8.2 KiB
NVMe offload
作者: Hongxin Liu
前置教程:
相关论文
- ZeRO-Offload: Democratizing Billion-Scale Model Training
- ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
引言
如果模型具有N个参数,在使用 Adam 时,优化器状态具有8N个参数。对于十亿规模的模型,优化器状态至少需要 32 GB 内存。 GPU显存限制了我们可以训练的模型规模,这称为GPU显存墙。如果我们将优化器状态 offload 到磁盘,我们可以突破 GPU 内存墙。
我们实现了一个用户友好且高效的异步 Tensor I/O 库:TensorNVMe。有了这个库,我们可以简单地实现 NVMe offload。
该库与各种磁盘(HDD、SATA SSD 和 NVMe SSD)兼容。由于 HDD 或 SATA SSD 的 I/O 带宽较低,建议仅在 NVMe 磁盘上使用此库。
在优化参数时,我们可以将优化过程分为三个阶段:读取、计算和 offload。我们以流水线的方式执行优化过程,这可以重叠计算和 I/O。
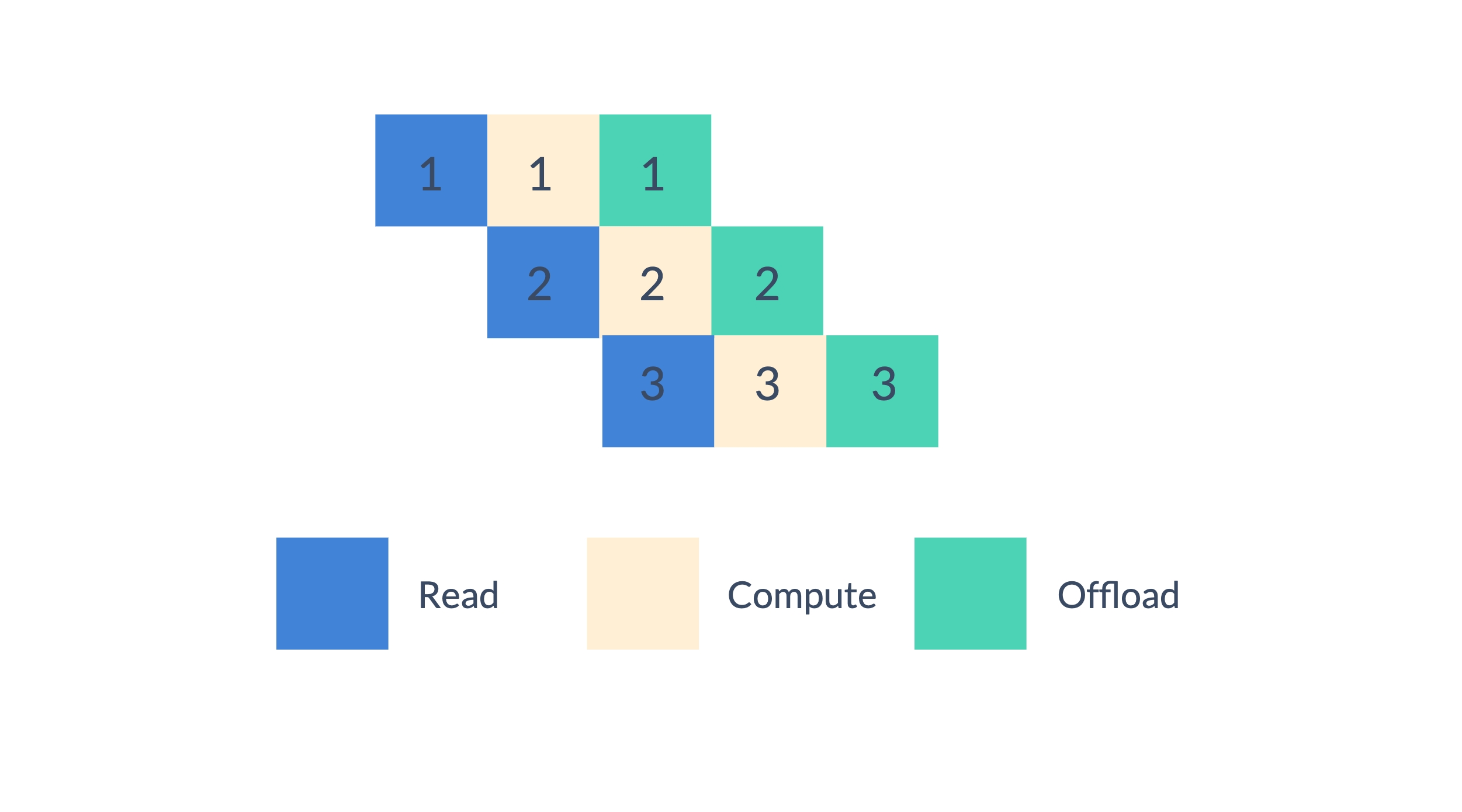
使用
首先,请确保您安装了 TensorNVMe:
pip install packaging
pip install tensornvme
我们为 Adam (CPUAdam 和 HybridAdam) 实现了优化器状态的 NVMe offload。
from colossalai.nn.optimizer import CPUAdam, HybridAdam
optimizer = HybridAdam(model.parameters(), lr=1e-3, nvme_offload_fraction=1.0, nvme_offload_dir='./')
nvme_offload_fraction 是要 offload 到 NVMe 的优化器状态的比例。 nvme_offload_dir 是保存 NVMe offload 文件的目录。如果 nvme_offload_dir 为 None,将使用随机临时目录。
它与 ColossalAI 中的所有并行方法兼容。
⚠ 它只会卸载在 CPU 上的优化器状态。这意味着它只会影响 CPU 训练或者使用卸载的 Zero/Gemini。
Examples
首先让我们从两个简单的例子开始 -- 用不同的方法训练 GPT。这些例子依赖transformers。
我们首先应该安装依赖:
pip install psutil transformers
首先,我们导入必要的包和模块:
import os
import time
from typing import Dict, Optional
import psutil
import torch
import torch.nn as nn
from transformers.models.gpt2.configuration_gpt2 import GPT2Config
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
import colossalai
from colossalai.nn.optimizer import HybridAdam
from colossalai.utils.model.colo_init_context import ColoInitContext
from colossalai.booster import Booster
from colossalai.booster.plugin import GeminiPlugin
然后我们定义一个损失函数:
class GPTLMLoss(nn.Module):
def __init__(self):
super().__init__()
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, logits, labels):
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
return self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)),
shift_labels.view(-1))
我们定义一些工具函数,用来生成随机数据、计算模型参数量和获取当前进程内存占用:
def get_data(batch_size: int, seq_len: int,
vocab_size: int, device: Optional[str] = None) -> Dict[str, torch.Tensor]:
device = torch.cuda.current_device() if device is None else device
input_ids = torch.randint(vocab_size, (batch_size, seq_len),
device=device)
attn_mask = torch.ones_like(input_ids)
return dict(input_ids=input_ids, attention_mask=attn_mask)
def get_model_numel(model: nn.Module) -> int:
return sum(p.numel() for p in model.parameters())
def get_mem_usage() -> int:
proc = psutil.Process(os.getpid())
return proc.memory_info().rss
我们首先尝试在 CPU 上训练 GPT 模型:
def train_cpu(nvme_offload_fraction: float = 0.0):
config = GPT2Config()
model = GPT2LMHeadModel(config)
criterion = GPTLMLoss()
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size, device='cpu')
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
print(f'Time: {time.time() - start:.3f} s')
print(f'Mem usage: {get_mem_usage() / 1024**2:.3f} MB')
不使用 NVME 卸载:
train_cpu(0.0)
我们可能得到如下输出:
Model numel: 0.116 B
[0] loss: 10.953
[1] loss: 10.974
[2] loss: 10.965
Time: 7.739 s
Mem usage: 5966.445 MB
然后使用(全量) NVME 卸载:
train_cpu(1.0)
我们可能得到:
Model numel: 0.116 B
[0] loss: 10.951
[1] loss: 10.994
[2] loss: 10.984
Time: 8.527 s
Mem usage: 4968.016 MB
对于有1.16亿参数的 GPT2-S 来说,它的优化器状态大约需要占用 0.928 GB 内存。NVME 卸载节省了大约 998 MB 内存,符合我们的预期。
然后我们可以用 Gemini 来训练 GPT 模型。放置策略应该设置为"auto"、 "cpu" 或 "const"。
def train_gemini_cpu(nvme_offload_fraction: float = 0.0):
colossalai.launch_from_torch({})
config = GPT2Config()
with ColoInitContext(device=torch.cuda.current_device()):
model = GPT2LMHeadModel(config)
criterion = GPTLMLoss()
optimizer = HybridAdam(model.parameters(), nvme_offload_fraction=nvme_offload_fraction)
print(f'Model numel: {get_model_numel(model) / 1024**3:.3f} B')
plugin = GeminiPlugin(
strict_ddp_mode=True,
device=torch.cuda.current_device(),
placement_policy='cpu',
pin_memory=True,
hidden_dim=config.n_embd,
initial_scale=2**5
)
booster = Booster(plugin)
model, optimizer, criterion, _* = booster.boost(model, optimizer, criterion)
start = time.time()
for step in range(3):
data = get_data(4, 128, config.vocab_size)
outputs = model(**data)
loss = criterion(outputs.logits, data['input_ids'])
booster.backward(loss, optimizer)
optimizer.step()
optimizer.zero_grad()
print(f'[{step}] loss: {loss.item():.3f}')
print(f'Time: {time.time() - start:.3f} s')
print(f'Mem usage: {get_mem_usage() / 1024**2:.3f} MB')
不使用 NVME 卸载:
train_gemini_cpu(0.0)
我们可能得到:
Model numel: 0.116 B
searching chunk configuration is completed in 0.27 s.
used number: 118.68 MB, wasted number: 0.75 MB
total wasted percentage is 0.63%
[0] loss: 10.953
[1] loss: 10.938
[2] loss: 10.969
Time: 2.997 s
Mem usage: 5592.227 MB
然后使用(全量) NVME 卸载:
train_gemini_cpu(1.0)
我们可能得到:
Model numel: 0.116 B
searching chunk configuration is completed in 0.27 s.
used number: 118.68 MB, wasted number: 0.75 MB
total wasted percentage is 0.63%
[0] loss: 10.953
[1] loss: 10.938
[2] loss: 10.969
Time: 3.691 s
Mem usage: 5298.344 MB
NVME 卸载节省了大约 294 MB 内存。注意使用 Gemini 的 pin_memory 功能可以加速训练,但是会增加内存占用。所以这个结果也是符合我们预期的。如果我们关闭 pin_memory,我们仍然可以观察到大约 900 MB 的内存占用下降。
API 参考
{{ autodoc:colossalai.nn.optimizer.HybridAdam }}
{{ autodoc:colossalai.nn.optimizer.CPUAdam }}