mirror of https://github.com/hpcaitech/ColossalAI
[Feature] qlora support (#5586)
* [feature] qlora support * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * qlora follow commit * migrate qutization folder to colossalai/ * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * minor fixes --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>pull/5670/head
parent
8954a0c2e2
commit
91fa553775
15
LICENSE
15
LICENSE
|
|
@ -552,3 +552,18 @@ Copyright 2021- HPC-AI Technology Inc. All rights reserved.
|
||||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||||
THE SOFTWARE.
|
THE SOFTWARE.
|
||||||
|
---------------- LICENSE FOR Hugging Face accelerate ----------------
|
||||||
|
|
||||||
|
Copyright 2021 The HuggingFace Team
|
||||||
|
|
||||||
|
Licensed under the Apache License, Version 2.0 (the "License");
|
||||||
|
you may not use this file except in compliance with the License.
|
||||||
|
You may obtain a copy of the License at
|
||||||
|
|
||||||
|
http://www.apache.org/licenses/LICENSE-2.0
|
||||||
|
|
||||||
|
Unless required by applicable law or agreed to in writing, software
|
||||||
|
distributed under the License is distributed on an "AS IS" BASIS,
|
||||||
|
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||||
|
See the License for the specific language governing permissions and
|
||||||
|
limitations under the License.
|
||||||
|
|
|
||||||
|
|
@ -80,15 +80,19 @@ class DataCollatorForSupervisedDataset(object):
|
||||||
|
|
||||||
# `List[torch.Tensor]`
|
# `List[torch.Tensor]`
|
||||||
batch_input_ids = [
|
batch_input_ids = [
|
||||||
torch.LongTensor(instance["input_ids"][: self.max_length])
|
(
|
||||||
if len(instance["input_ids"]) > self.max_length
|
torch.LongTensor(instance["input_ids"][: self.max_length])
|
||||||
else torch.LongTensor(instance["input_ids"])
|
if len(instance["input_ids"]) > self.max_length
|
||||||
|
else torch.LongTensor(instance["input_ids"])
|
||||||
|
)
|
||||||
for instance in instances
|
for instance in instances
|
||||||
]
|
]
|
||||||
batch_labels = [
|
batch_labels = [
|
||||||
torch.LongTensor(instance["labels"][: self.max_length])
|
(
|
||||||
if len(instance["labels"]) > self.max_length
|
torch.LongTensor(instance["labels"][: self.max_length])
|
||||||
else torch.LongTensor(instance["labels"])
|
if len(instance["labels"]) > self.max_length
|
||||||
|
else torch.LongTensor(instance["labels"])
|
||||||
|
)
|
||||||
for instance in instances
|
for instance in instances
|
||||||
]
|
]
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -253,9 +253,11 @@ def main() -> None:
|
||||||
coordinator.print_on_master(f"Model params: {format_numel_str(model_numel)}")
|
coordinator.print_on_master(f"Model params: {format_numel_str(model_numel)}")
|
||||||
|
|
||||||
optimizer = HybridAdam(
|
optimizer = HybridAdam(
|
||||||
model_params=filter(lambda p: p.requires_grad, model.parameters())
|
model_params=(
|
||||||
if args.freeze_non_embeds_params
|
filter(lambda p: p.requires_grad, model.parameters())
|
||||||
else model.parameters(),
|
if args.freeze_non_embeds_params
|
||||||
|
else model.parameters()
|
||||||
|
),
|
||||||
lr=args.lr,
|
lr=args.lr,
|
||||||
betas=(0.9, 0.95),
|
betas=(0.9, 0.95),
|
||||||
weight_decay=args.weight_decay,
|
weight_decay=args.weight_decay,
|
||||||
|
|
|
||||||
|
|
@ -19,6 +19,7 @@ except ImportError:
|
||||||
import colossalai.interface.pretrained as pretrained_utils
|
import colossalai.interface.pretrained as pretrained_utils
|
||||||
from colossalai.checkpoint_io import GeneralCheckpointIO
|
from colossalai.checkpoint_io import GeneralCheckpointIO
|
||||||
from colossalai.interface import ModelWrapper, OptimizerWrapper
|
from colossalai.interface import ModelWrapper, OptimizerWrapper
|
||||||
|
from colossalai.quantization import BnbQuantizationConfig
|
||||||
|
|
||||||
from .accelerator import Accelerator
|
from .accelerator import Accelerator
|
||||||
from .mixed_precision import MixedPrecision, mixed_precision_factory
|
from .mixed_precision import MixedPrecision, mixed_precision_factory
|
||||||
|
|
@ -230,7 +231,12 @@ class Booster:
|
||||||
return self.plugin.no_sync(model, optimizer)
|
return self.plugin.no_sync(model, optimizer)
|
||||||
|
|
||||||
def enable_lora(
|
def enable_lora(
|
||||||
self, model: nn.Module, pretrained_dir: Optional[str] = None, lora_config: "peft.LoraConfig" = None
|
self,
|
||||||
|
model: nn.Module,
|
||||||
|
pretrained_dir: Optional[str] = None,
|
||||||
|
lora_config: "peft.LoraConfig" = None,
|
||||||
|
bnb_quantization_config: Optional[BnbQuantizationConfig] = None,
|
||||||
|
quantize=False,
|
||||||
) -> nn.Module:
|
) -> nn.Module:
|
||||||
"""
|
"""
|
||||||
Wrap the passed in model with LoRA modules for training. If pretrained directory is provided, lora configs and weights are loaded from that directory.
|
Wrap the passed in model with LoRA modules for training. If pretrained directory is provided, lora configs and weights are loaded from that directory.
|
||||||
|
|
@ -259,7 +265,20 @@ class Booster:
|
||||||
assert (
|
assert (
|
||||||
pretrained_dir is not None
|
pretrained_dir is not None
|
||||||
), "Please provide pretrained directory path if not passing in lora configuration."
|
), "Please provide pretrained directory path if not passing in lora configuration."
|
||||||
return self.plugin.enable_lora(model, pretrained_dir, lora_config)
|
if quantize is True:
|
||||||
|
if bnb_quantization_config is not None:
|
||||||
|
warnings.warn(
|
||||||
|
"User defined BnbQuantizationConfig is not fully tested in ColossalAI. Use it at your own risk."
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
bnb_quantization_config = BnbQuantizationConfig(
|
||||||
|
load_in_4bit=True,
|
||||||
|
bnb_4bit_compute_dtype=torch.bfloat16,
|
||||||
|
bnb_4bit_use_double_quant=True,
|
||||||
|
bnb_4bit_quant_type="nf4",
|
||||||
|
)
|
||||||
|
|
||||||
|
return self.plugin.enable_lora(model, pretrained_dir, lora_config, bnb_quantization_config)
|
||||||
|
|
||||||
def load_model(self, model: Union[nn.Module, ModelWrapper], checkpoint: str, strict: bool = True) -> None:
|
def load_model(self, model: Union[nn.Module, ModelWrapper], checkpoint: str, strict: bool = True) -> None:
|
||||||
"""Load model from checkpoint.
|
"""Load model from checkpoint.
|
||||||
|
|
|
||||||
|
|
@ -28,6 +28,7 @@ from colossalai.checkpoint_io.utils import (
|
||||||
sharded_optimizer_loading_epilogue,
|
sharded_optimizer_loading_epilogue,
|
||||||
)
|
)
|
||||||
from colossalai.interface import AMPModelMixin, ModelWrapper, OptimizerWrapper
|
from colossalai.interface import AMPModelMixin, ModelWrapper, OptimizerWrapper
|
||||||
|
from colossalai.quantization import BnbQuantizationConfig, quantize_model
|
||||||
from colossalai.zero import LowLevelZeroOptimizer
|
from colossalai.zero import LowLevelZeroOptimizer
|
||||||
|
|
||||||
from .dp_plugin_base import DPPluginBase
|
from .dp_plugin_base import DPPluginBase
|
||||||
|
|
@ -338,7 +339,11 @@ class LowLevelZeroPlugin(DPPluginBase):
|
||||||
return True
|
return True
|
||||||
|
|
||||||
def enable_lora(
|
def enable_lora(
|
||||||
self, model: nn.Module, pretrained_dir: Optional[str] = None, lora_config: Optional[Dict] = None
|
self,
|
||||||
|
model: nn.Module,
|
||||||
|
pretrained_dir: Optional[str] = None,
|
||||||
|
lora_config: Optional[Dict] = None,
|
||||||
|
bnb_quantization_config: Optional[BnbQuantizationConfig] = None,
|
||||||
) -> nn.Module:
|
) -> nn.Module:
|
||||||
from peft import PeftModel, get_peft_model
|
from peft import PeftModel, get_peft_model
|
||||||
|
|
||||||
|
|
@ -346,6 +351,9 @@ class LowLevelZeroPlugin(DPPluginBase):
|
||||||
self.lora_enabled = True
|
self.lora_enabled = True
|
||||||
warnings.warn("You have enabled LoRa training. Please check the hyperparameters such as lr")
|
warnings.warn("You have enabled LoRa training. Please check the hyperparameters such as lr")
|
||||||
|
|
||||||
|
if bnb_quantization_config is not None:
|
||||||
|
model = quantize_model(model, bnb_quantization_config)
|
||||||
|
|
||||||
if pretrained_dir is None:
|
if pretrained_dir is None:
|
||||||
peft_model = get_peft_model(model, lora_config)
|
peft_model = get_peft_model(model, lora_config)
|
||||||
else:
|
else:
|
||||||
|
|
|
||||||
|
|
@ -9,6 +9,7 @@ from torch.utils.data import DataLoader
|
||||||
from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO
|
from colossalai.checkpoint_io import CheckpointIO, GeneralCheckpointIO
|
||||||
from colossalai.cluster import DistCoordinator
|
from colossalai.cluster import DistCoordinator
|
||||||
from colossalai.interface import ModelWrapper, OptimizerWrapper
|
from colossalai.interface import ModelWrapper, OptimizerWrapper
|
||||||
|
from colossalai.quantization import BnbQuantizationConfig, quantize_model
|
||||||
|
|
||||||
from .dp_plugin_base import DPPluginBase
|
from .dp_plugin_base import DPPluginBase
|
||||||
|
|
||||||
|
|
@ -237,10 +238,17 @@ class TorchDDPPlugin(DPPluginBase):
|
||||||
return model.module.no_sync()
|
return model.module.no_sync()
|
||||||
|
|
||||||
def enable_lora(
|
def enable_lora(
|
||||||
self, model: nn.Module, pretrained_dir: Optional[str] = None, lora_config: Optional[Dict] = None
|
self,
|
||||||
|
model: nn.Module,
|
||||||
|
pretrained_dir: Optional[str] = None,
|
||||||
|
lora_config: Optional[Dict] = None,
|
||||||
|
bnb_quantization_config: Optional[BnbQuantizationConfig] = None,
|
||||||
) -> nn.Module:
|
) -> nn.Module:
|
||||||
from peft import PeftModel, get_peft_model
|
from peft import PeftModel, get_peft_model
|
||||||
|
|
||||||
|
if bnb_quantization_config is not None:
|
||||||
|
model = quantize_model(model, bnb_quantization_config)
|
||||||
|
|
||||||
assert not isinstance(model, TorchDDPModel), "Lora should be enabled before boosting the model."
|
assert not isinstance(model, TorchDDPModel), "Lora should be enabled before boosting the model."
|
||||||
if pretrained_dir is None:
|
if pretrained_dir is None:
|
||||||
return get_peft_model(model, lora_config)
|
return get_peft_model(model, lora_config)
|
||||||
|
|
|
||||||
|
|
@ -165,7 +165,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
|
||||||
##### Llama
|
##### Llama
|
||||||
|
|
||||||
| batch_size | 8 | 16 | 32 |
|
| batch_size | 8 | 16 | 32 |
|
||||||
| :---------------------: | :----: | :----: | :----: |
|
|:-----------------------:|:------:|:------:|:------:|
|
||||||
| hugging-face torch fp16 | 199.12 | 246.56 | 278.4 |
|
| hugging-face torch fp16 | 199.12 | 246.56 | 278.4 |
|
||||||
| colossal-inference | 326.4 | 582.72 | 816.64 |
|
| colossal-inference | 326.4 | 582.72 | 816.64 |
|
||||||
|
|
||||||
|
|
@ -174,7 +174,7 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
|
||||||
#### Bloom
|
#### Bloom
|
||||||
|
|
||||||
| batch_size | 8 | 16 | 32 |
|
| batch_size | 8 | 16 | 32 |
|
||||||
| :---------------------: | :----: | :----: | :----: |
|
|:-----------------------:|:------:|:------:|:------:|
|
||||||
| hugging-face torch fp16 | 189.68 | 226.66 | 249.61 |
|
| hugging-face torch fp16 | 189.68 | 226.66 | 249.61 |
|
||||||
| colossal-inference | 323.28 | 538.52 | 611.64 |
|
| colossal-inference | 323.28 | 538.52 | 611.64 |
|
||||||
|
|
||||||
|
|
@ -187,40 +187,40 @@ We conducted multiple benchmark tests to evaluate the performance. We compared t
|
||||||
|
|
||||||
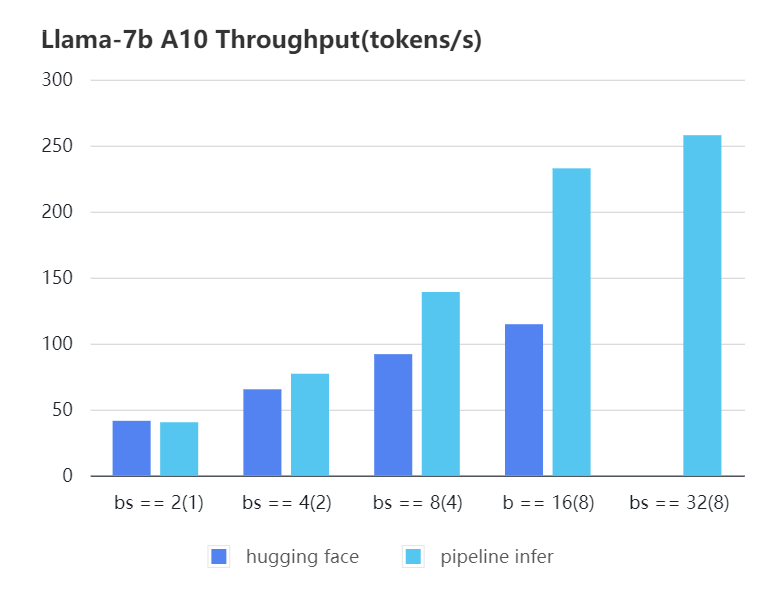
#### A10 7b, fp16
|
#### A10 7b, fp16
|
||||||
|
|
||||||
| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
|
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16) |
|
||||||
| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
|
|:----------------------------:|:-----:|:-----:|:------:|:------:|:------:|:------:|
|
||||||
| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
|
| Pipeline Inference | 40.35 | 77.10 | 139.03 | 232.70 | 257.81 | OOM |
|
||||||
| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
|
| Hugging Face | 41.43 | 65.30 | 91.93 | 114.62 | OOM | OOM |
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
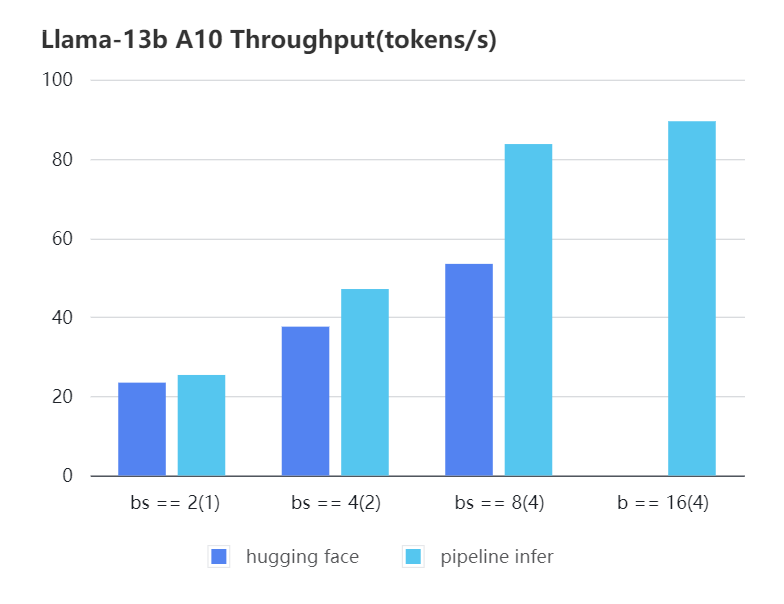
#### A10 13b, fp16
|
#### A10 13b, fp16
|
||||||
|
|
||||||
| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
|
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(4) |
|
||||||
| :---: | :---: | :---: | :---: | :---: |
|
|:----------------------------:|:-----:|:-----:|:-----:|:-----:|
|
||||||
| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
|
| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
|
||||||
| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
|
| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
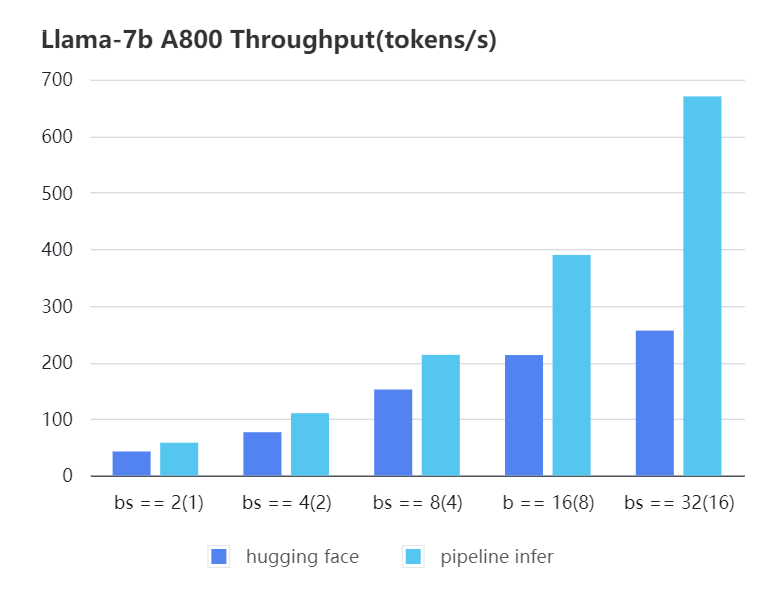
#### A800 7b, fp16
|
#### A800 7b, fp16
|
||||||
|
|
||||||
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
|
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
|
||||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
|:----------------------------:|:-----:|:------:|:------:|:------:|:------:|
|
||||||
| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
|
| Pipeline Inference | 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
|
||||||
| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
|
| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
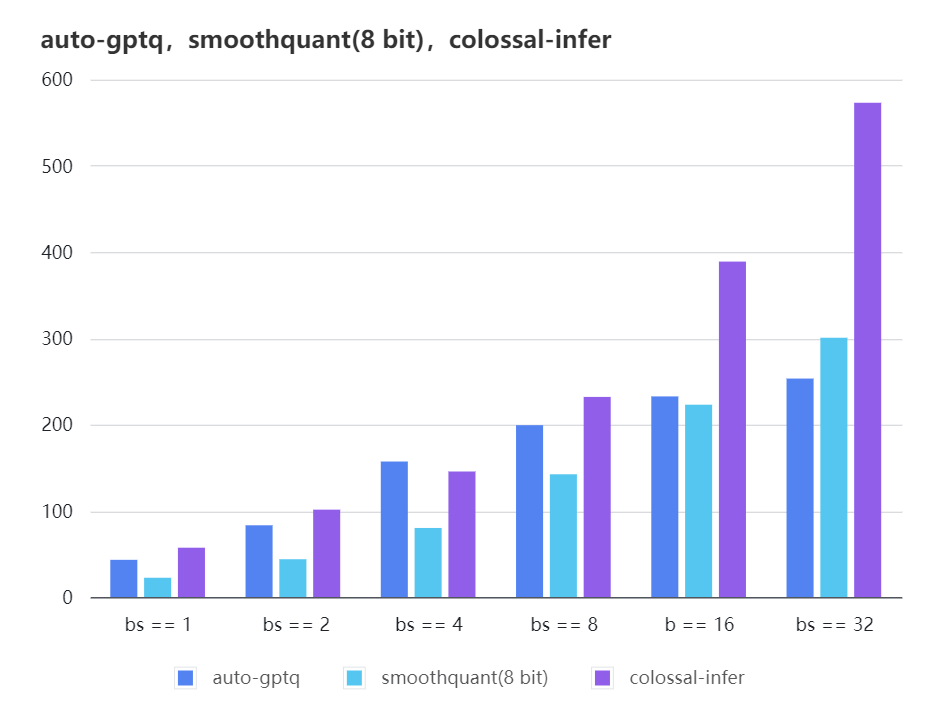
### Quantization LLama
|
### Quantization LLama
|
||||||
|
|
||||||
| batch_size | 8 | 16 | 32 |
|
| batch_size | 8 | 16 | 32 |
|
||||||
| :---------------------: | :----: | :----: | :----: |
|
|:-------------:|:------:|:------:|:------:|
|
||||||
| auto-gptq | 199.20 | 232.56 | 253.26 |
|
| auto-gptq | 199.20 | 232.56 | 253.26 |
|
||||||
| smooth-quant | 142.28 | 222.96 | 300.59 |
|
| smooth-quant | 142.28 | 222.96 | 300.59 |
|
||||||
| colossal-gptq | 231.98 | 388.87 | 573.03 |
|
| colossal-gptq | 231.98 | 388.87 | 573.03 |
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,7 @@
|
||||||
|
from .bnb import quantize_model
|
||||||
|
from .bnb_config import BnbQuantizationConfig
|
||||||
|
|
||||||
|
__all__ = [
|
||||||
|
"BnbQuantizationConfig",
|
||||||
|
"quantize_model",
|
||||||
|
]
|
||||||
|
|
@ -0,0 +1,321 @@
|
||||||
|
# adapted from Hugging Face accelerate/utils/bnb.py accelerate/utils/modeling.py
|
||||||
|
|
||||||
|
import logging
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.nn as nn
|
||||||
|
|
||||||
|
from .bnb_config import BnbQuantizationConfig
|
||||||
|
|
||||||
|
try:
|
||||||
|
import bitsandbytes as bnb
|
||||||
|
|
||||||
|
IS_4BIT_BNB_AVAILABLE = bnb.__version__ >= "0.39.0"
|
||||||
|
IS_8BIT_BNB_AVAILABLE = bnb.__version__ >= "0.37.2"
|
||||||
|
except ImportError:
|
||||||
|
pass
|
||||||
|
|
||||||
|
|
||||||
|
logger = logging.getLogger(__name__)
|
||||||
|
|
||||||
|
|
||||||
|
def quantize_model(
|
||||||
|
model: torch.nn.Module,
|
||||||
|
bnb_quantization_config: BnbQuantizationConfig,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
This function will quantize the input loaded model with the associated config passed in `bnb_quantization_config`.
|
||||||
|
We will quantize the model and put the model on the GPU.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
model (`torch.nn.Module`):
|
||||||
|
Input model. The model already loaded
|
||||||
|
bnb_quantization_config (`BnbQuantizationConfig`):
|
||||||
|
The bitsandbytes quantization parameters
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
`torch.nn.Module`: The quantized model
|
||||||
|
"""
|
||||||
|
|
||||||
|
load_in_4bit = bnb_quantization_config.load_in_4bit
|
||||||
|
load_in_8bit = bnb_quantization_config.load_in_8bit
|
||||||
|
|
||||||
|
if load_in_8bit and not IS_8BIT_BNB_AVAILABLE:
|
||||||
|
raise ImportError(
|
||||||
|
"You have a version of `bitsandbytes` that is not compatible with 8bit quantization,"
|
||||||
|
" make sure you have the latest version of `bitsandbytes` installed."
|
||||||
|
)
|
||||||
|
if load_in_4bit and not IS_4BIT_BNB_AVAILABLE:
|
||||||
|
raise ValueError(
|
||||||
|
"You have a version of `bitsandbytes` that is not compatible with 4bit quantization,"
|
||||||
|
"make sure you have the latest version of `bitsandbytes` installed."
|
||||||
|
)
|
||||||
|
|
||||||
|
# We keep some modules such as the lm_head in their original dtype for numerical stability reasons
|
||||||
|
if bnb_quantization_config.skip_modules is None:
|
||||||
|
bnb_quantization_config.skip_modules = get_keys_to_not_convert(model)
|
||||||
|
|
||||||
|
modules_to_not_convert = bnb_quantization_config.skip_modules
|
||||||
|
|
||||||
|
# We add the modules we want to keep in full precision
|
||||||
|
if bnb_quantization_config.keep_in_fp32_modules is None:
|
||||||
|
bnb_quantization_config.keep_in_fp32_modules = []
|
||||||
|
keep_in_fp32_modules = bnb_quantization_config.keep_in_fp32_modules
|
||||||
|
|
||||||
|
# compatibility with peft
|
||||||
|
model.is_loaded_in_4bit = load_in_4bit
|
||||||
|
model.is_loaded_in_8bit = load_in_8bit
|
||||||
|
|
||||||
|
# assert model_device is cuda
|
||||||
|
model_device = next(model.parameters()).device
|
||||||
|
|
||||||
|
model = replace_with_bnb_layers(model, bnb_quantization_config, modules_to_not_convert=modules_to_not_convert)
|
||||||
|
|
||||||
|
# convert param to the right dtype
|
||||||
|
dtype = bnb_quantization_config.torch_dtype
|
||||||
|
for name, param in model.state_dict().items():
|
||||||
|
if any(module_to_keep_in_fp32 in name for module_to_keep_in_fp32 in keep_in_fp32_modules):
|
||||||
|
param.to(torch.float32)
|
||||||
|
if param.dtype != torch.float32:
|
||||||
|
name = name.replace(".weight", "").replace(".bias", "")
|
||||||
|
param = getattr(model, name, None)
|
||||||
|
if param is not None:
|
||||||
|
param.to(torch.float32)
|
||||||
|
elif torch.is_floating_point(param):
|
||||||
|
param.to(dtype)
|
||||||
|
if model_device.type == "cuda":
|
||||||
|
# move everything to cpu in the first place because we can't do quantization if the weights are already on cuda
|
||||||
|
model.cuda(torch.cuda.current_device())
|
||||||
|
torch.cuda.empty_cache()
|
||||||
|
elif torch.cuda.is_available():
|
||||||
|
model.to(torch.cuda.current_device())
|
||||||
|
logger.info(
|
||||||
|
f"The model device type is {model_device.type}. However, cuda is needed for quantization."
|
||||||
|
"We move the model to cuda."
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise RuntimeError("No GPU found. A GPU is needed for quantization.")
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def replace_with_bnb_layers(model, bnb_quantization_config, modules_to_not_convert=None, current_key_name=None):
|
||||||
|
"""
|
||||||
|
A helper function to replace all `torch.nn.Linear` modules by `bnb.nn.Linear8bit` modules or by `bnb.nn.Linear4bit`
|
||||||
|
modules from the `bitsandbytes`library. The function will be run recursively and replace `torch.nn.Linear` modules.
|
||||||
|
|
||||||
|
Parameters:
|
||||||
|
model (`torch.nn.Module`):
|
||||||
|
Input model or `torch.nn.Module` as the function is run recursively.
|
||||||
|
modules_to_not_convert (`List[str]`):
|
||||||
|
Names of the modules to not quantize convert. In practice we keep the `lm_head` in full precision for
|
||||||
|
numerical stability reasons.
|
||||||
|
current_key_name (`List[str]`, *optional*):
|
||||||
|
An array to track the current key of the recursion. This is used to check whether the current key (part of
|
||||||
|
it) is not in the list of modules to not convert.
|
||||||
|
"""
|
||||||
|
|
||||||
|
if modules_to_not_convert is None:
|
||||||
|
modules_to_not_convert = []
|
||||||
|
|
||||||
|
model, has_been_replaced = _replace_with_bnb_layers(
|
||||||
|
model, bnb_quantization_config, modules_to_not_convert, current_key_name
|
||||||
|
)
|
||||||
|
if not has_been_replaced:
|
||||||
|
logger.warning(
|
||||||
|
"You are loading your model in 8bit or 4bit but no linear modules were found in your model."
|
||||||
|
" this can happen for some architectures such as gpt2 that uses Conv1D instead of Linear layers."
|
||||||
|
" Please double check your model architecture, or submit an issue on github if you think this is"
|
||||||
|
" a bug."
|
||||||
|
)
|
||||||
|
return model
|
||||||
|
|
||||||
|
|
||||||
|
def _replace_with_bnb_layers(
|
||||||
|
model,
|
||||||
|
bnb_quantization_config,
|
||||||
|
modules_to_not_convert=None,
|
||||||
|
current_key_name=None,
|
||||||
|
):
|
||||||
|
"""
|
||||||
|
Private method that wraps the recursion for module replacement.
|
||||||
|
|
||||||
|
Returns the converted model and a boolean that indicates if the conversion has been successfull or not.
|
||||||
|
"""
|
||||||
|
# bitsandbytes will initialize CUDA on import, so it needs to be imported lazily
|
||||||
|
|
||||||
|
has_been_replaced = False
|
||||||
|
for name, module in model.named_children():
|
||||||
|
if current_key_name is None:
|
||||||
|
current_key_name = []
|
||||||
|
current_key_name.append(name)
|
||||||
|
if isinstance(module, nn.Linear) and name not in modules_to_not_convert:
|
||||||
|
# Check if the current key is not in the `modules_to_not_convert`
|
||||||
|
current_key_name_str = ".".join(current_key_name)
|
||||||
|
proceed = True
|
||||||
|
for key in modules_to_not_convert:
|
||||||
|
if (
|
||||||
|
(key in current_key_name_str) and (key + "." in current_key_name_str)
|
||||||
|
) or key == current_key_name_str:
|
||||||
|
proceed = False
|
||||||
|
break
|
||||||
|
if proceed:
|
||||||
|
# Load bnb module with empty weight and replace ``nn.Linear` module
|
||||||
|
if bnb_quantization_config.load_in_8bit:
|
||||||
|
bnb_module = bnb.nn.Linear8bitLt(
|
||||||
|
module.in_features,
|
||||||
|
module.out_features,
|
||||||
|
module.bias is not None,
|
||||||
|
has_fp16_weights=False,
|
||||||
|
threshold=bnb_quantization_config.llm_int8_threshold,
|
||||||
|
)
|
||||||
|
elif bnb_quantization_config.load_in_4bit:
|
||||||
|
bnb_module = bnb.nn.Linear4bit(
|
||||||
|
module.in_features,
|
||||||
|
module.out_features,
|
||||||
|
module.bias is not None,
|
||||||
|
bnb_quantization_config.bnb_4bit_compute_dtype,
|
||||||
|
compress_statistics=bnb_quantization_config.bnb_4bit_use_double_quant,
|
||||||
|
quant_type=bnb_quantization_config.bnb_4bit_quant_type,
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
raise ValueError("load_in_8bit and load_in_4bit can't be both False")
|
||||||
|
bnb_module.weight.data = module.weight.data
|
||||||
|
bnb_module.weight.skip_zero_check = True
|
||||||
|
if module.bias is not None:
|
||||||
|
bnb_module.bias.data = module.bias.data
|
||||||
|
bnb_module.bias.skip_zero_check = True
|
||||||
|
bnb_module.requires_grad_(False)
|
||||||
|
setattr(model, name, bnb_module)
|
||||||
|
has_been_replaced = True
|
||||||
|
if len(list(module.children())) > 0:
|
||||||
|
_, _has_been_replaced = _replace_with_bnb_layers(
|
||||||
|
module, bnb_quantization_config, modules_to_not_convert, current_key_name
|
||||||
|
)
|
||||||
|
has_been_replaced = has_been_replaced | _has_been_replaced
|
||||||
|
# Remove the last key for recursion
|
||||||
|
current_key_name.pop(-1)
|
||||||
|
return model, has_been_replaced
|
||||||
|
|
||||||
|
|
||||||
|
def get_keys_to_not_convert(model):
|
||||||
|
r"""
|
||||||
|
An utility function to get the key of the module to keep in full precision if any For example for CausalLM modules
|
||||||
|
we may want to keep the lm_head in full precision for numerical stability reasons. For other architectures, we want
|
||||||
|
to keep the tied weights of the model. The function will return a list of the keys of the modules to not convert in
|
||||||
|
int8.
|
||||||
|
|
||||||
|
Parameters:
|
||||||
|
model (`torch.nn.Module`):
|
||||||
|
Input model
|
||||||
|
"""
|
||||||
|
# Create a copy of the model
|
||||||
|
# with init_empty_weights():
|
||||||
|
# tied_model = deepcopy(model) # this has 0 cost since it is done inside `init_empty_weights` context manager`
|
||||||
|
tied_model = model
|
||||||
|
|
||||||
|
tied_params = find_tied_parameters(tied_model)
|
||||||
|
# For compatibility with Accelerate < 0.18
|
||||||
|
if isinstance(tied_params, dict):
|
||||||
|
tied_keys = sum(list(tied_params.values()), []) + list(tied_params.keys())
|
||||||
|
else:
|
||||||
|
tied_keys = sum(tied_params, [])
|
||||||
|
has_tied_params = len(tied_keys) > 0
|
||||||
|
|
||||||
|
# Check if it is a base model
|
||||||
|
is_base_model = False
|
||||||
|
if hasattr(model, "base_model_prefix"):
|
||||||
|
is_base_model = not hasattr(model, model.base_model_prefix)
|
||||||
|
|
||||||
|
# Ignore this for base models (BertModel, GPT2Model, etc.)
|
||||||
|
if (not has_tied_params) and is_base_model:
|
||||||
|
return []
|
||||||
|
|
||||||
|
# otherwise they have an attached head
|
||||||
|
list_modules = list(model.named_children())
|
||||||
|
list_last_module = [list_modules[-1][0]]
|
||||||
|
|
||||||
|
# add last module together with tied weights
|
||||||
|
intersection = set(list_last_module) - set(tied_keys)
|
||||||
|
list_untouched = list(set(tied_keys)) + list(intersection)
|
||||||
|
|
||||||
|
# remove ".weight" from the keys
|
||||||
|
names_to_remove = [".weight", ".bias"]
|
||||||
|
filtered_module_names = []
|
||||||
|
for name in list_untouched:
|
||||||
|
for name_to_remove in names_to_remove:
|
||||||
|
if name_to_remove in name:
|
||||||
|
name = name.replace(name_to_remove, "")
|
||||||
|
filtered_module_names.append(name)
|
||||||
|
|
||||||
|
return filtered_module_names
|
||||||
|
|
||||||
|
|
||||||
|
def find_tied_parameters(model: nn.Module, **kwargs):
|
||||||
|
"""
|
||||||
|
Find the tied parameters in a given model.
|
||||||
|
|
||||||
|
<Tip warning={true}>
|
||||||
|
|
||||||
|
The signature accepts keyword arguments, but they are for the recursive part of this function and you should ignore
|
||||||
|
them.
|
||||||
|
|
||||||
|
</Tip>
|
||||||
|
|
||||||
|
Args:
|
||||||
|
model (`torch.nn.Module`): The model to inspect.
|
||||||
|
|
||||||
|
Returns:
|
||||||
|
List[List[str]]: A list of lists of parameter names being all tied together.
|
||||||
|
|
||||||
|
Example:
|
||||||
|
|
||||||
|
```py
|
||||||
|
>>> from collections import OrderedDict
|
||||||
|
>>> import torch.nn as nn
|
||||||
|
|
||||||
|
>>> model = nn.Sequential(OrderedDict([("linear1", nn.Linear(4, 4)), ("linear2", nn.Linear(4, 4))]))
|
||||||
|
>>> model.linear2.weight = model.linear1.weight
|
||||||
|
>>> find_tied_parameters(model)
|
||||||
|
[['linear1.weight', 'linear2.weight']]
|
||||||
|
```
|
||||||
|
"""
|
||||||
|
# Initialize result and named_parameters before recursing.
|
||||||
|
named_parameters = kwargs.get("named_parameters", None)
|
||||||
|
prefix = kwargs.get("prefix", "")
|
||||||
|
result = kwargs.get("result", {})
|
||||||
|
|
||||||
|
if named_parameters is None:
|
||||||
|
named_parameters = {n: p for n, p in model.named_parameters()}
|
||||||
|
else:
|
||||||
|
# A tied parameter will not be in the full `named_parameters` seen above but will be in the `named_parameters`
|
||||||
|
# of the submodule it belongs to. So while recursing we track the names that are not in the initial
|
||||||
|
# `named_parameters`.
|
||||||
|
for name, parameter in model.named_parameters():
|
||||||
|
full_name = name if prefix == "" else f"{prefix}.{name}"
|
||||||
|
if full_name not in named_parameters:
|
||||||
|
# When we find one, it has to be one of the existing parameters.
|
||||||
|
for new_name, new_param in named_parameters.items():
|
||||||
|
if new_param is parameter:
|
||||||
|
if new_name not in result:
|
||||||
|
result[new_name] = []
|
||||||
|
result[new_name].append(full_name)
|
||||||
|
|
||||||
|
# Once we have treated direct parameters, we move to the child modules.
|
||||||
|
for name, child in model.named_children():
|
||||||
|
child_name = name if prefix == "" else f"{prefix}.{name}"
|
||||||
|
find_tied_parameters(child, named_parameters=named_parameters, prefix=child_name, result=result)
|
||||||
|
|
||||||
|
return FindTiedParametersResult([sorted([weight] + list(set(tied))) for weight, tied in result.items()])
|
||||||
|
|
||||||
|
|
||||||
|
class FindTiedParametersResult(list):
|
||||||
|
"""
|
||||||
|
This is a subclass of a list to handle backward compatibility for Transformers. Do not rely on the fact this is not
|
||||||
|
a list or on the `values` method as in the future this will be removed.
|
||||||
|
"""
|
||||||
|
|
||||||
|
def __init__(self, *args, **kwargs):
|
||||||
|
super().__init__(*args, **kwargs)
|
||||||
|
|
||||||
|
def values(self):
|
||||||
|
return sum([x[1:] for x in self], [])
|
||||||
|
|
@ -0,0 +1,113 @@
|
||||||
|
# adapted from Hugging Face accelerate/utils/dataclasses.py
|
||||||
|
|
||||||
|
import warnings
|
||||||
|
from dataclasses import dataclass, field
|
||||||
|
from typing import List
|
||||||
|
|
||||||
|
import torch
|
||||||
|
|
||||||
|
|
||||||
|
@dataclass
|
||||||
|
class BnbQuantizationConfig:
|
||||||
|
"""
|
||||||
|
A plugin to enable BitsAndBytes 4bit and 8bit quantization
|
||||||
|
"""
|
||||||
|
|
||||||
|
load_in_8bit: bool = field(default=False, metadata={"help": "enable 8bit quantization."})
|
||||||
|
|
||||||
|
llm_int8_threshold: float = field(
|
||||||
|
default=6.0, metadata={"help": "value of the outliner threshold. only relevant when load_in_8bit=True"}
|
||||||
|
)
|
||||||
|
|
||||||
|
load_in_4bit: bool = field(default=False, metadata={"help": "enable 4bit quantization."})
|
||||||
|
|
||||||
|
bnb_4bit_quant_type: str = field(
|
||||||
|
default="fp4",
|
||||||
|
metadata={
|
||||||
|
"help": "set the quantization data type in the `bnb.nn.Linear4Bit` layers. Options are {'fp4','np4'}."
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
bnb_4bit_use_double_quant: bool = field(
|
||||||
|
default=False,
|
||||||
|
metadata={
|
||||||
|
"help": "enable nested quantization where the quantization constants from the first quantization are quantized again."
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
bnb_4bit_compute_dtype: bool = field(
|
||||||
|
default="fp16",
|
||||||
|
metadata={
|
||||||
|
"help": "This sets the computational type which might be different than the input time. For example, inputs might be "
|
||||||
|
"fp32, but computation can be set to bf16 for speedups. Options are {'fp32','fp16','bf16'}."
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
torch_dtype: torch.dtype = field(
|
||||||
|
default=None,
|
||||||
|
metadata={
|
||||||
|
"help": "this sets the dtype of the remaining non quantized layers. `bitsandbytes` library suggests to set the value"
|
||||||
|
"to `torch.float16` for 8 bit model and use the same dtype as the compute dtype for 4 bit model "
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
skip_modules: List[str] = field(
|
||||||
|
default=None,
|
||||||
|
metadata={
|
||||||
|
"help": "an explicit list of the modules that we don't quantize. The dtype of these modules will be `torch_dtype`."
|
||||||
|
},
|
||||||
|
)
|
||||||
|
|
||||||
|
keep_in_fp32_modules: List[str] = field(
|
||||||
|
default=None,
|
||||||
|
metadata={"help": "an explicit list of the modules that we don't quantize. We keep them in `torch.float32`."},
|
||||||
|
)
|
||||||
|
|
||||||
|
def __post_init__(self):
|
||||||
|
if isinstance(self.bnb_4bit_compute_dtype, str):
|
||||||
|
if self.bnb_4bit_compute_dtype == "fp32":
|
||||||
|
self.bnb_4bit_compute_dtype = torch.float32
|
||||||
|
elif self.bnb_4bit_compute_dtype == "fp16":
|
||||||
|
self.bnb_4bit_compute_dtype = torch.float16
|
||||||
|
elif self.bnb_4bit_compute_dtype == "bf16":
|
||||||
|
self.bnb_4bit_compute_dtype = torch.bfloat16
|
||||||
|
else:
|
||||||
|
raise ValueError(
|
||||||
|
f"bnb_4bit_compute_dtype must be in ['fp32','fp16','bf16'] but found {self.bnb_4bit_compute_dtype}"
|
||||||
|
)
|
||||||
|
elif not isinstance(self.bnb_4bit_compute_dtype, torch.dtype):
|
||||||
|
raise ValueError("bnb_4bit_compute_dtype must be a string or a torch.dtype")
|
||||||
|
|
||||||
|
if self.skip_modules is not None and not isinstance(self.skip_modules, list):
|
||||||
|
raise ValueError("skip_modules must be a list of strings")
|
||||||
|
|
||||||
|
if self.keep_in_fp32_modules is not None and not isinstance(self.keep_in_fp32_modules, list):
|
||||||
|
raise ValueError("keep_in_fp_32_modules must be a list of strings")
|
||||||
|
|
||||||
|
if self.load_in_4bit:
|
||||||
|
self.target_dtype = "int4"
|
||||||
|
|
||||||
|
if self.load_in_8bit:
|
||||||
|
self.target_dtype = torch.int8
|
||||||
|
|
||||||
|
if self.load_in_4bit and self.llm_int8_threshold != 6.0:
|
||||||
|
warnings.warn("llm_int8_threshold can only be used for model loaded in 8bit")
|
||||||
|
|
||||||
|
if isinstance(self.torch_dtype, str):
|
||||||
|
if self.torch_dtype == "fp32":
|
||||||
|
self.torch_dtype = torch.float32
|
||||||
|
elif self.torch_dtype == "fp16":
|
||||||
|
self.torch_dtype = torch.float16
|
||||||
|
elif self.torch_dtype == "bf16":
|
||||||
|
self.torch_dtype = torch.bfloat16
|
||||||
|
else:
|
||||||
|
raise ValueError(f"torch_dtype must be in ['fp32','fp16','bf16'] but found {self.torch_dtype}")
|
||||||
|
|
||||||
|
if self.load_in_8bit and self.torch_dtype is None:
|
||||||
|
self.torch_dtype = torch.float16
|
||||||
|
|
||||||
|
if self.load_in_4bit and self.torch_dtype is None:
|
||||||
|
self.torch_dtype = self.bnb_4bit_compute_dtype
|
||||||
|
|
||||||
|
if not isinstance(self.torch_dtype, torch.dtype):
|
||||||
|
raise ValueError("torch_dtype must be a torch.dtype")
|
||||||
|
|
@ -235,9 +235,10 @@ class LowLevelZeroOptimizer(OptimizerWrapper):
|
||||||
for param_group in self.optim.param_groups:
|
for param_group in self.optim.param_groups:
|
||||||
group_params = param_group["params"]
|
group_params = param_group["params"]
|
||||||
for param in group_params:
|
for param in group_params:
|
||||||
assert (
|
if not hasattr(param, "skip_zero_check") or param.skip_zero_check is False:
|
||||||
param.dtype == self._dtype
|
assert (
|
||||||
), f"Parameters are expected to have the same dtype `{self._dtype}`, but got `{param.dtype}`"
|
param.dtype == self._dtype
|
||||||
|
), f"Parameters are expected to have the same dtype `{self._dtype}`, but got `{param.dtype}`"
|
||||||
|
|
||||||
def _create_master_param_current_rank(self, param_list):
|
def _create_master_param_current_rank(self, param_list):
|
||||||
# split each param evenly by world size
|
# split each param evenly by world size
|
||||||
|
|
|
||||||
|
|
@ -18,3 +18,4 @@ google
|
||||||
protobuf
|
protobuf
|
||||||
transformers==4.36.2
|
transformers==4.36.2
|
||||||
peft>=0.7.1
|
peft>=0.7.1
|
||||||
|
bitsandbytes>=0.39.0
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,106 @@
|
||||||
|
import copy
|
||||||
|
import os
|
||||||
|
from itertools import product
|
||||||
|
|
||||||
|
import torch
|
||||||
|
from peft import LoraConfig
|
||||||
|
from torch import distributed as dist
|
||||||
|
from torch.optim import AdamW
|
||||||
|
|
||||||
|
import colossalai
|
||||||
|
from colossalai.booster import Booster
|
||||||
|
from colossalai.booster.plugin import LowLevelZeroPlugin, TorchDDPPlugin
|
||||||
|
from colossalai.testing import check_state_dict_equal, clear_cache_before_run, rerun_if_address_is_in_use, spawn
|
||||||
|
from tests.kit.model_zoo import model_zoo
|
||||||
|
from tests.test_checkpoint_io.utils import shared_tempdir
|
||||||
|
|
||||||
|
|
||||||
|
@clear_cache_before_run()
|
||||||
|
def check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type):
|
||||||
|
model = model_fn()
|
||||||
|
lora_config = LoraConfig(task_type=task_type, r=8, lora_alpha=32, lora_dropout=0.1)
|
||||||
|
|
||||||
|
test_plugins = [TorchDDPPlugin(), LowLevelZeroPlugin()]
|
||||||
|
test_configs = [
|
||||||
|
{
|
||||||
|
"lora_config": lora_config,
|
||||||
|
"quantize": False,
|
||||||
|
},
|
||||||
|
{
|
||||||
|
"lora_config": lora_config,
|
||||||
|
"quantize": True,
|
||||||
|
},
|
||||||
|
]
|
||||||
|
for plugin, test_config in product(test_plugins, test_configs):
|
||||||
|
# checkpoint loaded model
|
||||||
|
model_save = model_fn()
|
||||||
|
model_load = copy.deepcopy(model_save)
|
||||||
|
|
||||||
|
optimizer = AdamW(model.parameters(), lr=0.001)
|
||||||
|
criterion = loss_fn
|
||||||
|
|
||||||
|
booster = Booster(plugin=plugin)
|
||||||
|
model_save = booster.enable_lora(model_save, **test_config)
|
||||||
|
model_save, optimizer, criterion, _, _ = booster.boost(model_save, optimizer, criterion)
|
||||||
|
|
||||||
|
with shared_tempdir() as tempdir:
|
||||||
|
lora_ckpt_path = os.path.join(tempdir, "ckpt")
|
||||||
|
booster.save_lora_as_pretrained(model_save, lora_ckpt_path)
|
||||||
|
dist.barrier()
|
||||||
|
|
||||||
|
# The Lora checkpoint should be small in size
|
||||||
|
checkpoint_size_mb = os.path.getsize(os.path.join(lora_ckpt_path, "adapter_model.bin")) / (1024 * 1024)
|
||||||
|
assert checkpoint_size_mb < 1
|
||||||
|
|
||||||
|
model_load = booster.enable_lora(model_load, pretrained_dir=lora_ckpt_path, **test_config)
|
||||||
|
model_load, _, _, _, _ = booster.boost(model_load)
|
||||||
|
|
||||||
|
check_state_dict_equal(model_save.state_dict(), model_load.state_dict())
|
||||||
|
|
||||||
|
# test fwd bwd correctness
|
||||||
|
test_model = model_load
|
||||||
|
model_copy = copy.deepcopy(model_load)
|
||||||
|
|
||||||
|
data = data_gen_fn()
|
||||||
|
data = {
|
||||||
|
k: v.to("cuda") if torch.is_tensor(v) or "Tensor" in v.__class__.__name__ else v for k, v in data.items()
|
||||||
|
}
|
||||||
|
|
||||||
|
output = test_model(**data)
|
||||||
|
output = output_transform_fn(output)
|
||||||
|
loss = criterion(output)
|
||||||
|
|
||||||
|
booster.backward(loss, optimizer)
|
||||||
|
optimizer.clip_grad_by_norm(1.0)
|
||||||
|
optimizer.step()
|
||||||
|
|
||||||
|
for (n1, p1), (n2, p2) in zip(test_model.named_parameters(), model_copy.named_parameters()):
|
||||||
|
if "lora_" in n1:
|
||||||
|
# lora modules require gradients, thus updated
|
||||||
|
assert p1.requires_grad
|
||||||
|
assert not torch.testing.assert_close(p1.to(p2.device).to(p2.dtype), p2, atol=5e-3, rtol=5e-3)
|
||||||
|
else:
|
||||||
|
if not p1.requires_grad:
|
||||||
|
torch.testing.assert_close(p1.to(p2.device).to(p2.dtype), p2, atol=5e-3, rtol=5e-3)
|
||||||
|
|
||||||
|
|
||||||
|
def run_lora_test():
|
||||||
|
sub_model_zoo = model_zoo.get_sub_registry("transformers_llama")
|
||||||
|
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
|
||||||
|
task_type = None
|
||||||
|
if name == "transformers_llama_for_casual_lm":
|
||||||
|
task_type = "CAUSAL_LM"
|
||||||
|
if name == "transformers_llama_for_sequence_classification":
|
||||||
|
task_type = "SEQ_CLS"
|
||||||
|
check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type)
|
||||||
|
|
||||||
|
|
||||||
|
def run_dist(rank, world_size, port):
|
||||||
|
config = {}
|
||||||
|
colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
|
||||||
|
run_lora_test()
|
||||||
|
|
||||||
|
|
||||||
|
@rerun_if_address_is_in_use()
|
||||||
|
def test_torch_ddp_lora():
|
||||||
|
spawn(run_dist, 2)
|
||||||
|
|
@ -1,108 +0,0 @@
|
||||||
import copy
|
|
||||||
import os
|
|
||||||
|
|
||||||
import torch
|
|
||||||
from peft import LoraConfig
|
|
||||||
from torch import distributed as dist
|
|
||||||
from torch.optim import AdamW
|
|
||||||
|
|
||||||
import colossalai
|
|
||||||
from colossalai.booster import Booster
|
|
||||||
from colossalai.booster.plugin import TorchDDPPlugin
|
|
||||||
from colossalai.testing import (
|
|
||||||
assert_equal,
|
|
||||||
assert_not_equal,
|
|
||||||
check_state_dict_equal,
|
|
||||||
clear_cache_before_run,
|
|
||||||
rerun_if_address_is_in_use,
|
|
||||||
spawn,
|
|
||||||
)
|
|
||||||
from tests.kit.model_zoo import model_zoo
|
|
||||||
from tests.test_checkpoint_io.utils import shared_tempdir
|
|
||||||
|
|
||||||
|
|
||||||
@clear_cache_before_run()
|
|
||||||
def check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type):
|
|
||||||
model = model_fn()
|
|
||||||
lora_config = LoraConfig(task_type=task_type, r=8, lora_alpha=32, lora_dropout=0.1)
|
|
||||||
|
|
||||||
plugin = TorchDDPPlugin()
|
|
||||||
booster = Booster(plugin=plugin)
|
|
||||||
|
|
||||||
model = booster.enable_lora(model, lora_config=lora_config)
|
|
||||||
model_copy = copy.deepcopy(model)
|
|
||||||
|
|
||||||
optimizer = AdamW(model.parameters(), lr=0.001)
|
|
||||||
criterion = loss_fn
|
|
||||||
|
|
||||||
model, optimizer, criterion, _, _ = booster.boost(model, optimizer, criterion)
|
|
||||||
|
|
||||||
data = data_gen_fn()
|
|
||||||
data = {k: v.to("cuda") if torch.is_tensor(v) or "Tensor" in v.__class__.__name__ else v for k, v in data.items()}
|
|
||||||
|
|
||||||
output = model(**data)
|
|
||||||
output = output_transform_fn(output)
|
|
||||||
loss = criterion(output)
|
|
||||||
|
|
||||||
booster.backward(loss, optimizer)
|
|
||||||
optimizer.clip_grad_by_norm(1.0)
|
|
||||||
optimizer.step()
|
|
||||||
|
|
||||||
for (n1, p1), (n2, p2) in zip(model.named_parameters(), model_copy.named_parameters()):
|
|
||||||
if "lora_" in n1:
|
|
||||||
# lora modules require gradients, thus updated
|
|
||||||
assert p1.requires_grad
|
|
||||||
assert_not_equal(p1.to(p2.device), p2)
|
|
||||||
else:
|
|
||||||
if not p1.requires_grad:
|
|
||||||
assert_equal(p1.to(p2.device), p2)
|
|
||||||
|
|
||||||
|
|
||||||
@clear_cache_before_run()
|
|
||||||
def check_checkpoint(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type):
|
|
||||||
plugin = TorchDDPPlugin()
|
|
||||||
lora_config = LoraConfig(task_type=task_type, r=8, lora_alpha=32, lora_dropout=0.1)
|
|
||||||
|
|
||||||
model_save = model_fn()
|
|
||||||
model_load = copy.deepcopy(model_save)
|
|
||||||
|
|
||||||
booster = Booster(plugin=plugin)
|
|
||||||
model_save = booster.enable_lora(model_save, lora_config=lora_config)
|
|
||||||
model_save, _, _, _, _ = booster.boost(model_save)
|
|
||||||
|
|
||||||
with shared_tempdir() as tempdir:
|
|
||||||
lora_ckpt_path = os.path.join(tempdir, "ckpt")
|
|
||||||
booster.save_lora_as_pretrained(model_save, lora_ckpt_path)
|
|
||||||
dist.barrier()
|
|
||||||
|
|
||||||
# The Lora checkpoint should be small in size
|
|
||||||
checkpoint_size_mb = os.path.getsize(os.path.join(lora_ckpt_path, "adapter_model.bin")) / (1024 * 1024)
|
|
||||||
assert checkpoint_size_mb < 1
|
|
||||||
|
|
||||||
model_load = booster.enable_lora(model_load, pretrained_dir=lora_ckpt_path)
|
|
||||||
model_load, _, _, _, _ = booster.boost(model_load)
|
|
||||||
|
|
||||||
check_state_dict_equal(model_save.state_dict(), model_load.state_dict())
|
|
||||||
|
|
||||||
|
|
||||||
def run_lora_test():
|
|
||||||
sub_model_zoo = model_zoo.get_sub_registry("transformers_llama")
|
|
||||||
for name, (model_fn, data_gen_fn, output_transform_fn, loss_fn, _) in sub_model_zoo.items():
|
|
||||||
task_type = None
|
|
||||||
if name == "transformers_llama_for_casual_lm":
|
|
||||||
task_type = "CAUSAL_LM"
|
|
||||||
if name == "transformers_llama_for_sequence_classification":
|
|
||||||
task_type = "SEQ_CLS"
|
|
||||||
check_fwd_bwd(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type)
|
|
||||||
check_checkpoint(model_fn, data_gen_fn, output_transform_fn, loss_fn, task_type)
|
|
||||||
|
|
||||||
|
|
||||||
def run_dist(rank, world_size, port):
|
|
||||||
config = {}
|
|
||||||
colossalai.launch(config=config, rank=rank, world_size=world_size, host="localhost", port=port, backend="nccl")
|
|
||||||
run_lora_test()
|
|
||||||
|
|
||||||
|
|
||||||
@rerun_if_address_is_in_use()
|
|
||||||
def test_torch_ddp_lora():
|
|
||||||
spawn(run_dist, 2)
|
|
||||||
Loading…
Reference in New Issue