* add SimPO
* fix dataloader
* remove debug code
* add orpo
* fix style
* fix colossalai, transformers version
* fix colossalai, transformers version
* fix colossalai, transformers version
* fix torch colossalai version
* update transformers version
* [shardformer] DeepseekMoE support (#5871)
* [Feature] deepseek moe expert parallel implement
* [misc] fix typo, remove redundant file (#5867)
* [misc] fix typo
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
---------
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
* [Feature] deepseek support & unit test
* [misc] remove debug code & useless print
* [misc] fix typos (#5872)
* [Feature] remove modeling file, use auto config. (#5884)
* [misc] fix typos
* [Feature] deepseek support via auto model, remove modeling file
* [misc] delete useless file
* [misc] fix typos
* [Deepseek] remove redundant code (#5888)
* [misc] fix typos
* [Feature] deepseek support via auto model, remove modeling file
* [misc] delete useless file
* [misc] fix typos
* [misc] remove redundant code
* [Feature/deepseek] resolve comment. (#5889)
* [misc] fix typos
* [Feature] deepseek support via auto model, remove modeling file
* [misc] delete useless file
* [misc] fix typos
* [misc] remove redundant code
* [misc] mv module replacement into if branch
* [misc] add some warning message and modify some code in unit test
* [misc] fix typos
---------
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
* [Hoxfix] Fix CUDA_DEVICE_MAX_CONNECTIONS for comm overlap
Co-authored-by: Edenzzzz <wtan45@wisc.edu>
* [Feat] Diffusion Model(PixArtAlpha/StableDiffusion3) Support (#5838)
* Diffusion Model Inference support
* Stable Diffusion 3 Support
* pixartalpha support
* [HotFix] CI,import,requirements-test for #5838 (#5892)
* [Hot Fix] CI,import,requirements-test
---------
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
* [Feature] Enable PP + SP for llama (#5868)
* fix cross-PP-stage position id length diff bug
* fix typo
* fix typo
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* use a one cross entropy func for all shardformer models
---------
Co-authored-by: Edenzzzz <wtan45@wisc.edu>
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
* [ShardFormer] Add Ulysses Sequence Parallelism support for Command-R, Qwen2 and ChatGLM (#5897)
* add benchmark for sft, dpo, simpo, orpo. Add benchmarking result. Support lora with gradient checkpoint
* fix style
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* fix eval
* hotfix citation
* [zero] support all-gather overlap (#5898)
* [zero] support all-gather overlap
* [zero] add overlap all-gather flag
* [misc] fix typo
* [zero] update api
* fix orpo cross entropy loss
* [Auto Parallel]: Speed up intra-op plan generation by 44% (#5446)
* Remove unnecessary calls to deepcopy
* Build DimSpec's difference dict only once
This change considerably speeds up construction speed of DimSpec objects. The difference_dict is the same for each DimSpec object, so a single copy of it is enough.
* Fix documentation of DimSpec's difference method
* [ShardFormer] fix qwen2 sp (#5903)
* [compatibility] support torch 2.2 (#5875)
* Support Pytorch 2.2.2
* keep build_on_pr file and update .compatibility
* fix object_to_tensor usage when torch>=2.3.0 (#5820)
* [misc] support torch2.3 (#5893)
* [misc] support torch2.3
* [devops] update compatibility ci
* [devops] update compatibility ci
* [devops] add debug
* [devops] add debug
* [devops] add debug
* [devops] add debug
* [devops] remove debug
* [devops] remove debug
* [release] update version (#5912)
* [plugin] support all-gather overlap for hybrid parallel (#5919)
* [plugin] fixed all-gather overlap support for hybrid parallel
* add kto
* fix style, add kto data sample
* [Examples] Add lazy init to OPT and GPT examples (#5924)
Co-authored-by: Edenzzzz <wtan45@wisc.edu>
* [ColossalChat] Hotfix for ColossalChat (#5910)
* add ignore and tiny llama
* fix path issue
* run style
* fix issue
* update bash
* add ignore and tiny llama
* fix path issue
* run style
* fix issue
* update bash
* fix ddp issue
* add Qwen 1.5 32B
* refactor tokenization
* [FIX BUG] UnboundLocalError: cannot access local variable 'default_conversation' where it is not associated with a value (#5931)
* cannot access local variable 'default_conversation' where it is not associated with a value
set default value for 'default_conversation'
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
---------
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
* fix test data
* refactor evaluation
* remove real data path
* remove real data path
* Add n_fused as an input from native_module (#5894)
* [FIX BUG] convert env param to int in (#5934)
* [Hotfix] Fix ZeRO typo #5936
Co-authored-by: Edenzzzz <wtan45@wisc.edu>
* [Feature] Add a switch to control whether the model checkpoint needs to be saved after each epoch ends (#5941)
* Add a switch to control whether the model checkpoint needs to be saved after each epoch ends
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
---------
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
* fix style
* fix style
* fix style
* [shardformer] hotfix attn mask (#5945)
* [shardformer] hotfix attn mask (#5947)
* [Feat] Distrifusion Acceleration Support for Diffusion Inference (#5895)
* Distrifusion Support source
* comp comm overlap optimization
* sd3 benchmark
* pixart distrifusion bug fix
* sd3 bug fix and benchmark
* generation bug fix
* naming fix
* add docstring, fix counter and shape error
* add reference
* readme and requirement
* [zero] hotfix update master params (#5951)
* [release] update version (#5952)
* [Chat] Fix lora (#5946)
* fix merging
* remove filepath
* fix style
* Update README.md (#5958)
* [hotfix] Remove unused plan section (#5957)
* remove readme
* fix readme
* update
* [test] add mixtral for sequence classification
* [test] add mixtral transformer test
* [moe] fix plugin
* [test] mixtra pp shard test
* [chore] handle non member group
* [zero] solve hang
* [test] pass mixtral shardformer test
* [moe] implement transit between non moe tp and ep
* [zero] solve hang
* [misc] solve booster hang by rename the variable
* solve hang when parallel mode = pp + dp
* [moe] implement submesh initialization
* [moe] add mixtral dp grad scaling when not all experts are activated
* [chore] manually revert unintended commit
* [chore] trivial fix
* [chore] arg pass & remove drop token
* [test] add mixtral modelling test
* [moe] implement tp
* [moe] test deepseek
* [moe] clean legacy code
* [Feature] MoE Ulysses Support (#5918)
* moe sp support
* moe sp bug solve
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
---------
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
* [chore] minor fix
* [moe] init moe plugin comm setting with sp
* moe sp + ep bug fix
* [moe] finalize test (no pp)
* [moe] full test for deepseek and mixtral (pp + sp to fix)
* [chore] minor fix after rebase
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* [chore] solve moe ckpt test failure and some other arg pass failure
* [moe] remove ops
* [test] fix test: test_zero1_2
* [bug] fix: somehow logger hangs the program
* [moe] deepseek moe sp support
* [test] add check
* [deepseek] replace attn (a workaround for bug in transformers)
* [misc] skip redunant test
* [misc] remove debug/print code
* [moe] refactor mesh assignment
* Revert "[moe] implement submesh initialization"
This reverts commit
|
||
|---|---|---|
| .github | ||
| applications | ||
| colossalai | ||
| docker | ||
| docs | ||
| examples | ||
| extensions | ||
| requirements | ||
| tests | ||
| .clang-format | ||
| .compatibility | ||
| .coveragerc | ||
| .cuda_ext.json | ||
| .gitignore | ||
| .gitmodules | ||
| .isort.cfg | ||
| .pre-commit-config.yaml | ||
| CHANGE_LOG.md | ||
| CONTRIBUTING.md | ||
| LICENSE | ||
| MANIFEST.in | ||
| README.md | ||
| pytest.ini | ||
| setup.py | ||
| version.txt | ||
README.md
Colossal-AI
![]()
Colossal-AI: Making large AI models cheaper, faster, and more accessible
Paper | Documentation | Examples | Forum | GPU Cloud Playground | Blog

![]()

Latest News
- [2024/06] Open-Sora Continues Open Source: Generate Any 16-Second 720p HD Video with One Click, Model Weights Ready to Use
- [2024/05] Large AI Models Inference Speed Doubled, Colossal-Inference Open Source Release
- [2024/04] Open-Sora Unveils Major Upgrade: Embracing Open Source with Single-Shot 16-Second Video Generation and 720p Resolution
- [2024/04] Most cost-effective solutions for inference, fine-tuning and pretraining, tailored to LLaMA3 series
- [2024/03] 314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, Efficient and Easy-to-Use PyTorch+HuggingFace version is Here
- [2024/03] Open-Sora: Revealing Complete Model Parameters, Training Details, and Everything for Sora-like Video Generation Models
- [2024/03] Open-Sora:Sora Replication Solution with 46% Cost Reduction, Sequence Expansion to Nearly a Million
- [2024/01] Inference Performance Improved by 46%, Open Source Solution Breaks the Length Limit of LLM for Multi-Round Conversations
- [2023/07] HPC-AI Tech Raises 22 Million USD in Series A Funding
Table of Contents
- Why Colossal-AI
- Features
-
Colossal-AI for Real World Applications
- Open-Sora: Revealing Complete Model Parameters, Training Details, and Everything for Sora-like Video Generation Models
- Colossal-LLaMA-2: One Half-Day of Training Using a Few Hundred Dollars Yields Similar Results to Mainstream Large Models, Open-Source and Commercial-Free Domain-Specific Llm Solution
- ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline
- AIGC: Acceleration of Stable Diffusion
- Biomedicine: Acceleration of AlphaFold Protein Structure
- Parallel Training Demo
- Single GPU Training Demo
- Inference
- Installation
- Use Docker
- Community
- Contributing
- Cite Us
Why Colossal-AI

Prof. James Demmel (UC Berkeley): Colossal-AI makes training AI models efficient, easy, and scalable.
Features
Colossal-AI provides a collection of parallel components for you. We aim to support you to write your distributed deep learning models just like how you write your model on your laptop. We provide user-friendly tools to kickstart distributed training and inference in a few lines.
-
Parallelism strategies
- Data Parallelism
- Pipeline Parallelism
- 1D, 2D, 2.5D, 3D Tensor Parallelism
- Sequence Parallelism
- Zero Redundancy Optimizer (ZeRO)
- Auto-Parallelism
-
Heterogeneous Memory Management
-
Friendly Usage
- Parallelism based on the configuration file
Colossal-AI in the Real World
Open-Sora
Open-Sora:Revealing Complete Model Parameters, Training Details, and Everything for Sora-like Video Generation Models [code] [blog] [Model weights] [Demo] [GPU Cloud Playground] [OpenSora Image]

Colossal-LLaMA-2
[GPU Cloud Playground] [LLaMA3 Image]
-
7B: One half-day of training using a few hundred dollars yields similar results to mainstream large models, open-source and commercial-free domain-specific LLM solution. [code] [blog] [HuggingFace model weights] [Modelscope model weights]
-
13B: Construct refined 13B private model with just $5000 USD. [code] [blog] [HuggingFace model weights] [Modelscope model weights]
| Model | Backbone | Tokens Consumed | MMLU (5-shot) | CMMLU (5-shot) | AGIEval (5-shot) | GAOKAO (0-shot) | CEval (5-shot) |
|---|---|---|---|---|---|---|---|
| Baichuan-7B | - | 1.2T | 42.32 (42.30) | 44.53 (44.02) | 38.72 | 36.74 | 42.80 |
| Baichuan-13B-Base | - | 1.4T | 50.51 (51.60) | 55.73 (55.30) | 47.20 | 51.41 | 53.60 |
| Baichuan2-7B-Base | - | 2.6T | 46.97 (54.16) | 57.67 (57.07) | 45.76 | 52.60 | 54.00 |
| Baichuan2-13B-Base | - | 2.6T | 54.84 (59.17) | 62.62 (61.97) | 52.08 | 58.25 | 58.10 |
| ChatGLM-6B | - | 1.0T | 39.67 (40.63) | 41.17 (-) | 40.10 | 36.53 | 38.90 |
| ChatGLM2-6B | - | 1.4T | 44.74 (45.46) | 49.40 (-) | 46.36 | 45.49 | 51.70 |
| InternLM-7B | - | 1.6T | 46.70 (51.00) | 52.00 (-) | 44.77 | 61.64 | 52.80 |
| Qwen-7B | - | 2.2T | 54.29 (56.70) | 56.03 (58.80) | 52.47 | 56.42 | 59.60 |
| Llama-2-7B | - | 2.0T | 44.47 (45.30) | 32.97 (-) | 32.60 | 25.46 | - |
| Linly-AI/Chinese-LLaMA-2-7B-hf | Llama-2-7B | 1.0T | 37.43 | 29.92 | 32.00 | 27.57 | - |
| wenge-research/yayi-7b-llama2 | Llama-2-7B | - | 38.56 | 31.52 | 30.99 | 25.95 | - |
| ziqingyang/chinese-llama-2-7b | Llama-2-7B | - | 33.86 | 34.69 | 34.52 | 25.18 | 34.2 |
| TigerResearch/tigerbot-7b-base | Llama-2-7B | 0.3T | 43.73 | 42.04 | 37.64 | 30.61 | - |
| LinkSoul/Chinese-Llama-2-7b | Llama-2-7B | - | 48.41 | 38.31 | 38.45 | 27.72 | - |
| FlagAlpha/Atom-7B | Llama-2-7B | 0.1T | 49.96 | 41.10 | 39.83 | 33.00 | - |
| IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | Llama-13B | 0.11T | 50.25 | 40.99 | 40.04 | 30.54 | - |
| Colossal-LLaMA-2-7b-base | Llama-2-7B | 0.0085T | 53.06 | 49.89 | 51.48 | 58.82 | 50.2 |
| Colossal-LLaMA-2-13b-base | Llama-2-13B | 0.025T | 56.42 | 61.80 | 54.69 | 69.53 | 60.3 |
ColossalChat

ColossalChat: An open-source solution for cloning ChatGPT with a complete RLHF pipeline. [code] [blog] [demo] [tutorial]
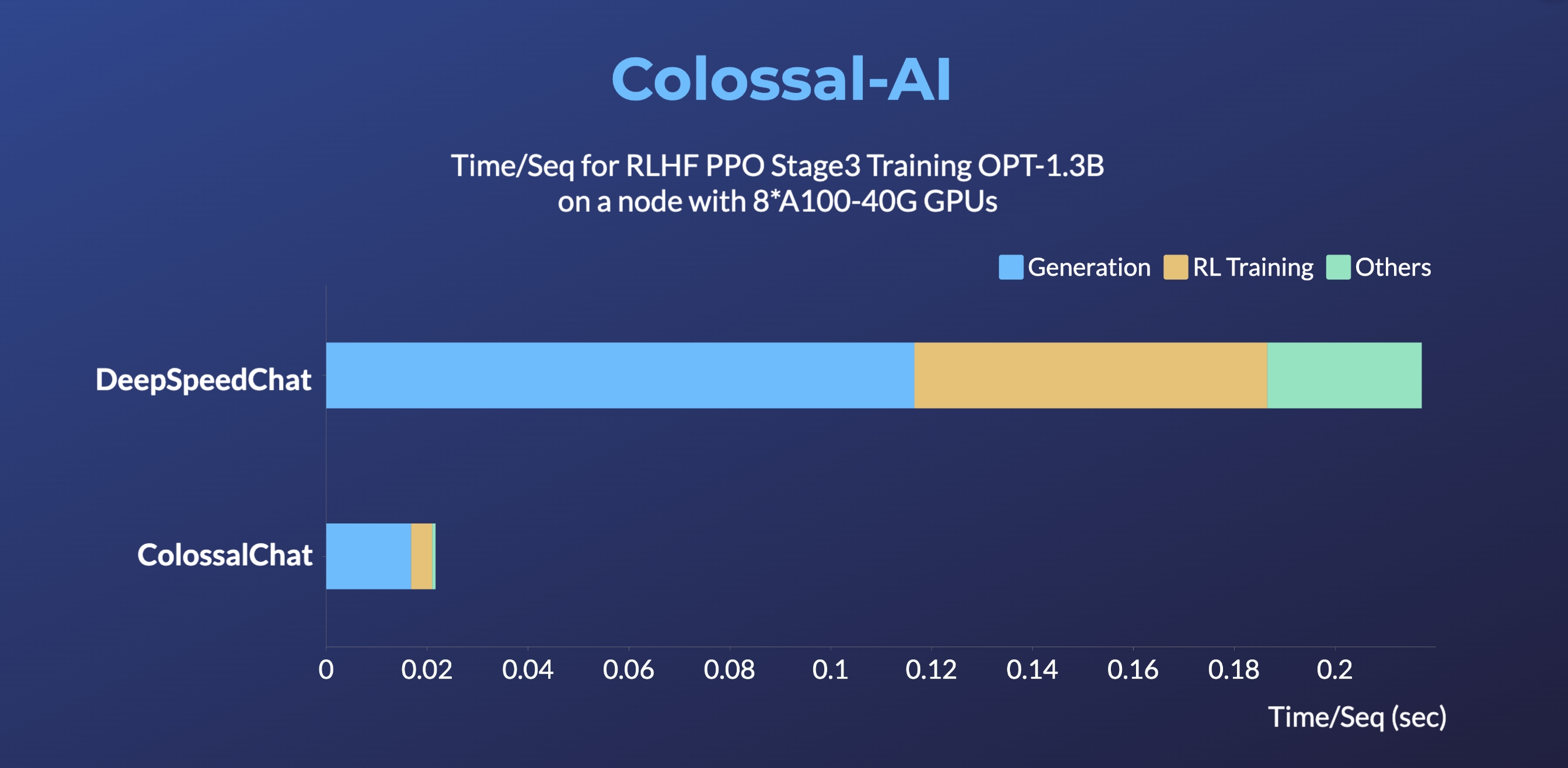
- Up to 10 times faster for RLHF PPO Stage3 Training

- Up to 7.73 times faster for single server training and 1.42 times faster for single-GPU inference
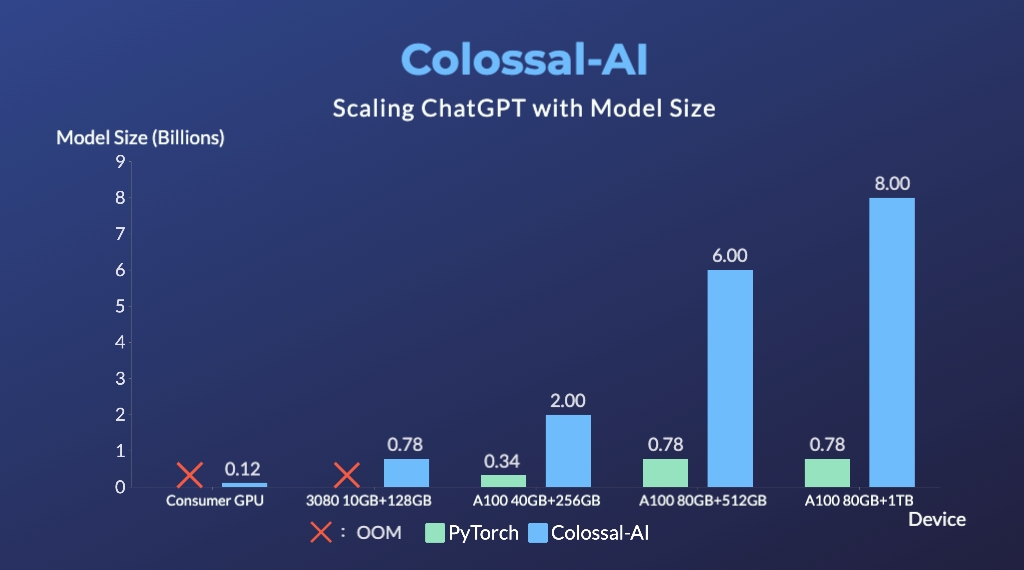
- Up to 10.3x growth in model capacity on one GPU
- A mini demo training process requires only 1.62GB of GPU memory (any consumer-grade GPU)
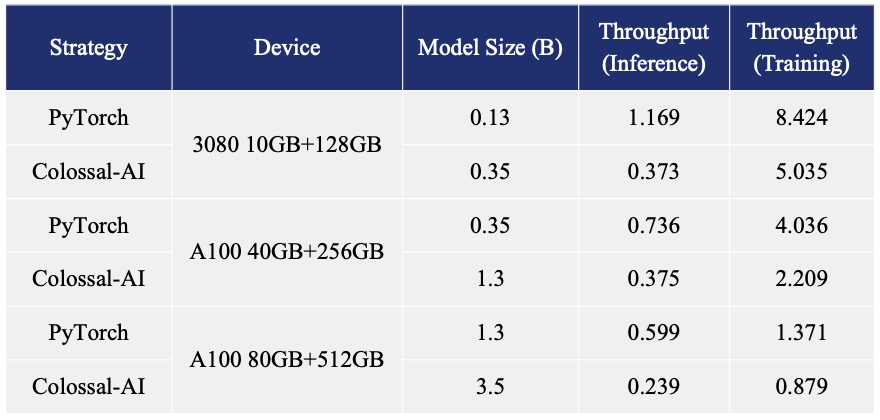
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
- Keep at a sufficiently high running speed
AIGC
Acceleration of AIGC (AI-Generated Content) models such as Stable Diffusion v1 and Stable Diffusion v2.
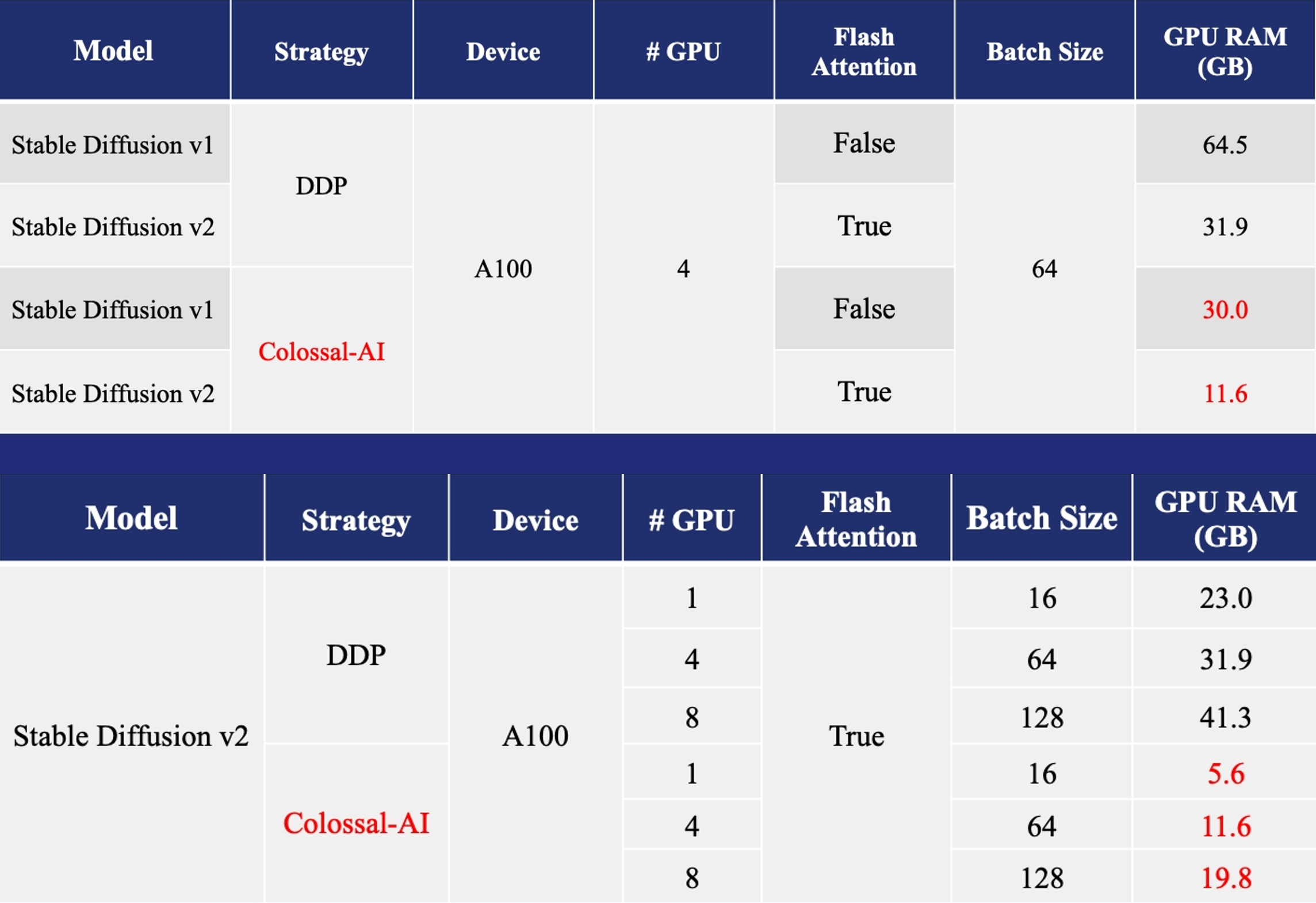
- Training: Reduce Stable Diffusion memory consumption by up to 5.6x and hardware cost by up to 46x (from A100 to RTX3060).

- DreamBooth Fine-tuning: Personalize your model using just 3-5 images of the desired subject.

- Inference: Reduce inference GPU memory consumption by 2.5x.
Biomedicine
Acceleration of AlphaFold Protein Structure

- FastFold: Accelerating training and inference on GPU Clusters, faster data processing, inference sequence containing more than 10000 residues.
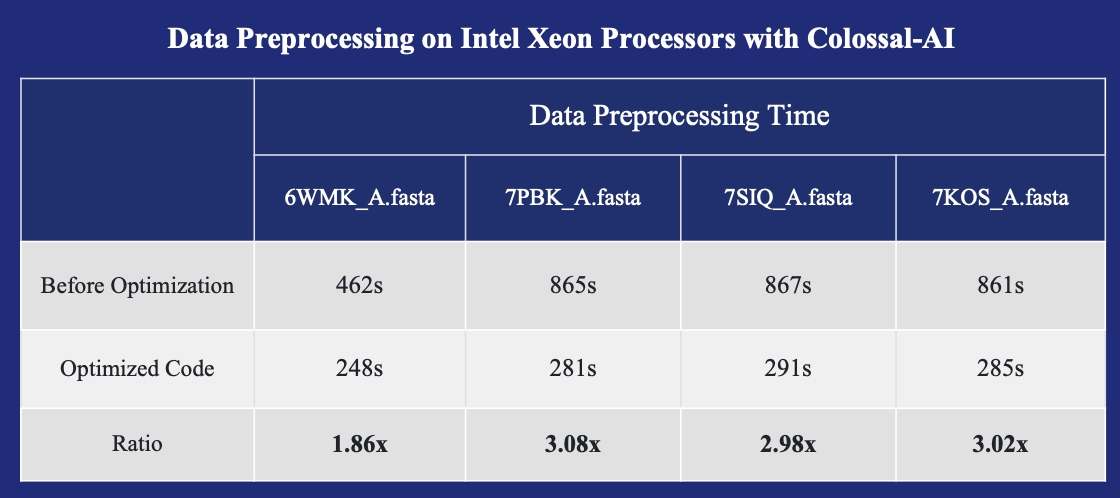
- FastFold with Intel: 3x inference acceleration and 39% cost reduce.
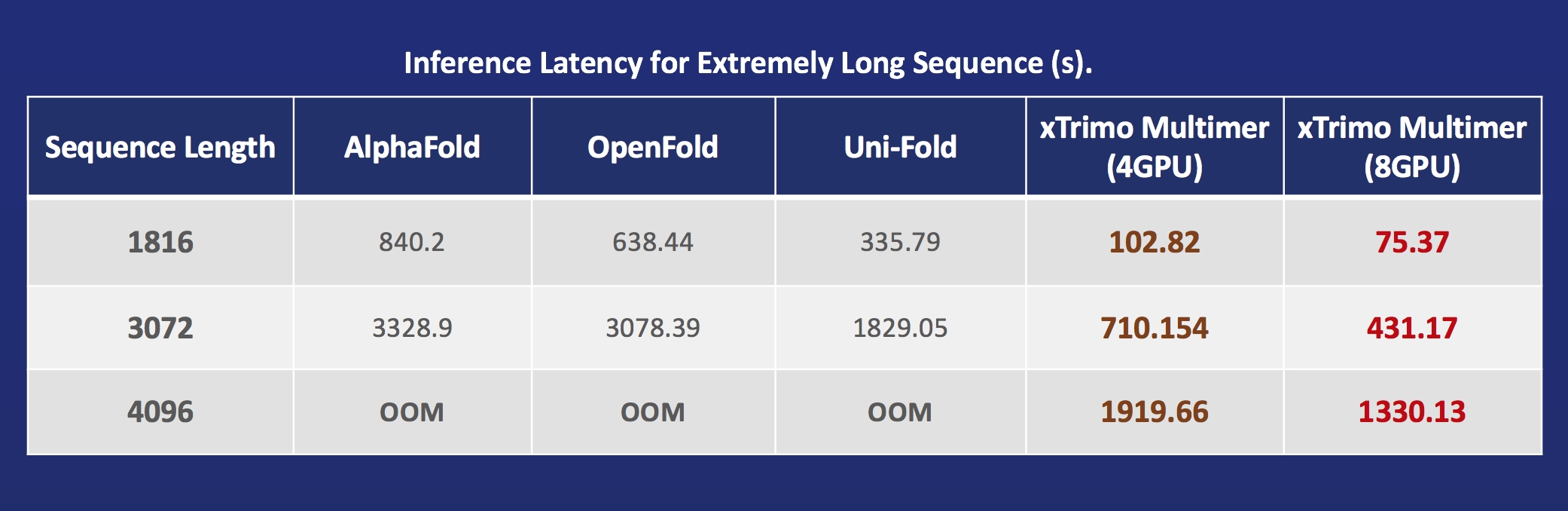
- xTrimoMultimer: accelerating structure prediction of protein monomers and multimer by 11x.
Parallel Training Demo
LLaMA3
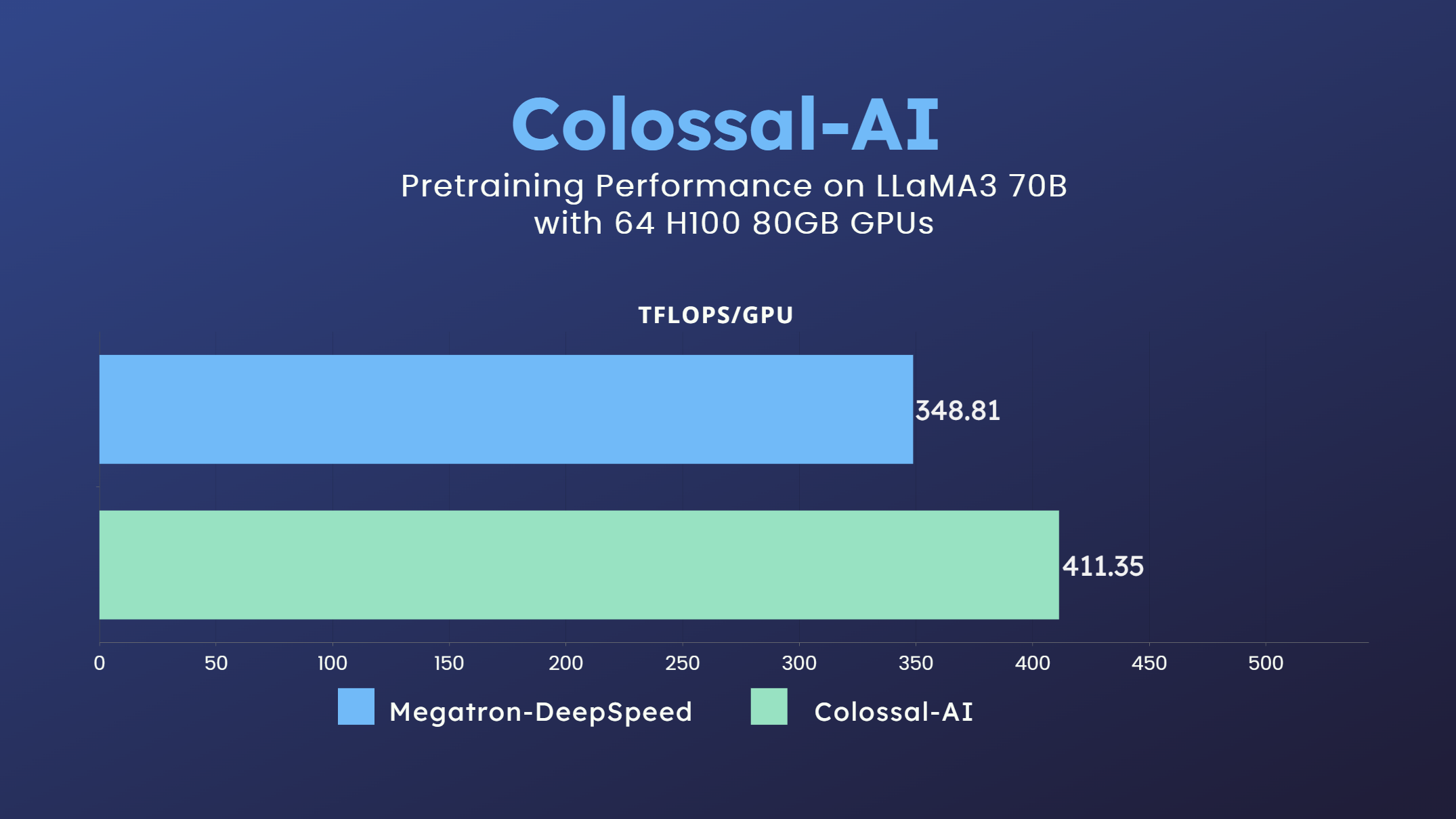
- 70 billion parameter LLaMA3 model training accelerated by 18% [code] [GPU Cloud Playground] [LLaMA3 Image]
LLaMA2
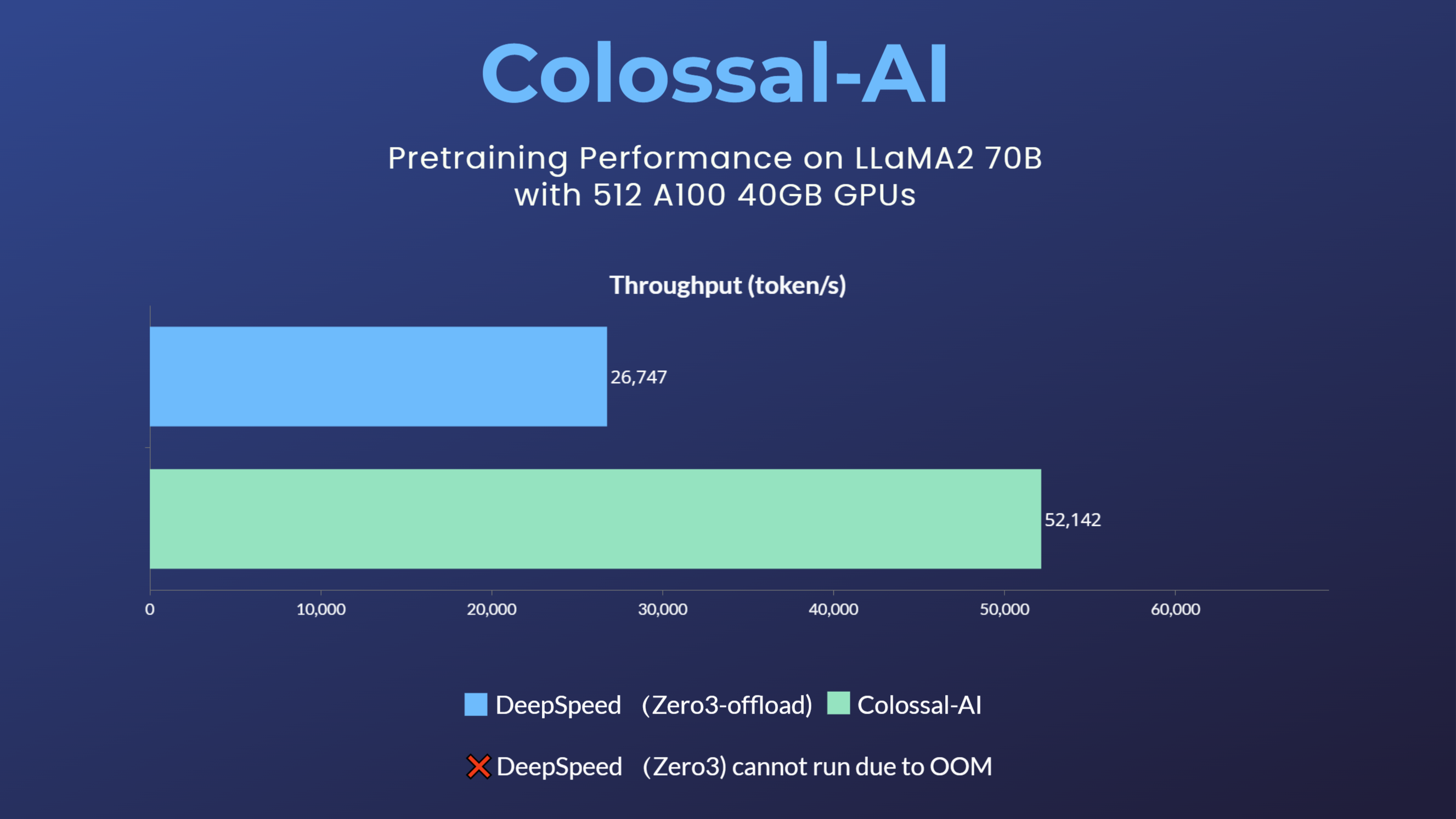
LLaMA1
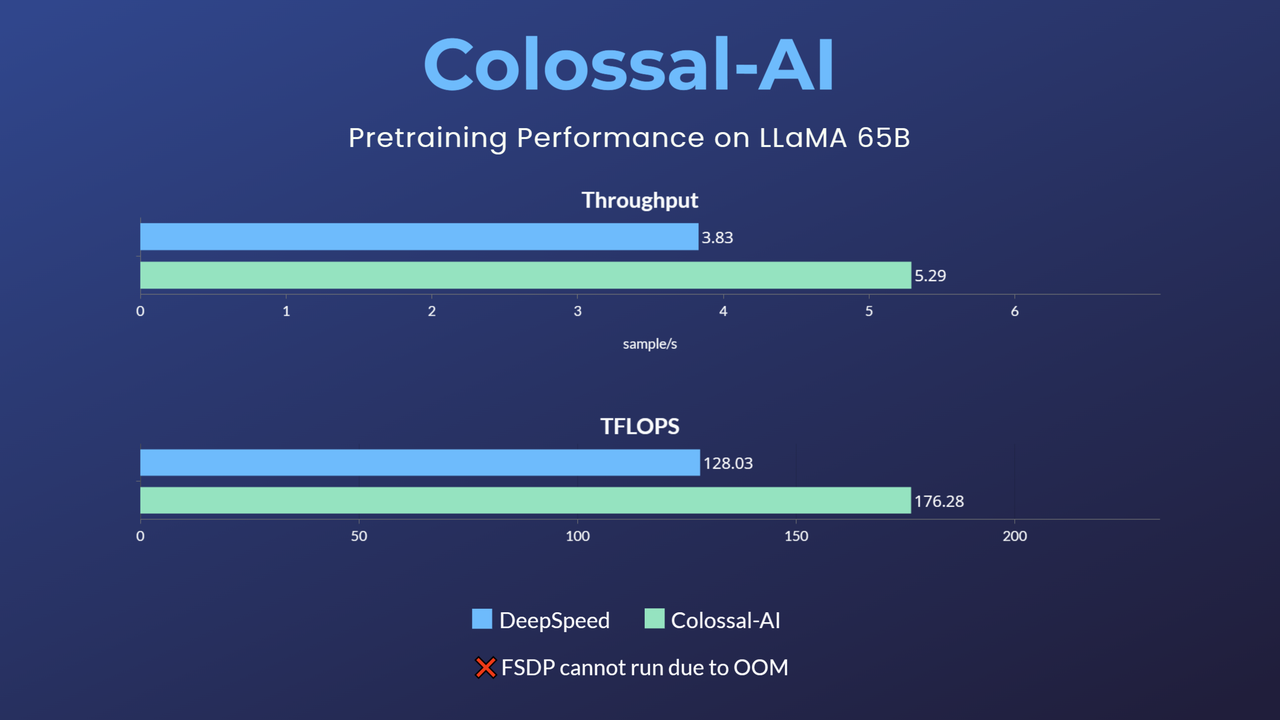
MoE
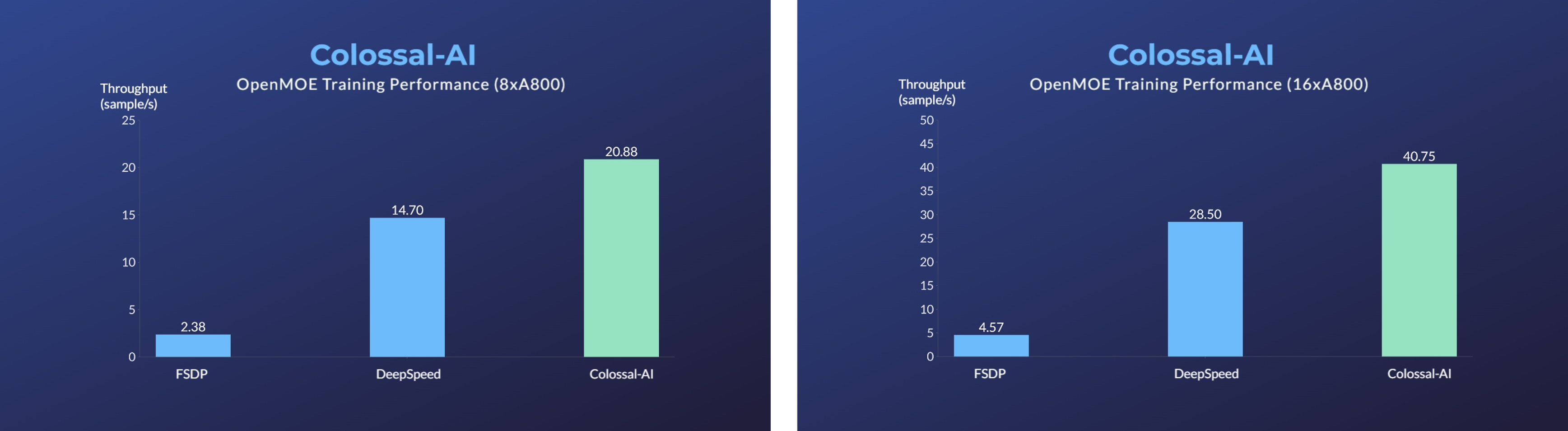
- Enhanced MoE parallelism, Open-source MoE model training can be 9 times more efficient [code] [blog]
GPT-3
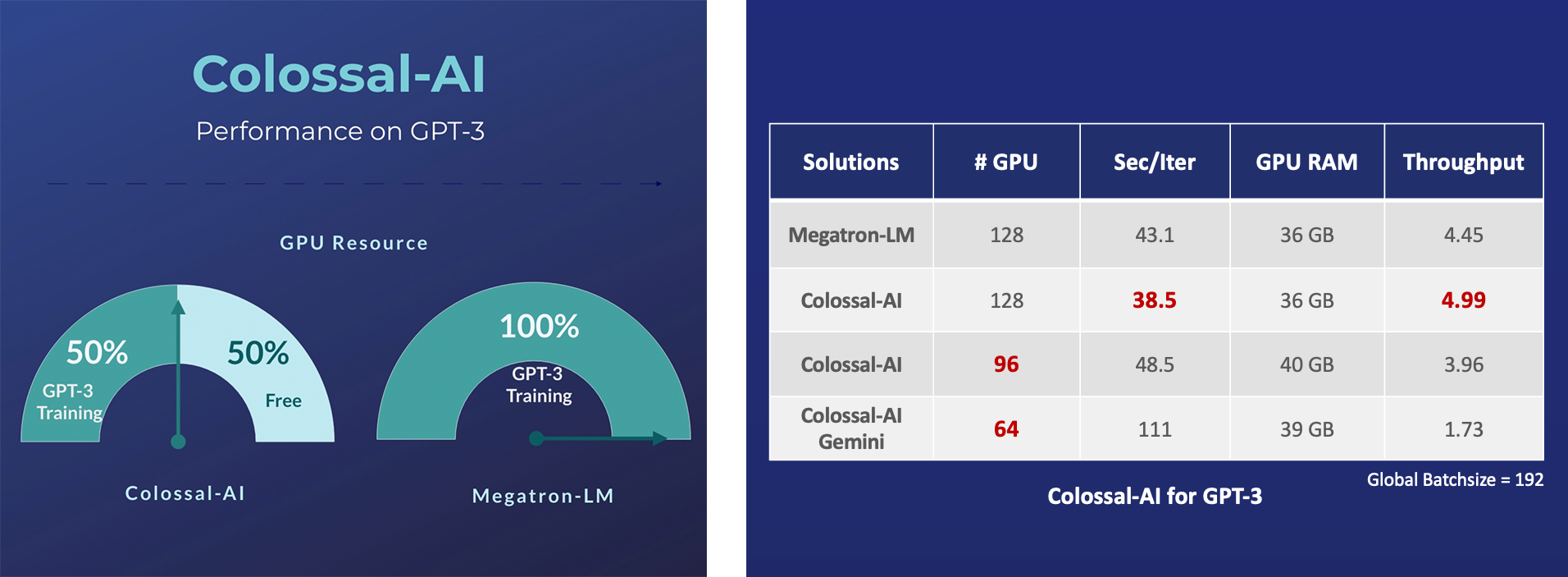
- Save 50% GPU resources and 10.7% acceleration
GPT-2
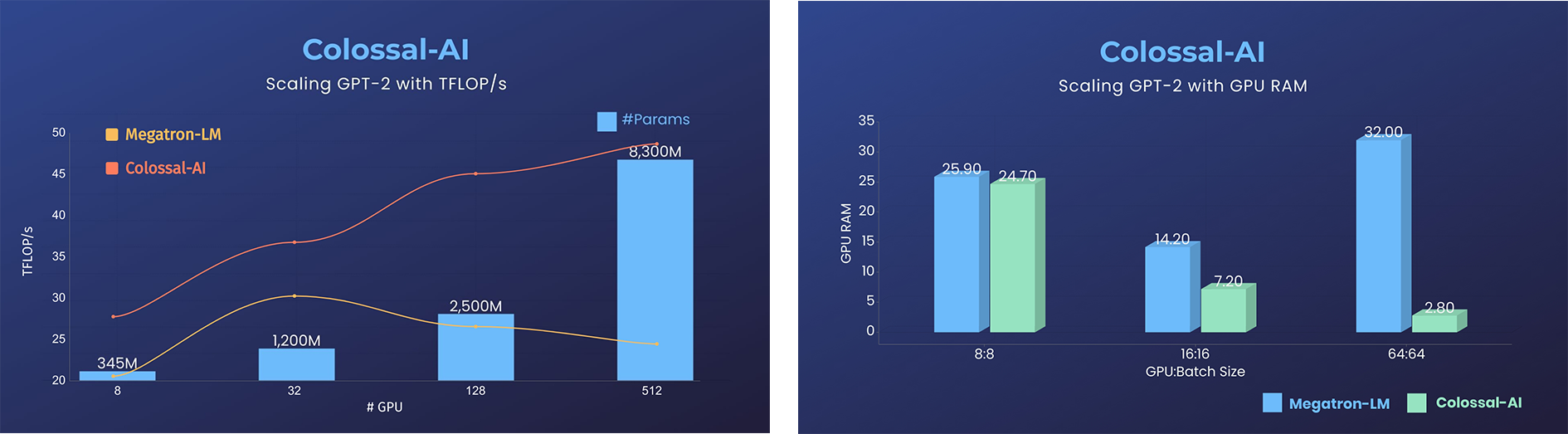
- 11x lower GPU memory consumption, and superlinear scaling efficiency with Tensor Parallelism
GPT-2.png)
- 24x larger model size on the same hardware
- over 3x acceleration
BERT
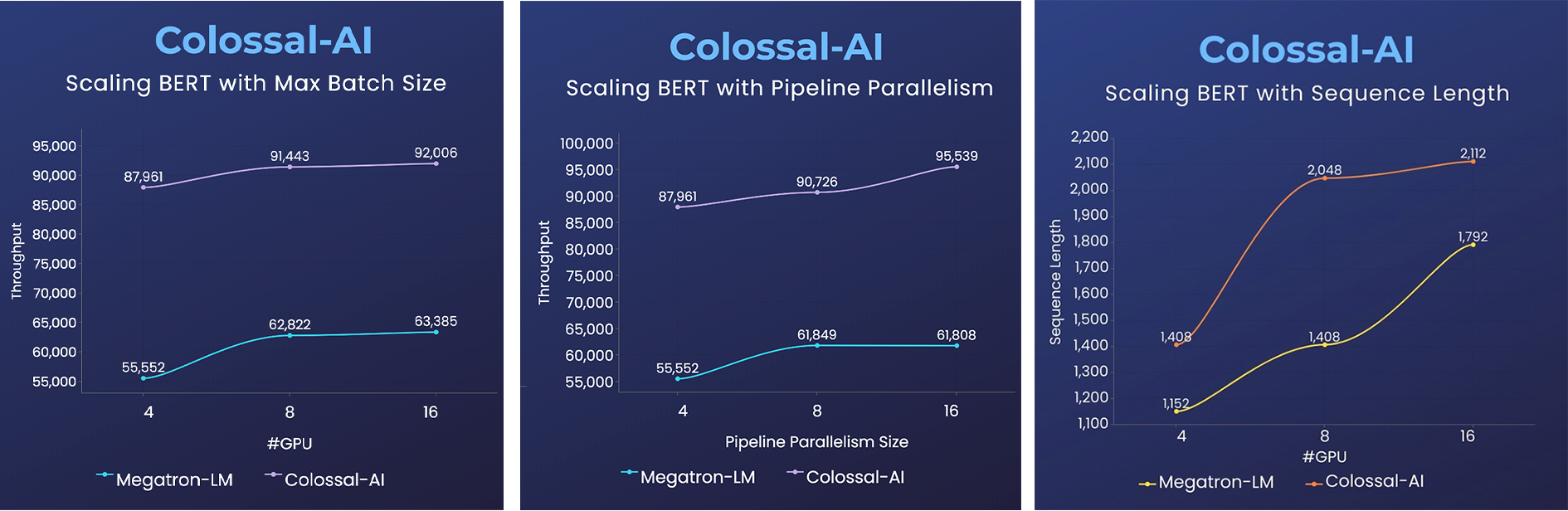
- 2x faster training, or 50% longer sequence length
PaLM
- PaLM-colossalai: Scalable implementation of Google's Pathways Language Model (PaLM).
OPT
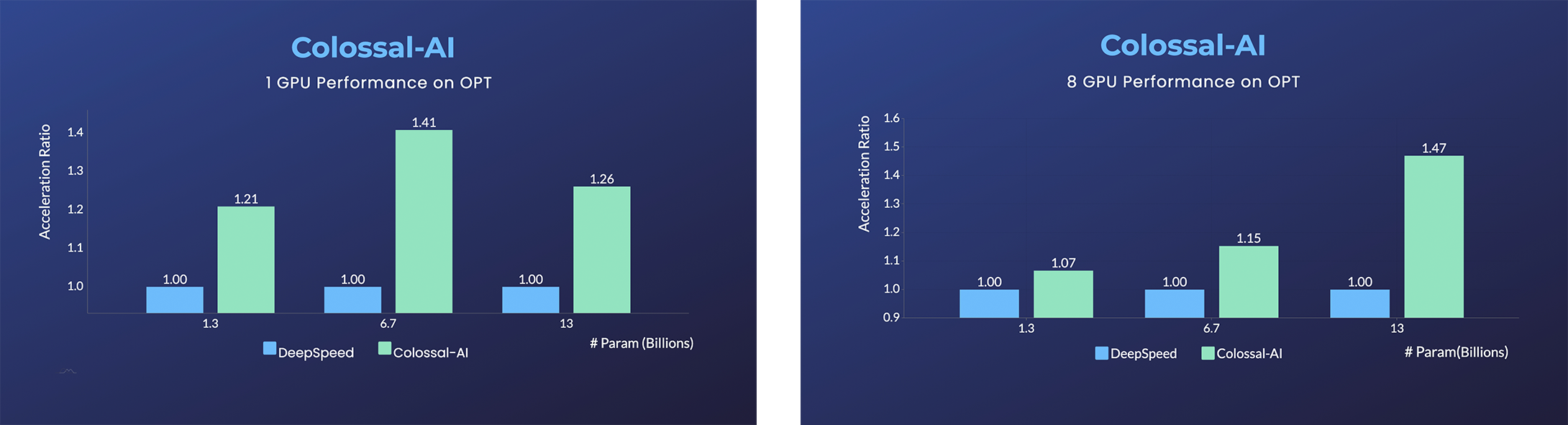
- Open Pretrained Transformer (OPT), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because of public pre-trained model weights.
- 45% speedup fine-tuning OPT at low cost in lines. [Example] [Online Serving]
Please visit our documentation and examples for more details.
ViT
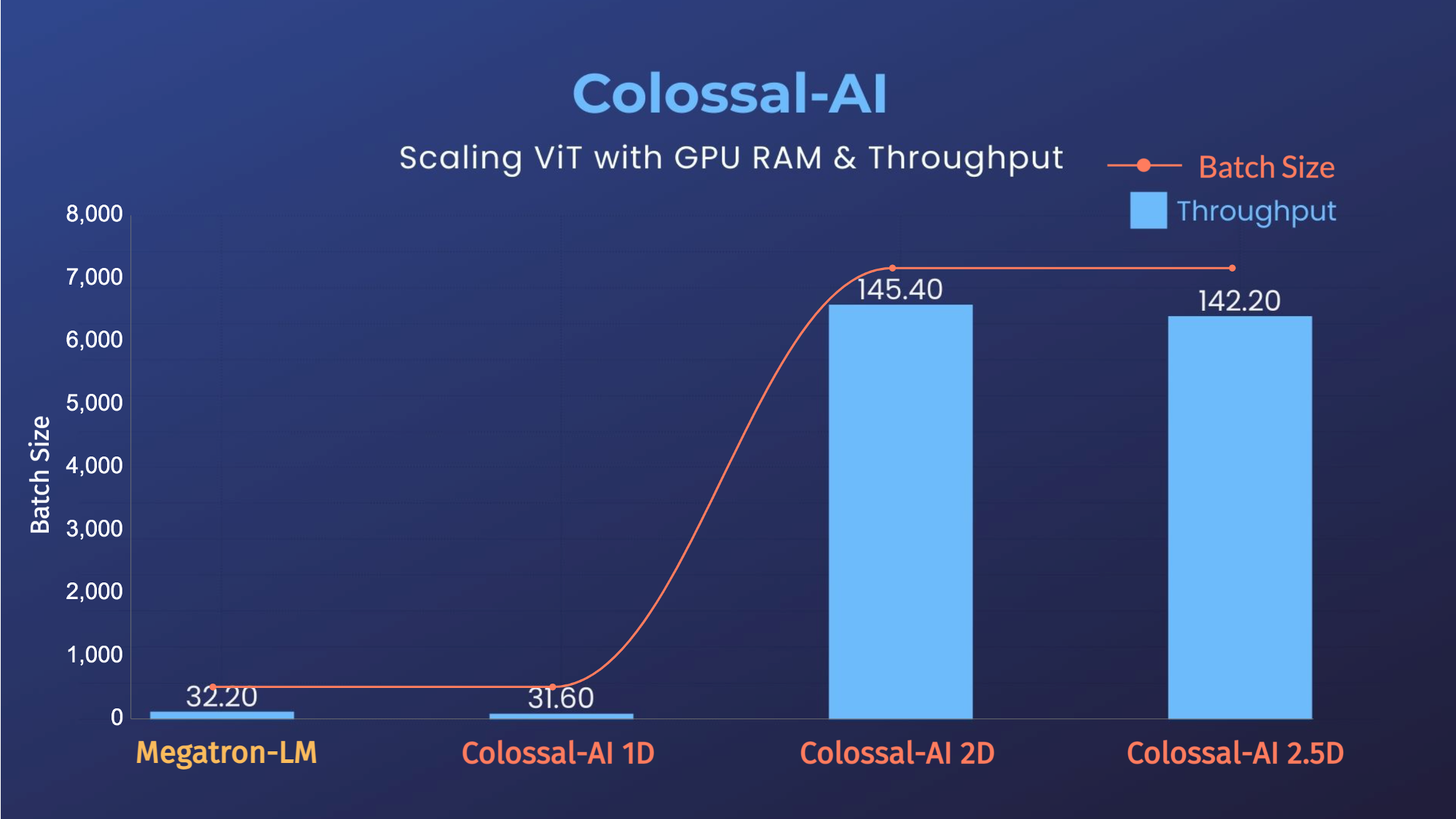
- 14x larger batch size, and 5x faster training for Tensor Parallelism = 64
Recommendation System Models
- Cached Embedding, utilize software cache to train larger embedding tables with a smaller GPU memory budget.
Single GPU Training Demo
GPT-2
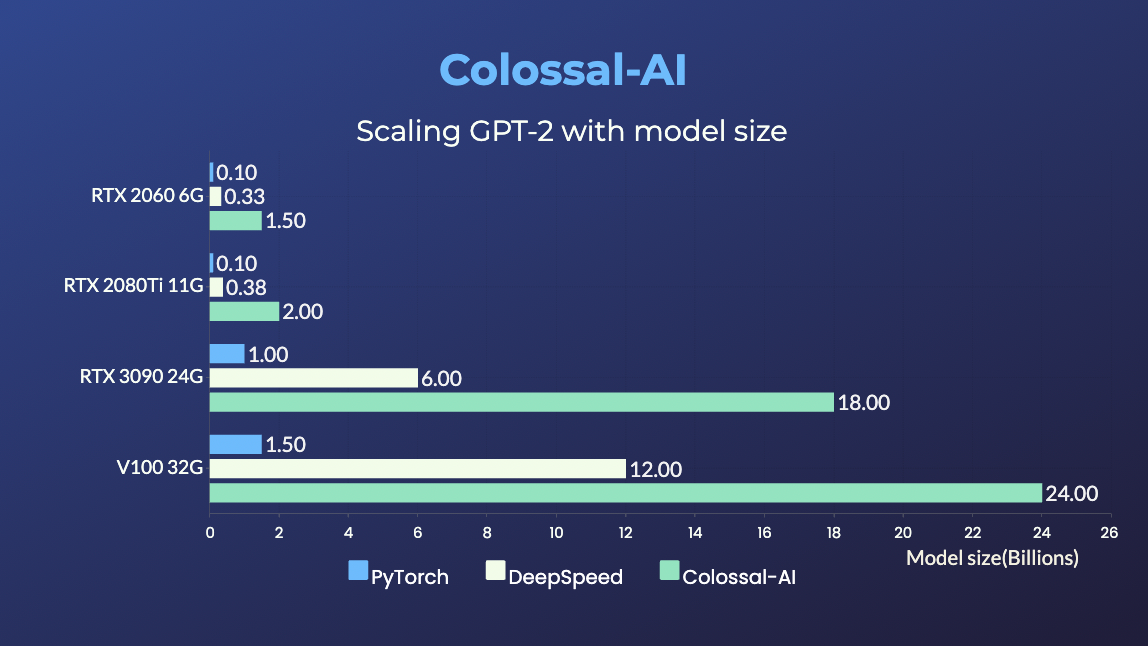
- 20x larger model size on the same hardware
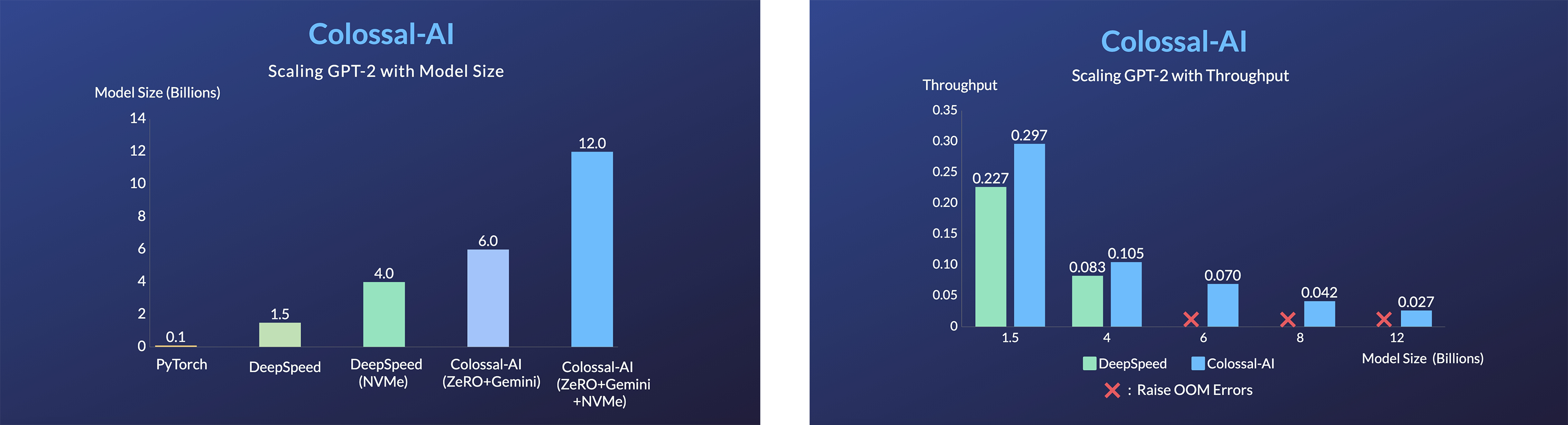
- 120x larger model size on the same hardware (RTX 3080)
PaLM
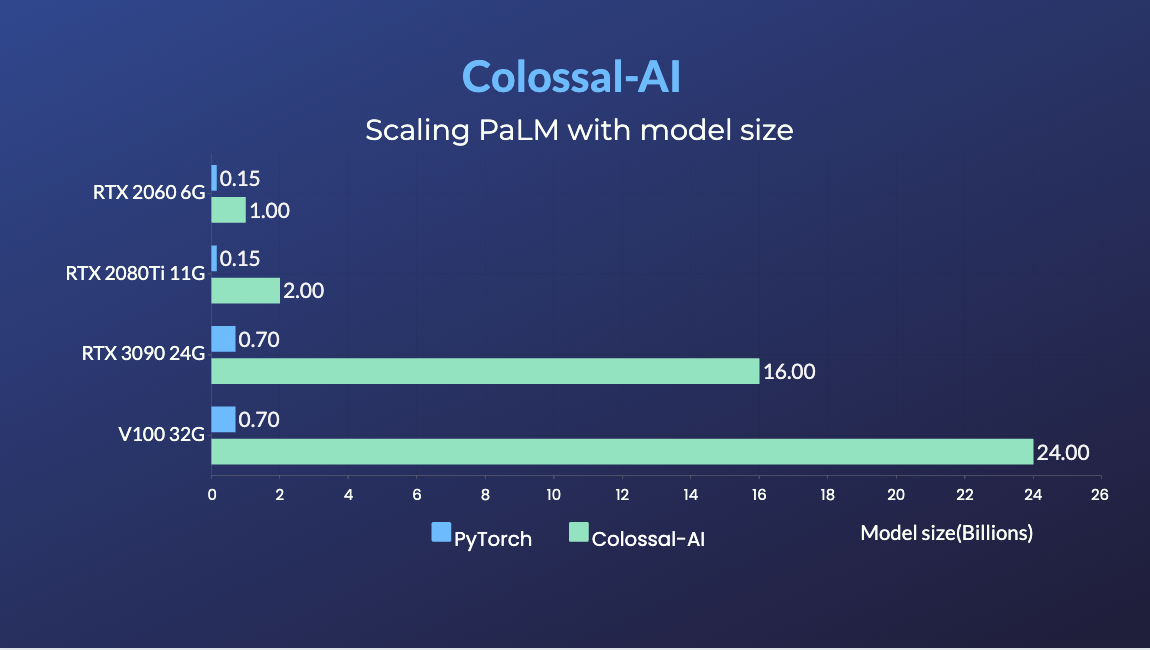
- 34x larger model size on the same hardware
Inference
Colossal-Inference
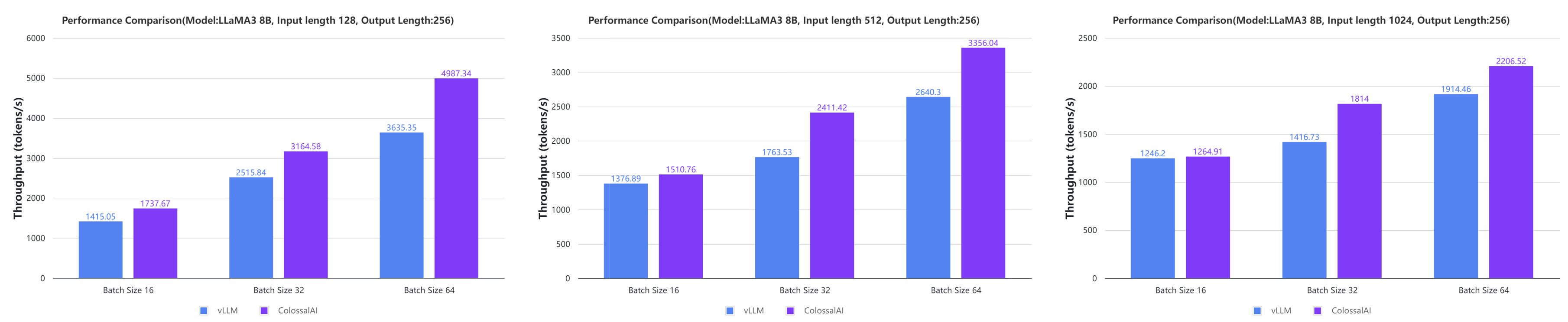
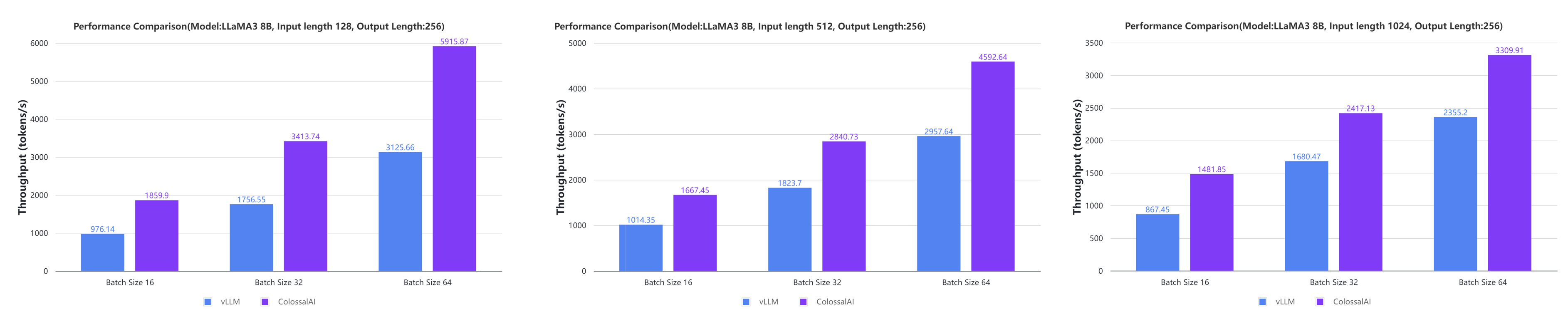
- Large AI models inference speed doubled, compared to the offline inference performance of vLLM in some cases. [code] [blog] [GPU Cloud Playground] [LLaMA3 Image]
Grok-1
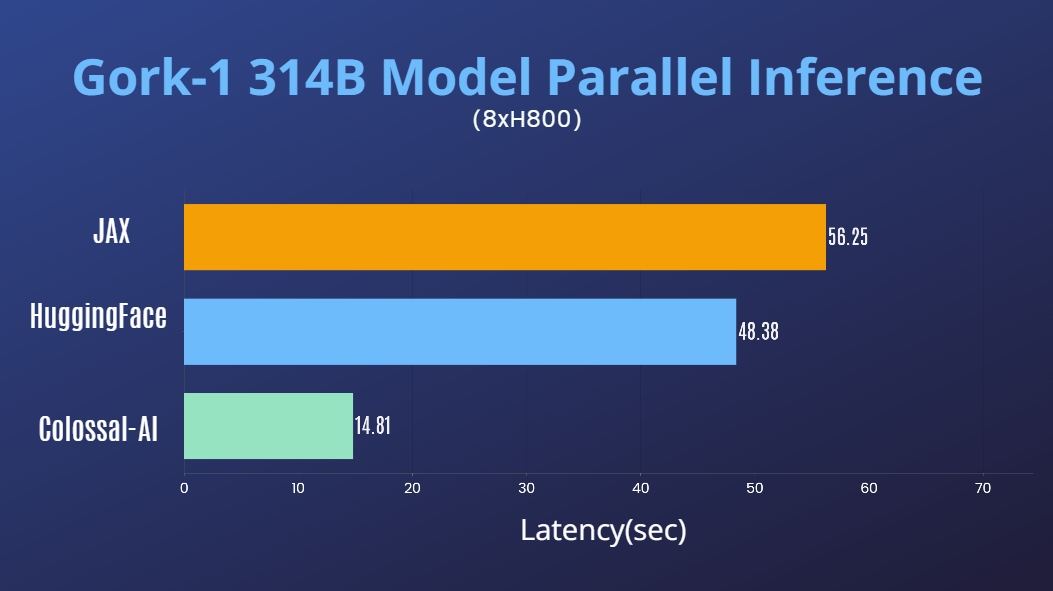
- 314 Billion Parameter Grok-1 Inference Accelerated by 3.8x, an easy-to-use Python + PyTorch + HuggingFace version for Inference.
[code] [blog] [HuggingFace Grok-1 PyTorch model weights] [ModelScope Grok-1 PyTorch model weights]
SwiftInfer
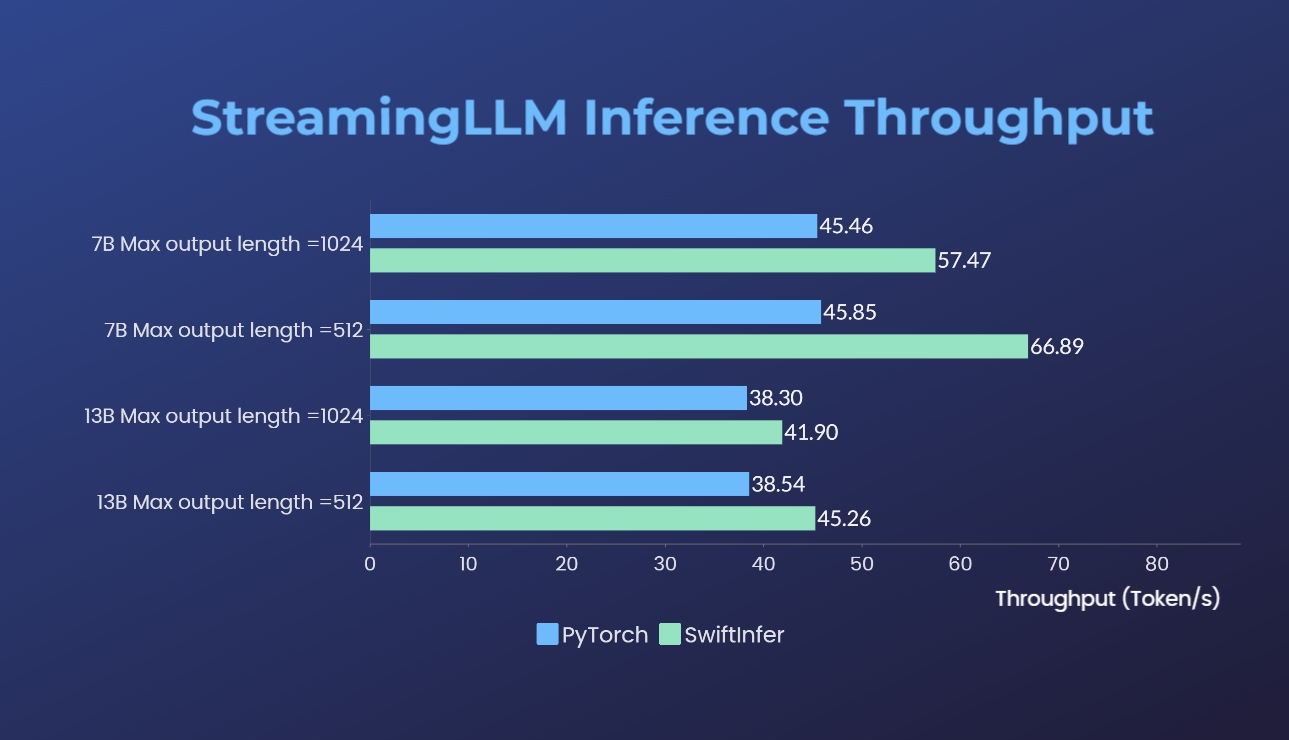
- SwiftInfer: Inference performance improved by 46%, open source solution breaks the length limit of LLM for multi-round conversations
Installation
Requirements:
- PyTorch >= 2.1
- Python >= 3.7
- CUDA >= 11.0
- NVIDIA GPU Compute Capability >= 7.0 (V100/RTX20 and higher)
- Linux OS
If you encounter any problem with installation, you may want to raise an issue in this repository.
Install from PyPI
You can easily install Colossal-AI with the following command. By default, we do not build PyTorch extensions during installation.
pip install colossalai
Note: only Linux is supported for now.
However, if you want to build the PyTorch extensions during installation, you can set BUILD_EXT=1.
BUILD_EXT=1 pip install colossalai
Otherwise, CUDA kernels will be built during runtime when you actually need them.
We also keep releasing the nightly version to PyPI every week. This allows you to access the unreleased features and bug fixes in the main branch. Installation can be made via
pip install colossalai-nightly
Download From Source
The version of Colossal-AI will be in line with the main branch of the repository. Feel free to raise an issue if you encounter any problems. :)
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# install colossalai
pip install .
By default, we do not compile CUDA/C++ kernels. ColossalAI will build them during runtime. If you want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
BUILD_EXT=1 pip install .
For Users with CUDA 10.2, you can still build ColossalAI from source. However, you need to manually download the cub library and copy it to the corresponding directory.
# clone the repository
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# download the cub library
wget https://github.com/NVIDIA/cub/archive/refs/tags/1.8.0.zip
unzip 1.8.0.zip
cp -r cub-1.8.0/cub/ colossalai/kernel/cuda_native/csrc/kernels/include/
# install
BUILD_EXT=1 pip install .
Use Docker
Pull from DockerHub
You can directly pull the docker image from our DockerHub page. The image is automatically uploaded upon release.
Build On Your Own
Run the following command to build a docker image from Dockerfile provided.
Building Colossal-AI from scratch requires GPU support, you need to use Nvidia Docker Runtime as the default when doing
docker build. More details can be found here. We recommend you install Colossal-AI from our project page directly.
cd ColossalAI
docker build -t colossalai ./docker
Run the following command to start the docker container in interactive mode.
docker run -ti --gpus all --rm --ipc=host colossalai bash
Community
Join the Colossal-AI community on Forum, Slack, and WeChat(微信) to share your suggestions, feedback, and questions with our engineering team.
Contributing
Referring to the successful attempts of BLOOM and Stable Diffusion, any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models!
You may contact us or participate in the following ways:
- Leaving a Star ⭐ to show your like and support. Thanks!
- Posting an issue, or submitting a PR on GitHub follow the guideline in Contributing
- Send your official proposal to email contact@hpcaitech.com
Thanks so much to all of our amazing contributors!
CI/CD
We leverage the power of GitHub Actions to automate our development, release and deployment workflows. Please check out this documentation on how the automated workflows are operated.
Cite Us
This project is inspired by some related projects (some by our team and some by other organizations). We would like to credit these amazing projects as listed in the Reference List.
To cite this project, you can use the following BibTeX citation.
@inproceedings{10.1145/3605573.3605613,
author = {Li, Shenggui and Liu, Hongxin and Bian, Zhengda and Fang, Jiarui and Huang, Haichen and Liu, Yuliang and Wang, Boxiang and You, Yang},
title = {Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
year = {2023},
isbn = {9798400708435},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3605573.3605613},
doi = {10.1145/3605573.3605613},
abstract = {The success of Transformer models has pushed the deep learning model scale to billions of parameters, but the memory limitation of a single GPU has led to an urgent need for training on multi-GPU clusters. However, the best practice for choosing the optimal parallel strategy is still lacking, as it requires domain expertise in both deep learning and parallel computing. The Colossal-AI system addressed the above challenge by introducing a unified interface to scale your sequential code of model training to distributed environments. It supports parallel training methods such as data, pipeline, tensor, and sequence parallelism and is integrated with heterogeneous training and zero redundancy optimizer. Compared to the baseline system, Colossal-AI can achieve up to 2.76 times training speedup on large-scale models.},
booktitle = {Proceedings of the 52nd International Conference on Parallel Processing},
pages = {766–775},
numpages = {10},
keywords = {datasets, gaze detection, text tagging, neural networks},
location = {Salt Lake City, UT, USA},
series = {ICPP '23}
}
Colossal-AI has been accepted as official tutorial by top conferences NeurIPS, SC, AAAI, PPoPP, CVPR, ISC, NVIDIA GTC ,etc.