
PLEASE NOTE: This document applies to the HEAD of the source tree
If you are using a released version of Kubernetes, you should
refer to the docs that go with that version.
Documentation for other releases can be found at
[releases.k8s.io](http://releases.k8s.io).
--
# Kubelet: Runtime Pod Cache
This proposal builds on top of the Pod Lifecycle Event Generator (PLEG) proposed
in [#12802](https://issues.k8s.io/12802). It assumes that Kubelet subscribes to
the pod lifecycle event stream to eliminate periodic polling of pod
states. Please see [#12802](https://issues.k8s.io/12802). for the motivation and
design concept for PLEG.
Runtime pod cache is an in-memory cache which stores the *status* of
all pods, and is maintained by PLEG. It serves as a single source of
truth for internal pod status, freeing Kubelet from querying the
container runtime.
## Motivation
With PLEG, Kubelet no longer needs to perform comprehensive state
checking for all pods periodically. It only instructs a pod worker to
start syncing when there is a change of its pod status. Nevertheless,
during each sync, a pod worker still needs to construct the pod status
by examining all containers (whether dead or alive) in the pod, due to
the lack of the caching of previous states. With the integration of
pod cache, we can further improve Kubelet's CPU usage by
1. Lowering the number of concurrent requests to the container
runtime since pod workers no longer have to query the runtime
individually.
2. Lowering the total number of inspect requests because there is no
need to inspect containers with no state changes.
***Don't we already have a [container runtime cache]
(https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/container/runtime_cache.go)?***
The runtime cache is an optimization that reduces the number of `GetPods()`
calls from the workers. However,
* The cache does not store all information necessary for a worker to
complete a sync (e.g., `docker inspect`); workers still need to inspect
containers individually to generate `api.PodStatus`.
* Workers sometimes need to bypass the cache in order to retrieve the
latest pod state.
This proposal generalizes the cache and instructs PLEG to populate the cache, so
that the content is always up-to-date.
**Why can't each worker cache its own pod status?**
The short answer is yes, they can. The longer answer is that localized
caching limits the use of the cache content -- other components cannot
access it. This often leads to caching at multiple places and/or passing
objects around, complicating the control flow.
## Runtime Pod Cache
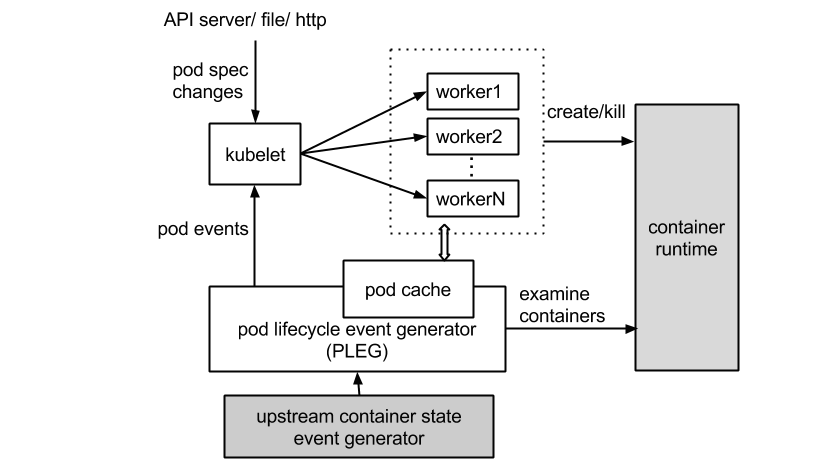
Pod cache stores the `PodStatus` for all pods on the node. `PodStatus` encompasses
all the information required from the container runtime to generate
`api.PodStatus` for a pod.
```go
// PodStatus represents the status of the pod and its containers.
// api.PodStatus can be derived from examining PodStatus and api.Pod.
type PodStatus struct {
ID types.UID
Name string
Namespace string
IP string
ContainerStatuses []*ContainerStatus
}
// ContainerStatus represents the status of a container.
type ContainerStatus struct {
ID ContainerID
Name string
State ContainerState
CreatedAt time.Time
StartedAt time.Time
FinishedAt time.Time
ExitCode int
Image string
ImageID string
Hash uint64
RestartCount int
Reason string
Message string
}
```
`PodStatus` is defined in the container runtime interface, hence is
runtime-agnostic.
PLEG is responsible for updating the entries pod cache, hence always keeping
the cache up-to-date.
1. Detect change of container state
2. Inspect the pod for details
3. Update the pod cache with the new PodStatus
- If there is no real change of the pod entry, do nothing
- Otherwise, generate and send out the corresponding pod lifecycle event
Note that in (3), PLEG can check if there is any disparity between the old
and the new pod entry to filter out duplicated events if needed.
### Evict cache entries
Note that the cache represents all the pods/containers known by the container
runtime. A cache entry should only be evicted if the pod is no longer visible
by the container runtime. PLEG is responsible for deleting entries in the
cache.
### Generate `api.PodStatus`
Because pod cache stores the up-to-date `PodStatus` of the pods, Kubelet can
generate the `api.PodStatus` by interpreting the cache entry at any
time. To avoid sending intermediate status (e.g., while a pod worker
is restarting a container), we will instruct the pod worker to generate a new
status at the beginning of each sync.
### Cache contention
Cache contention should not be a problem when the number of pods is
small. When Kubelet scales, we can always shard the pods by ID to
reduce contention.
### Disk management
The pod cache is not capable to fulfill the needs of container/image garbage
collectors as they may demand more than pod-level information. These components
will still need to query the container runtime directly at times. We may
consider extending the cache for these use cases, but they are beyond the scope
of this proposal.
## Impact on Pod Worker Control Flow
A pod worker may perform various operations (e.g., start/kill a container)
during a sync. They will expect to see the results of such operations reflected
in the cache in the next sync. Alternately, they can bypass the cache and
query the container runtime directly to get the latest status. However, this
is not desirable since the cache is introduced exactly to eliminate unnecessary,
concurrent queries. Therefore, a pod worker should be blocked until all expected
results have been updated to the cache by PLEG.
Depending on the type of PLEG (see [#12802](https://issues.k8s.io/12802)) in
use, the methods to check whether a requirement is met can differ. For a
PLEG that solely relies on relisting, a pod worker can simply wait until the
relist timestamp is newer than the end of the worker's last sync. On the other
hand, if pod worker knows what events to expect, they can also block until the
events are observed.
It should be noted that `api.PodStatus` will only be generated by the pod
worker *after* the cache has been updated. This means that the perceived
responsiveness of Kubelet (from querying the API server) will be affected by
how soon the cache can be populated. For the pure-relisting PLEG, the relist
period can become the bottleneck. On the other hand, A PLEG which watches the
upstream event stream (and knows how what events to expect) is not restricted
by such periods and should improve Kubelet's perceived responsiveness.
## TODOs for v1.2
- Redefine container runtime types ([#12619](https://issues.k8s.io/12619)):
and introduce `PodStatus`. Refactor dockertools and rkt to use the new type.
- Add cache and instruct PLEG to populate it.
- Refactor Kubelet to use the cache.
- Deprecate the old runtime cache.
[]()