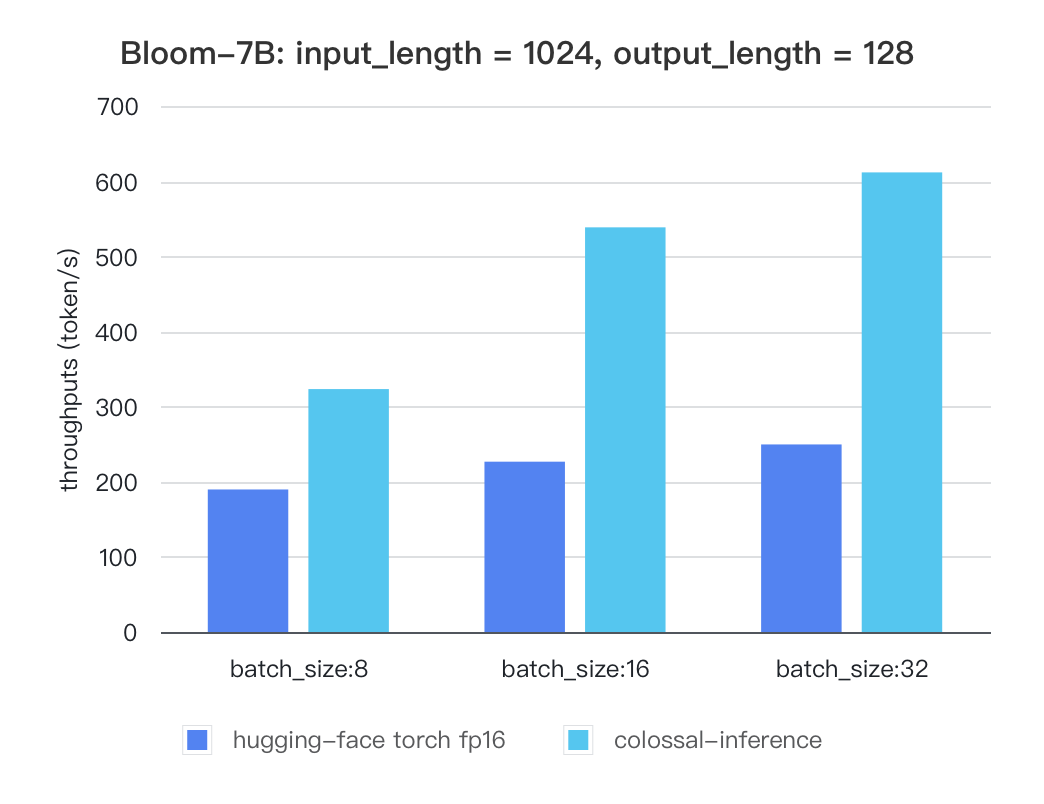
|
||||
|
||||
The results of more models are coming soon!
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
from .engine import TPInferEngine
|
||||
from .kvcache_manager import MemoryManager
|
||||
|
||||
__all__ = ['MemoryManager', 'TPInferEngine']
|
||||
|
|
@ -0,0 +1,55 @@
|
|||
# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
|
||||
from dataclasses import dataclass
|
||||
from typing import Any
|
||||
|
||||
import torch
|
||||
|
||||
from .kvcache_manager import MemoryManager
|
||||
|
||||
|
||||
@dataclass
|
||||
class BatchInferState:
|
||||
r"""
|
||||
Information to be passed and used for a batch of inputs during
|
||||
a single model forward
|
||||
"""
|
||||
batch_size: int
|
||||
max_len_in_batch: int
|
||||
|
||||
cache_manager: MemoryManager = None
|
||||
|
||||
block_loc: torch.Tensor = None
|
||||
start_loc: torch.Tensor = None
|
||||
seq_len: torch.Tensor = None
|
||||
past_key_values_len: int = None
|
||||
|
||||
is_context_stage: bool = False
|
||||
context_mem_index: torch.Tensor = None
|
||||
decode_is_contiguous: bool = None
|
||||
decode_mem_start: int = None
|
||||
decode_mem_end: int = None
|
||||
decode_mem_index: torch.Tensor = None
|
||||
decode_layer_id: int = None
|
||||
|
||||
device: torch.device = torch.device('cuda')
|
||||
|
||||
@property
|
||||
def total_token_num(self):
|
||||
# return self.batch_size * self.max_len_in_batch
|
||||
assert self.seq_len is not None and self.seq_len.size(0) > 0
|
||||
return int(torch.sum(self.seq_len))
|
||||
|
||||
def set_cache_manager(self, manager: MemoryManager):
|
||||
self.cache_manager = manager
|
||||
|
||||
@staticmethod
|
||||
def init_block_loc(b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int,
|
||||
alloc_mem_index: torch.Tensor):
|
||||
""" in-place update block loc mapping based on the sequence length of the inputs in current bath"""
|
||||
start_index = 0
|
||||
seq_len_numpy = seq_len.cpu().numpy()
|
||||
for i, cur_seq_len in enumerate(seq_len_numpy):
|
||||
b_loc[i, max_len_in_batch - cur_seq_len:max_len_in_batch] = alloc_mem_index[start_index:start_index +
|
||||
cur_seq_len]
|
||||
start_index += cur_seq_len
|
||||
return
|
||||
|
|
@ -0,0 +1,294 @@
|
|||
from typing import Any, Callable, Dict, List, Optional, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from transformers import BloomForCausalLM, LlamaForCausalLM
|
||||
from transformers.generation import GenerationConfig
|
||||
from transformers.generation.stopping_criteria import StoppingCriteriaList
|
||||
from transformers.tokenization_utils_base import BatchEncoding
|
||||
|
||||
from colossalai.shardformer import ShardConfig, ShardFormer
|
||||
from colossalai.shardformer.policies.auto_policy import get_autopolicy
|
||||
|
||||
from .batch_infer_state import BatchInferState
|
||||
from .kvcache_manager import MemoryManager
|
||||
|
||||
DP_AXIS, PP_AXIS, TP_AXIS = 0, 1, 2
|
||||
|
||||
_supported_models = ['LlamaForCausalLM', 'LlamaModel', 'BloomForCausalLM']
|
||||
|
||||
|
||||
class TPInferEngine:
|
||||
"""Engine class for tensor parallel inference.
|
||||
|
||||
Args:
|
||||
model (Module): original model, e.g. huggingface CausalLM
|
||||
shard_config (ShardConfig): The config for sharding original model
|
||||
max_batch_size (int): maximum batch size
|
||||
max_input_len (int): maximum input length of sequence
|
||||
max_output_len (int): maximum output length of output tokens
|
||||
dtype (torch.dtype): datatype used to init KV cache space
|
||||
device (str): device the KV cache of engine to be initialized on
|
||||
|
||||
Examples:
|
||||
>>> # define model and shard config for your inference
|
||||
>>> model = ...
|
||||
>>> generate_kwargs = ...
|
||||
>>> shard_config = ShardConfig(enable_tensor_parallelism=True, inference_only=True)
|
||||
>>> infer_engine = TPInferEngine(model, shard_config, MAX_BATCH_SIZE, MAX_INPUT_LEN, MAX_OUTPUT_LEN)
|
||||
>>> outputs = infer_engine.generate(input_ids, **generate_kwargs)
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
model: nn.Module,
|
||||
shard_config: ShardConfig,
|
||||
max_batch_size: int,
|
||||
max_input_len: int,
|
||||
max_output_len: int,
|
||||
dtype: torch.dtype = torch.float16,
|
||||
device: str = 'cuda') -> None:
|
||||
self.max_batch_size = max_batch_size
|
||||
self.max_input_len = max_input_len
|
||||
self.max_output_len = max_output_len
|
||||
self.max_total_token_num = self.max_batch_size * (self.max_input_len + self.max_output_len)
|
||||
|
||||
# Constraints relatable with specs of devices and model
|
||||
# This may change into an optional arg in the future
|
||||
assert self.max_batch_size <= 64, "Max batch size exceeds the constraint"
|
||||
assert self.max_input_len + self.max_output_len <= 4096, "Max length exceeds the constraint"
|
||||
|
||||
self.dtype = dtype
|
||||
|
||||
self.head_dim = model.config.hidden_size // model.config.num_attention_heads
|
||||
self.head_num = model.config.num_attention_heads
|
||||
self.layer_num = model.config.num_hidden_layers
|
||||
|
||||
self.tp_size = -1 # to be set with given shard config in self.prepare_shard_config
|
||||
self.cache_manager = None
|
||||
|
||||
self.shard_config = shard_config
|
||||
self.model = None
|
||||
# optimize the original model by sharding with ShardFormer
|
||||
self._optimize_model(model=model.to(device))
|
||||
|
||||
def _init_manager(self) -> None:
|
||||
assert self.tp_size >= 1, "TP size not initialized without providing a valid ShardConfig"
|
||||
assert self.head_num % self.tp_size == 0, f"Cannot shard {self.head_num} heads with tp size {self.tp_size}"
|
||||
self.head_num //= self.tp_size # update sharded number of heads
|
||||
self.cache_manager = MemoryManager(self.max_total_token_num, self.dtype, self.head_num, self.head_dim,
|
||||
self.layer_num)
|
||||
|
||||
def _optimize_model(self, model: nn.Module) -> None:
|
||||
"""
|
||||
Optimize the original model by sharding with ShardFormer.
|
||||
In further generation, use the sharded model instead of original model.
|
||||
"""
|
||||
# NOTE we will change to use an inference config later with additional attrs we want
|
||||
assert self.shard_config.inference_only is True
|
||||
shardformer = ShardFormer(shard_config=self.shard_config)
|
||||
self._prepare_with_shard_config(shard_config=self.shard_config)
|
||||
self._shard_model_by(shardformer, model)
|
||||
|
||||
def _prepare_with_shard_config(self, shard_config: Optional[ShardConfig] = None) -> ShardConfig:
|
||||
""" Prepare the engine with a given ShardConfig.
|
||||
|
||||
Args:
|
||||
shard_config (ShardConfig): shard config given to specify settings of the engine.
|
||||
If not provided, a default ShardConfig with tp size 1 will be created.
|
||||
"""
|
||||
self.tp_size = 1
|
||||
if shard_config is None:
|
||||
shard_config = ShardConfig(
|
||||
tensor_parallel_process_group=None,
|
||||
pipeline_stage_manager=None,
|
||||
enable_tensor_parallelism=False,
|
||||
enable_fused_normalization=False,
|
||||
enable_all_optimization=False,
|
||||
enable_flash_attention=False,
|
||||
enable_jit_fused=False,
|
||||
inference_only=True,
|
||||
)
|
||||
else:
|
||||
shard_config.inference_only = True
|
||||
shard_config.pipeline_stage_manager = None
|
||||
if shard_config.enable_tensor_parallelism:
|
||||
self.tp_size = shard_config.tensor_parallel_size
|
||||
self._init_manager()
|
||||
|
||||
return shard_config
|
||||
|
||||
def _shard_model_by(self, shardformer: ShardFormer, model: nn.Module) -> None:
|
||||
""" Shard original model by the given ShardFormer and store the sharded model. """
|
||||
assert self.tp_size == shardformer.shard_config.tensor_parallel_size, \
|
||||
"Discrepancy between the tp size of TPInferEngine and the tp size of shard config"
|
||||
model_name = model.__class__.__name__
|
||||
assert model_name in self.supported_models, f"Unsupported model cls {model_name} for TP inference."
|
||||
policy = get_autopolicy(model, inference_only=True)
|
||||
self.model, _ = shardformer.optimize(model, policy)
|
||||
self.model = self.model.cuda()
|
||||
|
||||
@property
|
||||
def supported_models(self) -> List[str]:
|
||||
return _supported_models
|
||||
|
||||
def generate(self, input_tokens: Union[BatchEncoding, dict, list, torch.Tensor], **generate_kwargs) -> torch.Tensor:
|
||||
"""Generate token sequence.
|
||||
|
||||
Args:
|
||||
input_tokens: could be one of the following types
|
||||
1. BatchEncoding or dict (e.g. tokenizer batch_encode)
|
||||
2. list of input token ids (e.g. appended result of tokenizer encode)
|
||||
3. torch.Tensor (e.g. tokenizer encode with return_tensors='pt')
|
||||
Returns:
|
||||
torch.Tensor: The returned sequence is given inputs + generated_tokens.
|
||||
"""
|
||||
if isinstance(input_tokens, torch.Tensor):
|
||||
input_tokens = dict(input_ids=input_tokens, attention_mask=torch.ones_like(input_tokens, dtype=torch.bool))
|
||||
for t in input_tokens:
|
||||
if torch.is_tensor(input_tokens[t]):
|
||||
input_tokens[t] = input_tokens[t].cuda()
|
||||
if 'max_new_tokens' not in generate_kwargs:
|
||||
generate_kwargs.update(max_new_tokens=self.max_output_len)
|
||||
|
||||
return self._generate_by_set_infer_state(input_tokens, **generate_kwargs)
|
||||
|
||||
def prepare_batch_state(self, inputs) -> BatchInferState:
|
||||
"""
|
||||
Create and prepare BatchInferState used for inference during model forwrad,
|
||||
by processing each sequence of the given inputs.
|
||||
|
||||
Args:
|
||||
inputs: should be one of the following types
|
||||
1. BatchEncoding or dict (e.g. tokenizer batch_encode)
|
||||
2. list of input token ids (e.g. appended result of tokenizer encode)
|
||||
3. torch.Tensor (e.g. tokenizer encode with return_tensors='pt')
|
||||
NOTE For torch.Tensor inputs representing a batch of inputs, we are unable to retrieve
|
||||
the actual length (e.g. number of tokens) of each input without attention mask
|
||||
Hence, for torch.Tensor with shape [bs, l] where bs > 1, we will assume
|
||||
all the inputs in the batch has the maximum length l
|
||||
Returns:
|
||||
BatchInferState: the states for the current batch during inference
|
||||
"""
|
||||
if not isinstance(inputs, (BatchEncoding, dict, list, torch.Tensor)):
|
||||
raise TypeError(f"inputs type {type(inputs)} is not supported in prepare_batch_state")
|
||||
|
||||
input_ids_list = None
|
||||
attention_mask = None
|
||||
|
||||
if isinstance(inputs, (BatchEncoding, dict)):
|
||||
input_ids_list = inputs['input_ids']
|
||||
attention_mask = inputs['attention_mask']
|
||||
else:
|
||||
input_ids_list = inputs
|
||||
if isinstance(input_ids_list[0], int): # for a single input
|
||||
input_ids_list = [input_ids_list]
|
||||
attention_mask = [attention_mask] if attention_mask is not None else attention_mask
|
||||
|
||||
batch_size = len(input_ids_list)
|
||||
|
||||
seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device='cuda')
|
||||
seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device='cuda')
|
||||
start_index = 0
|
||||
|
||||
max_len_in_batch = -1
|
||||
if isinstance(inputs, (BatchEncoding, dict)):
|
||||
for i, attn_mask in enumerate(attention_mask):
|
||||
curr_seq_len = len(attn_mask)
|
||||
# if isinstance(attn_mask, torch.Tensor):
|
||||
# curr_seq_len = int(torch.sum(attn_mask))
|
||||
# else:
|
||||
# curr_seq_len = int(sum(attn_mask))
|
||||
seq_lengths[i] = curr_seq_len
|
||||
seq_start_indexes[i] = start_index
|
||||
start_index += curr_seq_len
|
||||
max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
|
||||
else:
|
||||
length = max(len(input_id) for input_id in input_ids_list)
|
||||
for i, input_ids in enumerate(input_ids_list):
|
||||
curr_seq_len = length
|
||||
seq_lengths[i] = curr_seq_len
|
||||
seq_start_indexes[i] = start_index
|
||||
start_index += curr_seq_len
|
||||
max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
|
||||
block_loc = torch.empty((batch_size, self.max_input_len + self.max_output_len), dtype=torch.long, device='cuda')
|
||||
batch_infer_state = BatchInferState(batch_size, max_len_in_batch)
|
||||
batch_infer_state.seq_len = seq_lengths.to('cuda')
|
||||
batch_infer_state.start_loc = seq_start_indexes.to('cuda')
|
||||
batch_infer_state.block_loc = block_loc
|
||||
batch_infer_state.decode_layer_id = 0
|
||||
batch_infer_state.past_key_values_len = 0
|
||||
batch_infer_state.is_context_stage = True
|
||||
batch_infer_state.set_cache_manager(self.cache_manager)
|
||||
return batch_infer_state
|
||||
|
||||
@torch.no_grad()
|
||||
def _generate_by_set_infer_state(self, input_tokens, **generate_kwargs) -> torch.Tensor:
|
||||
"""
|
||||
Generate output tokens by setting BatchInferState as an attribute to the model and calling model.generate
|
||||
|
||||
Args:
|
||||
inputs: should be one of the following types
|
||||
1. BatchEncoding or dict (e.g. tokenizer batch_encode)
|
||||
2. list of input token ids (e.g. appended result of tokenizer encode)
|
||||
3. torch.Tensor (e.g. tokenizer encode with return_tensors='pt')
|
||||
"""
|
||||
|
||||
# for testing, always use sharded model
|
||||
assert self.model is not None, "sharded model does not exist"
|
||||
|
||||
batch_infer_state = self.prepare_batch_state(input_tokens)
|
||||
assert batch_infer_state.max_len_in_batch <= self.max_input_len, "max length in batch exceeds limit"
|
||||
|
||||
# set BatchInferState for the current batch as attr to model
|
||||
# NOTE this is not a preferable way to pass BatchInferState during inference
|
||||
# we might want to rewrite generate function (e.g. _generate_by_pass_infer_state)
|
||||
# and pass BatchInferState via model forward
|
||||
model = self.model
|
||||
if isinstance(model, LlamaForCausalLM):
|
||||
model = self.model.model
|
||||
elif isinstance(model, BloomForCausalLM):
|
||||
model = self.model.transformer
|
||||
setattr(model, 'infer_state', batch_infer_state)
|
||||
|
||||
outputs = self.model.generate(**input_tokens, **generate_kwargs, early_stopping=False)
|
||||
|
||||
# NOTE In future development, we're going to let the scheduler to handle the cache,
|
||||
# instead of freeing space explicitly at the end of generation
|
||||
self.cache_manager.free_all()
|
||||
|
||||
return outputs
|
||||
|
||||
# TODO might want to implement the func that generates output tokens by passing BatchInferState
|
||||
# as an arg into model.forward.
|
||||
# It requires rewriting model generate and replacing model forward.
|
||||
@torch.no_grad()
|
||||
def _generate_by_pass_infer_state(self,
|
||||
input_tokens,
|
||||
max_out_length: int,
|
||||
generation_config: Optional[GenerationConfig] = None,
|
||||
stopping_criteria: Optional[StoppingCriteriaList] = None,
|
||||
prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
|
||||
**model_kwargs) -> torch.Tensor:
|
||||
|
||||
raise NotImplementedError("generate by passing BatchInferState is not implemented.")
|
||||
|
||||
# might want to use in rewritten generate method: use after model.forward
|
||||
# BatchInferState is created and kept during generation
|
||||
# after each iter of model forward, we should update BatchInferState
|
||||
def _update_batch_state(self, infer_state: Optional[BatchInferState]) -> None:
|
||||
batch_size = infer_state.batch_size
|
||||
device = infer_state.start_loc.device
|
||||
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device=device)
|
||||
infer_state.seq_len += 1
|
||||
|
||||
# might want to create a sequence pool
|
||||
# add a single request/sequence/input text at a time and record its length
|
||||
# In other words, store the actual length of input tokens representing a single input text
|
||||
# E.g. "Introduce landmarks in Beijing"
|
||||
# => add request
|
||||
# => record token length and other necessary information to be used
|
||||
# => engine hold all these necessary information until `generate` (or other name) is called,
|
||||
# => put information already recorded in batchinferstate and pass it to model forward
|
||||
# => clear records in engine
|
||||
def add_request():
|
||||
raise NotImplementedError()
|
||||
|
|
@ -0,0 +1,101 @@
|
|||
# Adapted from lightllm/common/mem_manager.py
|
||||
# of the ModelTC/lightllm GitHub repository
|
||||
# https://github.com/ModelTC/lightllm/blob/050af3ce65edca617e2f30ec2479397d5bb248c9/lightllm/common/mem_manager.py
|
||||
|
||||
import torch
|
||||
from transformers.utils import logging
|
||||
|
||||
|
||||
class MemoryManager:
|
||||
r"""
|
||||
Manage token block indexes and allocate physical memory for key and value cache
|
||||
|
||||
Args:
|
||||
size: maximum token number used as the size of key and value buffer
|
||||
dtype: data type of cached key and value
|
||||
head_num: number of heads the memory manager is responsible for
|
||||
head_dim: embedded size per head
|
||||
layer_num: the number of layers in the model
|
||||
device: device used to store the key and value cache
|
||||
"""
|
||||
|
||||
def __init__(self,
|
||||
size: int,
|
||||
dtype: torch.dtype,
|
||||
head_num: int,
|
||||
head_dim: int,
|
||||
layer_num: int,
|
||||
device: torch.device = torch.device('cuda')):
|
||||
self.logger = logging.get_logger(__name__)
|
||||
self.available_size = size
|
||||
self.past_key_values_length = 0
|
||||
self._init_mem_states(size, device)
|
||||
self._init_kv_buffers(size, device, dtype, head_num, head_dim, layer_num)
|
||||
|
||||
def _init_mem_states(self, size, device):
|
||||
""" Initialize tensors used to manage memory states """
|
||||
self.mem_state = torch.ones((size,), dtype=torch.bool, device=device)
|
||||
self.mem_cum_sum = torch.empty((size,), dtype=torch.int32, device=device)
|
||||
self.indexes = torch.arange(0, size, dtype=torch.long, device=device)
|
||||
|
||||
def _init_kv_buffers(self, size, device, dtype, head_num, head_dim, layer_num):
|
||||
""" Initialize key buffer and value buffer on specified device """
|
||||
self.key_buffer = [
|
||||
torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
|
||||
]
|
||||
self.value_buffer = [
|
||||
torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
|
||||
]
|
||||
|
||||
@torch.no_grad()
|
||||
def alloc(self, required_size):
|
||||
""" allocate space of required_size by providing indexes representing available physical spaces """
|
||||
if required_size > self.available_size:
|
||||
self.logger.warning(f"No enough cache: required_size {required_size} "
|
||||
f"left_size {self.available_size}")
|
||||
return None
|
||||
torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
|
||||
select_index = torch.logical_and(self.mem_cum_sum <= required_size, self.mem_state == 1)
|
||||
select_index = self.indexes[select_index]
|
||||
self.mem_state[select_index] = 0
|
||||
self.available_size -= len(select_index)
|
||||
return select_index
|
||||
|
||||
@torch.no_grad()
|
||||
def alloc_contiguous(self, required_size):
|
||||
""" allocate contiguous space of required_size """
|
||||
if required_size > self.available_size:
|
||||
self.logger.warning(f"No enough cache: required_size {required_size} "
|
||||
f"left_size {self.available_size}")
|
||||
return None
|
||||
torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
|
||||
sum_size = len(self.mem_cum_sum)
|
||||
loc_sums = self.mem_cum_sum[required_size - 1:] - self.mem_cum_sum[0:sum_size - required_size +
|
||||
1] + self.mem_state[0:sum_size -
|
||||
required_size + 1]
|
||||
can_used_loc = self.indexes[0:sum_size - required_size + 1][loc_sums == required_size]
|
||||
if can_used_loc.shape[0] == 0:
|
||||
self.logger.info(f"No enough contiguous cache: required_size {required_size} "
|
||||
f"left_size {self.available_size}")
|
||||
return None
|
||||
start_loc = can_used_loc[0]
|
||||
select_index = self.indexes[start_loc:start_loc + required_size]
|
||||
self.mem_state[select_index] = 0
|
||||
self.available_size -= len(select_index)
|
||||
start = start_loc.item()
|
||||
end = start + required_size
|
||||
return select_index, start, end
|
||||
|
||||
@torch.no_grad()
|
||||
def free(self, free_index):
|
||||
""" free memory by updating memory states based on given indexes """
|
||||
self.available_size += free_index.shape[0]
|
||||
self.mem_state[free_index] = 1
|
||||
|
||||
@torch.no_grad()
|
||||
def free_all(self):
|
||||
""" free all memory by updating memory states """
|
||||
self.available_size = len(self.mem_state)
|
||||
self.mem_state[:] = 1
|
||||
self.past_key_values_length = 0
|
||||
self.logger.info("freed all space of memory manager")
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
from .bloom import BloomInferenceForwards
|
||||
from .llama import LlamaInferenceForwards
|
||||
|
||||
__all__ = ['BloomInferenceForwards', 'LlamaInferenceForwards']
|
||||
|
|
@ -0,0 +1,521 @@
|
|||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from torch.nn import CrossEntropyLoss
|
||||
from torch.nn import functional as F
|
||||
from transformers.models.bloom.modeling_bloom import (
|
||||
BaseModelOutputWithPastAndCrossAttentions,
|
||||
BloomAttention,
|
||||
BloomBlock,
|
||||
BloomForCausalLM,
|
||||
BloomModel,
|
||||
CausalLMOutputWithCrossAttentions,
|
||||
)
|
||||
from transformers.utils import logging
|
||||
|
||||
from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
|
||||
from colossalai.kernel.triton.context_attention import bloom_context_attn_fwd
|
||||
from colossalai.kernel.triton.copy_kv_cache_dest import copy_kv_cache_to_dest
|
||||
from colossalai.kernel.triton.token_attention_kernel import token_attention_fwd
|
||||
|
||||
|
||||
def generate_alibi(n_head, dtype=torch.float16):
|
||||
"""
|
||||
This method is adapted from `_generate_alibi` function
|
||||
in `lightllm/models/bloom/layer_weights/transformer_layer_weight.py`
|
||||
of the ModelTC/lightllm GitHub repository.
|
||||
This method is originally the `build_alibi_tensor` function
|
||||
in `transformers/models/bloom/modeling_bloom.py`
|
||||
of the huggingface/transformers GitHub repository.
|
||||
"""
|
||||
|
||||
def get_slopes_power_of_2(n):
|
||||
start = 2**(-(2**-(math.log2(n) - 3)))
|
||||
return [start * start**i for i in range(n)]
|
||||
|
||||
def get_slopes(n):
|
||||
if math.log2(n).is_integer():
|
||||
return get_slopes_power_of_2(n)
|
||||
else:
|
||||
closest_power_of_2 = 2**math.floor(math.log2(n))
|
||||
slopes_power_of_2 = get_slopes_power_of_2(closest_power_of_2)
|
||||
slopes_double = get_slopes(2 * closest_power_of_2)
|
||||
slopes_combined = slopes_power_of_2 + slopes_double[0::2][:n - closest_power_of_2]
|
||||
return slopes_combined
|
||||
|
||||
slopes = get_slopes(n_head)
|
||||
return torch.tensor(slopes, dtype=dtype)
|
||||
|
||||
|
||||
class BloomInferenceForwards:
|
||||
"""
|
||||
This class serves a micro library for bloom inference forwards.
|
||||
We intend to replace the forward methods for BloomForCausalLM, BloomModel, BloomBlock, and BloomAttention,
|
||||
as well as prepare_inputs_for_generation method for BloomForCausalLM.
|
||||
For future improvement, we might want to skip replacing methods for BloomForCausalLM,
|
||||
and call BloomModel.forward iteratively in TpInferEngine
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def bloom_model_forward(
|
||||
self: BloomModel,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
head_mask: Optional[torch.LongTensor] = None,
|
||||
inputs_embeds: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
**deprecated_arguments,
|
||||
) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
if deprecated_arguments.pop("position_ids", False) is not False:
|
||||
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
|
||||
warnings.warn(
|
||||
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
|
||||
" passing `position_ids`.",
|
||||
FutureWarning,
|
||||
)
|
||||
if len(deprecated_arguments) > 0:
|
||||
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
|
||||
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (output_hidden_states
|
||||
if output_hidden_states is not None else self.config.output_hidden_states)
|
||||
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size, seq_length = input_ids.shape
|
||||
elif inputs_embeds is not None:
|
||||
batch_size, seq_length, _ = inputs_embeds.shape
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
# still need to keep past_key_values to fit original forward flow
|
||||
if past_key_values is None:
|
||||
past_key_values = tuple([None] * len(self.h))
|
||||
|
||||
# Prepare head mask if needed
|
||||
# 1.0 in head_mask indicate we keep the head
|
||||
# attention_probs has shape batch_size x num_heads x N x N
|
||||
# head_mask has shape n_layer x batch x num_heads x N x N
|
||||
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.word_embeddings(input_ids)
|
||||
|
||||
hidden_states = self.word_embeddings_layernorm(inputs_embeds)
|
||||
|
||||
presents = () if use_cache else None
|
||||
all_self_attentions = () if output_attentions else None
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
if use_cache:
|
||||
logger.warning_once(
|
||||
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...")
|
||||
use_cache = False
|
||||
|
||||
# NOTE determine if BatchInferState is passed in via arg
|
||||
# if not, get the attr binded to the model
|
||||
# We might wantto remove setattr later
|
||||
if infer_state is None:
|
||||
assert hasattr(self, 'infer_state')
|
||||
infer_state = self.infer_state
|
||||
|
||||
# Compute alibi tensor: check build_alibi_tensor documentation
|
||||
seq_length_with_past = seq_length
|
||||
past_key_values_length = 0
|
||||
# if self.cache_manager.past_key_values_length > 0:
|
||||
if infer_state.cache_manager.past_key_values_length > 0:
|
||||
# update the past key values length in cache manager,
|
||||
# NOTE use BatchInferState.past_key_values_length instead the one in cache manager
|
||||
past_key_values_length = infer_state.cache_manager.past_key_values_length
|
||||
seq_length_with_past = seq_length_with_past + past_key_values_length
|
||||
|
||||
# infer_state.cache_manager = self.cache_manager
|
||||
|
||||
if use_cache and seq_length != 1:
|
||||
# prefill stage
|
||||
infer_state.is_context_stage = True # set prefill stage, notify attention layer
|
||||
infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
|
||||
BatchInferState.init_block_loc(infer_state.block_loc, infer_state.seq_len, seq_length,
|
||||
infer_state.context_mem_index)
|
||||
else:
|
||||
infer_state.is_context_stage = False
|
||||
alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
|
||||
if alloc_mem is not None:
|
||||
infer_state.decode_is_contiguous = True
|
||||
infer_state.decode_mem_index = alloc_mem[0]
|
||||
infer_state.decode_mem_start = alloc_mem[1]
|
||||
infer_state.decode_mem_end = alloc_mem[2]
|
||||
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
|
||||
else:
|
||||
print(f" *** Encountered allocation non-contiguous")
|
||||
print(
|
||||
f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
|
||||
)
|
||||
infer_state.decode_is_contiguous = False
|
||||
alloc_mem = infer_state.cache_manager.alloc(batch_size)
|
||||
infer_state.decode_mem_index = alloc_mem
|
||||
# infer_state.decode_key_buffer = torch.empty((batch_size, self.tp_head_num_, self.head_dim_), dtype=torch.float16, device="cuda")
|
||||
# infer_state.decode_value_buffer = torch.empty((batch_size, self.tp_head_num_, self.head_dim_), dtype=torch.float16, device="cuda")
|
||||
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
|
||||
|
||||
if attention_mask is None:
|
||||
attention_mask = torch.ones((batch_size, seq_length_with_past), device=hidden_states.device)
|
||||
else:
|
||||
attention_mask = attention_mask.to(hidden_states.device)
|
||||
|
||||
# NOTE revise: we might want to store a single 1D alibi(length is #heads) in model,
|
||||
# or store to BatchInferState to prevent re-calculating
|
||||
# When we have multiple process group (e.g. dp together with tp), we need to pass the pg to here
|
||||
# alibi = generate_alibi(self.num_heads).contiguous().cuda()
|
||||
tp_size = dist.get_world_size()
|
||||
curr_tp_rank = dist.get_rank()
|
||||
alibi = generate_alibi(self.num_heads * tp_size).contiguous()[curr_tp_rank * self.num_heads:(curr_tp_rank + 1) *
|
||||
self.num_heads].cuda()
|
||||
causal_mask = self._prepare_attn_mask(
|
||||
attention_mask,
|
||||
input_shape=(batch_size, seq_length),
|
||||
past_key_values_length=past_key_values_length,
|
||||
)
|
||||
|
||||
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
|
||||
if output_hidden_states:
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
# NOTE: currently our KV cache manager does not handle this condition
|
||||
def create_custom_forward(module):
|
||||
|
||||
def custom_forward(*inputs):
|
||||
# None for past_key_value
|
||||
return module(*inputs, use_cache=use_cache, output_attentions=output_attentions)
|
||||
|
||||
return custom_forward
|
||||
|
||||
outputs = torch.utils.checkpoint.checkpoint(
|
||||
create_custom_forward(block),
|
||||
hidden_states,
|
||||
alibi,
|
||||
causal_mask,
|
||||
layer_past,
|
||||
head_mask[i],
|
||||
)
|
||||
else:
|
||||
outputs = block(
|
||||
hidden_states,
|
||||
layer_past=layer_past,
|
||||
attention_mask=causal_mask,
|
||||
head_mask=head_mask[i],
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
alibi=alibi,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
|
||||
hidden_states = outputs[0]
|
||||
if use_cache is True:
|
||||
presents = presents + (outputs[1],)
|
||||
|
||||
if output_attentions:
|
||||
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
|
||||
|
||||
# Add last hidden state
|
||||
hidden_states = self.ln_f(hidden_states)
|
||||
|
||||
if output_hidden_states:
|
||||
all_hidden_states = all_hidden_states + (hidden_states,)
|
||||
|
||||
# update indices of kv cache block
|
||||
# NOT READY FOR PRIME TIME
|
||||
# might want to remove this part, instead, better to pass the BatchInferState from model forward,
|
||||
# and update these information in engine.generate after model foward called
|
||||
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
|
||||
infer_state.seq_len += 1
|
||||
infer_state.decode_layer_id = 0
|
||||
|
||||
if not return_dict:
|
||||
return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
|
||||
|
||||
return BaseModelOutputWithPastAndCrossAttentions(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=presents, # should always be (None, None, ..., None)
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_self_attentions,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def bloom_for_causal_lm_forward(self: BloomForCausalLM,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
head_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
labels: Optional[torch.Tensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
**deprecated_arguments):
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
|
||||
`labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
|
||||
are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
|
||||
"""
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
if deprecated_arguments.pop("position_ids", False) is not False:
|
||||
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
|
||||
warnings.warn(
|
||||
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
|
||||
" passing `position_ids`.",
|
||||
FutureWarning,
|
||||
)
|
||||
if len(deprecated_arguments) > 0:
|
||||
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
|
||||
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
transformer_outputs = BloomInferenceForwards.bloom_model_forward(self.transformer,
|
||||
input_ids,
|
||||
past_key_values=past_key_values,
|
||||
attention_mask=attention_mask,
|
||||
head_mask=head_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
infer_state=infer_state)
|
||||
hidden_states = transformer_outputs[0]
|
||||
|
||||
lm_logits = self.lm_head(hidden_states)
|
||||
|
||||
loss = None
|
||||
if labels is not None:
|
||||
# move labels to correct device to enable model parallelism
|
||||
labels = labels.to(lm_logits.device)
|
||||
# Shift so that tokens < n predict n
|
||||
shift_logits = lm_logits[..., :-1, :].contiguous()
|
||||
shift_labels = labels[..., 1:].contiguous()
|
||||
batch_size, seq_length, vocab_size = shift_logits.shape
|
||||
# Flatten the tokens
|
||||
loss_fct = CrossEntropyLoss()
|
||||
loss = loss_fct(shift_logits.view(batch_size * seq_length, vocab_size),
|
||||
shift_labels.view(batch_size * seq_length))
|
||||
|
||||
if not return_dict:
|
||||
output = (lm_logits,) + transformer_outputs[1:]
|
||||
return ((loss,) + output) if loss is not None else output
|
||||
|
||||
return CausalLMOutputWithCrossAttentions(
|
||||
loss=loss,
|
||||
logits=lm_logits,
|
||||
past_key_values=transformer_outputs.past_key_values,
|
||||
hidden_states=transformer_outputs.hidden_states,
|
||||
attentions=transformer_outputs.attentions,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def bloom_for_causal_lm_prepare_inputs_for_generation(
|
||||
self: BloomForCausalLM,
|
||||
input_ids: torch.LongTensor,
|
||||
past_key_values: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
**kwargs,
|
||||
) -> dict:
|
||||
# only last token for input_ids if past is not None
|
||||
if past_key_values:
|
||||
input_ids = input_ids[:, -1].unsqueeze(-1)
|
||||
|
||||
# NOTE we won't use past key values here
|
||||
# the cache may be in the stardard format (e.g. in contrastive search), convert to bloom's format if needed
|
||||
# if past_key_values[0][0].shape[0] == input_ids.shape[0]:
|
||||
# past_key_values = self._convert_to_bloom_cache(past_key_values)
|
||||
|
||||
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
||||
if inputs_embeds is not None and past_key_values is None:
|
||||
model_inputs = {"inputs_embeds": inputs_embeds}
|
||||
else:
|
||||
model_inputs = {"input_ids": input_ids}
|
||||
|
||||
model_inputs.update({
|
||||
"past_key_values": past_key_values,
|
||||
"use_cache": kwargs.get("use_cache"),
|
||||
"attention_mask": attention_mask,
|
||||
})
|
||||
return model_inputs
|
||||
|
||||
@staticmethod
|
||||
def bloom_block_forward(
|
||||
self: BloomBlock,
|
||||
hidden_states: torch.Tensor,
|
||||
alibi: torch.Tensor,
|
||||
attention_mask: torch.Tensor,
|
||||
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
|
||||
head_mask: Optional[torch.Tensor] = None,
|
||||
use_cache: bool = False,
|
||||
output_attentions: bool = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
):
|
||||
# hidden_states: [batch_size, seq_length, hidden_size]
|
||||
|
||||
# Layer norm at the beginning of the transformer layer.
|
||||
layernorm_output = self.input_layernorm(hidden_states)
|
||||
|
||||
# Layer norm post the self attention.
|
||||
if self.apply_residual_connection_post_layernorm:
|
||||
residual = layernorm_output
|
||||
else:
|
||||
residual = hidden_states
|
||||
|
||||
# Self attention.
|
||||
attn_outputs = self.self_attention(
|
||||
layernorm_output,
|
||||
residual,
|
||||
layer_past=layer_past,
|
||||
attention_mask=attention_mask,
|
||||
alibi=alibi,
|
||||
head_mask=head_mask,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
|
||||
attention_output = attn_outputs[0]
|
||||
|
||||
outputs = attn_outputs[1:]
|
||||
|
||||
layernorm_output = self.post_attention_layernorm(attention_output)
|
||||
|
||||
# Get residual
|
||||
if self.apply_residual_connection_post_layernorm:
|
||||
residual = layernorm_output
|
||||
else:
|
||||
residual = attention_output
|
||||
|
||||
# MLP.
|
||||
output = self.mlp(layernorm_output, residual)
|
||||
|
||||
if use_cache:
|
||||
outputs = (output,) + outputs
|
||||
else:
|
||||
outputs = (output,) + outputs[1:]
|
||||
|
||||
return outputs # hidden_states, present, attentions
|
||||
|
||||
@staticmethod
|
||||
def bloom_attention_forward(
|
||||
self: BloomAttention,
|
||||
hidden_states: torch.Tensor,
|
||||
residual: torch.Tensor,
|
||||
alibi: torch.Tensor,
|
||||
attention_mask: torch.Tensor,
|
||||
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
|
||||
head_mask: Optional[torch.Tensor] = None,
|
||||
use_cache: bool = False,
|
||||
output_attentions: bool = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
):
|
||||
|
||||
fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
|
||||
|
||||
# 3 x [batch_size, seq_length, num_heads, head_dim]
|
||||
(query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
|
||||
batch_size, q_length, H, D_HEAD = query_layer.shape
|
||||
k = key_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
|
||||
v = value_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
|
||||
|
||||
mem_manager = infer_state.cache_manager
|
||||
layer_id = infer_state.decode_layer_id
|
||||
|
||||
if layer_id == 0: # once per model.forward
|
||||
infer_state.cache_manager.past_key_values_length += q_length # += 1
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
# context process
|
||||
max_input_len = q_length
|
||||
b_start_loc = infer_state.start_loc
|
||||
b_seq_len = infer_state.seq_len[:batch_size]
|
||||
q = query_layer.reshape(-1, H, D_HEAD)
|
||||
|
||||
copy_kv_cache_to_dest(k, infer_state.context_mem_index, mem_manager.key_buffer[layer_id])
|
||||
copy_kv_cache_to_dest(v, infer_state.context_mem_index, mem_manager.value_buffer[layer_id])
|
||||
|
||||
# output = self.output[:batch_size*q_length, :, :]
|
||||
output = torch.empty_like(q)
|
||||
|
||||
bloom_context_attn_fwd(q, k, v, output, b_start_loc, b_seq_len, max_input_len, alibi)
|
||||
|
||||
context_layer = output.view(batch_size, q_length, H * D_HEAD)
|
||||
else:
|
||||
# query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
|
||||
# need shape: batch_size, H, D_HEAD (q_length == 1), input q shape : (batch_size, q_length(1), H, D_HEAD)
|
||||
assert q_length == 1, "for non-context process, we only support q_length == 1"
|
||||
q = query_layer.reshape(-1, H, D_HEAD)
|
||||
|
||||
if infer_state.decode_is_contiguous:
|
||||
# if decode is contiguous, then we copy to key cache and value cache in cache manager directly
|
||||
cache_k = infer_state.cache_manager.key_buffer[layer_id][
|
||||
infer_state.decode_mem_start:infer_state.decode_mem_end, :, :]
|
||||
cache_v = infer_state.cache_manager.value_buffer[layer_id][
|
||||
infer_state.decode_mem_start:infer_state.decode_mem_end, :, :]
|
||||
cache_k.copy_(k)
|
||||
cache_v.copy_(v)
|
||||
else:
|
||||
# if decode is not contiguous, use triton kernel to copy key and value cache
|
||||
# k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head]
|
||||
copy_kv_cache_to_dest(k, infer_state.decode_mem_index, mem_manager.key_buffer[layer_id])
|
||||
copy_kv_cache_to_dest(v, infer_state.decode_mem_index, mem_manager.value_buffer[layer_id])
|
||||
|
||||
b_start_loc = infer_state.start_loc
|
||||
b_loc = infer_state.block_loc
|
||||
b_seq_len = infer_state.seq_len
|
||||
output = torch.empty_like(q)
|
||||
token_attention_fwd(q, mem_manager.key_buffer[layer_id], mem_manager.value_buffer[layer_id], output, b_loc,
|
||||
b_start_loc, b_seq_len, infer_state.cache_manager.past_key_values_length, alibi)
|
||||
|
||||
context_layer = output.view(batch_size, q_length, H * D_HEAD)
|
||||
|
||||
# update layer id
|
||||
infer_state.decode_layer_id += 1
|
||||
|
||||
# NOTE: always set present as none for now, instead of returning past key value to the next decoding,
|
||||
# we create the past key value pair from the cache manager
|
||||
present = None
|
||||
|
||||
# aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
|
||||
if self.pretraining_tp > 1 and self.slow_but_exact:
|
||||
slices = self.hidden_size / self.pretraining_tp
|
||||
output_tensor = torch.zeros_like(context_layer)
|
||||
for i in range(self.pretraining_tp):
|
||||
output_tensor = output_tensor + F.linear(
|
||||
context_layer[:, :, int(i * slices):int((i + 1) * slices)],
|
||||
self.dense.weight[:, int(i * slices):int((i + 1) * slices)],
|
||||
)
|
||||
else:
|
||||
output_tensor = self.dense(context_layer)
|
||||
|
||||
# dropout is not required here during inference
|
||||
output_tensor = residual + output_tensor
|
||||
|
||||
outputs = (output_tensor, present)
|
||||
assert output_attentions is False, "we do not support output_attentions at this time"
|
||||
|
||||
return outputs
|
||||
|
|
@ -0,0 +1,359 @@
|
|||
from typing import List, Optional, Tuple
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from transformers.modeling_outputs import BaseModelOutputWithPast
|
||||
from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaModel, LlamaRMSNorm
|
||||
|
||||
from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
|
||||
from colossalai.kernel.triton.context_attention import llama_context_attn_fwd
|
||||
from colossalai.kernel.triton.copy_kv_cache_dest import copy_kv_cache_to_dest
|
||||
from colossalai.kernel.triton.rotary_embedding_kernel import rotary_embedding_fwd
|
||||
from colossalai.kernel.triton.token_attention_kernel import token_attention_fwd
|
||||
|
||||
try:
|
||||
from vllm import layernorm_ops, pos_encoding_ops
|
||||
rms_norm = layernorm_ops.rms_norm
|
||||
rotary_embedding_neox = pos_encoding_ops.rotary_embedding_neox
|
||||
HAS_VLLM_KERNERL = True
|
||||
except:
|
||||
print("fall back to original rotary_embedding_neox of huggingface")
|
||||
print("install vllm from https://github.com/vllm-project/vllm to accelerate your inference")
|
||||
print(
|
||||
"if falied to install vllm, please use this branch to install: https://github.com/tiandiao123/vllm/tree/setup_branch"
|
||||
)
|
||||
HAS_VLLM_KERNERL = False
|
||||
|
||||
|
||||
def rotate_half(x):
|
||||
"""Rotates half the hidden dims of the input."""
|
||||
x1 = x[..., :x.shape[-1] // 2]
|
||||
x2 = x[..., x.shape[-1] // 2:]
|
||||
return torch.cat((-x2, x1), dim=-1)
|
||||
|
||||
|
||||
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
|
||||
# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
|
||||
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
|
||||
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
|
||||
cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
|
||||
sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
|
||||
|
||||
q_embed = (q * cos) + (rotate_half(q) * sin)
|
||||
k_embed = (k * cos) + (rotate_half(k) * sin)
|
||||
return q_embed, k_embed
|
||||
|
||||
|
||||
def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
|
||||
copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
|
||||
copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
|
||||
return
|
||||
|
||||
|
||||
class LlamaInferenceForwards:
|
||||
"""
|
||||
This class holds forwards for llama inference.
|
||||
We intend to replace the forward methods for LlamaModel, LlamaDecoderLayer, and LlamaAttention for LlamaForCausalLM.
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def llama_model_forward(
|
||||
self: LlamaModel,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
):
|
||||
|
||||
batch_size = input_ids.shape[0] # input_ids.shape[0]
|
||||
|
||||
infer_state = self.infer_state
|
||||
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size, seq_length = input_ids.shape
|
||||
elif inputs_embeds is not None:
|
||||
batch_size, seq_length, _ = inputs_embeds.shape
|
||||
else:
|
||||
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
|
||||
|
||||
seq_length_with_past = seq_length
|
||||
past_key_values_length = 0
|
||||
|
||||
if past_key_values is not None:
|
||||
# NOT READY FOR PRIME TIME
|
||||
# dummy but work, revise it
|
||||
past_key_values_length = infer_state.cache_manager.past_key_values_length
|
||||
# past_key_values_length = past_key_values[0][0].shape[2]
|
||||
seq_length_with_past = seq_length_with_past + past_key_values_length
|
||||
|
||||
# NOTE: differentiate with prefill stage
|
||||
# block_loc require different value-assigning method for two different stage
|
||||
if use_cache and seq_length != 1:
|
||||
# NOTE assuem prefill stage
|
||||
# allocate memory block
|
||||
infer_state.is_context_stage = True # set prefill stage, notify attention layer
|
||||
infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
|
||||
infer_state.init_block_loc(infer_state.block_loc, infer_state.seq_len, seq_length,
|
||||
infer_state.context_mem_index)
|
||||
else:
|
||||
infer_state.is_context_stage = False
|
||||
alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
|
||||
if alloc_mem is not None:
|
||||
infer_state.decode_is_contiguous = True
|
||||
infer_state.decode_mem_index = alloc_mem[0]
|
||||
infer_state.decode_mem_start = alloc_mem[1]
|
||||
infer_state.decode_mem_end = alloc_mem[2]
|
||||
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
|
||||
else:
|
||||
print(f" *** Encountered allocation non-contiguous")
|
||||
print(
|
||||
f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
|
||||
)
|
||||
infer_state.decode_is_contiguous = False
|
||||
alloc_mem = infer_state.cache_manager.alloc(batch_size)
|
||||
infer_state.decode_mem_index = alloc_mem
|
||||
# infer_state.decode_key_buffer = torch.empty((batch_size, self.tp_head_num_, self.head_dim_), dtype=torch.float16, device="cuda")
|
||||
# infer_state.decode_value_buffer = torch.empty((batch_size, self.tp_head_num_, self.head_dim_), dtype=torch.float16, device="cuda")
|
||||
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
|
||||
if position_ids is None:
|
||||
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
||||
position_ids = torch.arange(past_key_values_length,
|
||||
seq_length + past_key_values_length,
|
||||
dtype=torch.long,
|
||||
device=device)
|
||||
position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
|
||||
else:
|
||||
position_ids = position_ids.view(-1, seq_length).long()
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
|
||||
infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
|
||||
position_ids.view(-1).shape[0], -1)
|
||||
infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
|
||||
position_ids.view(-1).shape[0], -1)
|
||||
else:
|
||||
seq_len = infer_state.seq_len
|
||||
infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
|
||||
infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embed_tokens(input_ids)
|
||||
|
||||
# embed positions
|
||||
if attention_mask is None:
|
||||
attention_mask = torch.ones((batch_size, seq_length_with_past),
|
||||
dtype=torch.bool,
|
||||
device=inputs_embeds.device)
|
||||
|
||||
attention_mask = self._prepare_decoder_attention_mask(attention_mask, (batch_size, seq_length), inputs_embeds,
|
||||
past_key_values_length)
|
||||
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
# decoder layers
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_self_attns = () if output_attentions else None
|
||||
next_decoder_cache = () if use_cache else None
|
||||
|
||||
infer_state.decode_layer_id = 0
|
||||
|
||||
for idx, decoder_layer in enumerate(self.layers):
|
||||
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
||||
# NOTE: modify here for passing args to decoder layer
|
||||
layer_outputs = decoder_layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
infer_state.decode_layer_id += 1
|
||||
hidden_states = layer_outputs[0]
|
||||
|
||||
if use_cache:
|
||||
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
next_cache = next_decoder_cache if use_cache else None
|
||||
|
||||
# update indices
|
||||
# infer_state.block_loc[:, infer_state.max_len_in_batch-1] = infer_state.total_token_num + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
|
||||
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
|
||||
infer_state.seq_len += 1
|
||||
|
||||
if not return_dict:
|
||||
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
||||
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_self_attns,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def llama_decoder_layer_forward(
|
||||
self: LlamaDecoderLayer,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: Optional[bool] = False,
|
||||
use_cache: Optional[bool] = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = self.input_layernorm(hidden_states)
|
||||
|
||||
# Self Attention
|
||||
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
# Fully Connected
|
||||
residual = hidden_states
|
||||
hidden_states = self.post_attention_layernorm(hidden_states)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states,)
|
||||
|
||||
if output_attentions:
|
||||
outputs += (self_attn_weights,)
|
||||
|
||||
if use_cache:
|
||||
outputs += (present_key_value,)
|
||||
|
||||
return outputs
|
||||
|
||||
@staticmethod
|
||||
def llama_flash_attn_kvcache_forward(
|
||||
self: LlamaAttention,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
|
||||
assert use_cache is True, "use_cache should be set to True using this llama attention"
|
||||
|
||||
bsz, q_len, _ = hidden_states.size()
|
||||
|
||||
# NOTE might think about better way to handle transposed k and v
|
||||
# key_states [bs, seq_len, num_heads, head_dim/embed_size_per_head]
|
||||
# key_states_transposed [bs, num_heads, seq_len, head_dim/embed_size_per_head]
|
||||
|
||||
query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
|
||||
key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
|
||||
value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
|
||||
|
||||
# NOTE might want to revise
|
||||
# need some way to record the length of past key values cache
|
||||
# since we won't return past_key_value_cache right now
|
||||
if infer_state.decode_layer_id == 0: # once per model.forward
|
||||
infer_state.cache_manager.past_key_values_length += q_len # seq_len
|
||||
|
||||
cos, sin = infer_state.position_cos, infer_state.position_sin
|
||||
# print("shape ", cos.shape, query_states.view(-1, self.num_heads, self.head_dim).shape, )
|
||||
|
||||
rotary_embedding_fwd(query_states.view(-1, self.num_heads, self.head_dim), cos, sin)
|
||||
rotary_embedding_fwd(key_states.view(-1, self.num_heads, self.head_dim), cos, sin)
|
||||
|
||||
def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
|
||||
copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
|
||||
copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
|
||||
return
|
||||
|
||||
query_states = query_states.reshape(-1, self.num_heads, self.head_dim)
|
||||
key_states = key_states.reshape(-1, self.num_heads, self.head_dim)
|
||||
value_states = value_states.reshape(-1, self.num_heads, self.head_dim)
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
# first token generation
|
||||
|
||||
# copy key and value calculated in current step to memory manager
|
||||
_copy_kv_to_mem_cache(infer_state.decode_layer_id, key_states, value_states, infer_state.context_mem_index,
|
||||
infer_state.cache_manager)
|
||||
|
||||
attn_output = torch.empty_like(query_states)
|
||||
|
||||
llama_context_attn_fwd(query_states, key_states, value_states, attn_output, infer_state.start_loc,
|
||||
infer_state.seq_len, infer_state.cache_manager.past_key_values_length)
|
||||
else:
|
||||
|
||||
if infer_state.decode_is_contiguous:
|
||||
# if decode is contiguous, then we copy to key cache and value cache in cache manager directly
|
||||
cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
|
||||
infer_state.decode_mem_start:infer_state.decode_mem_end, :, :]
|
||||
cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
|
||||
infer_state.decode_mem_start:infer_state.decode_mem_end, :, :]
|
||||
cache_k.copy_(key_states)
|
||||
cache_v.copy_(value_states)
|
||||
else:
|
||||
# if decode is not contiguous, use triton kernel to copy key and value cache
|
||||
# k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
|
||||
_copy_kv_to_mem_cache(infer_state.decode_layer_id, key_states, value_states,
|
||||
infer_state.decode_mem_index, infer_state.cache_manager)
|
||||
|
||||
# second token and follows
|
||||
# kv = torch.stack((key_states, value_states), dim=2)
|
||||
# (batch_size, seqlen, nheads, headdim)
|
||||
attn_output = torch.empty_like(query_states)
|
||||
|
||||
token_attention_fwd(query_states, infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
|
||||
infer_state.cache_manager.value_buffer[infer_state.decode_layer_id], attn_output,
|
||||
infer_state.block_loc, infer_state.start_loc, infer_state.seq_len,
|
||||
infer_state.cache_manager.past_key_values_length)
|
||||
|
||||
attn_output = attn_output.view(bsz, q_len, self.hidden_size)
|
||||
|
||||
attn_output = self.o_proj(attn_output)
|
||||
|
||||
# return past_key_value as None
|
||||
return attn_output, None, None
|
||||
|
||||
|
||||
def get_llama_vllm_rmsnorm_forward():
|
||||
|
||||
if HAS_VLLM_KERNERL:
|
||||
|
||||
def _vllm_rmsnorm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor):
|
||||
x = hidden_states
|
||||
out = torch.empty_like(x)
|
||||
rms_norm(
|
||||
out,
|
||||
x,
|
||||
self.weight.data,
|
||||
self.variance_epsilon,
|
||||
)
|
||||
|
||||
return out
|
||||
|
||||
return _vllm_rmsnorm_forward
|
||||
else:
|
||||
return None
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
from .bloom import BloomModelInferPolicy
|
||||
from .llama import LlamaModelInferPolicy
|
||||
|
||||
__all__ = ['BloomModelInferPolicy', 'LlamaModelInferPolicy']
|
||||
|
|
@ -0,0 +1,66 @@
|
|||
from functools import partial
|
||||
|
||||
import torch
|
||||
from torch.nn import LayerNorm
|
||||
|
||||
from colossalai.shardformer.policies.bloom import BloomForCausalLMPolicy
|
||||
|
||||
from ..modeling.bloom import BloomInferenceForwards
|
||||
|
||||
try:
|
||||
from colossalai.kernel.triton.fused_layernorm import layer_norm
|
||||
HAS_TRITON_NORM = True
|
||||
except:
|
||||
print("you should install triton from https://github.com/openai/triton")
|
||||
HAS_TRITON_NORM = False
|
||||
|
||||
|
||||
def get_triton_layernorm_forward():
|
||||
if HAS_TRITON_NORM:
|
||||
|
||||
def _triton_layernorm_forward(self: LayerNorm, hidden_states: torch.Tensor):
|
||||
return layer_norm(hidden_states, self.weight.data, self.bias, self.eps)
|
||||
|
||||
return _triton_layernorm_forward
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class BloomModelInferPolicy(BloomForCausalLMPolicy):
|
||||
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
def module_policy(self):
|
||||
from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomForCausalLM, BloomModel
|
||||
policy = super().module_policy()
|
||||
# NOTE set inference mode to shard config
|
||||
self.shard_config._infer()
|
||||
|
||||
method_replacement = {
|
||||
'forward': BloomInferenceForwards.bloom_for_causal_lm_forward,
|
||||
'prepare_inputs_for_generation': BloomInferenceForwards.bloom_for_causal_lm_prepare_inputs_for_generation
|
||||
}
|
||||
self.append_or_create_method_replacement(description=method_replacement,
|
||||
policy=policy,
|
||||
target_key=BloomForCausalLM)
|
||||
|
||||
method_replacement = {'forward': BloomInferenceForwards.bloom_model_forward}
|
||||
self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomModel)
|
||||
|
||||
method_replacement = {'forward': BloomInferenceForwards.bloom_block_forward}
|
||||
self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomBlock)
|
||||
|
||||
method_replacement = {'forward': BloomInferenceForwards.bloom_attention_forward}
|
||||
self.append_or_create_method_replacement(description=method_replacement,
|
||||
policy=policy,
|
||||
target_key=BloomAttention)
|
||||
|
||||
if HAS_TRITON_NORM:
|
||||
infer_method = get_triton_layernorm_forward()
|
||||
method_replacement = {'forward': partial(infer_method)}
|
||||
self.append_or_create_method_replacement(description=method_replacement,
|
||||
policy=policy,
|
||||
target_key=LayerNorm)
|
||||
|
||||
return policy
|
||||
|
|
@ -0,0 +1,70 @@
|
|||
from functools import partial
|
||||
import torch
|
||||
from transformers.models.llama.modeling_llama import (
|
||||
LlamaAttention,
|
||||
LlamaDecoderLayer,
|
||||
LlamaModel,
|
||||
LlamaRMSNorm
|
||||
)
|
||||
|
||||
# import colossalai
|
||||
from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
|
||||
from ..modeling.llama import LlamaInferenceForwards, get_llama_vllm_rmsnorm_forward
|
||||
|
||||
try:
|
||||
from colossalai.kernel.triton.rms_norm import rmsnorm_forward
|
||||
HAS_TRITON_RMSNORM = True
|
||||
except:
|
||||
print("you should install triton from https://github.com/openai/triton")
|
||||
HAS_TRITON_RMSNORM = False
|
||||
|
||||
|
||||
def get_triton_rmsnorm_forward():
|
||||
if HAS_TRITON_RMSNORM:
|
||||
def _triton_rmsnorm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor):
|
||||
return rmsnorm_forward(hidden_states, self.weight.data, self.variance_epsilon)
|
||||
|
||||
return _triton_rmsnorm_forward
|
||||
else:
|
||||
return None
|
||||
|
||||
class LlamaModelInferPolicy(LlamaForCausalLMPolicy):
|
||||
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
def module_policy(self):
|
||||
policy = super().module_policy()
|
||||
self.shard_config._infer()
|
||||
|
||||
infer_forward = LlamaInferenceForwards.llama_model_forward
|
||||
method_replacement = {'forward': partial(infer_forward)}
|
||||
self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
|
||||
|
||||
infer_forward = LlamaInferenceForwards.llama_decoder_layer_forward
|
||||
method_replacement = {'forward': partial(infer_forward)}
|
||||
self.append_or_create_method_replacement(description=method_replacement,
|
||||
policy=policy,
|
||||
target_key=LlamaDecoderLayer)
|
||||
|
||||
infer_forward = LlamaInferenceForwards.llama_flash_attn_kvcache_forward
|
||||
method_replacement = {'forward': partial(infer_forward)}
|
||||
self.append_or_create_method_replacement(description=method_replacement,
|
||||
policy=policy,
|
||||
target_key=LlamaAttention)
|
||||
|
||||
infer_forward = None
|
||||
if HAS_TRITON_RMSNORM:
|
||||
infer_forward = get_triton_rmsnorm_forward()
|
||||
else:
|
||||
# NOTE: adding rms_norm from cuda kernels caused precision issue, fix @tiandiao123
|
||||
infer_forward = get_llama_vllm_rmsnorm_forward()
|
||||
|
||||
if infer_forward is not None:
|
||||
method_replacement = {'forward': partial(infer_forward)}
|
||||
self.append_or_create_method_replacement(description=method_replacement,
|
||||
policy=policy,
|
||||
target_key=LlamaRMSNorm)
|
||||
|
||||
return policy
|
||||
|
||||
|
|
@ -1,7 +1,14 @@
|
|||
from .cuda_native import FusedScaleMaskSoftmax, LayerNorm, MultiHeadAttention
|
||||
from .triton import llama_context_attn_fwd, bloom_context_attn_fwd
|
||||
from .triton import softmax
|
||||
from .triton import copy_kv_cache_to_dest
|
||||
|
||||
__all__ = [
|
||||
"LayerNorm",
|
||||
"FusedScaleMaskSoftmax",
|
||||
"MultiHeadAttention",
|
||||
"llama_context_attn_fwd",
|
||||
"bloom_context_attn_fwd",
|
||||
"softmax",
|
||||
"copy_kv_cache_to_dest",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -0,0 +1,5 @@
|
|||
from .context_attention import bloom_context_attn_fwd, llama_context_attn_fwd
|
||||
from .copy_kv_cache_dest import copy_kv_cache_to_dest
|
||||
from .fused_layernorm import layer_norm
|
||||
from .rms_norm import rmsnorm_forward
|
||||
from .softmax import softmax
|
||||
|
|
@ -0,0 +1,184 @@
|
|||
import torch
|
||||
import math
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
|
||||
if HAS_TRITON:
|
||||
'''
|
||||
this function is modified from
|
||||
https://github.com/ModelTC/lightllm/blob/f093edc20683ac3ea1bca3fb5d8320a0dd36cf7b/lightllm/models/llama/triton_kernel/context_flashattention_nopad.py#L10
|
||||
'''
|
||||
@triton.jit
|
||||
def _context_flash_attention_kernel(
|
||||
Q, K, V, sm_scale,
|
||||
B_Start_Loc, B_Seqlen,
|
||||
TMP,
|
||||
alibi_ptr,
|
||||
Out,
|
||||
stride_qbs, stride_qh, stride_qd,
|
||||
stride_kbs, stride_kh, stride_kd,
|
||||
stride_vbs, stride_vh, stride_vd,
|
||||
stride_obs, stride_oh, stride_od,
|
||||
stride_tmp_b, stride_tmp_h, stride_tmp_s,
|
||||
# suggtest set-up 64, 128, 256, 512
|
||||
BLOCK_M: tl.constexpr,
|
||||
BLOCK_DMODEL: tl.constexpr,
|
||||
BLOCK_N: tl.constexpr,
|
||||
):
|
||||
|
||||
batch_id = tl.program_id(0)
|
||||
cur_head = tl.program_id(1)
|
||||
start_m = tl.program_id(2)
|
||||
|
||||
# initialize offsets
|
||||
offs_n = tl.arange(0, BLOCK_N)
|
||||
offs_d = tl.arange(0, BLOCK_DMODEL)
|
||||
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
|
||||
|
||||
# get batch info
|
||||
cur_batch_seq_len = tl.load(B_Seqlen + batch_id)
|
||||
cur_batch_start_index = tl.load(B_Start_Loc + batch_id)
|
||||
block_start_loc = BLOCK_M * start_m
|
||||
|
||||
load_p_ptrs = Q + (cur_batch_start_index + offs_m[:, None]) * stride_qbs + cur_head * stride_qh + offs_d[None, :] * stride_qd
|
||||
q = tl.load(load_p_ptrs, mask=offs_m[:, None] < cur_batch_seq_len, other=0.0)
|
||||
|
||||
k_ptrs = K + offs_n[None, :] * stride_kbs + cur_head * stride_kh + offs_d[:, None] * stride_kd
|
||||
v_ptrs = V + offs_n[:, None] * stride_vbs + cur_head * stride_vh + offs_d[None, :] * stride_vd
|
||||
t_ptrs = TMP + batch_id * stride_tmp_b + cur_head * stride_tmp_h + offs_m * stride_tmp_s
|
||||
|
||||
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
|
||||
l_i = tl.zeros([BLOCK_M], dtype=tl.float32)
|
||||
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
|
||||
|
||||
if alibi_ptr is not None:
|
||||
alibi_m = tl.load(alibi_ptr + cur_head)
|
||||
|
||||
block_mask = tl.where(block_start_loc < cur_batch_seq_len, 1, 0)
|
||||
|
||||
for start_n in range(0, block_mask * (start_m + 1) * BLOCK_M, BLOCK_N):
|
||||
start_n = tl.multiple_of(start_n, BLOCK_N)
|
||||
k = tl.load(k_ptrs + (cur_batch_start_index + start_n) * stride_kbs,
|
||||
mask=(start_n + offs_n[None, :]) < cur_batch_seq_len, other=0.0)
|
||||
|
||||
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
|
||||
qk += tl.dot(q, k)
|
||||
qk *= sm_scale
|
||||
|
||||
if alibi_ptr is not None:
|
||||
alibi_loc = offs_m[:, None] - (start_n + offs_n[None, :])
|
||||
qk -= alibi_loc * alibi_m
|
||||
|
||||
qk = tl.where(offs_m[:, None] >= (start_n + offs_n[None, :]), qk, float("-inf"))
|
||||
|
||||
m_ij = tl.max(qk, 1)
|
||||
p = tl.exp(qk - m_ij[:, None])
|
||||
l_ij = tl.sum(p, 1)
|
||||
# -- update m_i and l_i
|
||||
m_i_new = tl.maximum(m_i, m_ij)
|
||||
alpha = tl.exp(m_i - m_i_new)
|
||||
beta = tl.exp(m_ij - m_i_new)
|
||||
l_i_new = alpha * l_i + beta * l_ij
|
||||
# -- update output accumulator --
|
||||
# scale p
|
||||
p_scale = beta / l_i_new
|
||||
p = p * p_scale[:, None]
|
||||
# scale acc
|
||||
acc_scale = l_i / l_i_new * alpha
|
||||
tl.store(t_ptrs, acc_scale)
|
||||
acc_scale = tl.load(t_ptrs)
|
||||
acc = acc * acc_scale[:, None]
|
||||
# update acc
|
||||
v = tl.load(v_ptrs + (cur_batch_start_index + start_n) * stride_vbs,
|
||||
mask=(start_n + offs_n[:, None]) < cur_batch_seq_len, other=0.0)
|
||||
|
||||
p = p.to(v.dtype)
|
||||
acc += tl.dot(p, v)
|
||||
# update m_i and l_i
|
||||
l_i = l_i_new
|
||||
m_i = m_i_new
|
||||
|
||||
off_o = (cur_batch_start_index + offs_m[:, None]) * stride_obs + cur_head * stride_oh + offs_d[None, :] * stride_od
|
||||
out_ptrs = Out + off_o
|
||||
tl.store(out_ptrs, acc, mask=offs_m[:, None] < cur_batch_seq_len)
|
||||
return
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def bloom_context_attn_fwd(q, k, v, o, b_start_loc, b_seq_len, max_input_len, alibi=None):
|
||||
BLOCK = 128
|
||||
# shape constraints
|
||||
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
||||
assert Lq == Lk, "context process only supports equal query, key, value length"
|
||||
assert Lk == Lv, "context process only supports equal query, key, value length"
|
||||
assert Lk in {16, 32, 64, 128}
|
||||
|
||||
sm_scale = 1.0 / math.sqrt(Lk)
|
||||
batch, head = b_seq_len.shape[0], q.shape[1]
|
||||
|
||||
grid = (batch, head, triton.cdiv(max_input_len, BLOCK))
|
||||
|
||||
num_warps = 4 if Lk <= 64 else 8
|
||||
|
||||
tmp = torch.empty((batch, head, max_input_len + 256), device=q.device, dtype=torch.float32)
|
||||
|
||||
_context_flash_attention_kernel[grid](
|
||||
q, k, v, sm_scale,
|
||||
b_start_loc, b_seq_len,
|
||||
tmp,
|
||||
alibi,
|
||||
o,
|
||||
q.stride(0), q.stride(1), q.stride(2),
|
||||
k.stride(0), k.stride(1), k.stride(2),
|
||||
v.stride(0), v.stride(1), v.stride(2),
|
||||
o.stride(0), o.stride(1), o.stride(2),
|
||||
tmp.stride(0), tmp.stride(1), tmp.stride(2),
|
||||
# manually setting this blcok num, we can use tuning config to futher speed-up
|
||||
BLOCK_M=BLOCK,
|
||||
BLOCK_DMODEL=Lk,
|
||||
BLOCK_N=BLOCK,
|
||||
num_warps=num_warps,
|
||||
num_stages=1,
|
||||
)
|
||||
return
|
||||
|
||||
@torch.no_grad()
|
||||
def llama_context_attn_fwd(q, k, v, o, b_start_loc, b_seq_len, max_input_len):
|
||||
BLOCK = 128
|
||||
# shape constraints
|
||||
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
|
||||
assert Lq == Lk, "context process only supports equal query, key, value length"
|
||||
assert Lk == Lv, "context process only supports equal query, key, value length"
|
||||
assert Lk in {16, 32, 64, 128}
|
||||
|
||||
sm_scale = 1.0 / math.sqrt(Lk)
|
||||
batch, head = b_seq_len.shape[0], q.shape[1]
|
||||
|
||||
grid = (batch, head, triton.cdiv(max_input_len, BLOCK))
|
||||
|
||||
tmp = torch.empty((batch, head, max_input_len + 256), device=q.device, dtype=torch.float32)
|
||||
num_warps = 4 if Lk <= 64 else 8
|
||||
# num_warps = 4
|
||||
_context_flash_attention_kernel[grid](
|
||||
q, k, v, sm_scale, b_start_loc, b_seq_len,
|
||||
tmp,
|
||||
None,
|
||||
o,
|
||||
q.stride(0), q.stride(1), q.stride(2),
|
||||
k.stride(0), k.stride(1), k.stride(2),
|
||||
v.stride(0), v.stride(1), v.stride(2),
|
||||
o.stride(0), o.stride(1), o.stride(2),
|
||||
tmp.stride(0), tmp.stride(1), tmp.stride(2),
|
||||
BLOCK_M=BLOCK,
|
||||
BLOCK_DMODEL=Lk,
|
||||
BLOCK_N=BLOCK,
|
||||
num_warps=num_warps,
|
||||
num_stages=1,
|
||||
)
|
||||
return
|
||||
|
|
@ -0,0 +1,69 @@
|
|||
import torch
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
if HAS_TRITON:
|
||||
@triton.jit
|
||||
def _fwd_copy_kv_cache_dest(
|
||||
kv_cache_ptr, dest_index_ptr,
|
||||
out,
|
||||
stride_k_bs,
|
||||
stride_k_h,
|
||||
stride_k_d,
|
||||
stride_o_bs,
|
||||
stride_o_h,
|
||||
stride_o_d,
|
||||
head_num,
|
||||
BLOCK_DMODEL: tl.constexpr,
|
||||
BLOCK_HEAD: tl.constexpr
|
||||
):
|
||||
cur_index = tl.program_id(0)
|
||||
offs_h = tl.arange(0, BLOCK_HEAD)
|
||||
offs_d = tl.arange(0, BLOCK_DMODEL)
|
||||
|
||||
dest_index = tl.load(dest_index_ptr + cur_index)
|
||||
|
||||
cache_offsets = stride_k_h * offs_h[:, None] + stride_k_d * offs_d[None, :]
|
||||
k_ptrs = kv_cache_ptr + cur_index * stride_k_bs + cache_offsets
|
||||
|
||||
o_offsets = stride_o_h * offs_h[:, None] + stride_o_d * offs_d[None, :]
|
||||
o_ptrs = out + dest_index * stride_o_bs + o_offsets
|
||||
|
||||
k = tl.load(k_ptrs, mask=offs_h[:, None] < head_num, other=0.0)
|
||||
tl.store(o_ptrs, k, mask=offs_h[:, None] < head_num)
|
||||
return
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def copy_kv_cache_to_dest(k_ptr, dest_index_ptr, out):
|
||||
seq_len = dest_index_ptr.shape[0]
|
||||
head_num = k_ptr.shape[1]
|
||||
head_dim = k_ptr.shape[2]
|
||||
assert head_num == out.shape[1], "head_num should be the same for k_ptr and out"
|
||||
assert head_dim == out.shape[2], "head_dim should be the same for k_ptr and out"
|
||||
|
||||
num_warps = 2
|
||||
|
||||
_fwd_copy_kv_cache_dest[(seq_len,)](
|
||||
k_ptr, dest_index_ptr, out,
|
||||
k_ptr.stride(0),
|
||||
k_ptr.stride(1),
|
||||
k_ptr.stride(2),
|
||||
out.stride(0),
|
||||
out.stride(1),
|
||||
out.stride(2),
|
||||
head_num,
|
||||
BLOCK_DMODEL=head_dim,
|
||||
BLOCK_HEAD=triton.next_power_of_2(head_num),
|
||||
num_warps=num_warps,
|
||||
num_stages=2,
|
||||
)
|
||||
return
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,83 @@
|
|||
import torch
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
if HAS_TRITON:
|
||||
# CREDITS: These functions are adapted from the Triton tutorial
|
||||
# https://triton-lang.org/main/getting-started/tutorials/05-layer-norm.html
|
||||
|
||||
@triton.jit
|
||||
def _layer_norm_fwd_fused(
|
||||
X, # pointer to the input
|
||||
Y, # pointer to the output
|
||||
W, # pointer to the weights
|
||||
B, # pointer to the biases
|
||||
stride, # how much to increase the pointer when moving by 1 row
|
||||
N, # number of columns in X
|
||||
eps, # epsilon to avoid division by zero
|
||||
BLOCK_SIZE: tl.constexpr,
|
||||
):
|
||||
# Map the program id to the row of X and Y it should compute.
|
||||
row = tl.program_id(0)
|
||||
Y += row * stride
|
||||
X += row * stride
|
||||
# Compute mean
|
||||
mean = 0
|
||||
_mean = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
|
||||
for off in range(0, N, BLOCK_SIZE):
|
||||
cols = off + tl.arange(0, BLOCK_SIZE)
|
||||
a = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
|
||||
_mean += a
|
||||
mean = tl.sum(_mean, axis=0) / N
|
||||
# Compute variance
|
||||
_var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
|
||||
for off in range(0, N, BLOCK_SIZE):
|
||||
cols = off + tl.arange(0, BLOCK_SIZE)
|
||||
x = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
|
||||
x = tl.where(cols < N, x - mean, 0.)
|
||||
_var += x * x
|
||||
var = tl.sum(_var, axis=0) / N
|
||||
rstd = 1 / tl.sqrt(var + eps)
|
||||
# Normalize and apply linear transformation
|
||||
for off in range(0, N, BLOCK_SIZE):
|
||||
cols = off + tl.arange(0, BLOCK_SIZE)
|
||||
mask = cols < N
|
||||
w = tl.load(W + cols, mask=mask)
|
||||
b = tl.load(B + cols, mask=mask)
|
||||
x = tl.load(X + cols, mask=mask, other=0.).to(tl.float32)
|
||||
x_hat = (x - mean) * rstd
|
||||
y = x_hat * w + b
|
||||
# Write output
|
||||
tl.store(Y + cols, y.to(tl.float16), mask=mask)
|
||||
|
||||
@torch.no_grad()
|
||||
def layer_norm(x, weight, bias, eps):
|
||||
# allocate output
|
||||
y = torch.empty_like(x)
|
||||
# reshape input data into 2D tensor
|
||||
x_arg = x.reshape(-1, x.shape[-1])
|
||||
M, N = x_arg.shape
|
||||
# Less than 64KB per feature: enqueue fused kernel
|
||||
MAX_FUSED_SIZE = 65536 // x.element_size()
|
||||
BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
|
||||
if N > BLOCK_SIZE:
|
||||
raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
|
||||
# heuristics for number of warps
|
||||
num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
|
||||
# enqueue kernel
|
||||
_layer_norm_fwd_fused[(M,)](x_arg,
|
||||
y,
|
||||
weight,
|
||||
bias,
|
||||
x_arg.stride(0),
|
||||
N,
|
||||
eps,
|
||||
BLOCK_SIZE=BLOCK_SIZE,
|
||||
num_warps=num_warps)
|
||||
return y
|
||||
|
|
@ -0,0 +1,72 @@
|
|||
import torch
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
|
||||
if HAS_TRITON:
|
||||
'''
|
||||
this kernel function is modified from
|
||||
https://github.com/ModelTC/lightllm/blob/main/lightllm/models/llama/triton_kernel/rmsnorm.py
|
||||
'''
|
||||
@triton.jit
|
||||
def _rms_norm_fwd_fused(
|
||||
X, # pointer to the input
|
||||
Y, # pointer to the output
|
||||
W, # pointer to the weights
|
||||
stride, # how much to increase the pointer when moving by 1 row
|
||||
N, # number of columns in X
|
||||
eps, # epsilon to avoid division by zero
|
||||
BLOCK_SIZE: tl.constexpr,
|
||||
):
|
||||
# Map the program id to the row of X and Y it should compute.
|
||||
row = tl.program_id(0)
|
||||
Y += row * stride
|
||||
X += row * stride
|
||||
# Compute variance
|
||||
_var = tl.zeros([BLOCK_SIZE], dtype=tl.float32)
|
||||
for off in range(0, N, BLOCK_SIZE):
|
||||
cols = off + tl.arange(0, BLOCK_SIZE)
|
||||
x = tl.load(X + cols, mask=cols < N, other=0.).to(tl.float32)
|
||||
_var += x * x
|
||||
var = tl.sum(_var, axis=0) / N
|
||||
rstd = 1 / tl.sqrt(var + eps)
|
||||
# Normalize and apply linear transformation
|
||||
for off in range(0, N, BLOCK_SIZE):
|
||||
cols = off + tl.arange(0, BLOCK_SIZE)
|
||||
mask = cols < N
|
||||
w = tl.load(W + cols, mask=mask).to(tl.float32)
|
||||
x = tl.load(X + cols, mask=mask, other=0.).to(tl.float32)
|
||||
x_hat = x * rstd
|
||||
y = x_hat * w
|
||||
# Write output
|
||||
tl.store(Y + cols, y.to(tl.float16), mask=mask)
|
||||
|
||||
|
||||
def rmsnorm_forward(x, weight, eps):
|
||||
# allocate output
|
||||
y = torch.empty_like(x)
|
||||
# reshape input data into 2D tensor
|
||||
x_arg = x.view(-1, x.shape[-1])
|
||||
M, N = x_arg.shape
|
||||
# Less than 64KB per feature: enqueue fused kernel
|
||||
MAX_FUSED_SIZE = 65536 // x.element_size()
|
||||
BLOCK_SIZE = min(MAX_FUSED_SIZE, triton.next_power_of_2(N))
|
||||
# print("BLOCK_SIZE:", BLOCK_SIZE)
|
||||
if N > BLOCK_SIZE:
|
||||
raise RuntimeError("This layer norm doesn't support feature dim >= 64KB.")
|
||||
# heuristics for number of warps
|
||||
num_warps = min(max(BLOCK_SIZE // 256, 1), 8)
|
||||
# print(BLOCK_SIZE, num_warps, "block_size, numwarps")
|
||||
BLOCK_SIZE = 128 * 2 * 2 * 2 * 2 * 2 * 2 * 2
|
||||
num_warps = 8
|
||||
# enqueue kernel
|
||||
_rms_norm_fwd_fused[(M,)](x_arg, y, weight,
|
||||
x_arg.stride(0), N, eps,
|
||||
BLOCK_SIZE=BLOCK_SIZE, num_warps=num_warps)
|
||||
return y
|
||||
|
|
@ -0,0 +1,93 @@
|
|||
# Adapted from ModelTC https://github.com/ModelTC/lightllm
|
||||
import torch
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
|
||||
@triton.jit
|
||||
def _rotary_kernel(
|
||||
q,
|
||||
Cos,
|
||||
Sin,
|
||||
q_bs_stride,
|
||||
q_h_stride,
|
||||
q_d_stride,
|
||||
cos_bs_stride,
|
||||
cos_d_stride,
|
||||
total_len,
|
||||
HEAD_NUM: tl.constexpr,
|
||||
BLOCK_HEAD: tl.constexpr,
|
||||
BLOCK_SEQ: tl.constexpr,
|
||||
HEAD_DIM: tl.constexpr,
|
||||
):
|
||||
current_head_index = tl.program_id(0)
|
||||
current_seq_index = tl.program_id(1)
|
||||
|
||||
current_head_range = current_head_index * BLOCK_HEAD + tl.arange(0, BLOCK_HEAD)
|
||||
current_seq_range = current_seq_index * BLOCK_SEQ + tl.arange(0, BLOCK_SEQ)
|
||||
|
||||
dim_range0 = tl.arange(0, HEAD_DIM // 2)
|
||||
dim_range1 = tl.arange(HEAD_DIM // 2, HEAD_DIM)
|
||||
|
||||
off_q0 = current_seq_range[:, None, None] * q_bs_stride + current_head_range[
|
||||
None, :, None] * q_h_stride + dim_range0[None, None, :] * q_d_stride
|
||||
off_q1 = current_seq_range[:, None, None] * q_bs_stride + current_head_range[
|
||||
None, :, None] * q_h_stride + dim_range1[None, None, :] * q_d_stride
|
||||
|
||||
off_dimcos_sin = current_seq_range[:, None, None] * cos_bs_stride + dim_range0[None, None, :] * cos_d_stride
|
||||
|
||||
q0 = tl.load(q + off_q0,
|
||||
mask=(current_seq_range[:, None, None] < total_len) & (current_head_range[None, :, None] < HEAD_NUM),
|
||||
other=0.0)
|
||||
q1 = tl.load(q + off_q1,
|
||||
mask=(current_seq_range[:, None, None] < total_len) & (current_head_range[None, :, None] < HEAD_NUM),
|
||||
other=0.0)
|
||||
|
||||
cos = tl.load(Cos + off_dimcos_sin, mask=current_seq_range[:, None, None] < total_len, other=0.0)
|
||||
sin = tl.load(Sin + off_dimcos_sin, mask=current_seq_range[:, None, None] < total_len, other=0.0)
|
||||
|
||||
out0 = q0 * cos - q1 * sin
|
||||
out1 = q0 * sin + q1 * cos
|
||||
|
||||
tl.store(q + off_q0,
|
||||
out0,
|
||||
mask=(current_seq_range[:, None, None] < total_len) & (current_head_range[None, :, None] < HEAD_NUM))
|
||||
tl.store(q + off_q1,
|
||||
out1,
|
||||
mask=(current_seq_range[:, None, None] < total_len) & (current_head_range[None, :, None] < HEAD_NUM))
|
||||
|
||||
return
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def rotary_embedding_fwd(q, cos, sin):
|
||||
total_len = q.shape[0]
|
||||
head_num = q.shape[1]
|
||||
head_dim = q.shape[2]
|
||||
assert q.shape[0] == cos.shape[0] and q.shape[0] == sin.shape[0], f"q shape {q.shape} cos shape {cos.shape}"
|
||||
BLOCK_HEAD = 4
|
||||
BLOCK_SEQ = 32
|
||||
grid = (triton.cdiv(head_num, BLOCK_HEAD), triton.cdiv(total_len, BLOCK_SEQ))
|
||||
if head_dim >= 128:
|
||||
num_warps = 8
|
||||
else:
|
||||
num_warps = 4
|
||||
|
||||
_rotary_kernel[grid](
|
||||
q,
|
||||
cos,
|
||||
sin,
|
||||
q.stride(0),
|
||||
q.stride(1),
|
||||
q.stride(2),
|
||||
cos.stride(0),
|
||||
cos.stride(1),
|
||||
total_len,
|
||||
HEAD_NUM=head_num,
|
||||
BLOCK_HEAD=BLOCK_HEAD,
|
||||
BLOCK_SEQ=BLOCK_SEQ,
|
||||
HEAD_DIM=head_dim,
|
||||
num_warps=num_warps,
|
||||
num_stages=1,
|
||||
)
|
||||
return
|
||||
|
|
@ -11,10 +11,11 @@ except ImportError:
|
|||
|
||||
if HAS_TRITON:
|
||||
from .qkv_matmul_kernel import qkv_gemm_4d_kernel
|
||||
from .softmax_kernel import softmax_kernel
|
||||
from .softmax import softmax_kernel
|
||||
|
||||
def self_attention_forward_without_fusion(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor, input_mask: torch.Tensor, scale: float):
|
||||
r""" A function to do QKV Attention calculation by calling GEMM and softmax triton kernels
|
||||
def self_attention_forward_without_fusion(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor,
|
||||
input_mask: torch.Tensor, scale: float):
|
||||
r""" A function to do QKV Attention calculation by calling GEMM and softmax triton kernels
|
||||
Args:
|
||||
q (torch.Tensor): Q embedding in attention layer, shape should be (batch, seq_len, num_heads, head_size)
|
||||
k (torch.Tensor): K embedding in attention layer, shape should be (batch, seq_len, num_heads, head_size)
|
||||
|
|
@ -36,39 +37,49 @@ if HAS_TRITON:
|
|||
# head_size * num_of_head
|
||||
d_model = q.shape[-1] * q.shape[-2]
|
||||
|
||||
score_output = torch.empty(
|
||||
(batches, H, M, N), device=q.device, dtype=q.dtype)
|
||||
score_output = torch.empty((batches, H, M, N), device=q.device, dtype=q.dtype)
|
||||
|
||||
grid = lambda meta: (
|
||||
batches,
|
||||
H,
|
||||
triton.cdiv(M, meta["BLOCK_SIZE_M"]) *
|
||||
triton.cdiv(N, meta["BLOCK_SIZE_N"]),
|
||||
triton.cdiv(M, meta["BLOCK_SIZE_M"]) * triton.cdiv(N, meta["BLOCK_SIZE_N"]),
|
||||
)
|
||||
|
||||
qkv_gemm_4d_kernel[grid](
|
||||
q, k, score_output,
|
||||
M, N, K,
|
||||
q.stride(0), q.stride(2), q.stride(1), q.stride(3),
|
||||
k.stride(0), k.stride(2), k.stride(3), k.stride(1),
|
||||
score_output.stride(0), score_output.stride(1), score_output.stride(2), score_output.stride(3),
|
||||
q,
|
||||
k,
|
||||
score_output,
|
||||
M,
|
||||
N,
|
||||
K,
|
||||
q.stride(0),
|
||||
q.stride(2),
|
||||
q.stride(1),
|
||||
q.stride(3),
|
||||
k.stride(0),
|
||||
k.stride(2),
|
||||
k.stride(3),
|
||||
k.stride(1),
|
||||
score_output.stride(0),
|
||||
score_output.stride(1),
|
||||
score_output.stride(2),
|
||||
score_output.stride(3),
|
||||
scale=scale,
|
||||
# currently manually setting, later on we can use auto-tune config to match best setting
|
||||
# currently manually setting, later on we can use auto-tune config to match best setting
|
||||
BLOCK_SIZE_M=64,
|
||||
BLOCK_SIZE_N=32,
|
||||
BLOCK_SIZE_K=32,
|
||||
GROUP_SIZE_M=8,
|
||||
)
|
||||
|
||||
softmax_output = torch.empty(
|
||||
score_output.shape, device=score_output.device, dtype=score_output.dtype)
|
||||
|
||||
softmax_output = torch.empty(score_output.shape, device=score_output.device, dtype=score_output.dtype)
|
||||
score_output_shape = score_output.shape
|
||||
|
||||
score_output = score_output.view(-1, score_output.shape[-1])
|
||||
n_rows, n_cols = score_output.shape
|
||||
|
||||
if n_rows <= 350000:
|
||||
|
||||
|
||||
block_size = max(triton.next_power_of_2(n_cols), 2)
|
||||
num_warps = 4
|
||||
if block_size >= 4096:
|
||||
|
|
@ -78,37 +89,39 @@ if HAS_TRITON:
|
|||
else:
|
||||
num_warps = 4
|
||||
|
||||
softmax_kernel[(n_rows, )](
|
||||
softmax_kernel[(n_rows,)](
|
||||
softmax_output,
|
||||
score_output,
|
||||
score_output.stride(0),
|
||||
n_cols,
|
||||
mask_ptr = input_mask,
|
||||
mask_ptr=input_mask,
|
||||
num_warps=num_warps,
|
||||
BLOCK_SIZE=block_size,
|
||||
)
|
||||
|
||||
else:
|
||||
#TODO: change softmax kernel functions to make it suitable for large size dimension
|
||||
# NOTE: change softmax kernel functions to make it suitable for large size dimension
|
||||
softmax_output = torch.nn.functional.softmax(score_output, dim=-1)
|
||||
softmax_output = softmax_output.view(*score_output_shape)
|
||||
|
||||
batches, H, M, K = softmax_output.shape
|
||||
N = v.shape[-1]
|
||||
|
||||
output = torch.empty(
|
||||
(batches, M, H, N), device=softmax_output.device, dtype=softmax_output.dtype)
|
||||
output = torch.empty((batches, M, H, N), device=softmax_output.device, dtype=softmax_output.dtype)
|
||||
|
||||
grid = lambda meta: (
|
||||
batches,
|
||||
H,
|
||||
triton.cdiv(M, meta["BLOCK_SIZE_M"]) *
|
||||
triton.cdiv(N, meta["BLOCK_SIZE_N"]),
|
||||
triton.cdiv(M, meta["BLOCK_SIZE_M"]) * triton.cdiv(N, meta["BLOCK_SIZE_N"]),
|
||||
)
|
||||
|
||||
qkv_gemm_4d_kernel[grid](
|
||||
softmax_output, v, output,
|
||||
M, N, K,
|
||||
softmax_output,
|
||||
v,
|
||||
output,
|
||||
M,
|
||||
N,
|
||||
K,
|
||||
softmax_output.stride(0),
|
||||
softmax_output.stride(1),
|
||||
softmax_output.stride(2),
|
||||
|
|
@ -129,7 +142,6 @@ if HAS_TRITON:
|
|||
)
|
||||
return output.view(batches, -1, d_model)
|
||||
|
||||
|
||||
def self_attention_compute_using_triton(qkv,
|
||||
input_mask,
|
||||
layer_past,
|
||||
|
|
@ -152,58 +164,6 @@ if HAS_TRITON:
|
|||
k = k.view(batches, -1, num_of_heads, head_size)
|
||||
v = v.view(batches, -1, num_of_heads, head_size)
|
||||
|
||||
data_output_triton = self_attention_forward_without_fusion(
|
||||
q, k, v, input_mask, scale)
|
||||
data_output_triton = self_attention_forward_without_fusion(q, k, v, input_mask, scale)
|
||||
|
||||
return data_output_triton
|
||||
|
||||
|
||||
def softmax(input: torch.Tensor, mask: torch.Tensor = None, dim=-1) -> torch.Tensor:
|
||||
if mask is not None:
|
||||
assert input[-1] == mask[-1], "the last dimentions should be the same for input and mask"
|
||||
assert dim == -1 or dim == len(input.shape)-1, "currently softmax layer only support last dimention"
|
||||
|
||||
hidden_dim = input.shape[-1]
|
||||
output = torch.empty_like(input)
|
||||
input = input.view(-1, hidden_dim)
|
||||
if mask is not None:
|
||||
mask = mask.view(-1, hidden_dim)
|
||||
assert input.shape[0] == mask.shape[0], "the fist dimention of mask and input should be the same"
|
||||
|
||||
num_rows, num_cols = input.shape
|
||||
block_size = max(triton.next_power_of_2(num_cols), 2)
|
||||
num_warps = 16
|
||||
if block_size >= 4096:
|
||||
num_warps = 16
|
||||
elif block_size >= 2048:
|
||||
num_warps = 8
|
||||
else:
|
||||
num_warps = 4
|
||||
|
||||
if num_rows <= 350000:
|
||||
grid = (num_rows,)
|
||||
softmax_kernel[grid](output, input, input.stride(0), num_cols, mask, BLOCK_SIZE = block_size, num_warps=num_warps)
|
||||
else:
|
||||
grid = lambda meta: ()
|
||||
|
||||
grid = lambda meta: (
|
||||
triton.cdiv(num_rows, meta["BLOCK_M"]),
|
||||
)
|
||||
|
||||
BLOCK_M = 32
|
||||
if block_size >= 4096:
|
||||
BLOCK_M = 4
|
||||
elif block_size >= 2048:
|
||||
BLOCK_M = 8
|
||||
|
||||
softmax_kernel_2[grid](output_ptr = output,
|
||||
input_ptr = input,
|
||||
row_stride = input.stride(0),
|
||||
n_rows = num_rows,
|
||||
n_cols = num_cols,
|
||||
mask_ptr = mask,
|
||||
# currently manually setting up size
|
||||
BLOCK_M = 32,
|
||||
BLOCK_SIZE = block_size)
|
||||
|
||||
return output
|
||||
|
|
@ -0,0 +1,96 @@
|
|||
import torch
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
if HAS_TRITON:
|
||||
'''
|
||||
softmax kernel is modified based on
|
||||
https://github.com/openai/triton/blob/34817ecc954a6f4ca7b4dfb352fdde1f8bd49ca5/python/tutorials/02-fused-softmax.py
|
||||
'''
|
||||
@triton.jit
|
||||
def softmax_kernel(output_ptr, input_ptr, row_stride, n_cols, mask_ptr, BLOCK_SIZE: tl.constexpr):
|
||||
r""" the kernel function for implementing softmax operator
|
||||
Args:
|
||||
output_ptr: the output after finishing softmax operation, (N, hidden_dim)
|
||||
input_ptr: the tensor of input, shape should be (N, hidden_dim)
|
||||
n_cols(tl.constexpr): the number of cols of input
|
||||
BLOCK_SIZE(tl.constexpr): the block_size of your hidden_dim dimension, typically BLOCK_SIZE >= hidden_dim
|
||||
"""
|
||||
row_idx = tl.program_id(0)
|
||||
row_start_ptr = input_ptr + row_idx * row_stride
|
||||
col_offsets = tl.arange(0, BLOCK_SIZE)
|
||||
input_ptrs = row_start_ptr + col_offsets
|
||||
row = tl.load(input_ptrs, mask=col_offsets < n_cols, other=-float('inf')).to(tl.float32)
|
||||
row_minus_max = row - tl.max(row, axis=0)
|
||||
|
||||
if mask_ptr is not None:
|
||||
# load mask into SRAM
|
||||
mask_ptrs = (mask_ptr + (row_indx * row_stride)) + col_offsets
|
||||
mask = tl.load(mask_ptrs, mask=col_offsets < n_cols, other=0).to(tl.float32)
|
||||
|
||||
# update
|
||||
row_minus_max = row_minus_max + mask
|
||||
|
||||
numerator = tl.exp(row_minus_max)
|
||||
denominator = tl.sum(numerator, axis=0)
|
||||
softmax_output = numerator / denominator
|
||||
output_row_start_ptr = output_ptr + row_idx * row_stride
|
||||
output_ptrs = output_row_start_ptr + col_offsets
|
||||
# Write back output to DRAM
|
||||
tl.store(output_ptrs, softmax_output, mask=col_offsets < n_cols)
|
||||
|
||||
|
||||
def softmax(input: torch.Tensor, mask: torch.Tensor = None, dim=-1) -> torch.Tensor:
|
||||
if mask is not None:
|
||||
assert input[-1] == mask[-1], "the last dimentions should be the same for input and mask"
|
||||
assert dim == -1 or dim == len(input.shape)-1, "currently softmax layer only support last dimention"
|
||||
|
||||
hidden_dim = input.shape[-1]
|
||||
output = torch.empty_like(input)
|
||||
input = input.view(-1, hidden_dim)
|
||||
if mask is not None:
|
||||
mask = mask.view(-1, hidden_dim)
|
||||
assert input.shape[0] == mask.shape[0], "the fist dimention of mask and input should be the same"
|
||||
|
||||
num_rows, num_cols = input.shape
|
||||
block_size = max(triton.next_power_of_2(num_cols), 2)
|
||||
num_warps = 16
|
||||
if block_size >= 4096:
|
||||
num_warps = 16
|
||||
elif block_size >= 2048:
|
||||
num_warps = 8
|
||||
else:
|
||||
num_warps = 4
|
||||
|
||||
if num_rows <= 350000:
|
||||
grid = (num_rows,)
|
||||
softmax_kernel[grid](output, input, input.stride(0), num_cols, mask, BLOCK_SIZE = block_size, num_warps=num_warps)
|
||||
else:
|
||||
grid = lambda meta: ()
|
||||
|
||||
grid = lambda meta: (
|
||||
triton.cdiv(num_rows, meta["BLOCK_M"]),
|
||||
)
|
||||
|
||||
BLOCK_M = 32
|
||||
if block_size >= 4096:
|
||||
BLOCK_M = 4
|
||||
elif block_size >= 2048:
|
||||
BLOCK_M = 8
|
||||
|
||||
softmax_kernel[grid](output_ptr = output,
|
||||
input_ptr = input,
|
||||
row_stride = input.stride(0),
|
||||
n_rows = num_rows,
|
||||
n_cols = num_cols,
|
||||
mask_ptr = mask,
|
||||
# currently manually setting up size
|
||||
BLOCK_M = 32,
|
||||
BLOCK_SIZE = block_size)
|
||||
|
||||
return output
|
||||
|
|
@ -1,44 +0,0 @@
|
|||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
if HAS_TRITON:
|
||||
'''
|
||||
softmax kernel is modified based on
|
||||
https://github.com/openai/triton/blob/34817ecc954a6f4ca7b4dfb352fdde1f8bd49ca5/python/tutorials/02-fused-softmax.py
|
||||
'''
|
||||
@triton.jit
|
||||
def softmax_kernel(output_ptr, input_ptr, row_stride, n_cols, mask_ptr, BLOCK_SIZE: tl.constexpr):
|
||||
r""" the kernel function for implementing softmax operator
|
||||
Args:
|
||||
output_ptr: the output after finishing softmax operation, (N, hidden_dim)
|
||||
input_ptr: the tensor of input, shape should be (N, hidden_dim)
|
||||
n_cols(tl.constexpr): the number of cols of input
|
||||
BLOCK_SIZE(tl.constexpr): the block_size of your hidden_dim dimension, typically BLOCK_SIZE >= hidden_dim
|
||||
"""
|
||||
row_idx = tl.program_id(0)
|
||||
row_start_ptr = input_ptr + row_idx * row_stride
|
||||
col_offsets = tl.arange(0, BLOCK_SIZE)
|
||||
input_ptrs = row_start_ptr + col_offsets
|
||||
row = tl.load(input_ptrs, mask=col_offsets < n_cols, other=-float('inf')).to(tl.float32)
|
||||
row_minus_max = row - tl.max(row, axis=0)
|
||||
|
||||
if mask_ptr is not None:
|
||||
# load mask into SRAM
|
||||
mask_ptrs = (mask_ptr + (row_indx * row_stride)) + col_offsets
|
||||
mask = tl.load(mask_ptrs, mask=col_offsets < n_cols, other=0).to(tl.float32)
|
||||
|
||||
# update
|
||||
row_minus_max = row_minus_max + mask
|
||||
|
||||
numerator = tl.exp(row_minus_max)
|
||||
denominator = tl.sum(numerator, axis=0)
|
||||
softmax_output = numerator / denominator
|
||||
output_row_start_ptr = output_ptr + row_idx * row_stride
|
||||
output_ptrs = output_row_start_ptr + col_offsets
|
||||
# Write back output to DRAM
|
||||
tl.store(output_ptrs, softmax_output, mask=col_offsets < n_cols)
|
||||
|
|
@ -0,0 +1,333 @@
|
|||
# Adapted from ModelTC https://github.com/ModelTC/lightllm
|
||||
|
||||
import math
|
||||
|
||||
import torch
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
if HAS_TRITON:
|
||||
|
||||
@triton.jit
|
||||
def _token_attn_1_kernel(Q, K, sm_scale, kv_cache_loc, kv_cache_start_loc, kv_cache_seqlen, max_kv_cache_len,
|
||||
attn_out, kv_cache_loc_b_stride, kv_cache_loc_s_stride, q_batch_stride, q_head_stride,
|
||||
q_head_dim_stride, k_batch_stride, k_head_stride, k_head_dim_stride, attn_head_stride,
|
||||
attn_batch_stride, HEAD_DIM: tl.constexpr, BLOCK_N: tl.constexpr):
|
||||
current_batch = tl.program_id(0)
|
||||
current_head = tl.program_id(1)
|
||||
start_n = tl.program_id(2)
|
||||
|
||||
offs_d = tl.arange(0, HEAD_DIM)
|
||||
current_batch_seq_len = tl.load(kv_cache_seqlen + current_batch)
|
||||
current_batch_in_all_start_index = tl.load(kv_cache_start_loc + current_batch)
|
||||
|
||||
current_batch_start_index = max_kv_cache_len - current_batch_seq_len
|
||||
current_batch_end_index = max_kv_cache_len
|
||||
|
||||
off_q = current_batch * q_batch_stride + current_head * q_head_stride + offs_d * q_head_dim_stride
|
||||
|
||||
offs_n = start_n * BLOCK_N + tl.arange(0, BLOCK_N)
|
||||
|
||||
block_stard_index = start_n * BLOCK_N
|
||||
block_mask = tl.where(block_stard_index < current_batch_seq_len, 1, 0)
|
||||
|
||||
for start_mark in range(0, block_mask, 1):
|
||||
q = tl.load(Q + off_q + start_mark)
|
||||
offs_n_new = current_batch_start_index + offs_n
|
||||
k_loc = tl.load(kv_cache_loc + kv_cache_loc_b_stride * current_batch + kv_cache_loc_s_stride * offs_n_new,
|
||||
mask=offs_n_new < current_batch_end_index,
|
||||
other=0)
|
||||
off_k = k_loc[:, None] * k_batch_stride + current_head * k_head_stride + offs_d[None, :] * k_head_dim_stride
|
||||
k = tl.load(K + off_k, mask=offs_n_new[:, None] < current_batch_end_index, other=0.0)
|
||||
att_value = tl.sum(q[None, :] * k, 1)
|
||||
att_value *= sm_scale
|
||||
off_o = current_head * attn_head_stride + (current_batch_in_all_start_index + offs_n) * attn_batch_stride
|
||||
tl.store(attn_out + off_o, att_value, mask=offs_n_new < current_batch_end_index)
|
||||
return
|
||||
|
||||
@triton.jit
|
||||
def _token_attn_1_alibi_kernel(Q, K, sm_scale, alibi, kv_cache_loc, kv_cache_start_loc, kv_cache_seqlen,
|
||||
max_kv_cache_len, attn_out, kv_cache_loc_b_stride, kv_cache_loc_s_stride,
|
||||
q_batch_stride, q_head_stride, q_head_dim_stride, k_batch_stride, k_head_stride,
|
||||
k_head_dim_stride, attn_head_stride, attn_batch_stride, HEAD_DIM: tl.constexpr,
|
||||
BLOCK_N: tl.constexpr):
|
||||
current_batch = tl.program_id(0)
|
||||
current_head = tl.program_id(1)
|
||||
start_n = tl.program_id(2)
|
||||
|
||||
offs_d = tl.arange(0, HEAD_DIM)
|
||||
current_batch_seq_len = tl.load(kv_cache_seqlen + current_batch)
|
||||
current_batch_in_all_start_index = tl.load(kv_cache_start_loc + current_batch)
|
||||
|
||||
current_batch_start_index = max_kv_cache_len - current_batch_seq_len
|
||||
current_batch_end_index = max_kv_cache_len
|
||||
|
||||
off_q = current_batch * q_batch_stride + current_head * q_head_stride + offs_d * q_head_dim_stride
|
||||
|
||||
offs_n = start_n * BLOCK_N + tl.arange(0, BLOCK_N)
|
||||
|
||||
block_stard_index = start_n * BLOCK_N
|
||||
block_mask = tl.where(block_stard_index < current_batch_seq_len, 1, 0)
|
||||
|
||||
for start_mark in range(0, block_mask, 1):
|
||||
alibi_m = tl.load(alibi + current_head)
|
||||
q = tl.load(Q + off_q + start_mark)
|
||||
offs_n_new = current_batch_start_index + offs_n
|
||||
k_loc = tl.load(kv_cache_loc + kv_cache_loc_b_stride * current_batch + kv_cache_loc_s_stride * offs_n_new,
|
||||
mask=offs_n_new < current_batch_end_index,
|
||||
other=0)
|
||||
off_k = k_loc[:, None] * k_batch_stride + current_head * k_head_stride + offs_d[None, :] * k_head_dim_stride
|
||||
k = tl.load(K + off_k, mask=offs_n_new[:, None] < current_batch_end_index, other=0.0)
|
||||
att_value = tl.sum(q[None, :] * k, 1)
|
||||
att_value *= sm_scale
|
||||
att_value -= alibi_m * (current_batch_seq_len - 1 - offs_n)
|
||||
off_o = current_head * attn_head_stride + (current_batch_in_all_start_index + offs_n) * attn_batch_stride
|
||||
tl.store(attn_out + off_o, att_value, mask=offs_n_new < current_batch_end_index)
|
||||
return
|
||||
|
||||
@torch.no_grad()
|
||||
def token_attn_fwd_1(q,
|
||||
k,
|
||||
attn_out,
|
||||
kv_cache_loc,
|
||||
kv_cache_start_loc,
|
||||
kv_cache_seqlen,
|
||||
max_kv_cache_len,
|
||||
alibi=None):
|
||||
BLOCK = 32
|
||||
# shape constraints
|
||||
q_head_dim, k_head_dim = q.shape[-1], k.shape[-1]
|
||||
assert q_head_dim == k_head_dim
|
||||
assert k_head_dim in {16, 32, 64, 128}
|
||||
sm_scale = 1.0 / (k_head_dim**0.5)
|
||||
|
||||
batch, head_num = kv_cache_loc.shape[0], q.shape[1]
|
||||
|
||||
grid = (batch, head_num, triton.cdiv(max_kv_cache_len, BLOCK))
|
||||
|
||||
num_warps = 4 if k_head_dim <= 64 else 8
|
||||
num_warps = 2
|
||||
|
||||
if alibi is not None:
|
||||
_token_attn_1_alibi_kernel[grid](
|
||||
q,
|
||||
k,
|
||||
sm_scale,
|
||||
alibi,
|
||||
kv_cache_loc,
|
||||
kv_cache_start_loc,
|
||||
kv_cache_seqlen,
|
||||
max_kv_cache_len,
|
||||
attn_out,
|
||||
kv_cache_loc.stride(0),
|
||||
kv_cache_loc.stride(1),
|
||||
q.stride(0),
|
||||
q.stride(1),
|
||||
q.stride(2),
|
||||
k.stride(0),
|
||||
k.stride(1),
|
||||
k.stride(2),
|
||||
attn_out.stride(0),
|
||||
attn_out.stride(1),
|
||||
HEAD_DIM=k_head_dim,
|
||||
BLOCK_N=BLOCK,
|
||||
num_warps=num_warps,
|
||||
num_stages=1,
|
||||
)
|
||||
else:
|
||||
_token_attn_1_kernel[grid](
|
||||
q,
|
||||
k,
|
||||
sm_scale,
|
||||
kv_cache_loc,
|
||||
kv_cache_start_loc,
|
||||
kv_cache_seqlen,
|
||||
max_kv_cache_len,
|
||||
attn_out,
|
||||
kv_cache_loc.stride(0),
|
||||
kv_cache_loc.stride(1),
|
||||
q.stride(0),
|
||||
q.stride(1),
|
||||
q.stride(2),
|
||||
k.stride(0),
|
||||
k.stride(1),
|
||||
k.stride(2),
|
||||
attn_out.stride(0),
|
||||
attn_out.stride(1),
|
||||
HEAD_DIM=k_head_dim,
|
||||
BLOCK_N=BLOCK,
|
||||
num_warps=num_warps,
|
||||
num_stages=1,
|
||||
)
|
||||
return
|
||||
|
||||
@triton.jit
|
||||
def _token_attn_softmax_fwd(softmax_logics, kv_cache_start_loc, kv_cache_seqlen, softmax_prob_out,
|
||||
logics_head_dim_stride, logics_batch_stride, prob_head_dim_stride, prob_batch_stride,
|
||||
BLOCK_SIZE: tl.constexpr):
|
||||
current_batch = tl.program_id(0)
|
||||
current_head = tl.program_id(1)
|
||||
|
||||
col_offsets = tl.arange(0, BLOCK_SIZE)
|
||||
current_batch_seq_len = tl.load(kv_cache_seqlen + current_batch)
|
||||
current_batch_in_all_start_index = tl.load(kv_cache_start_loc + current_batch)
|
||||
|
||||
row = tl.load(softmax_logics + current_head * logics_head_dim_stride +
|
||||
(current_batch_in_all_start_index + col_offsets) * logics_batch_stride,
|
||||
mask=col_offsets < current_batch_seq_len,
|
||||
other=-float('inf')).to(tl.float32)
|
||||
|
||||
row_minus_max = row - tl.max(row, axis=0)
|
||||
numerator = tl.exp(row_minus_max)
|
||||
denominator = tl.sum(numerator, axis=0)
|
||||
softmax_output = numerator / denominator
|
||||
|
||||
tl.store(softmax_prob_out + current_head * prob_head_dim_stride +
|
||||
(current_batch_in_all_start_index + col_offsets) * prob_batch_stride,
|
||||
softmax_output,
|
||||
mask=col_offsets < current_batch_seq_len)
|
||||
return
|
||||
|
||||
@torch.no_grad()
|
||||
def token_attn_softmax_fwd(softmax_logics, kv_cache_start_loc, kv_cache_seqlen, softmax_prob_out, max_kv_cache_len):
|
||||
BLOCK_SIZE = triton.next_power_of_2(max_kv_cache_len)
|
||||
batch, head_num = kv_cache_start_loc.shape[0], softmax_logics.shape[0]
|
||||
|
||||
num_warps = 4
|
||||
if BLOCK_SIZE >= 2048:
|
||||
num_warps = 8
|
||||
if BLOCK_SIZE >= 4096:
|
||||
num_warps = 16
|
||||
|
||||
_token_attn_softmax_fwd[(batch, head_num)](
|
||||
softmax_logics,
|
||||
kv_cache_start_loc,
|
||||
kv_cache_seqlen,
|
||||
softmax_prob_out,
|
||||
softmax_logics.stride(0),
|
||||
softmax_logics.stride(1),
|
||||
softmax_prob_out.stride(0),
|
||||
softmax_prob_out.stride(1),
|
||||
num_warps=num_warps,
|
||||
BLOCK_SIZE=BLOCK_SIZE,
|
||||
)
|
||||
return
|
||||
|
||||
@triton.jit
|
||||
def _token_attn_2_kernel(Prob, V, attn_out, kv_cache_loc, kv_cache_start_loc, kv_cache_seqlen, max_kv_cache_len,
|
||||
kv_cache_loc_b_stride, kv_cache_loc_s_stride, prob_head_dim_stride, prob_batch_stride,
|
||||
v_batch_stride, v_head_stride, v_head_dim_stride, attn_out_batch_stride,
|
||||
attn_out_head_stride, attn_out_head_dim_stride, HEAD_DIM: tl.constexpr,
|
||||
BLOCK_N: tl.constexpr):
|
||||
current_batch = tl.program_id(0)
|
||||
current_head = tl.program_id(1)
|
||||
|
||||
offs_n = tl.arange(0, BLOCK_N)
|
||||
offs_d = tl.arange(0, HEAD_DIM)
|
||||
current_batch_seq_len = tl.load(kv_cache_seqlen + current_batch)
|
||||
current_batch_start_index = max_kv_cache_len - current_batch_seq_len
|
||||
current_batch_end_index = current_batch_seq_len
|
||||
current_batch_in_all_start_index = tl.load(kv_cache_start_loc + current_batch)
|
||||
|
||||
v_loc_off = current_batch * kv_cache_loc_b_stride + (current_batch_start_index + offs_n) * kv_cache_loc_s_stride
|
||||
p_offs = current_head * prob_head_dim_stride + (current_batch_in_all_start_index + offs_n) * prob_batch_stride
|
||||
v_offs = current_head * v_head_stride + offs_d[None, :] * v_head_dim_stride
|
||||
|
||||
acc = tl.zeros([HEAD_DIM], dtype=tl.float32)
|
||||
for start_n in range(0, current_batch_seq_len, BLOCK_N):
|
||||
start_n = tl.multiple_of(start_n, BLOCK_N)
|
||||
p_value = tl.load(Prob + p_offs + start_n * kv_cache_loc_s_stride,
|
||||
mask=(start_n + offs_n) < current_batch_seq_len,
|
||||
other=0.0)
|
||||
v_loc = tl.load(kv_cache_loc + v_loc_off + start_n * kv_cache_loc_s_stride,
|
||||
mask=(start_n + offs_n) < current_batch_seq_len,
|
||||
other=0.0)
|
||||
v_value = tl.load(V + v_offs + v_loc[:, None] * v_batch_stride,
|
||||
mask=(start_n + offs_n[:, None]) < current_batch_seq_len,
|
||||
other=0.0)
|
||||
acc += tl.sum(p_value[:, None] * v_value, 0)
|
||||
|
||||
acc = acc.to(tl.float16)
|
||||
off_o = current_batch * attn_out_batch_stride + current_head * attn_out_head_stride + offs_d * attn_out_head_dim_stride
|
||||
out_ptrs = attn_out + off_o
|
||||
tl.store(out_ptrs, acc)
|
||||
return
|
||||
|
||||
@torch.no_grad()
|
||||
def token_attn_fwd_2(prob, v, attn_out, kv_cache_loc, kv_cache_start_loc, kv_cache_seqlen, max_kv_cache_len):
|
||||
if triton.__version__ >= "2.1.0":
|
||||
BLOCK = 128
|
||||
else:
|
||||
BLOCK = 64
|
||||
batch, head = kv_cache_loc.shape[0], v.shape[1]
|
||||
grid = (batch, head)
|
||||
num_warps = 4
|
||||
dim = v.shape[-1]
|
||||
|
||||
_token_attn_2_kernel[grid](
|
||||
prob,
|
||||
v,
|
||||
attn_out,
|
||||
kv_cache_loc,
|
||||
kv_cache_start_loc,
|
||||
kv_cache_seqlen,
|
||||
max_kv_cache_len,
|
||||
kv_cache_loc.stride(0),
|
||||
kv_cache_loc.stride(1),
|
||||
prob.stride(0),
|
||||
prob.stride(1),
|
||||
v.stride(0),
|
||||
v.stride(1),
|
||||
v.stride(2),
|
||||
attn_out.stride(0),
|
||||
attn_out.stride(1),
|
||||
attn_out.stride(2),
|
||||
HEAD_DIM=dim,
|
||||
BLOCK_N=BLOCK,
|
||||
num_warps=num_warps,
|
||||
num_stages=1,
|
||||
)
|
||||
return
|
||||
|
||||
@torch.no_grad()
|
||||
def token_attention_fwd(q,
|
||||
k,
|
||||
v,
|
||||
attn_out,
|
||||
kv_cache_loc,
|
||||
kv_cache_start_loc,
|
||||
kv_cache_seq_len,
|
||||
max_len_in_batch,
|
||||
alibi=None):
|
||||
head_num = k.shape[1]
|
||||
batch_size = kv_cache_seq_len.shape[0]
|
||||
calcu_shape1 = (batch_size, head_num, k.shape[2])
|
||||
total_token_num = k.shape[0]
|
||||
|
||||
att_m_tensor = torch.empty((head_num, total_token_num), dtype=q.dtype, device="cuda")
|
||||
|
||||
token_attn_fwd_1(q.view(calcu_shape1),
|
||||
k,
|
||||
att_m_tensor,
|
||||
kv_cache_loc,
|
||||
kv_cache_start_loc,
|
||||
kv_cache_seq_len,
|
||||
max_len_in_batch,
|
||||
alibi=alibi)
|
||||
|
||||
prob = torch.empty_like(att_m_tensor)
|
||||
|
||||
token_attn_softmax_fwd(att_m_tensor, kv_cache_start_loc, kv_cache_seq_len, prob, max_len_in_batch)
|
||||
att_m_tensor = None
|
||||
token_attn_fwd_2(prob, v, attn_out.view(calcu_shape1), kv_cache_loc, kv_cache_start_loc, kv_cache_seq_len,
|
||||
max_len_in_batch)
|
||||
|
||||
prob = None
|
||||
|
||||
return
|
||||
|
|
@ -20,6 +20,7 @@ class LlamaPipelineForwards:
|
|||
under pipeline setting.
|
||||
'''
|
||||
|
||||
@staticmethod
|
||||
def llama_model_forward(
|
||||
self: LlamaModel,
|
||||
input_ids: torch.LongTensor = None,
|
||||
|
|
@ -170,6 +171,7 @@ class LlamaPipelineForwards:
|
|||
# always return dict for imediate stage
|
||||
return {'hidden_states': hidden_states}
|
||||
|
||||
@staticmethod
|
||||
def llama_for_causal_lm_forward(
|
||||
self: LlamaForCausalLM,
|
||||
input_ids: torch.LongTensor = None,
|
||||
|
|
@ -277,6 +279,7 @@ class LlamaPipelineForwards:
|
|||
hidden_states = outputs.get('hidden_states')
|
||||
return {'hidden_states': hidden_states}
|
||||
|
||||
@staticmethod
|
||||
def llama_for_sequence_classification_forward(
|
||||
self: LlamaForSequenceClassification,
|
||||
input_ids: torch.LongTensor = None,
|
||||
|
|
@ -390,6 +393,8 @@ class LlamaPipelineForwards:
|
|||
|
||||
|
||||
def get_llama_flash_attention_forward():
|
||||
|
||||
from colossalai.kernel.cuda_native import AttnMaskType, ColoAttention
|
||||
|
||||
from transformers.models.llama.modeling_llama import LlamaAttention, apply_rotary_pos_emb
|
||||
|
||||
|
|
@ -423,6 +428,7 @@ def get_llama_flash_attention_forward():
|
|||
kv_seq_len += past_key_value[0].shape[-2]
|
||||
|
||||
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
||||
|
||||
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
|
||||
|
||||
if past_key_value is not None:
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
import importlib
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
import torch.nn as nn
|
||||
|
||||
|
|
@ -130,12 +131,28 @@ _POLICY_LIST = {
|
|||
PolicyLocation(file_name="chatglm2", class_name="ChatGLMForConditionalGenerationPolicy"),
|
||||
}
|
||||
|
||||
_INFER_POLICY_LIST = {
|
||||
# LlaMa
|
||||
"transformers.models.llama.modeling_llama.LlamaModel":
|
||||
PolicyLocation(file_name="llama", class_name="LlamaModelInferPolicy"),
|
||||
"transformers.models.llama.modeling_llama.LlamaForCausalLM":
|
||||
PolicyLocation(file_name="llama", class_name="LlamaModelInferPolicy"),
|
||||
# Bloom
|
||||
"transformers.models.bloom.modeling_bloom.BloomModel":
|
||||
PolicyLocation(file_name="bloom", class_name="BloomModelInferPolicy"),
|
||||
"transformers.models.bloom.modeling_bloom.BloomForCausalLM":
|
||||
PolicyLocation(file_name="bloom", class_name="BloomModelInferPolicy"),
|
||||
}
|
||||
|
||||
def import_policy(policy_location: PolicyLocation) -> Policy:
|
||||
|
||||
def import_policy(policy_location: PolicyLocation, inference_only: Optional[bool] = False) -> Policy:
|
||||
"""
|
||||
Dynamically import a Policy class based on the policy location.
|
||||
"""
|
||||
module_name = f"colossalai.shardformer.policies.{policy_location.file_name}"
|
||||
if inference_only:
|
||||
module_name = f"colossalai.inference.tensor_parallel.policies.{policy_location.file_name}"
|
||||
else:
|
||||
module_name = f"colossalai.shardformer.policies.{policy_location.file_name}"
|
||||
module = importlib.import_module(module_name)
|
||||
return getattr(module, policy_location.class_name)
|
||||
|
||||
|
|
@ -151,7 +168,7 @@ def _fullname(obj):
|
|||
return module + '.' + klass.__qualname__
|
||||
|
||||
|
||||
def get_autopolicy(model: nn.Module) -> Policy:
|
||||
def get_autopolicy(model: nn.Module, inference_only: Optional[bool] = False) -> Policy:
|
||||
r"""
|
||||
Return the auto policy for the model
|
||||
|
||||
|
|
@ -162,12 +179,15 @@ def get_autopolicy(model: nn.Module) -> Policy:
|
|||
:class:`Policy`: The auto policy for the model
|
||||
"""
|
||||
full_name = _fullname(model)
|
||||
policy_location = _POLICY_LIST.get(full_name, None)
|
||||
if inference_only:
|
||||
policy_location = _INFER_POLICY_LIST.get(full_name, None)
|
||||
else:
|
||||
policy_location = _POLICY_LIST.get(full_name, None)
|
||||
|
||||
if policy_location is None:
|
||||
raise NotImplementedError(
|
||||
f"Auto policy for {model.__class__.__qualname__} is not implemented\n. Supported models are {list(_POLICY_LIST.keys())}"
|
||||
)
|
||||
else:
|
||||
policy = import_policy(policy_location)
|
||||
policy = import_policy(policy_location, inference_only)
|
||||
return policy()
|
||||
|
|
|
|||
|
|
@ -32,6 +32,9 @@ class ShardConfig:
|
|||
enable_jit_fused: bool = False
|
||||
enable_sequence_parallelism: bool = False
|
||||
enable_sequence_overlap: bool = False
|
||||
inference_only: bool = False
|
||||
enable_sequence_parallelism: bool = False
|
||||
enable_sequence_overlap: bool = False
|
||||
|
||||
# pipeline_parallel_size: int
|
||||
# data_parallel_size: int
|
||||
|
|
@ -68,3 +71,9 @@ class ShardConfig:
|
|||
self.enable_jit_fused = True
|
||||
self.enable_sequence_parallelism = True
|
||||
self.enable_sequence_overlap = True
|
||||
|
||||
def _infer(self):
|
||||
"""
|
||||
Set default params for inference.
|
||||
"""
|
||||
assert self.pipeline_stage_manager is None, "pipeline parallelism is not supported in inference for now"
|
||||
|
|
|
|||
|
|
@ -27,7 +27,7 @@ class ModelSharder(object):
|
|||
|
||||
def __init__(self, model: nn.Module, policy: Policy, shard_config: ShardConfig = None) -> None:
|
||||
self.model = model
|
||||
self.policy = get_autopolicy(self.model) if policy is None else policy
|
||||
self.policy = get_autopolicy(self.model, shard_config.inference_only) if policy is None else policy
|
||||
self.shard_config = shard_config
|
||||
|
||||
def shard(self) -> List[Dict[int, Tensor]]:
|
||||
|
|
|
|||
|
|
@ -0,0 +1,100 @@
|
|||
import argparse
|
||||
import os
|
||||
import time
|
||||
|
||||
import torch
|
||||
from transformers import BloomForCausalLM, BloomTokenizerFast
|
||||
|
||||
import colossalai
|
||||
from colossalai.inference.tensor_parallel.engine import TPInferEngine
|
||||
from colossalai.logging import disable_existing_loggers
|
||||
from colossalai.shardformer import ShardConfig
|
||||
from colossalai.testing import clear_cache_before_run, rerun_if_address_is_in_use, spawn
|
||||
|
||||
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = 'true'
|
||||
|
||||
|
||||
def print_perf_stats(latency_set, config, bs, warmup=3):
|
||||
# trim warmup queries
|
||||
latency_set = list(latency_set)
|
||||
latency_set = latency_set[warmup:]
|
||||
count = len(latency_set)
|
||||
|
||||
if count > 0:
|
||||
latency_set.sort()
|
||||
avg = sum(latency_set) / count
|
||||
num_layers = getattr(config, "num_layers", config.num_hidden_layers)
|
||||
num_parameters = num_layers * config.hidden_size * config.hidden_size * 12
|
||||
num_bytes = 2 # float16
|
||||
|
||||
print("Avg Per Token Latency: {0:8.2f} ms".format(avg * 1000))
|
||||
print("Avg BW: {0:8.2f} GB/s".format(1 / avg * num_parameters * num_bytes / 1e9))
|
||||
print("Avg flops: {0:8.2f} TFlops/s".format(1 / avg * num_parameters * num_bytes * bs / 1e12))
|
||||
print("Avg Throughput: tokens/s: {}".format((1000 / (avg * 1000)) * bs))
|
||||
|
||||
|
||||
def bench_bloom(args):
|
||||
model_path = args.path
|
||||
max_batch_size = args.batch_size
|
||||
max_input_len = args.input_len
|
||||
max_output_len = args.output_len
|
||||
|
||||
tokenizer = BloomTokenizerFast.from_pretrained(model_path)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
model = BloomForCausalLM.from_pretrained(model_path, pad_token_id=tokenizer.eos_token_id)
|
||||
model = model.half()
|
||||
|
||||
# init TPInferEngine and shard the original model
|
||||
# To benchmark torch original, comment out the line of optimizing model
|
||||
shard_config = ShardConfig(enable_tensor_parallelism=True if args.tp_size > 1 else False, inference_only=True)
|
||||
infer_engine = TPInferEngine(model, shard_config, max_batch_size, max_input_len, max_output_len)
|
||||
|
||||
# prepare data for generation
|
||||
generate_kwargs = dict(max_new_tokens=max_output_len, do_sample=False)
|
||||
input_tokens = {
|
||||
"input_ids": torch.randint(10, 1000, (max_batch_size, max_input_len)),
|
||||
"attention_mask": torch.ones((max_batch_size, max_input_len))
|
||||
}
|
||||
for t in input_tokens:
|
||||
if torch.is_tensor(input_tokens[t]):
|
||||
input_tokens[t] = input_tokens[t].to(torch.cuda.current_device())
|
||||
print(f" input_tokens[{t}].shape: {input_tokens[t].shape}")
|
||||
|
||||
iters = 10
|
||||
times = []
|
||||
for i in range(iters):
|
||||
torch.cuda.synchronize()
|
||||
start = time.time()
|
||||
outputs = infer_engine.generate(input_tokens, **generate_kwargs)
|
||||
torch.cuda.synchronize()
|
||||
end = time.time()
|
||||
out_len = outputs.shape[1]
|
||||
print(f" iter {i}: out len {str(out_len)}, generation time {str(end - start)} s")
|
||||
times.append((end - start) / (out_len - max_input_len))
|
||||
|
||||
print_perf_stats(times, model.config, max_batch_size)
|
||||
|
||||
|
||||
def check_bloom(rank, world_size, port, args):
|
||||
disable_existing_loggers()
|
||||
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
|
||||
bench_bloom(args)
|
||||
|
||||
|
||||
@rerun_if_address_is_in_use()
|
||||
@clear_cache_before_run()
|
||||
def test_bloom(args):
|
||||
spawn(check_bloom, args.tp_size, args=args)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('-p', '--path', type=str, help='Model path', required=True)
|
||||
parser.add_argument('-tp', '--tp_size', type=int, default=1, help='Tensor parallel size')
|
||||
parser.add_argument('-b', '--batch_size', type=int, default=16, help='Maximum batch size')
|
||||
parser.add_argument('--input_len', type=int, default=1024, help='Maximum input length')
|
||||
parser.add_argument('--output_len', type=int, default=128, help='Maximum output length')
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
test_bloom(args)
|
||||
|
|
@ -0,0 +1,128 @@
|
|||
import argparse
|
||||
import os
|
||||
import time
|
||||
|
||||
import torch
|
||||
from torch.profiler import ProfilerActivity, profile, record_function
|
||||
from transformers import LlamaForCausalLM, LlamaTokenizer
|
||||
|
||||
import colossalai
|
||||
from colossalai.inference.tensor_parallel.engine import TPInferEngine
|
||||
from colossalai.logging import disable_existing_loggers
|
||||
from colossalai.shardformer import ShardConfig
|
||||
from colossalai.testing import clear_cache_before_run, rerun_if_address_is_in_use, spawn
|
||||
|
||||
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = 'true'
|
||||
|
||||
|
||||
def init_to_get_rotary(self, base=10000):
|
||||
self.config.head_dim_ = self.config.hidden_size // self.config.num_attention_heads
|
||||
if not hasattr(self.config, "rope_scaling"):
|
||||
rope_scaling_factor = 1.0
|
||||
else:
|
||||
rope_scaling_factor = self.config.rope_scaling.factor if self.config.rope_scaling is not None else 1.0
|
||||
if hasattr(self.config, "max_sequence_length"):
|
||||
max_seq_len = self.config.max_sequence_length
|
||||
elif hasattr(self.config, "max_position_embeddings"):
|
||||
max_seq_len = self.config.max_position_embeddings * rope_scaling_factor
|
||||
else:
|
||||
max_seq_len = 2048 * rope_scaling_factor
|
||||
base = float(base)
|
||||
inv_freq = 1.0 / (base**(torch.arange(0, self.config.head_dim_, 2, device="cpu", dtype=torch.float32) /
|
||||
self.config.head_dim_))
|
||||
t = torch.arange(max_seq_len + 1024 * 64, device="cpu", dtype=torch.float32) / rope_scaling_factor
|
||||
freqs = torch.outer(t, inv_freq)
|
||||
|
||||
self._cos_cached = torch.cos(freqs).to(torch.float16).cuda()
|
||||
self._sin_cached = torch.sin(freqs).to(torch.float16).cuda()
|
||||
return
|
||||
|
||||
|
||||
def print_perf_stats(latency_set, config, bs, warmup=3):
|
||||
# trim warmup queries
|
||||
latency_set = list(latency_set)
|
||||
latency_set = latency_set[warmup:]
|
||||
count = len(latency_set)
|
||||
|
||||
if count > 0:
|
||||
latency_set.sort()
|
||||
avg = sum(latency_set) / count
|
||||
num_layers = getattr(config, "num_layers", config.num_hidden_layers)
|
||||
num_parameters = num_layers * config.hidden_size * config.hidden_size * 12
|
||||
num_bytes = 2
|
||||
|
||||
print("Avg Per Token Latency: {0:8.2f} ms".format(avg * 1000))
|
||||
print("Avg BW: {0:8.2f} GB/s".format(1 / avg * num_parameters * num_bytes / 1e9))
|
||||
print("Avg flops: {0:8.2f} TFlops/s".format(1 / avg * num_parameters * num_bytes * bs / 1e12))
|
||||
|
||||
|
||||
def run_llama_test(args):
|
||||
llama_model_path = args.path
|
||||
max_batch_size = args.batch_size
|
||||
max_input_len = args.input_len
|
||||
max_output_len = args.output_len
|
||||
|
||||
tokenizer = LlamaTokenizer.from_pretrained(llama_model_path)
|
||||
tokenizer.pad_token_id = tokenizer.unk_token_id
|
||||
model = LlamaForCausalLM.from_pretrained(llama_model_path, pad_token_id=tokenizer.eos_token_id)
|
||||
init_to_get_rotary(model.model, base=10000)
|
||||
model = model.half()
|
||||
|
||||
model_config = model.config
|
||||
|
||||
shard_config = ShardConfig(enable_tensor_parallelism=True if args.tp_size > 1 else False, inference_only=True)
|
||||
infer_engine = TPInferEngine(model, shard_config, max_batch_size, max_input_len, max_output_len)
|
||||
|
||||
generate_kwargs = dict(max_new_tokens=max_output_len, do_sample=False)
|
||||
input_tokens = {
|
||||
"input_ids": torch.randint(1, 1000, (max_batch_size, max_input_len), device='cuda'),
|
||||
"attention_mask": torch.ones((max_batch_size, max_input_len), device='cuda')
|
||||
}
|
||||
|
||||
iters = 10
|
||||
times = []
|
||||
|
||||
for i in range(iters):
|
||||
torch.cuda.synchronize()
|
||||
start = time.time()
|
||||
outputs = infer_engine.generate(input_tokens, **generate_kwargs)
|
||||
torch.cuda.synchronize()
|
||||
end = time.time()
|
||||
out_len = outputs.shape[1]
|
||||
print("generation time {} s".format(str(end - start)))
|
||||
times.append((end - start) / (out_len - max_input_len))
|
||||
|
||||
print("outputs, ", len(outputs))
|
||||
print_perf_stats(times, model_config, max_batch_size)
|
||||
|
||||
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], record_shapes=True) as prof:
|
||||
with record_function("model_inference"):
|
||||
torch.cuda.synchronize()
|
||||
outputs = infer_engine.generate(input_tokens, **generate_kwargs)
|
||||
torch.cuda.synchronize()
|
||||
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))
|
||||
|
||||
|
||||
def check_llama(rank, world_size, port, args):
|
||||
disable_existing_loggers()
|
||||
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
|
||||
run_llama_test(args)
|
||||
|
||||
|
||||
@rerun_if_address_is_in_use()
|
||||
@clear_cache_before_run()
|
||||
def test_llama(args):
|
||||
spawn(check_llama, args.tp_size, args=args)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('-p', '--path', type=str, help='Model path', required=True)
|
||||
parser.add_argument('-tp', '--tp_size', type=int, default=1, help='Tensor parallel size')
|
||||
parser.add_argument('-b', '--batch_size', type=int, default=16, help='Maximum batch size')
|
||||
parser.add_argument('--input_len', type=int, default=1024, help='Maximum input length')
|
||||
parser.add_argument('--output_len', type=int, default=128, help='Maximum output length')
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
test_llama(args)
|
||||
|
|
@ -0,0 +1,53 @@
|
|||
import copy
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from torch import Tensor
|
||||
from torch import distributed as dist
|
||||
from torch.distributed import ProcessGroup
|
||||
from torch.nn import Module
|
||||
from torch.optim import Adam, Optimizer
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster.plugin import HybridParallelPlugin
|
||||
from colossalai.booster.plugin.hybrid_parallel_plugin import HybridParallelModule
|
||||
from colossalai.shardformer import ShardConfig, ShardFormer
|
||||
from colossalai.shardformer._utils import getattr_
|
||||
from colossalai.shardformer.policies.auto_policy import Policy
|
||||
from colossalai.tensor.d_tensor.api import is_customized_distributed_tensor, is_distributed_tensor
|
||||
|
||||
|
||||
def build_model(
|
||||
model_fn,
|
||||
enable_fused_normalization=False,
|
||||
enable_tensor_parallelism=False,
|
||||
enable_flash_attention=False,
|
||||
enable_jit_fused=False,
|
||||
):
|
||||
# create new model
|
||||
org_model = model_fn()
|
||||
|
||||
# shard model
|
||||
shard_config = ShardConfig(enable_fused_normalization=enable_fused_normalization,
|
||||
enable_tensor_parallelism=enable_tensor_parallelism,
|
||||
enable_flash_attention=enable_flash_attention,
|
||||
enable_jit_fused=enable_jit_fused,
|
||||
inference_only=True)
|
||||
model_copy = copy.deepcopy(org_model)
|
||||
shard_former = ShardFormer(shard_config=shard_config)
|
||||
sharded_model, shared_params = shard_former.optimize(model_copy)
|
||||
return org_model.cuda(), sharded_model.cuda()
|
||||
|
||||
|
||||
def run_infer(original_model, sharded_model, data_gen_fn, output_transform_fn):
|
||||
# prepare input
|
||||
data = data_gen_fn()
|
||||
data = {k: v.cuda() for k, v in data.items()}
|
||||
# run forward
|
||||
org_output = original_model(**data)
|
||||
org_output = output_transform_fn(org_output)
|
||||
|
||||
shard_output = sharded_model(**data)
|
||||
shard_output = output_transform_fn(shard_output)
|
||||
|
||||
return org_output, shard_output
|
||||
|
|
@ -0,0 +1,58 @@
|
|||
import os
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
import colossalai
|
||||
from colossalai.inference.tensor_parallel import TPInferEngine
|
||||
from colossalai.logging import disable_existing_loggers
|
||||
from colossalai.shardformer import ShardConfig
|
||||
from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
|
||||
from tests.kit.model_zoo import model_zoo
|
||||
|
||||
TP_SIZE = 2
|
||||
MAX_BATCH_SIZE = 4
|
||||
MAX_INPUT_LEN = 16
|
||||
MAX_OUTPUT_LEN = 32
|
||||
|
||||
CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.5')
|
||||
|
||||
|
||||
@parameterize('test_config', [{
|
||||
'tp_size': TP_SIZE,
|
||||
}])
|
||||
def run(test_config):
|
||||
|
||||
sub_model_zoo = model_zoo.get_sub_registry('transformers_bloom_for_causal_lm')
|
||||
for name, (model_fn, data_gen_fn, _, _, _) in sub_model_zoo.items():
|
||||
orig_model = model_fn()
|
||||
orig_model = orig_model.half()
|
||||
data = data_gen_fn()
|
||||
|
||||
shard_config = ShardConfig(enable_tensor_parallelism=True if test_config['tp_size'] > 1 else False,
|
||||
inference_only=True)
|
||||
infer_engine = TPInferEngine(orig_model, shard_config, MAX_BATCH_SIZE, MAX_INPUT_LEN, MAX_OUTPUT_LEN)
|
||||
|
||||
generate_kwargs = dict(do_sample=False)
|
||||
outputs = infer_engine.generate(data, **generate_kwargs)
|
||||
|
||||
assert outputs is not None
|
||||
|
||||
|
||||
def check_bloom(rank, world_size, port):
|
||||
disable_existing_loggers()
|
||||
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
|
||||
run()
|
||||
|
||||
|
||||
@pytest.mark.skipif(not CUDA_SUPPORT, reason="kv-cache manager engine requires cuda version to be higher than 11.5")
|
||||
@pytest.mark.dist
|
||||
@rerun_if_address_is_in_use()
|
||||
@clear_cache_before_run()
|
||||
def test_bloom_infer():
|
||||
spawn(check_bloom, TP_SIZE)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
test_bloom_infer()
|
||||
|
|
@ -0,0 +1,94 @@
|
|||
from itertools import accumulate
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from packaging import version
|
||||
from transformers import BloomConfig, BloomForCausalLM, LlamaConfig, LlamaForCausalLM
|
||||
from transformers.tokenization_utils_base import BatchEncoding
|
||||
|
||||
import colossalai
|
||||
from colossalai.inference.tensor_parallel import TPInferEngine
|
||||
from colossalai.inference.tensor_parallel.batch_infer_state import BatchInferState
|
||||
from colossalai.logging import disable_existing_loggers
|
||||
from colossalai.shardformer import ShardConfig
|
||||
from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
|
||||
|
||||
TP_SIZE = 2
|
||||
MAX_BATCH_SIZE = 4
|
||||
MAX_INPUT_LEN = 16
|
||||
MAX_OUTPUT_LEN = 8
|
||||
|
||||
CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.5')
|
||||
|
||||
|
||||
@parameterize('test_config', [{
|
||||
'tp_size': TP_SIZE,
|
||||
}])
|
||||
def run(test_config):
|
||||
model_config = BloomConfig(num_hidden_layers=4, hidden_size=128, intermediate_size=256, num_attention_heads=4)
|
||||
model = BloomForCausalLM(model_config)
|
||||
model = model.half()
|
||||
model.to(torch.cuda.current_device())
|
||||
|
||||
# 1. check TPInferEngine init and model optimization
|
||||
shard_config = ShardConfig(enable_tensor_parallelism=True if test_config['tp_size'] > 1 else False,
|
||||
inference_only=True)
|
||||
infer_engine = TPInferEngine(model, shard_config, MAX_BATCH_SIZE, MAX_INPUT_LEN, MAX_OUTPUT_LEN)
|
||||
|
||||
assert infer_engine.cache_manager is not None
|
||||
assert infer_engine.tp_size == TP_SIZE
|
||||
assert infer_engine.head_num == model_config.num_attention_heads // TP_SIZE
|
||||
|
||||
# 2. check data preparation
|
||||
input_ids_list = [[80540, 15473, 3331, 11970, 90472, 361, 61335], [80540, 15473, 3331, 11970],
|
||||
[80540, 15473, 3331, 11970], [80540, 15473]]
|
||||
batch_size = len(input_ids_list)
|
||||
max_seq_len = max(len(li) for li in input_ids_list)
|
||||
attention_mask = [[0] * max_seq_len for _ in range(batch_size)]
|
||||
for i, li in enumerate(input_ids_list):
|
||||
attention_mask[i][max_seq_len - len(li):] = [1 for _ in range(len(li))]
|
||||
data = dict(input_ids=input_ids_list, attention_mask=attention_mask)
|
||||
inputs_batch_encoding = BatchEncoding(data=data)
|
||||
seq_lengths = [len(li) for li in input_ids_list]
|
||||
start_loc = list(accumulate([0] + seq_lengths[:-1]))
|
||||
seq_lengths = torch.tensor(seq_lengths, dtype=torch.int32)
|
||||
start_loc = torch.tensor(start_loc, dtype=torch.int32)
|
||||
# input token id list as inputs
|
||||
batch_state_out1 = infer_engine.prepare_batch_state(inputs_batch_encoding)
|
||||
# BatchEncoding as inputs
|
||||
batch_state_out2 = infer_engine.prepare_batch_state(input_ids_list)
|
||||
|
||||
assert batch_state_out1.batch_size == batch_state_out2.batch_size == batch_size
|
||||
assert torch.equal(batch_state_out1.seq_len, batch_state_out2.seq_len)
|
||||
|
||||
# The following tests are discarded for now, and will be reused after all features are added
|
||||
# assert torch.equal(batch_state_out1.seq_len.to(seq_lengths.device), seq_lengths)
|
||||
# assert torch.equal(batch_state_out2.seq_len.to(seq_lengths.device), seq_lengths)
|
||||
# assert torch.equal(batch_state_out1.start_loc.to(start_loc.device), start_loc)
|
||||
# assert torch.equal(batch_state_out2.start_loc.to(start_loc.device), start_loc)
|
||||
|
||||
# 3. check optimized model generate
|
||||
input_ids = torch.randint(low=10, high=1000, size=(MAX_BATCH_SIZE, MAX_INPUT_LEN))
|
||||
generate_kwargs = dict(do_sample=False)
|
||||
infer_engine.generate(input_ids, **generate_kwargs)
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
|
||||
def check_engine(rank, world_size, port):
|
||||
disable_existing_loggers()
|
||||
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
|
||||
run()
|
||||
|
||||
|
||||
@pytest.mark.skipif(not CUDA_SUPPORT, reason="kv-cache manager engine requires cuda version to be higher than 11.5")
|
||||
@pytest.mark.dist
|
||||
@rerun_if_address_is_in_use()
|
||||
@clear_cache_before_run()
|
||||
def test_engine():
|
||||
spawn(check_engine, TP_SIZE)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
test_engine()
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
import os
|
||||
from packaging import version
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
from colossalai.inference.tensor_parallel import MemoryManager
|
||||
from colossalai.logging import disable_existing_loggers
|
||||
from colossalai.testing import rerun_if_address_is_in_use, spawn
|
||||
|
||||
BATCH_SIZE = 4
|
||||
INPUT_LEN = 16
|
||||
OUTPUT_LEN = 8
|
||||
LAYER_NUM = 4
|
||||
HEAD_NUM = 32
|
||||
HEAD_DIM = 128
|
||||
|
||||
CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.5')
|
||||
|
||||
def create_cache_manager(rank, world_size, port, batch_size, input_len, output_len, layer_num, head_num, head_dim):
|
||||
os.environ['RANK'] = str(rank)
|
||||
os.environ['LOCAL_RANK'] = str(rank)
|
||||
os.environ['WORLD_SIZE'] = str(world_size)
|
||||
os.environ['MASTER_ADDR'] = 'localhost'
|
||||
os.environ['MASTER_PORT'] = str(port)
|
||||
disable_existing_loggers()
|
||||
|
||||
size = batch_size * (input_len + output_len)
|
||||
kvcache_manager = MemoryManager(size, torch.float16, head_num // world_size, head_dim, layer_num, rank)
|
||||
key_buffers = kvcache_manager.key_buffer
|
||||
value_buffers = kvcache_manager.value_buffer
|
||||
assert len(key_buffers) == len(value_buffers) == layer_num
|
||||
assert key_buffers[0].shape == value_buffers[0].shape
|
||||
# required size exceeds the maximum allocated size
|
||||
invalid_locs = kvcache_manager.alloc_contiguous(size + 1)
|
||||
assert invalid_locs is None
|
||||
# for prefill stage, allocation via alloc and alloc_contiguous should be the same
|
||||
total_token_prefill = batch_size * input_len
|
||||
prefill_locs = kvcache_manager.alloc(total_token_prefill)
|
||||
kvcache_manager.free_all()
|
||||
prefill_locs_contiguous = kvcache_manager.alloc_contiguous(total_token_prefill)[0]
|
||||
assert torch.equal(prefill_locs, prefill_locs_contiguous)
|
||||
assert torch.sum(kvcache_manager.mem_state).item() == size - total_token_prefill
|
||||
kvcache_manager.alloc_contiguous(batch_size)
|
||||
assert torch.all(kvcache_manager.mem_state[:total_token_prefill + batch_size] == False)
|
||||
|
||||
@pytest.mark.skipif(not CUDA_SUPPORT, reason="kv-cache manager engine requires cuda version to be higher than 11.5")
|
||||
@pytest.mark.dist
|
||||
@rerun_if_address_is_in_use()
|
||||
def test_cache_manager_dist():
|
||||
spawn(create_cache_manager,
|
||||
4,
|
||||
batch_size=BATCH_SIZE,
|
||||
input_len=INPUT_LEN,
|
||||
output_len=OUTPUT_LEN,
|
||||
layer_num=LAYER_NUM,
|
||||
head_num=HEAD_NUM,
|
||||
head_dim=HEAD_DIM)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
test_cache_manager_dist()
|
||||
|
|
@ -0,0 +1,84 @@
|
|||
import os
|
||||
import warnings
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
import colossalai
|
||||
from colossalai.inference.tensor_parallel.engine import TPInferEngine
|
||||
from colossalai.logging import disable_existing_loggers
|
||||
from colossalai.shardformer import ShardConfig
|
||||
from colossalai.testing import clear_cache_before_run, parameterize, rerun_if_address_is_in_use, spawn
|
||||
from tests.kit.model_zoo import model_zoo
|
||||
|
||||
os.environ['TRANSFORMERS_NO_ADVISORY_WARNINGS'] = 'true'
|
||||
TPSIZE = 2
|
||||
BATCH_SIZE = 8
|
||||
MAX_INPUT_LEN = 12
|
||||
MAX_OUTPUT_LEN = 100
|
||||
|
||||
CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.5')
|
||||
|
||||
|
||||
def init_to_get_rotary(self, base=10000):
|
||||
self.config.head_dim_ = self.config.hidden_size // self.config.num_attention_heads
|
||||
if not hasattr(self.config, "rope_scaling"):
|
||||
rope_scaling_factor = 1.0
|
||||
else:
|
||||
rope_scaling_factor = self.config.rope_scaling.factor if self.config.rope_scaling is not None else 1.0
|
||||
if hasattr(self.config, "max_sequence_length"):
|
||||
max_seq_len = self.config.max_sequence_length
|
||||
elif hasattr(self.config, "max_position_embeddings"):
|
||||
max_seq_len = self.config.max_position_embeddings * rope_scaling_factor
|
||||
else:
|
||||
max_seq_len = 2048 * rope_scaling_factor
|
||||
base = float(base)
|
||||
inv_freq = 1.0 / (base**(torch.arange(0, self.config.head_dim_, 2, device="cpu", dtype=torch.float32) /
|
||||
self.config.head_dim_))
|
||||
t = torch.arange(max_seq_len + 1024 * 64, device="cpu", dtype=torch.float32) / rope_scaling_factor
|
||||
freqs = torch.outer(t, inv_freq)
|
||||
|
||||
self._cos_cached = torch.cos(freqs).to(torch.float16).cuda()
|
||||
self._sin_cached = torch.sin(freqs).to(torch.float16).cuda()
|
||||
return
|
||||
|
||||
|
||||
@parameterize('test_config', [{
|
||||
'tp_size': TPSIZE,
|
||||
}])
|
||||
def run_llama_test(test_config):
|
||||
|
||||
sub_model_zoo = model_zoo.get_sub_registry('transformers_llama_for_casual_lm')
|
||||
for name, (model_fn, data_gen_fn, _, _, _) in sub_model_zoo.items():
|
||||
orig_model = model_fn()
|
||||
init_to_get_rotary(orig_model.model, base=10000)
|
||||
orig_model = orig_model.half()
|
||||
data = data_gen_fn()
|
||||
|
||||
shard_config = ShardConfig(enable_tensor_parallelism=True if test_config['tp_size'] > 1 else False,
|
||||
inference_only=True)
|
||||
infer_engine = TPInferEngine(orig_model, shard_config, BATCH_SIZE, MAX_INPUT_LEN, MAX_OUTPUT_LEN)
|
||||
|
||||
generate_kwargs = dict(do_sample=False)
|
||||
outputs = infer_engine.generate(data, **generate_kwargs)
|
||||
|
||||
assert outputs is not None
|
||||
|
||||
|
||||
def check_llama(rank, world_size, port):
|
||||
disable_existing_loggers()
|
||||
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
|
||||
run_llama_test()
|
||||
|
||||
|
||||
@pytest.mark.skipif(not CUDA_SUPPORT, reason="kv-cache manager engine requires cuda version to be higher than 11.5")
|
||||
@pytest.mark.dist
|
||||
@rerun_if_address_is_in_use()
|
||||
@clear_cache_before_run()
|
||||
def test_llama():
|
||||
spawn(check_llama, TPSIZE)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_llama()
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- encoding: utf-8 -*-
|
||||
import os
|
||||
import pytest
|
||||
import numpy as np
|
||||
from packaging import version
|
||||
|
||||
import torch
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
|
||||
try:
|
||||
from vllm import layernorm_ops
|
||||
rms_norm = layernorm_ops.rms_norm
|
||||
HAS_VLLM_KERNERL = True
|
||||
except:
|
||||
print("please install vllm kernels to install rmsnorm")
|
||||
print("install vllm from https://github.com/vllm-project/vllm to accelerate your inference")
|
||||
HAS_VLLM_KERNERL = False
|
||||
|
||||
class LlamaRMSNorm(nn.Module):
|
||||
def __init__(self, hidden_size, eps=1e-6):
|
||||
"""
|
||||
LlamaRMSNorm is equivalent to T5LayerNorm
|
||||
"""
|
||||
super().__init__()
|
||||
self.weight = nn.Parameter(torch.ones(hidden_size))
|
||||
self.variance_epsilon = eps
|
||||
|
||||
def forward(self, hidden_states):
|
||||
input_dtype = hidden_states.dtype
|
||||
hidden_states = hidden_states.to(torch.float32)
|
||||
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
||||
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
||||
return self.weight * hidden_states.to(input_dtype)
|
||||
|
||||
def cuda_rmsnorm_forward(hidden_states, weight, variance_epsilon):
|
||||
x = hidden_states
|
||||
out = torch.empty_like(x)
|
||||
rms_norm(
|
||||
out,
|
||||
x,
|
||||
weight,
|
||||
variance_epsilon,
|
||||
)
|
||||
return out
|
||||
|
||||
@pytest.mark.skipif(not HAS_VLLM_KERNERL, reason="You need to install llama supported cuda kernels to run this test")
|
||||
def test_rmsnorm():
|
||||
data = torch.randn((1024, 64), dtype=torch.float16, device="cuda")
|
||||
hg_rms = LlamaRMSNorm(64)
|
||||
hg_rms = hg_rms.half().cuda()
|
||||
out_torch = hg_rms(data)
|
||||
out_cuda = cuda_rmsnorm_forward(data, hg_rms.weight.data, hg_rms.variance_epsilon)
|
||||
|
||||
check = torch.allclose(out_torch.cpu(), out_cuda.cpu(), rtol=1e-3, atol=1e-5)
|
||||
assert check is True, "cuda rmsnorm forward is not matched with torch rmsnorm forward"
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_rmsnorm()
|
||||
|
|
@ -0,0 +1,156 @@
|
|||
#!/usr/bin/env python
|
||||
# -*- encoding: utf-8 -*-
|
||||
import pytest
|
||||
from typing import Tuple
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from transformers.models.llama.modeling_llama import apply_rotary_pos_emb, rotate_half
|
||||
|
||||
try:
|
||||
from vllm import pos_encoding_ops
|
||||
rotary_embedding_neox = pos_encoding_ops.rotary_embedding_neox
|
||||
HAS_VLLM_KERNERL = True
|
||||
except:
|
||||
print("fall back to original rotary_embedding_neox of huggingface")
|
||||
print("install vllm from https://github.com/vllm-project/vllm to accelerate your inference")
|
||||
HAS_VLLM_KERNERL = False
|
||||
|
||||
|
||||
def rotate_half(x: torch.Tensor) -> torch.Tensor:
|
||||
x1 = x[..., :x.shape[-1] // 2]
|
||||
x2 = x[..., x.shape[-1] // 2:]
|
||||
return torch.cat((-x2, x1), dim=-1)
|
||||
|
||||
|
||||
def apply_rotary_pos_emb(
|
||||
q: torch.Tensor,
|
||||
k: torch.Tensor,
|
||||
cos: torch.Tensor,
|
||||
sin: torch.Tensor,
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
q_embed = (q * cos) + (rotate_half(q) * sin)
|
||||
k_embed = (k * cos) + (rotate_half(k) * sin)
|
||||
return q_embed, k_embed
|
||||
|
||||
|
||||
class RefRotaryEmbeddingNeox(nn.Module):
|
||||
"""Reference implementation of the GPT-NeoX style rotary embedding."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
dim: int,
|
||||
max_position_embeddings: int = 2048,
|
||||
base: int = 10000,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.rotary_dim = dim
|
||||
self.max_position_embeddings = max_position_embeddings
|
||||
|
||||
# Create cos and sin embeddings.
|
||||
inv_freq = 1.0 / (base**(torch.arange(0, dim, 2) / dim))
|
||||
t = torch.arange(max_position_embeddings).float()
|
||||
freqs = torch.einsum("i,j->ij", t, inv_freq.float())
|
||||
emb = torch.cat((freqs, freqs), dim=-1)
|
||||
cos = emb.cos().to(dtype=inv_freq.dtype)
|
||||
sin = emb.sin().to(dtype=inv_freq.dtype)
|
||||
self.register_buffer("cos_cached", cos, persistent=False)
|
||||
self.register_buffer("sin_cached", sin, persistent=False)
|
||||
|
||||
def forward(
|
||||
self,
|
||||
positions: torch.Tensor, # [num_tokens]
|
||||
query: torch.Tensor, # [num_tokens, num_heads, head_size]
|
||||
key: torch.Tensor, # [num_tokens, num_heads, head_size]
|
||||
) -> Tuple[torch.Tensor, torch.Tensor]:
|
||||
|
||||
query_rot = query[..., :self.rotary_dim]
|
||||
query_pass = query[..., self.rotary_dim:]
|
||||
key_rot = key[..., :self.rotary_dim]
|
||||
key_pass = key[..., self.rotary_dim:]
|
||||
|
||||
query_rot = query_rot.transpose(0, 1)
|
||||
key_rot = key_rot.transpose(0, 1)
|
||||
cos = F.embedding(positions, self.cos_cached)
|
||||
sin = F.embedding(positions, self.sin_cached)
|
||||
query_rot, key_rot = apply_rotary_pos_emb(query_rot, key_rot, cos, sin)
|
||||
query_rot = query_rot.transpose(0, 1).contiguous()
|
||||
key_rot = key_rot.transpose(0, 1).contiguous()
|
||||
|
||||
query = torch.cat((query_rot, query_pass), dim=-1)
|
||||
key = torch.cat((key_rot, key_pass), dim=-1)
|
||||
|
||||
# Output query/key shape: [num_tokens, num_tokens, head_size]
|
||||
return query, key
|
||||
|
||||
def run_rotary_embedding_neox(
|
||||
num_tokens: int,
|
||||
num_heads: int,
|
||||
head_size: int,
|
||||
max_position: int,
|
||||
rotary_dim: int,
|
||||
dtype: torch.dtype,
|
||||
base: int = 10000,
|
||||
) -> None:
|
||||
positions = torch.randint(0, max_position, (num_tokens, ), device='cuda')
|
||||
query = torch.randn(num_tokens,
|
||||
num_heads * head_size,
|
||||
dtype=dtype,
|
||||
device='cuda')
|
||||
key = torch.randn(num_tokens,
|
||||
num_heads * head_size,
|
||||
dtype=dtype,
|
||||
device='cuda')
|
||||
|
||||
# Create the rotary embedding.
|
||||
inv_freq = 1.0 / (base**(torch.arange(0, rotary_dim, 2) / rotary_dim))
|
||||
t = torch.arange(max_position).float()
|
||||
freqs = torch.einsum('i,j -> ij', t, inv_freq.float())
|
||||
cos = freqs.cos()
|
||||
sin = freqs.sin()
|
||||
cos_sin_cache = torch.cat((cos, sin), dim=-1)
|
||||
cos_sin_cache = cos_sin_cache.to(dtype=dtype, device='cuda')
|
||||
|
||||
# Run the kernel. The kernel is in-place, so we need to clone the inputs.
|
||||
out_query = query.clone()
|
||||
out_key = key.clone()
|
||||
rotary_embedding_neox(
|
||||
positions,
|
||||
out_query,
|
||||
out_key,
|
||||
head_size,
|
||||
cos_sin_cache,
|
||||
)
|
||||
|
||||
# Run the reference implementation.
|
||||
ref_rotary_embedding = RefRotaryEmbeddingNeox(
|
||||
dim=rotary_dim,
|
||||
max_position_embeddings=max_position,
|
||||
base=base,
|
||||
).to(dtype=dtype, device='cuda')
|
||||
ref_query, ref_key = ref_rotary_embedding(
|
||||
positions,
|
||||
query.view(num_tokens, num_heads, head_size),
|
||||
key.view(num_tokens, num_heads, head_size),
|
||||
)
|
||||
ref_query = ref_query.view(num_tokens, num_heads * head_size)
|
||||
ref_key = ref_key.view(num_tokens, num_heads * head_size)
|
||||
|
||||
# Compare the results.
|
||||
assert torch.allclose(out_query, ref_query, atol=1e-3, rtol=1e-5)
|
||||
assert torch.allclose(out_key, ref_key, atol=1e-3, rtol=1e-5)
|
||||
|
||||
@pytest.mark.skipif(not HAS_VLLM_KERNERL, reason="You need to install llama supported cuda kernels to run this test")
|
||||
def test_rotary_embedding():
|
||||
run_rotary_embedding_neox(
|
||||
num_tokens=1024,
|
||||
num_heads=8,
|
||||
head_size=64,
|
||||
max_position=8192,
|
||||
rotary_dim=64,
|
||||
dtype=torch.float16,
|
||||
)
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_rotary_embedding()
|
||||
|
|
@ -0,0 +1,28 @@
|
|||
import math
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
from torch.nn import functional as F
|
||||
|
||||
|
||||
def torch_context_attention(xq, xk, xv, bs, seqlen, num_head, head_dim):
|
||||
'''
|
||||
adepted from https://github.com/ModelTC/lightllm/blob/main/lightllm/models/bloom/triton_kernel/context_flashattention_nopad.py#L253
|
||||
'''
|
||||
xq = xq.view(bs, seqlen, num_head, head_dim)
|
||||
xk = xk.view(bs, seqlen, num_head, head_dim)
|
||||
xv = xv.view(bs, seqlen, num_head, head_dim)
|
||||
mask = torch.tril(torch.ones(seqlen, seqlen), diagonal=0).unsqueeze(0).unsqueeze(0).cuda()
|
||||
mask[mask == 0.] = -100000000.0
|
||||
mask = mask.repeat(bs, num_head, 1, 1)
|
||||
keys = xk
|
||||
values = xv
|
||||
xq = xq.transpose(1, 2)
|
||||
keys = keys.transpose(1, 2)
|
||||
values = values.transpose(1, 2)
|
||||
sm_scale = 1 / math.sqrt(head_dim)
|
||||
scores = torch.matmul(xq, keys.transpose(2, 3)) * sm_scale
|
||||
scores = F.softmax(scores.float() + mask, dim=-1).to(dtype=torch.float16)
|
||||
|
||||
output = torch.matmul(scores, values).transpose(1, 2).contiguous().reshape(-1, num_head, head_dim)
|
||||
return output
|
||||
|
|
@ -0,0 +1,54 @@
|
|||
import math
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton import bloom_context_attn_fwd
|
||||
from tests.test_infer_ops.triton.kernel_utils import torch_context_attention
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_bloom_context_attention():
|
||||
bs = 4
|
||||
head_num = 8
|
||||
seq_len = 1024
|
||||
head_dim = 64
|
||||
|
||||
query = torch.randn((bs * seq_len, head_num, head_dim), dtype=torch.float16, device="cuda")
|
||||
k = torch.randn((bs * seq_len, head_num, head_dim), dtype=torch.float16, device="cuda")
|
||||
v = torch.randn((bs * seq_len, head_num, head_dim), dtype=torch.float16, device="cuda")
|
||||
|
||||
max_input_len = seq_len
|
||||
b_start = torch.zeros((bs,), device="cuda", dtype=torch.int32)
|
||||
b_len = torch.zeros((bs,), device="cuda", dtype=torch.int32)
|
||||
|
||||
for i in range(bs):
|
||||
b_start[i] = i * seq_len
|
||||
b_len[i] = seq_len
|
||||
|
||||
o = torch.randn((bs * seq_len, head_num, head_dim), dtype=torch.float16, device="cuda")
|
||||
alibi = torch.zeros((head_num,), dtype=torch.float32, device="cuda")
|
||||
bloom_context_attn_fwd(query.clone(), k.clone(), v.clone(), o, b_start, b_len, max_input_len, alibi)
|
||||
|
||||
torch_out = torch_context_attention(query.clone(), k.clone(), v.clone(), bs, seq_len, head_num, head_dim)
|
||||
|
||||
assert torch.allclose(torch_out.cpu(), o.cpu(), rtol=1e-3,
|
||||
atol=1e-2), "outputs from triton and torch are not matched"
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_bloom_context_attention()
|
||||
|
|
@ -0,0 +1,39 @@
|
|||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
from torch import nn
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton.copy_kv_cache_dest import copy_kv_cache_to_dest
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_kv_cache_copy_op():
|
||||
|
||||
B_NTX = 32 * 2048
|
||||
head_num = 8
|
||||
head_dim = 64
|
||||
|
||||
cache = torch.randn((B_NTX, head_num, head_dim), device="cuda", dtype=torch.float16)
|
||||
dest_index = torch.arange(0, B_NTX, device="cuda", dtype=torch.int32)
|
||||
|
||||
dest_data = torch.ones((B_NTX, head_num, head_dim), device="cuda", dtype=torch.float16)
|
||||
|
||||
copy_kv_cache_to_dest(cache, dest_index, dest_data)
|
||||
|
||||
assert torch.allclose(cache.cpu(), dest_data.cpu(), rtol=1e-3,
|
||||
atol=1e-3), "copy_kv_cache_to_dest outputs from triton and torch are not matched"
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_kv_cache_copy_op()
|
||||
|
|
@ -0,0 +1,44 @@
|
|||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
from colossalai.kernel.triton import layer_norm
|
||||
from colossalai.testing.utils import parameterize
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton.fused_layernorm import _layer_norm_fwd_fused
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
@parameterize('M', [2, 4, 8, 16])
|
||||
@parameterize('N', [64, 128])
|
||||
def test_layer_norm(M, N):
|
||||
dtype = torch.float16
|
||||
eps = 1e-5
|
||||
x_shape = (M, N)
|
||||
w_shape = (x_shape[-1],)
|
||||
weight = torch.rand(w_shape, dtype=dtype, device='cuda')
|
||||
bias = torch.rand(w_shape, dtype=dtype, device='cuda')
|
||||
x = -2.3 + 0.5 * torch.randn(x_shape, dtype=dtype, device='cuda')
|
||||
|
||||
y_triton = layer_norm(x, weight, bias, eps)
|
||||
y_torch = torch.nn.functional.layer_norm(x, w_shape, weight, bias, eps).to(dtype)
|
||||
|
||||
assert y_triton.shape == y_torch.shape
|
||||
assert y_triton.dtype == y_torch.dtype
|
||||
print("max delta: ", torch.max(torch.abs(y_triton - y_torch)))
|
||||
assert torch.allclose(y_triton, y_torch, atol=1e-2, rtol=0)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_layer_norm()
|
||||
|
|
@ -0,0 +1,53 @@
|
|||
import math
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
from torch import nn
|
||||
from torch.nn import functional as F
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton import llama_context_attn_fwd
|
||||
from tests.test_infer_ops.triton.kernel_utils import torch_context_attention
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_llama_context_attention():
|
||||
bs = 4
|
||||
head_num = 8
|
||||
seq_len = 1024
|
||||
head_dim = 64
|
||||
|
||||
query = torch.randn((bs * seq_len, head_num, head_dim), dtype=torch.float16, device="cuda")
|
||||
k = torch.randn((bs * seq_len, head_num, head_dim), dtype=torch.float16, device="cuda")
|
||||
v = torch.randn((bs * seq_len, head_num, head_dim), dtype=torch.float16, device="cuda")
|
||||
|
||||
max_input_len = seq_len
|
||||
b_start = torch.zeros((bs,), device="cuda", dtype=torch.int32)
|
||||
b_len = torch.zeros((bs,), device="cuda", dtype=torch.int32)
|
||||
|
||||
for i in range(bs):
|
||||
b_start[i] = i * seq_len
|
||||
b_len[i] = seq_len
|
||||
|
||||
o = torch.randn((bs * seq_len, head_num, head_dim), dtype=torch.float16, device="cuda")
|
||||
llama_context_attn_fwd(query.clone(), k.clone(), v.clone(), o, b_start, b_len, max_input_len)
|
||||
|
||||
torch_out = torch_context_attention(query.clone(), k.clone(), v.clone(), bs, seq_len, head_num, head_dim)
|
||||
|
||||
assert torch.allclose(torch_out.cpu(), o.cpu(), rtol=1e-3,
|
||||
atol=1e-3), "outputs from triton and torch are not matched"
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_llama_context_attention()
|
||||
|
|
@ -0,0 +1,56 @@
|
|||
# Adapted from ModelTC https://github.com/ModelTC/lightllm
|
||||
|
||||
import time
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton.rotary_embedding_kernel import rotary_embedding_fwd
|
||||
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
def torch_rotary_emb(x, cos, sin):
|
||||
seq_len, h, dim = x.shape
|
||||
x0 = x[:, :, 0:dim // 2]
|
||||
x1 = x[:, :, dim // 2:dim]
|
||||
cos = cos.view((seq_len, 1, dim // 2))
|
||||
sin = sin.view((seq_len, 1, dim // 2))
|
||||
o0 = x0 * cos - x1 * sin
|
||||
o1 = x0 * sin + x1 * cos
|
||||
return torch.cat((o0, o1), dim=-1)
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_rotary_emb():
|
||||
SEQ_LEN = 1
|
||||
HEAD_NUM = 32
|
||||
HEAD_DIM = 128
|
||||
dtype = torch.half
|
||||
# create data
|
||||
x_shape = (SEQ_LEN, HEAD_NUM, HEAD_DIM)
|
||||
x = -2.3 + 0.5 * torch.randn(x_shape, dtype=dtype, device='cuda')
|
||||
cos_shape = (SEQ_LEN, HEAD_DIM // 2)
|
||||
cos = -1.2 + 0.5 * torch.randn(cos_shape, dtype=dtype, device='cuda')
|
||||
sin = -2.0 + 0.5 * torch.randn(cos_shape, dtype=dtype, device='cuda')
|
||||
# forward pass
|
||||
y_torch = torch_rotary_emb(x, cos, sin)
|
||||
rotary_embedding_fwd(x, cos, sin)
|
||||
y_triton = x
|
||||
# compare
|
||||
assert torch.allclose(y_torch, y_triton, atol=1e-2, rtol=0)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_rotary_emb()
|
||||
|
|
@ -4,12 +4,11 @@ import torch
|
|||
from torch import nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from colossalai.kernel.triton.ops import self_attention_compute_using_triton
|
||||
from colossalai.kernel.triton.qkv_matmul_kernel import qkv_gemm_4d_kernel
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
from colossalai.kernel.triton.self_attention_nofusion import self_attention_compute_using_triton
|
||||
from colossalai.kernel.triton.qkv_matmul_kernel import qkv_gemm_4d_kernel
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
|
|
@ -17,7 +16,7 @@ except ImportError:
|
|||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT, reason="triton requires cuda version to be higher than 11.4")
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON, reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_qkv_matmul():
|
||||
qkv = torch.randn((4, 24, 64*3), device="cuda", dtype=torch.float16)
|
||||
scale = 1.2
|
||||
|
|
@ -106,7 +105,7 @@ def self_attention_compute_using_torch(qkv,
|
|||
|
||||
return res.view(batches, -1, d_model), score_output, softmax_output
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT, reason="triton requires cuda version to be higher than 11.4")
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON, reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_self_atttention_test():
|
||||
|
||||
qkv = torch.randn((4, 24, 64*3), device="cuda", dtype=torch.float16)
|
||||
|
|
@ -3,11 +3,19 @@ from packaging import version
|
|||
import torch
|
||||
from torch import nn
|
||||
|
||||
from colossalai.kernel.triton.ops import softmax
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
from colossalai.kernel.triton.softmax import softmax
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT, reason="triton requires cuda version to be higher than 11.4")
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON, reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_softmax_op():
|
||||
data_samples = [
|
||||
torch.randn((3, 4, 5, 32), device = "cuda", dtype = torch.float32),
|
||||
|
|
@ -0,0 +1,72 @@
|
|||
import math
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton.token_attention_kernel import token_attn_fwd_1
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
def torch_attn(xq, xk, bs, seqlen, num_head, head_dim):
|
||||
xq = xq.view(bs, 1, num_head, head_dim)
|
||||
xk = xk.view(bs, seqlen, num_head, head_dim)
|
||||
keys = xk
|
||||
xq = xq.transpose(1, 2)
|
||||
keys = keys.transpose(1, 2)
|
||||
scores = (torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(head_dim)).squeeze().transpose(0, 1).reshape(
|
||||
num_head, -1)
|
||||
return scores
|
||||
|
||||
|
||||
def torch_attn_1(xq, xk, seqlen, num_head, head_dim):
|
||||
xq = xq.view(1, num_head, head_dim)
|
||||
xk = xk.view(seqlen, num_head, head_dim)
|
||||
logics = torch.sum(xq * xk, dim=-1, keepdim=False)
|
||||
|
||||
logics = logics.transpose(0, 1) / math.sqrt(head_dim)
|
||||
return logics
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_attn_1():
|
||||
import time
|
||||
|
||||
batch_size, seq_len, head_num, head_dim = 17, 1025, 12, 128
|
||||
|
||||
dtype = torch.float16
|
||||
|
||||
q = torch.empty((batch_size, head_num, head_dim), dtype=dtype, device="cuda").normal_(mean=0.1, std=0.2)
|
||||
k = torch.empty((batch_size * seq_len, head_num, head_dim), dtype=dtype, device="cuda").normal_(mean=0.1, std=0.2)
|
||||
attn_out = torch.empty((head_num, batch_size * seq_len), dtype=dtype, device="cuda")
|
||||
|
||||
b_loc = torch.zeros((batch_size, seq_len), dtype=torch.int32, device="cuda")
|
||||
kv_cache_start_loc = torch.zeros((batch_size,), dtype=torch.int32, device="cuda")
|
||||
kv_cache_seq_len = torch.zeros((batch_size,), dtype=torch.int32, device="cuda")
|
||||
|
||||
for i in range(batch_size):
|
||||
kv_cache_start_loc[i] = i * seq_len
|
||||
kv_cache_seq_len[i] = seq_len
|
||||
b_loc[i] = i * seq_len + torch.arange(0, seq_len, dtype=torch.int32, device="cuda")
|
||||
|
||||
token_attn_fwd_1(q, k, attn_out, b_loc, kv_cache_start_loc, kv_cache_seq_len, seq_len)
|
||||
|
||||
torch_out = torch_attn(q, k, batch_size, seq_len, head_num, head_dim).squeeze()
|
||||
o = attn_out.squeeze()
|
||||
print("max ", torch.max(torch.abs(torch_out - o)))
|
||||
print("mean ", torch.mean(torch.abs(torch_out - o)))
|
||||
assert torch.allclose(torch_out, o, atol=1e-2, rtol=0)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_attn_1()
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
import math
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton.token_attention_kernel import token_attn_fwd_2
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
def torch_attn(V, P, bs, seqlen, num_head, head_dim):
|
||||
V = V.view(bs, seqlen, num_head, head_dim).transpose(1, 2)
|
||||
P = P.reshape(num_head, bs, 1, seqlen).transpose(0, 1)
|
||||
attn_out = torch.matmul(P, V)
|
||||
|
||||
return attn_out
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_token_attn_2():
|
||||
import time
|
||||
|
||||
batch_size, seq_len, head_num, head_dim = 17, 1025, 12, 128
|
||||
dtype = torch.float16
|
||||
|
||||
V = torch.empty((batch_size * seq_len, head_num, head_dim), dtype=dtype, device="cuda").normal_(mean=0.1, std=10)
|
||||
Prob = torch.empty(
|
||||
(head_num, batch_size * seq_len), dtype=dtype,
|
||||
device="cuda").normal_(mean=0.4, std=0.2).reshape(head_num, batch_size,
|
||||
seq_len).softmax(-1).reshape(head_num, batch_size * seq_len)
|
||||
attn_out = torch.empty((batch_size, head_num, head_dim), dtype=dtype, device="cuda")
|
||||
|
||||
kv_cache_start_loc = torch.zeros((batch_size,), dtype=torch.int32, device="cuda")
|
||||
kv_cache_seq_len = torch.zeros((batch_size,), dtype=torch.int32, device="cuda")
|
||||
kv_cache_loc = torch.zeros((batch_size, seq_len), dtype=torch.int32, device="cuda")
|
||||
for i in range(batch_size):
|
||||
kv_cache_start_loc[i] = i * seq_len
|
||||
kv_cache_seq_len[i] = seq_len
|
||||
kv_cache_loc[i] = i * seq_len + torch.arange(0, seq_len, dtype=torch.int32, device="cuda")
|
||||
|
||||
token_attn_fwd_2(Prob, V, attn_out, kv_cache_loc, kv_cache_start_loc, kv_cache_seq_len, seq_len)
|
||||
|
||||
torch_out = torch_attn(V, Prob, batch_size, seq_len, head_num, head_dim).squeeze()
|
||||
o = attn_out
|
||||
print("max ", torch.max(torch.abs(torch_out - o)))
|
||||
print("mean ", torch.mean(torch.abs(torch_out - o)))
|
||||
assert torch.allclose(torch_out, o, atol=1e-2, rtol=0)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_token_attn_2()
|
||||
|
|
@ -0,0 +1,67 @@
|
|||
import time
|
||||
|
||||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton.token_attention_kernel import token_attention_fwd
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
def torch_att(xq, xk, xv, bs, seqlen, num_head, head_dim):
|
||||
xq = xq.view(bs, 1, num_head, head_dim)
|
||||
xk = xk.view(bs, seqlen, num_head, head_dim)
|
||||
xv = xv.view(bs, seqlen, num_head, head_dim)
|
||||
|
||||
logics = torch.sum(xq * xk, dim=3, keepdim=False) * 1 / (head_dim**0.5)
|
||||
prob = torch.softmax(logics, dim=1)
|
||||
prob = prob.view(bs, seqlen, num_head, 1)
|
||||
|
||||
return torch.sum(prob * xv, dim=1, keepdim=False)
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
def test():
|
||||
|
||||
Z, head_num, seq_len, head_dim = 22, 112 // 8, 2048, 128
|
||||
dtype = torch.float16
|
||||
q = torch.empty((Z, head_num, head_dim), dtype=dtype, device="cuda").normal_(mean=0.1, std=0.2)
|
||||
k = torch.empty((Z * seq_len, head_num, head_dim), dtype=dtype, device="cuda").normal_(mean=0.4, std=0.2)
|
||||
v = torch.empty((Z * seq_len, head_num, head_dim), dtype=dtype, device="cuda").normal_(mean=0.3, std=0.2)
|
||||
o = torch.empty((Z, head_num, head_dim), dtype=dtype, device="cuda").normal_(mean=0.3, std=0.2)
|
||||
alibi = torch.zeros((head_num,), dtype=torch.float32, device="cuda")
|
||||
|
||||
max_kv_cache_len = seq_len
|
||||
kv_cache_start_loc = torch.zeros((Z,), dtype=torch.int32, device="cuda")
|
||||
kv_cache_loc = torch.zeros((Z, seq_len), dtype=torch.int32, device="cuda")
|
||||
kv_cache_seq_len = torch.ones((Z,), dtype=torch.int32, device="cuda")
|
||||
|
||||
kv_cache_seq_len[:] = seq_len
|
||||
kv_cache_start_loc[0] = 0
|
||||
kv_cache_start_loc[1] = seq_len
|
||||
kv_cache_start_loc[2] = 2 * seq_len
|
||||
kv_cache_start_loc[3] = 3 * seq_len
|
||||
|
||||
for i in range(Z):
|
||||
kv_cache_loc[i, :] = torch.arange(i * seq_len, (i + 1) * seq_len, dtype=torch.int32, device="cuda")
|
||||
|
||||
token_attention_fwd(q, k, v, o, kv_cache_loc, kv_cache_start_loc, kv_cache_seq_len, max_kv_cache_len, alibi=alibi)
|
||||
torch_out = torch_att(q, k, v, Z, seq_len, head_num, head_dim)
|
||||
|
||||
print("max ", torch.max(torch.abs(torch_out - o)))
|
||||
print("mean ", torch.mean(torch.abs(torch_out - o)))
|
||||
assert torch.allclose(torch_out, o, atol=1e-2, rtol=0)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test()
|
||||
|
|
@ -0,0 +1,48 @@
|
|||
import pytest
|
||||
import torch
|
||||
from packaging import version
|
||||
|
||||
try:
|
||||
import triton
|
||||
import triton.language as tl
|
||||
|
||||
from colossalai.kernel.triton.token_attention_kernel import token_attn_softmax_fwd
|
||||
HAS_TRITON = True
|
||||
except ImportError:
|
||||
HAS_TRITON = False
|
||||
print("please install triton from https://github.com/openai/triton")
|
||||
|
||||
TRITON_CUDA_SUPPORT = version.parse(torch.version.cuda) > version.parse('11.4')
|
||||
|
||||
|
||||
@pytest.mark.skipif(not TRITON_CUDA_SUPPORT or not HAS_TRITON,
|
||||
reason="triton requires cuda version to be higher than 11.4")
|
||||
def test_softmax():
|
||||
|
||||
import torch
|
||||
|
||||
batch_size, seq_len, head_num, head_dim = 4, 1025, 12, 128
|
||||
|
||||
dtype = torch.float16
|
||||
|
||||
Logics = torch.empty((head_num, batch_size * seq_len), dtype=dtype, device="cuda").normal_(mean=0.1, std=10)
|
||||
ProbOut = torch.empty((head_num, batch_size * seq_len), dtype=dtype, device="cuda").normal_(mean=0.4, std=0.2)
|
||||
|
||||
kv_cache_start_loc = torch.zeros((batch_size,), dtype=torch.int32, device="cuda")
|
||||
kv_cache_seq_len = torch.zeros((batch_size,), dtype=torch.int32, device="cuda")
|
||||
|
||||
for i in range(batch_size):
|
||||
kv_cache_start_loc[i] = i * seq_len
|
||||
kv_cache_seq_len[i] = seq_len
|
||||
|
||||
token_attn_softmax_fwd(Logics, kv_cache_start_loc, kv_cache_seq_len, ProbOut, seq_len)
|
||||
|
||||
torch_out = Logics.reshape(head_num * batch_size, -1).softmax(-1).reshape(head_num, batch_size * seq_len)
|
||||
o = ProbOut
|
||||
print("max ", torch.max(torch.abs(torch_out - o)))
|
||||
print("mean ", torch.mean(torch.abs(torch_out - o)))
|
||||
assert torch.allclose(torch_out, o, atol=1e-2, rtol=0)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_softmax()
|
||||
Loading…
Reference in New Issue