mirror of https://github.com/hpcaitech/ColossalAI
118 lines
5.0 KiB
Markdown
118 lines
5.0 KiB
Markdown
|
|
# 🚀 Colossal-Inference
|
|||
|
|
|
|||
|
|
## Table of contents
|
|||
|
|
|
|||
|
|
## Introduction
|
|||
|
|
|
|||
|
|
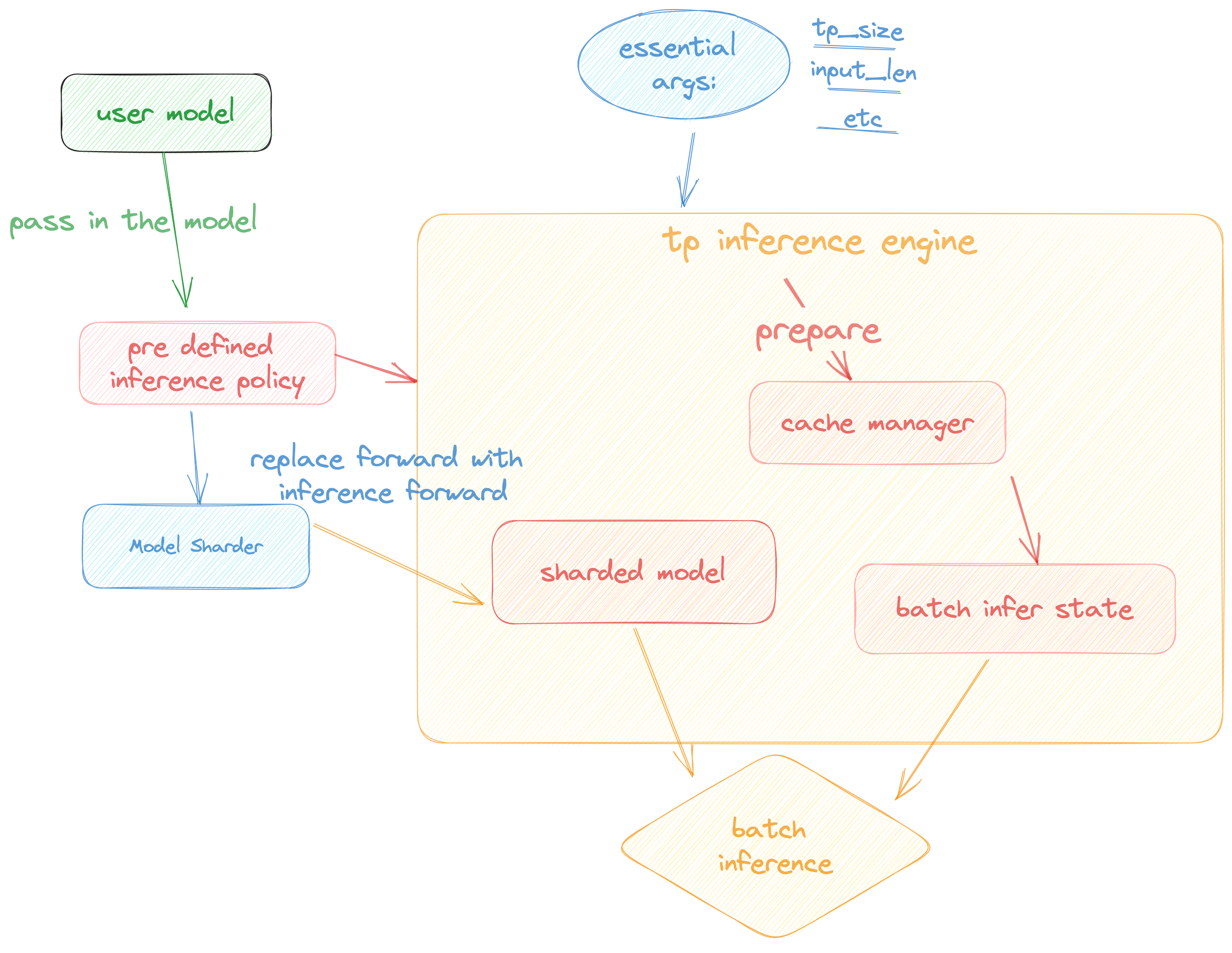
`Colossal Inference` is a module that contains colossal-ai designed inference framework, featuring high performance, steady and easy usability. `Colossal Inference` incorporated the advantages of the latest open-source inference systems, including TGI, vLLM, FasterTransformer, LightLLM and flash attention. while combining the design of Colossal AI, especially Shardformer, to reduce the learning curve for users.
|
|||
|
|
|
|||
|
|
## Design
|
|||
|
|
|
|||
|
|
Colossal Inference is composed of two main components:
|
|||
|
|
|
|||
|
|
1. High performance kernels and ops: which are inspired from existing libraries and modified correspondingly.
|
|||
|
|
2. Efficient memory management mechanism:which includes the key-value cache manager, allowing for zero memory waste during inference.
|
|||
|
|
1. `cache manager`: serves as a memory manager to help manage the key-value cache, it integrates functions such as memory allocation, indexing and release.
|
|||
|
|
2. `batch_infer_info`: holds all essential elements of a batch inference, which is updated every batch.
|
|||
|
|
3. High-level inference engine combined with `Shardformer`: it allows our inference framework to easily invoke and utilize various parallel methods.
|
|||
|
|
1. `engine.TPInferEngine`: it is a high level interface that integrates with shardformer, especially for multi-card (tensor parallel) inference:
|
|||
|
|
2. `modeling.llama.LlamaInferenceForwards`: contains the `forward` methods for llama inference. (in this case : llama)
|
|||
|
|
3. `policies.llama.LlamaModelInferPolicy` : contains the policies for `llama` models, which is used to call `shardformer` and segmentate the model forward in tensor parallelism way.
|
|||
|
|
|
|||
|
|
## Pipeline of inference:
|
|||
|
|
|
|||
|
|
In this section we discuss how the colossal inference works and integrates with the `Shardformer` . The details can be found in our codes.
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
## Roadmap of our implementation
|
|||
|
|
|
|||
|
|
- [x] Design cache manager and batch infer state
|
|||
|
|
- [x] Design TpInference engine to integrates with `Shardformer`
|
|||
|
|
- [x] Register corresponding high-performance `kernel` and `ops`
|
|||
|
|
- [x] Design policies and forwards (e.g. `Llama` and `Bloom`)
|
|||
|
|
- [x] policy
|
|||
|
|
- [x] context forward
|
|||
|
|
- [x] token forward
|
|||
|
|
- [ ] Replace the kernels with `faster-transformer` in token-forward stage
|
|||
|
|
- [ ] Support all models
|
|||
|
|
- [x] Llama
|
|||
|
|
- [x] Bloom
|
|||
|
|
- [ ] Chatglm2
|
|||
|
|
- [ ] Benchmarking for all models
|
|||
|
|
|
|||
|
|
## Get started
|
|||
|
|
|
|||
|
|
### Installation
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
pip install -e .
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### Requirements
|
|||
|
|
|
|||
|
|
dependencies
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
pytorch= 1.13.1 (gpu)
|
|||
|
|
cuda>= 11.6
|
|||
|
|
transformers= 4.30.2
|
|||
|
|
triton==2.0.0.dev20221202
|
|||
|
|
# for install vllm, please use this branch to install https://github.com/tiandiao123/vllm/tree/setup_branch
|
|||
|
|
vllm
|
|||
|
|
# for install flash-attention, please use commit hash: 67ae6fd74b4bc99c36b2ce524cf139c35663793c
|
|||
|
|
flash-attention
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### Docker
|
|||
|
|
|
|||
|
|
You can use docker run to use docker container to set-up environment
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
# env: python==3.8, cuda 11.6, pytorch == 1.13.1 triton==2.0.0.dev20221202, vllm kernels support, flash-attention-2 kernels support
|
|||
|
|
docker pull hpcaitech/colossalai-inference:v2
|
|||
|
|
docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcaitech/colossalai-inference:v2 /bin/bash
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### Dive into fast-inference!
|
|||
|
|
|
|||
|
|
example files are in
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
cd colossalai.examples
|
|||
|
|
python xx
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
## Performance
|
|||
|
|
|
|||
|
|
### environment:
|
|||
|
|
|
|||
|
|
We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `colossal-inference` and original `hugging-face torch fp16`.
|
|||
|
|
|
|||
|
|
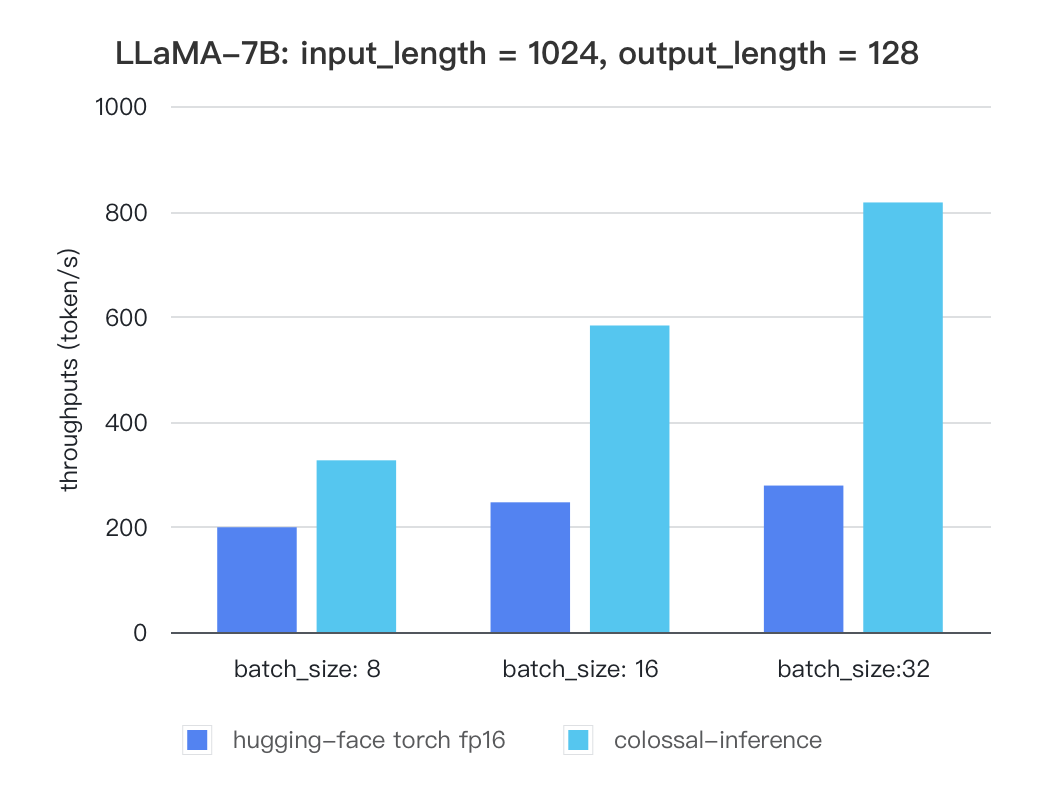
For various models, experiments were conducted using multiple batch sizes under the consistent model configuration of `7 billion(7b)` parameters, `1024` input length, and 128 output length. The obtained results are as follows (due to time constraints, the evaluation has currently been performed solely on the `A100` single GPU performance; multi-GPU performance will be addressed in the future):
|
|||
|
|
|
|||
|
|
### Single GPU Performance:
|
|||
|
|
|
|||
|
|
Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to furthur optimize the performance of LLM models. Please stay tuned.
|
|||
|
|
|
|||
|
|
#### Llama
|
|||
|
|
|
|||
|
|
| batch_size | 8 | 16 | 32 |
|
|||
|
|
| :---------------------: | :----: | :----: | :----: |
|
|||
|
|
| hugging-face torch fp16 | 199.12 | 246.56 | 278.4 |
|
|||
|
|
| colossal-inference | 326.4 | 582.72 | 816.64 |
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
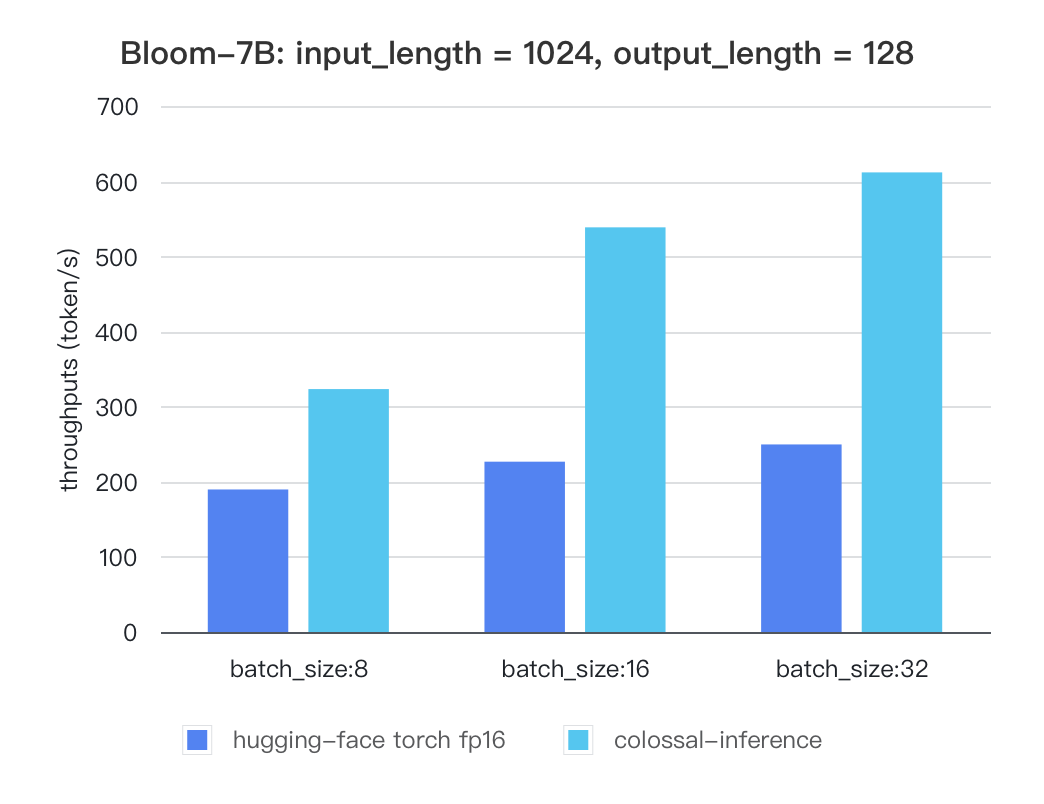
### Bloom
|
|||
|
|
|
|||
|
|
| batch_size | 8 | 16 | 32 |
|
|||
|
|
| :---------------------: | :----: | :----: | :----: |
|
|||
|
|
| hugging-face torch fp16 | 189.68 | 226.66 | 249.61 |
|
|||
|
|
| colossal-inference | 323.28 | 538.52 | 611.64 |
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
The results of more models are coming soon!
|