## Training Performance
InternLM deeply integrates Flash-Attention, Apex, and other high-performance model operators to improve training efficiency. It achieves efficient overlap of computation and communication, significantly reducing cross-node communication traffic during training by building the Hybrid Zero technique. InternLM supports expanding the 7B model from 8 GPUs to 1024 GPUs, with an acceleration efficiency of up to 90% at the thousand-card scale, a training throughput of over 180 TFLOPS, and an average of over 3600 tokens per GPU per second. The following table shows InternLM's scalability test data at different configurations:
| GPU Number | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
| ---------------- | ---- | ---- | ---- | ---- | ----- | ----- | ----- | ------ |
| TGS (Tokens/GPU/Second) | 4078 | 3939 | 3919 | 3944 | 3928 | 3920 | 3835 | 3625 |
| TFLOPS | 192 | 192 | 186 | 186 | 185 | 185 | 186 | 182 |
We tested the performance of training the 7B model in InternLM using various parallel configurations on a GPU cluster. In each test group, the number of tokens processed per GPU in a single iteration remained consistent. The hardware and parameter configurations used in the tests are shown in the table below:
| Hardware | Model |
| ----------------------- | ----------------------------- |
| GPU | nvidia_a100-sxm4-80gb |
| Memory | 2TB |
| Inter-machine bandwidth | 4 * 100Gb RoCE |
| CPU | 128 core Intel(R) Xeon(R) CPU |
| Hyperparameters | tp=1 | tp=2 |
| --------------- | ---- | ---- |
| micro_num | 4 | 4 |
| micro_bsz | 2 | 4 |
| seq_len | 2048 | 2048 |
The configuration of `zero1` in InternLM determines the allocation range of optimizer states.
- `zero1=-1` indicates that optimizer states are distributed across all data-parallel nodes (equivalent to Deepspeed Zero-1).
- In the case of `zero1=8, tp=1`, optimizer states are distributed within 8 GPUs in a single node, and the optimizer states remain consistent across different nodes.
### Throughput Measurement
Throughput is defined as TGS, the average number of tokens processed per GPU per second. In this test, the training configuration had `pack_sample_into_one=False` and `checkpoint=False`. The test results are shown in the following table. When using `zero1=8, tp=1`, InternLM achieves an acceleration efficiency of `88%` for training the 7B model with a thousand cards.
| Parallel Configuration | 8 GPUs | 16 GPUs | 32 GPUs | 64 GPUs | 128 GPUs | 256 GPUs | 512 GPUs | 1024 GPUs |
| ---------------------- | ------ | ------- | ------- | ------- | -------- | -------- | -------- | --------- |
| (tp=1, zero1=-1) | 4062 | 3842 | 3752 | 3690 | 3571 | 3209 | 2861 | 2271 |
| (tp=1, zero1=8) | 4078 | 3939 | 3919 | 3944 | 3928 | 3920 | 3835 | 3625 |
| (tp=2, zero1=-1) | 3822 | 3595 | 3475 | 3438 | 3308 | 3094 | 2992 | 2785 |
| (tp=2, zero1=4) | 3761 | 3658 | 3655 | 3650 | 3651 | 3653 | 3589 | 3486 |
### FLOPS Testing
The computational workload of model training is based on the FLOPS calculation method described in the [Megatron](https://deepakn94.github.io/assets/papers/megatron-sc21.pdf) paper. To ensure constant FLOPS during training, the test configuration had `pack_sample_into_one=True`. The training used the following configuration:
Activation Checkpointing | tp | zero-1 | seq_len | micro_num | micro_bsz |
| --- | --- | ------ | ------- | --------- | --------- |
Disabled | 1 | 8 | 2048 | 4 | 2 |
Enabled | 1 | 8 | 2048 | 1 | 8 |
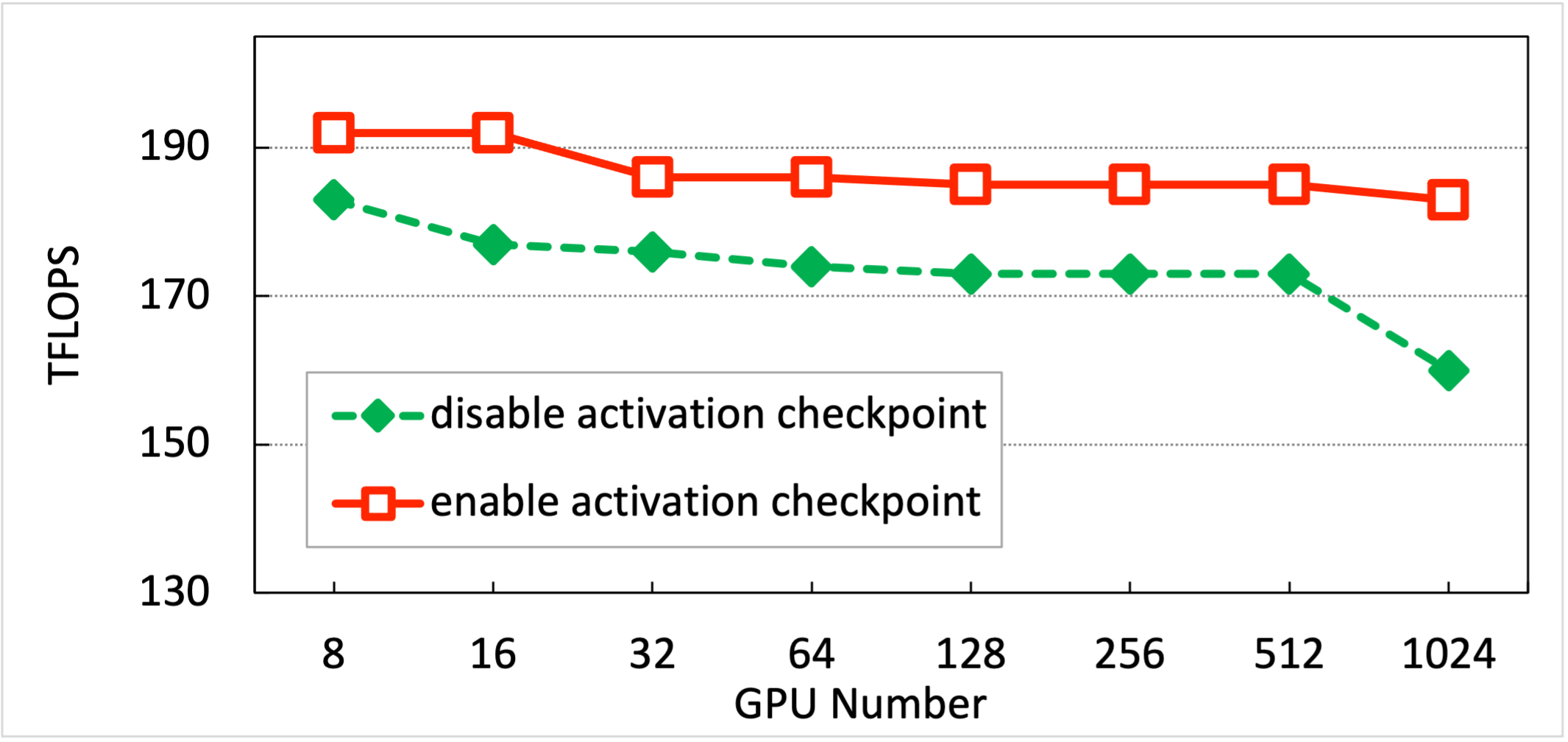
The test results are shown in the table below. InternLM can achieve `>180 TFLOPS` for 7B model on thousand-card scale.
| Activation Checkpoint | 8 GPUs | 16 GPUs | 32 GPUs | 64 GPUs | 128 GPUs | 256 GPUs | 512 GPUs | 1024 GPUs |
| --------------------- | ------ | ------- | ------- | ------- | -------- | -------- | -------- | --------- |
| Disabled | 183 | 177 | 176 | 174 | 173 | 173 | 173 | 160 |
| Enabled | 192 | 192 | 186 | 186 | 185 | 185 | 186 | 182 |