6.5 KiB
ColoTensor Concepts
Author: Jiarui Fang, Hongxin Liu and Haichen Huang
⚠️ 此页面上的信息已经过时并将被废弃。
Prerequisite:
Introduction
在ColossalAI 0.1.8 版本之后,ColoTensor 成为 ColossalAI 中张量的基本数据结构。 它是 torch.Tensor 的子类,可以当做 PyTorch Tensor使用。 此外,一些独特的功能使其能够表示一个payload分布在多个 GPU 设备上的Global Tensor,并提供一些列方式操作这个Global Tensor。 在 ColoTensor 的帮助下,用户可以以类似编写串行程序方式,编写的分布式 DNN 训练程序。
ColoTensor 包含额外的属性ColoTensorSpec 来描述张量的payload分布和计算模式。
- ProcessGroup:如何将进程组织为通信组。
- Distributed Spec:张量如何在进程组之间分布。
- Compute Spec:计算过程中如何使用张量。
我们一一详述。
ProcessGroup
ProcessGroup 类的一个实例描述了如何在进程组中组织进程。进程组内的进程可以一起参与同一个集合通信,比如allgather, allreduce等。进程组组织方式被张量的并行策略支配。比如,如果用户定义了Tensor的张量并行(TP),数据并行(DP)方式,那么进程组的进程组织方式将被自动推导出来。 进程组设置可能因不同的张量而异。 因此,它使我们能够支持更复杂的混合并行。流水线并行(PP)定义不在ProcessGroup中描述,它需要另一套机制,我们将在未来补充ColoTensor应用于PP的相关内容。
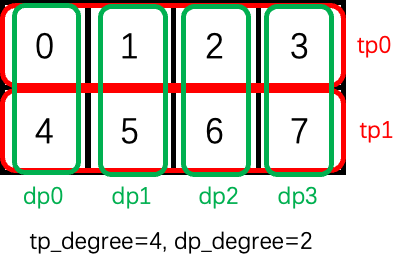
目前,ColoTensor 的一个进程组由 tp_degree 和 dp_degree 两种配置定义。 在 DP+TP 混合并行的情况下,可以将设备视为 2D 网格。 我们将 TP 通信组放置在设备网格的前导低维上,然后将数据并行组放置在设备网格的高维上。 原因是张量并行比数据并行具有更大的通信开销。 相邻设备放置在一个 TP 进程组内,并且通常放置在同一个节点中。
考虑到8个进程配置为tp_degree=4,dp_degree=2,布局如下图。 进程组 tp0 包含 gpu 0,1,2,3。 进程 dp1 包含 gpu 1 和 5。
Distributed Spec
Distributed Spec描述了 ColoTensor 如何在 ProcessGroup 中分布。
张量在 DP 进程组之间的分布方式是自动导出的,不需要用户手动指定。 如果这个张量是一个模型参数,它会在 DP 进程组中被复制。 如果是activation张量,则沿tensor最高维度在DP进程组中进行平均分割。
因此,在使用 Distributed Spec 时,我们只需要描述张量在 TP 进程组之间的分布方式即可。 TP 进程组目前有两种分布式规范,即 ShardSpec和ReplicaSpec。 ShardSpec 需要指定分区的维度索引 dim 和分区个数 num_partitions。 目前,我们仅支持在单个dim上进行拆分。 TP进程组上不同的dist spec可以通过set_dist_spec()接口相互转换。这些转化操作可以被记录在PyTorch的自动求导机制中,并在反向传播时候触发对应的反向操作。
Compute Spec
ComputeSpec类描述Tensor如何参与计算。目前,我们将作为module parameter的ColoTensor设置正确的Compute Pattern。可以触发正取的计算模式。具体应用方式我们会在接下来的文档中展示。
ColoParameter
ColoParameter是ColoTensor的子类。用来声明Parameter。他和ColoTensor关系和Torch.Tensor和torch.Parameter一致。后者可以让tensor出现在module的parameters()和name_parameters() 的返回值中。
Example
让我们看一个例子。 使用 tp_degree=4, dp_degree=2 在 8 个 GPU 上初始化并Shard一个ColoTensor。 然后tensor被沿着 TP 进程组中的最后一个维度进行分片。 最后,我们沿着 TP 进程组中的第一个维度(dim 0)对其进行重新Shard。 我们鼓励用户运行代码并观察每个张量的形状。
import torch
import torch.multiprocessing as mp
from colossalai.utils import print_rank_0
from functools import partial
import colossalai
from colossalai.tensor import ProcessGroup, ColoTensor, ColoTensorSpec, ShardSpec, ComputeSpec, ComputePattern
from colossalai.testing import spawn
import torch
def run_dist_tests(rank, world_size, port):
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
pg = ProcessGroup(tp_degree=2, dp_degree=2)
torch.manual_seed(0)
local_tensor = torch.randn(2, 3, 1).cuda()
print_rank_0(f"shape {local_tensor.shape}, {local_tensor.data}")
spec = ColoTensorSpec(pg, ShardSpec(dims=[-1], num_partitions=[pg.tp_world_size()]), ComputeSpec(ComputePattern.TP1D))
t1 = ColoTensor.from_torch_tensor(local_tensor, spec)
t1 = t1.to_replicate()
print_rank_0(f"shape {t1.shape}, {t1.data}")
spec2 = ShardSpec([0], [pg.tp_world_size()])
t1.set_dist_spec(spec2)
print_rank_0(f"shape {t1.shape}, {t1.data}")
def test_dist_cases(world_size):
spawn(run_dist_tests, world_size)
if __name__ == '__main__':
test_dist_cases(4)
:::caution
The ColoTensor is an experimental feature and may be updated.
:::