* add assert for num of attention heads divisible by tp_size * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> |
||
|---|---|---|
| .. | ||
| examples | ||
| layer | ||
| modeling | ||
| policies | ||
| shard | ||
| README.md | ||
| __init__.py | ||
| _utils.py | ||
README.md
⚡️ ShardFormer
📚 Table of Contents
🔗 Introduction
Shardformer is a module that automatically parallelizes the mainstream models in libraries such as HuggingFace and TIMM. This module aims to make parallelization hassle-free for users who are not from the system background.
🔨 Usage
Quick Start
The sample API usage is given below(If you enable the use of flash attention, please install flash_attn. In addition, xformers's cutlass_op provide a supplementary optimization):
from colossalai.shardformer import ShardConfig, ShardFormer
from transformers import BertForMaskedLM
import colossalai
# launch colossalai
colossalai.launch_from_torch()
# create model
config = BertConfig.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased', config=config)
# create huggingface model as normal
shard_config = ShardConfig(tensor_parallel_process_group=tp_group,
pipeline_stage_manager=stage_manager,
enable_tensor_parallelism=True,
enable_fused_normalization=True,
enable_flash_attention=True,
enable_jit_fused=True,
enable_sequence_parallelism=True,
enable_sequence_overlap=True)
shard_former = ShardFormer(shard_config=shard_config)
sharded_model, shared_params = shard_former.optimize(model).to('cuda')
# do everything like normal
...
Following are the description ShardConfig's arguments:
-
tensor_parallel_process_group: The process group of tensor parallelism, it's necessary when using tensor parallel. Defaults to None, which is the global process group. -
pipeline_stage_manager: If using pipeline parallelism, it's necessary to specify a pipeline stage manager for inter-process communication in pipeline parallelism. Defaults to None, which means not using pipeline parallelism. -
enable_tensor_parallelism: Whether to use tensor parallelism. Defaults to True. -
enable_fused_normalization: Whether to use fused layernorm. Defaults to False. -
enable_flash_attention: Whether to switch on flash attention. Defaults to False. -
enable_jit_fused: Whether to switch on JIT fused operators. Defaults to False. -
enable_sequence_parallelism: Whether to turn on sequence parallelism, which partitions non-tensor-parallel regions along the sequence dimension. Defaults to False. -
enable_sequence_overlap: Whether to turn on sequence overlap, which overlap the computation and communication in sequence parallelism. It can only be used whenenable_sequence_parallelismis True. Defaults to False. -
enable_all_optimization: Whether to turn on all optimization tools includingfused normalization,flash attention,JIT fused operators,sequence parallelismandsequence overlap. Defaults to False. -
extra_kwargs: A dict to store extra kwargs for ShardFormer.
Write your own policy
If you have a custom model, you can also use Shardformer to parallelize it by writing your own sharding policy. More information about the sharding policy can be found in API Design.
from colossalai.shardformer import Policy
class MyPolicy(Policy):
# implement your own policy
...
# init model and shard former
...
# use customized policy to shard model
my_policy = MyPolicy()
shard_former.optimize(model, my_policy)
🗺 Roadmap
We will follow this roadmap to develop Shardformer:
- API Design
- API Implementation
- Unit Testing
- Policy Implementation
| model | tensor parallel | pipeline parallel | lazy initialization | xformer | flash attn2 | jit fused operator | fused layernorm | sequence parallel | overlap |
|---|---|---|---|---|---|---|---|---|---|
| bert | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [√] |
| t5 | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [ ] | [ ] |
| llama V1/V2 | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [ ] | [ ] |
| gpt2 | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [√] |
| opt | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [ ] | [ ] |
| bloom | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [√] |
| chatglm2 | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [√] | [√] |
| vit | [√] | [√] | [ ] | [√] | [√] | [√] | [√] | [ ] | [ ] |
| whisper | [√] | [√] | [√] | [√] | [√] | [ ] | [√] | [ ] | [ ] |
| sam | [√] | [ ] | [ ] | [√] | [√] | [√] | [√] | [ ] | [ ] |
| blip2 | [√] | [ ] | [ ] | [√] | [√] | [√] | [√] | [ ] | [ ] |
| falcon | [√] | [√] | [√] | [√] | [√] | [ ] | [√] | [ ] | [ ] |
| roberta | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| albert | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| ernie | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| gpt-neo | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| gpt-j | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| beit | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| swin | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| swin V2 | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| qwen | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] | [ ] |
| mistral | [√] | [ ] | [ ] | [√] | [√] | [√] | [√] | [ ] | [ ] |
💡 API Design
We will discuss the major components of ShardFormer below to help you better understand how things work.
This section serves as the design doc for Shardformer and the function signature might differ from the actual implementation.
Please refer to the code for more details.
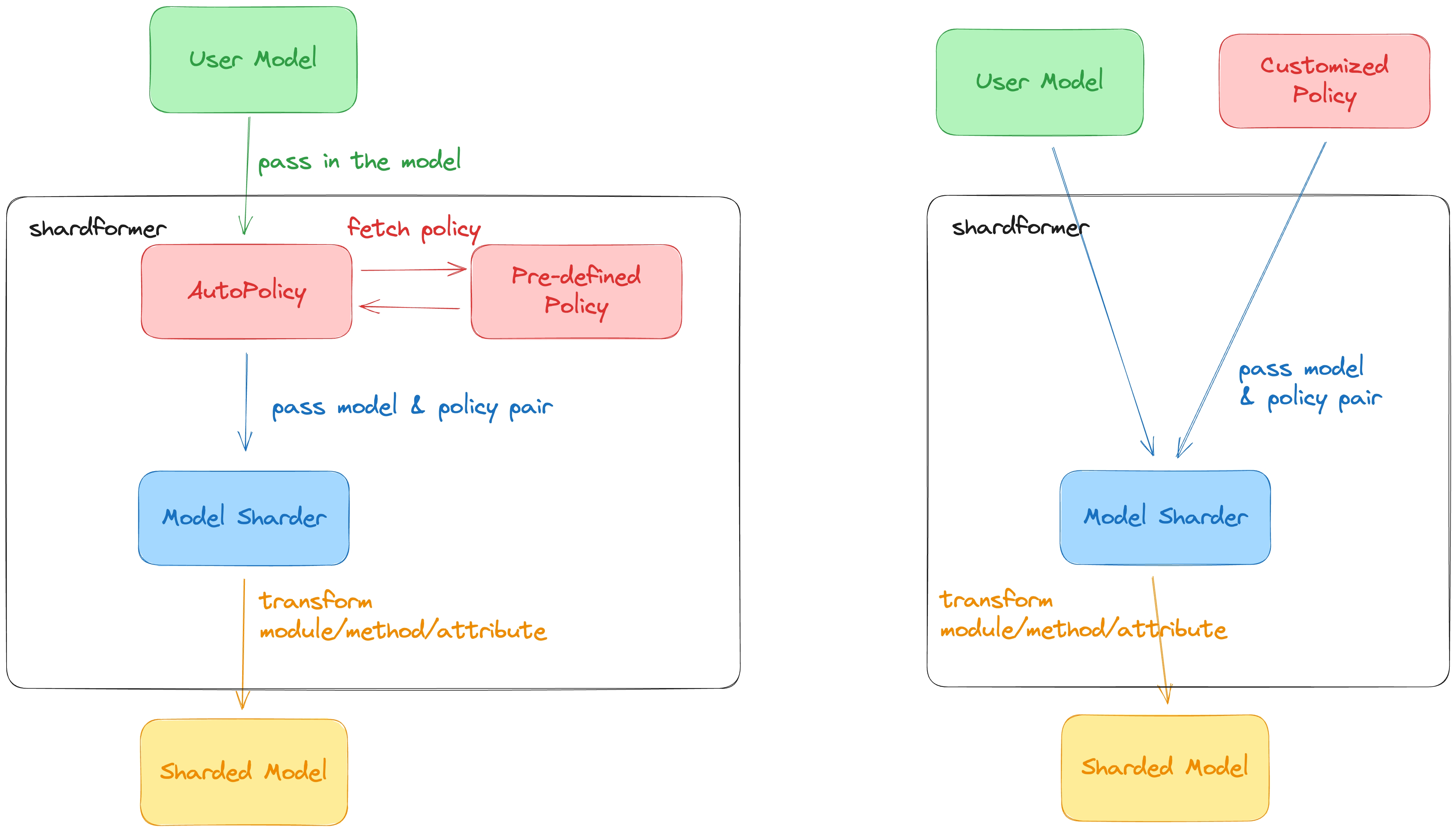
Distributed Modules
ShardFormer replaces the original PyTorch module with a distributed module.
The distributed module keeps the same attributes as the original module but replaces the original parameters with distributed parameters and defines a new forward function to execute distributed computation.
Each distributed module implements its from_native_module static method to convert the PyTorch module to its corresponding distributed module.
class ParallelModule(torch.nn.Module):
@abstractmethod
def from_native_module(module: torch.nn.Module, process_group: Union[ProcessGroup, Tuple[ProcessGroup]]) -> ParallelModule
"""
Convert a native module to a parallelized
Examples:
```python
# replace module
my_linear = Linear1D_Col.from_native_module(my_linear, process_group)
```
"""
Shard Config
ShardConfig is a simple data class to tell ShardFormer how sharding will be performed.
@dataclass
class ShardConfig:
tensor_parallel_process_group: ProcessGroup = None
enable_fused_normalization: bool = False
...
# Some possible future config fields
tensor_parallel_mode: Choice['1d', '2d', '2.5d', '3d'] # support different tensor parallel mode
use_flash_attention: bool # whether to use flash attention to speed up attention
extra_kwargs: Dict[str, Any] # extra kwargs for the shardformer
Policy
The Policy class describes how to handle the model sharding.
It is merely a description, the actual sharding will be performed by ModelSharder.
We abstract the policy into four stages:
- Preprocessing: call
Policy.preprocessto do some prior work before sharding, for example, resizing the embedding - Providing
ModulePolicyDescription: callPolicy.module_policyto get a bunch ofModulePolicyDescriptionto tellModelSharderhow the submodules's attributes, child parameters, and deeper submodules will be substituted. - Postprocessing: call
Policy.postprocessto perform some postprocessing work, for example, binding the embedding and classifier head weights of the BERT model.
@dataclass
class ModulePolicyDescription:
r"""
Describe how the attributes and parameters will be transformed in a policy.
Args:
attribute_replacement (Dict[str, Any]): key is the attribute name, value is the attribute value after sharding
param_replacement (List[Callable]): a list of functions to perform in-place param replacement. The function must receive only one arguments: module.
sub_module_replacement (List[SubModuleReplacementDescription]): each element in the list is a ParamReplacementDescription
object which specifies the module to be replaced and the target module used to replacement.
method_replace (Dict[str, Callable]): key is the method name, value is the method for replacement
"""
attribute_replacement: Dict[str, Any] = None
param_replacement: List[Callable] = None
sub_module_replacement: List[SubModuleReplacementDescription] = None
method_replacement: Dict[str, Callable] = None
@dataclass
class SubModuleReplacementDescription:
r"""
Describe how a submodule will be replaced
Args:
suffix (str): used to get the submodule object
target_module (ParallelModule): specifies the module class used to replace to submodule
kwargs (Dict[str, Any]): the dictionary used to pass extra arguments to the `ParallelModule.from_native_module` method.
ignore_if_not_exist (bool): if the submodule does not exist, ignore it or raise an exception
"""
suffix: str
target_module: ParallelModule
kwargs: Dict[str, Any] = None
ignore_if_not_exist: bool = False
class Policy(ABC):
r"""
The base class for all the policies. For each different model, it should have a different policy class,
like BertPolicy for Bert Model or OPTPolicy for OPT model.
Shardformer has provided many built-in sharding policies for the mainstream models. You can use the
built-in policies by setting `policy = None`, which is already the default argument for `Shardformer.optimize`.
If you want to define your own policy, you can inherit from this class and overwrite the methods you want to modify.
"""
def __init__(self)
self.model = None
def set_model(self, model: nn.Module) -> None:
"""
Set model as an attribute of the Policy object so that we can access the model's attributes.
"""
self.model = model
def set_shard_config(self, shard_config: ShardConfig) -> None:
r"""
Set shard config as an attribute of the Policy object.
Args:
shard_config (:class:`ShardConfig`): The shard config to be perform
"""
self.shard_config = shard_config
self.config_sanity_check()
@abstractmethod
def preprocess(self) -> nn.Module:
"""
Perform some preprocessing on the model, such as resizing the embedding size
"""
...
@abstractmethod
def module_policy(self) -> Dict[Union[str, nn.Module], ModulePolicyDescription]:
"""
Return the dict for the modify policy, the key is the original layer class and the value is the
argument for the modify layer
"""
...
@abstractmethods
def postprocess(self) -> nn.Module:
"""
Perform some postprocessing on the model, such as binding the embedding with the weight of the classifier head
"""
...
Model Sharder
ModelSharder is the class in charge of sharding the model based on the given policy.
class ModelSharder:
def __init__(self, model: torch.nn.Module, shard_config: ShardConfig, Policy: ShardPolicy = None):
#TODO: input is a cls or a obj
...
def shard(self) -> None:
"""
Shard model with parallelism with the help of pre-processing, replace_model_class, replace_module, and post-processing.
"""
...
def replace_module(self) -> None:
"""
Replace the layer according to the policy. Call Policy.module_policy() to get the module. Call _replace_module recursively.
"""
...
User-facing API
We only expose a limited number of APIs to the user to keep their user experience simple and clean.
class ShardFormer:
"""
Parallelize model based on the given config and policy
Example:
org_model = BertForMaskedLM.from_pretrained('bert-base-uncased')
shard_config = ShardConfig()
shard_former = ShardFormer(shard_config=shard_config)
model, shared_params = shard_former.optimize(org_model)
"""
def __init__(self, shard_config: ShardConfig):
"""
Do two things:
1. Create a distribute coordinator
2. serve as a store for shard config
"""
self.shard_config = shard_config
self.coordinator = DistCoordinator()
def optimize(self, model: nn.Module, policy: Policy = None) -> Tuple[nn.Module, List[Dict[int, Tensor]]]:
r"""
This method will optimize the model based on the given policy.
Args:
model (`torch.nn.Model`): the origin huggingface model
shard_config (`ShardConfig`): the config for distribute information
policy (`Policy`): the custom policy for sharding
Returns: the sharded model and the shared parameters
"""
sharder = ModelSharder(model=model, shard_config=self.shard_config, policy=policy)
shared_params = sharder.shard()
return model, shared_params
⌨️ Development Notes
Add New Policy to Shardformer
This section serves as the guideline for writing new policies and register them into shardformer.
- Step 1. Write your own model policy
You can create a new file in the colossalai/shardformer/policies folder and name the file with the model name. You can implement your policy in this file. You should not import the any model zoo library at the header section of the file because we do not want to import the library when we do not use the policy. Libraries such as transformers should be imported only in the function body when needed.
Please follow the following protocols when writing your policy:
-
You have to make a clear decision what you want to replace exactly in the original PyTorch module
- Use
ModulePolicyDescription.attribute_replacementto replace the module attributes - Use
ModulePolicyDescription.param_replacementto replace the module parameters - Use
ModulePolicyDescription.sub_module_replacementto replace the submodules completely. The target module should implement thefrom_native_modulefor the replacement. - Use
ModulePolicyDescription.method_replacementto replace the module methods. These replacement methods should be put in theshardformer/modeling/<model-name>.py.
- Use
-
You can implement the
ParallelModulefor primitive modules in theshardformer/layer/<model-name>.pyfile. Primitive modules refer to modules which are not composed of other modules. For example, thetorch.nn.Linearmodule is a primitive module while modules such asBertEncodermodule in thetransformerslibrary is a composite module. Primitive modules do not nested innernn.Modulemembers. For composite modules, you should consider usingModulePolicyDescriptionto implement your replacement. -
ParallelModuleis meant to be used in two ways:ParallelModule.from_native_moduleto convert native PyTorch module to theParallelModuleandParallelModule(...)to instantiate the module directly just like a normal PyTorch module.ParallelModuleshould be only implemented for modules whose weights are sharded. If you want to make your module compatible with theModulePolicyDescription.sub_module_replacementand there is no weight sharding in your module, you can just implement thefrom_native_modulemethod without inheriting theParallelModulelikecolossalai/shardformer/layer/normalization.py. -
Do not import any file in the
colossalai/shardformer/policiesandcolossalai/shardformer/modelingto avoid unwanted import error. For example, a file in these folders accidentally importstransformerslibrary at the top of the file, then the user will have to installtransformerslibrary even if they do not use this file. Any file in themodelingfolder should be only imported by the policy file. A policy implementation should be only imported dynamically via the autopolicy or manually via theShardFormermodule. -
Try to keep your import statement on third-party libraries such as
transformerswithin the function body instead of the header section of the file. This is because we do not want to import the library when we do not use the policy. -
Step 2. Register your policy to the autopolicy
Next, you need to register your policy in the colossalai/shardformer/policies/autopolicy.py file.
For example, if we register the policy for the BERT model, we just add a key-value in the _POLICY_LIST dictionary. The key if the qualname of the model object (you can get it by model.__class__.__qualname__). The value is a PolicyLocation object, which contains the file name and the class name of the policy. We do not import the policy directly because the policy file may contain libraries (such as transformers) which we do not want to import when we do not use the policy.
_POLICY_LIST = {
# BERT
"transformers.models.bert.modeling_bert.BertModel":
PolicyLocation(file_name="bert", class_name="BertModelPolicy"),
}
How to support those models in huggingface model hub but not in the transformers library
There are two cases:
- the modeling file is in the
transformerslibrary but the model weight is not in thetransformerslibrary. E.g. model structure of "01-ai/Yi-34B" is the same as LLaMA but the weight is not in thetransformerslibrary. In this case, we should support llama as usual and Yi-34B is also supported by the llama policy. We do not need to add a new policy for Yi-34B. - the modeling file is not in the
transformerslibrary, such as the "THUDM/chatglm2-6b".
Take "THUDM/chatglm2-6b" as an example, we clearly illustrate how to support this model in the shardformer.
Unlike llama which is in transformers library, we cannot import chatglm2 model directly. Thus, the key in policy should be str of class name, rather than class itself.
E.g. for llama:
policy[LlamaDecoderLayer] = ModulePolicyDescription(...)
for chatglm2:
policy["GLMBlock"] = ModulePolicyDescription(...)
Then when registering such models in the autopolicy, we should follow below format:
"transformers_modules.<modeling_filename>.<class_name>": PolicyLocation(
file_name="<policy_filename>", class_name="<policy_class_name>"
)
As for chatglm2 model, it should be:
"transformers_modules.modeling_chatglm.ChatGLMForConditionalGeneration": PolicyLocation(
file_name="chatglm2", class_name="ChatGLMForConditionalGenerationPolicy"
)
When using such models, AutoModel is supported as usual. The policy will be automatically loaded by the autopolicy.
Write Your Unit Testing
This section serves as the guideline for testing the shardformer module.
- Step 1. Add your model to the model zoo in the test kits.
Add your model to the tests/kit/model_zoo file. This allows you to define test-related components for this model. You can take tests/kit/model_zoo/transformers/llama.py as an example for reference.
- Step 2. Write your unit testing for the model
Next, implement your unit test in the tests/test_shardformer folder. Please refer to other similar tests for style consistency.
- Step 3. Execute your test
When you run tests locally, you should run tests for both your newly-added test file and the whole shardformer module tests.
# test for your own test file
pytest tests/test_shardformer/test_model/<your-file>.py
# test for the whole shardformer module
pytest tests/test_shardformer
📊 Benchmarking
System Performance
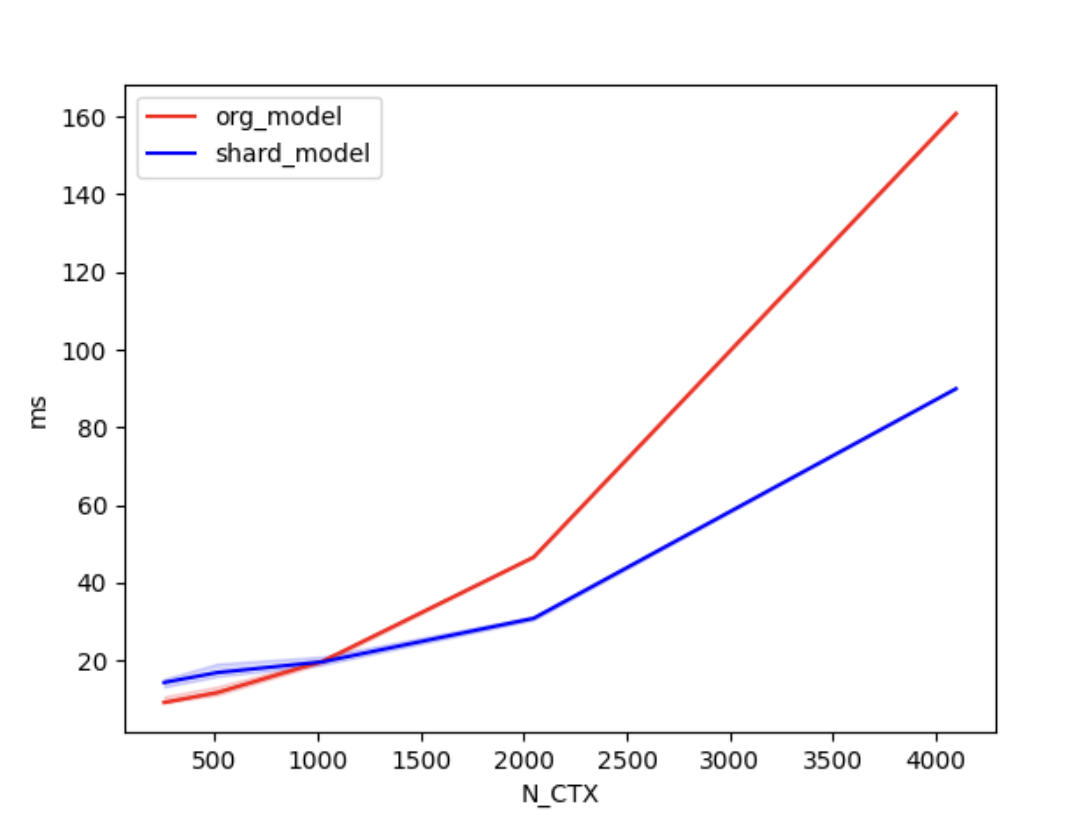
We conducted benchmark tests to evaluate the performance improvement of Shardformer. We compared the training time between the original model and the shard model.
We set the batch size to 4, the number of attention heads to 8, and the head dimension to 64. 'N_CTX' refers to the sequence length.
In the case of using 2 GPUs, the training times are as follows.
| N_CTX | org_model | shard_model |
|---|---|---|
| 256 | 11.2ms | 17.2ms |
| 512 | 9.8ms | 19.5ms |
| 1024 | 19.6ms | 18.9ms |
| 2048 | 46.6ms | 30.8ms |
| 4096 | 160.5ms | 90.4ms |
In the case of using 4 GPUs, the training times are as follows.
| N_CTX | org_model | shard_model |
|---|---|---|
| 256 | 10.0ms | 21.1ms |
| 512 | 11.5ms | 20.2ms |
| 1024 | 22.1ms | 20.6ms |
| 2048 | 46.9ms | 24.8ms |
| 4096 | 160.4ms | 68.0ms |
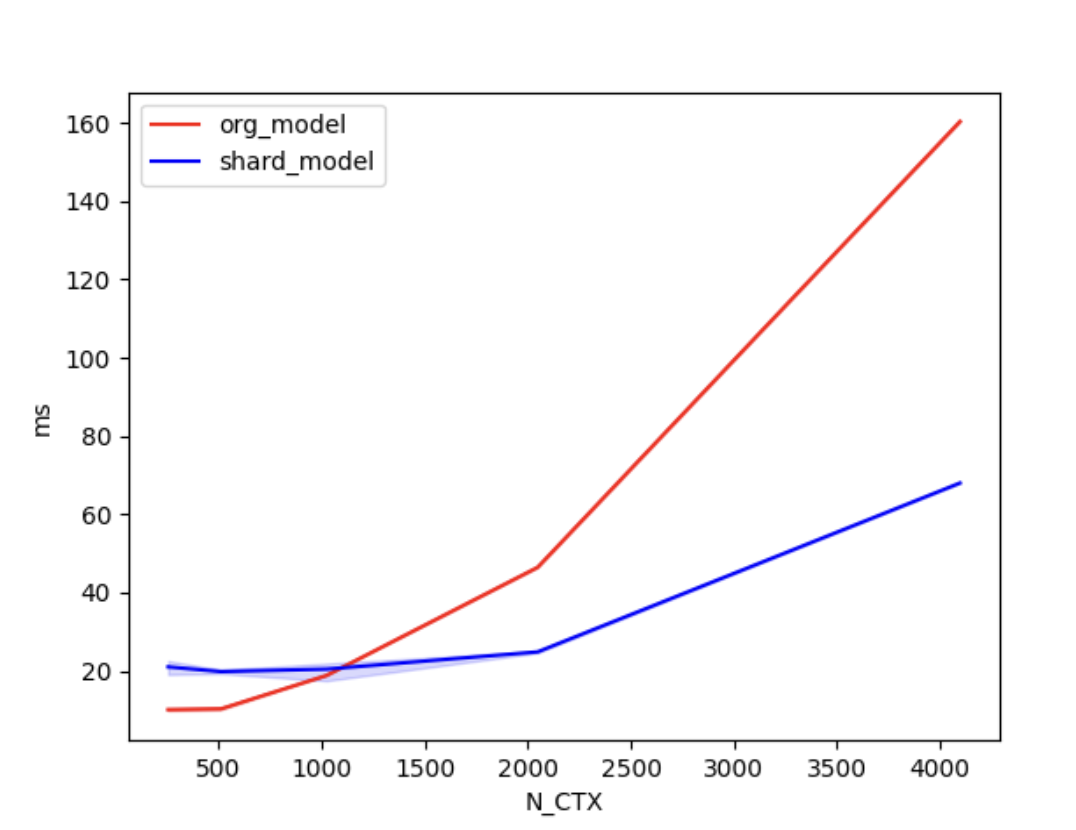
As shown in the figures above, when the sequence length is around 1000 or greater, the parallel optimization of Shardformer for long sequences starts to become evident.
Convergence
To validate that training the model using shardformers does not impact its convergence. We fine-tuned the BERT model using both shardformer and non-shardformer approaches. The example that utilizes Shardformer simultaneously with Pipeline Parallelism and Data Parallelism (Zero1). We then compared the accuracy, loss, and F1 score of the training results.
the configurations are as follows:
batch_size = 2
epoch = 3
lr = 2.4e-5
accumulation_steps = 8
warmup_fraction = 0.03
| accuracy | f1 | loss | GPU number | model sharded |
|---|---|---|---|---|
| 0.82971 | 0.87713 | 0.23194 | 4 | True |
| 0.83797 | 0.88006 | 0.22683 | 2 | True |
| 0.84521 | 0.88700 | 0.21822 | 1 | False |
Overall, the results demonstrate that using shardformers during model training does not affect the convergence.