|
|
2 years ago | |
|---|---|---|
| .. | ||
| benchmarks | 2 years ago | |
| chatgpt | 2 years ago | |
| examples | 2 years ago | |
| tests | 2 years ago | |
| .gitignore | 2 years ago | |
| LICENSE | 2 years ago | |
| README.md | 2 years ago | |
| pytest.ini | 2 years ago | |
| requirements-test.txt | 2 years ago | |
| requirements.txt | 2 years ago | |
| setup.py | 2 years ago | |
| version.txt | 2 years ago | |
README.md
RLHF - Colossal-AI
Table of Contents
Intro
Implementation of RLHF (Reinforcement Learning with Human Feedback) powered by Colossal-AI. It supports distributed training and offloading, which can fit extremly large models. More details can be found in the blog.
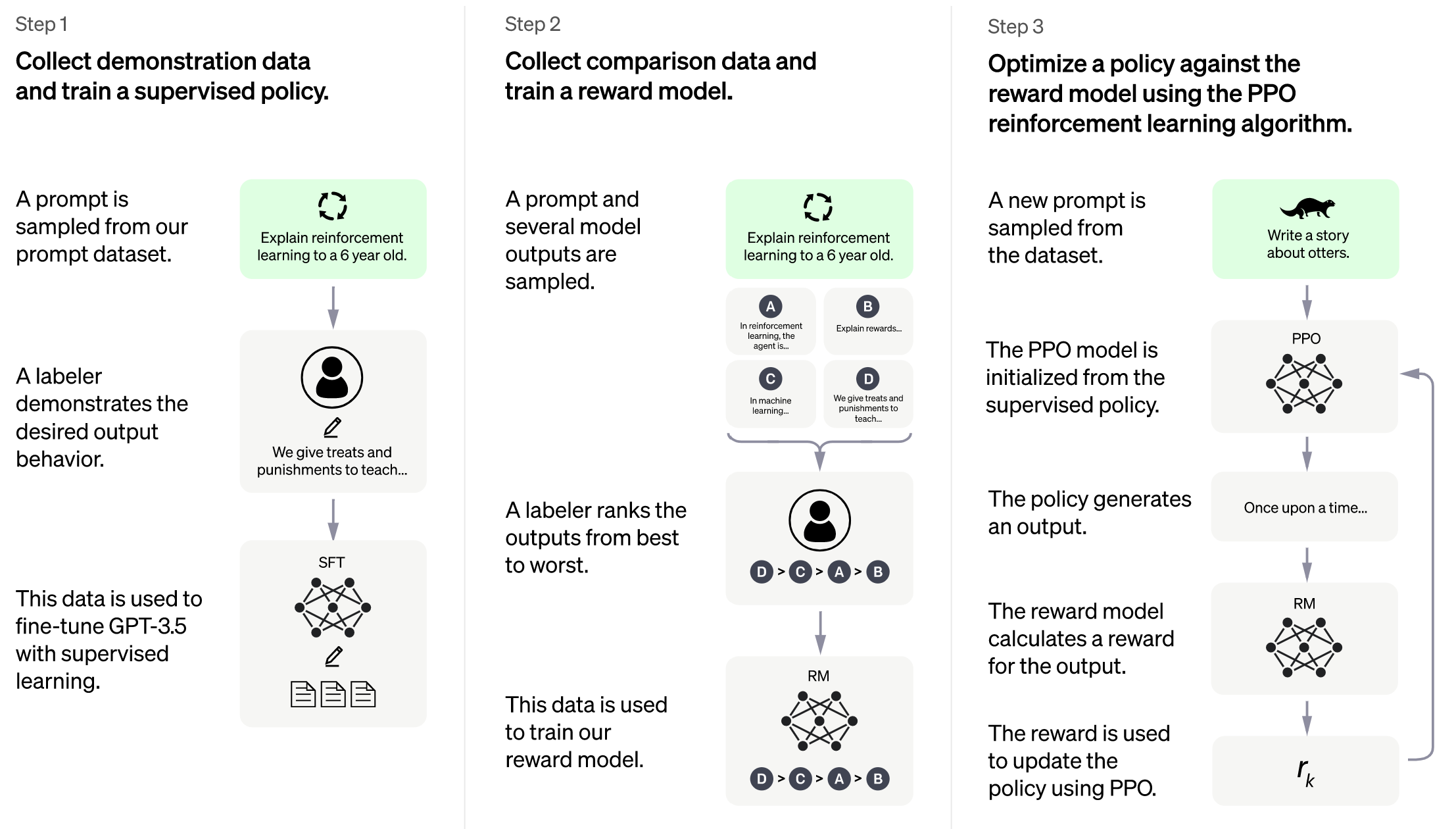
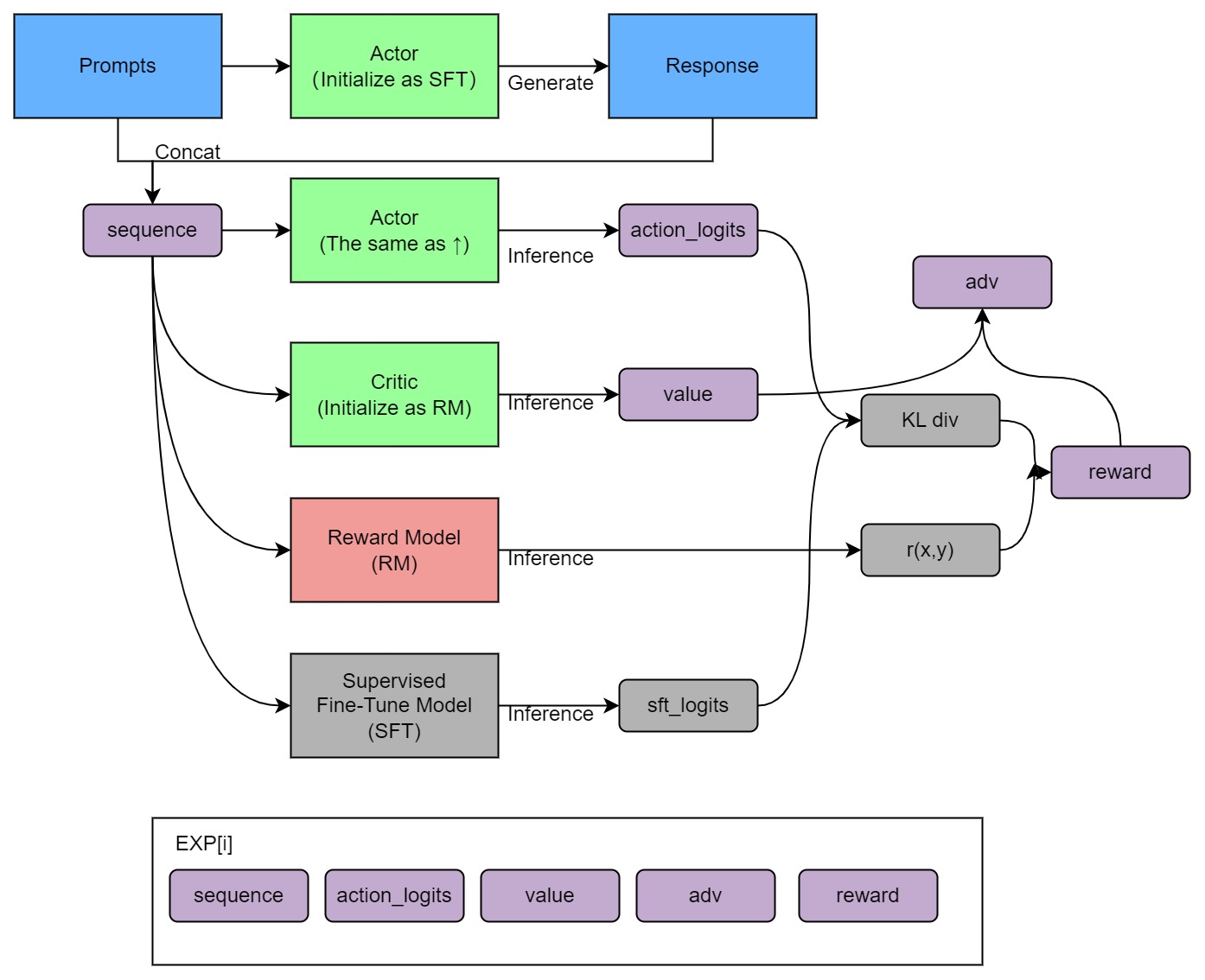
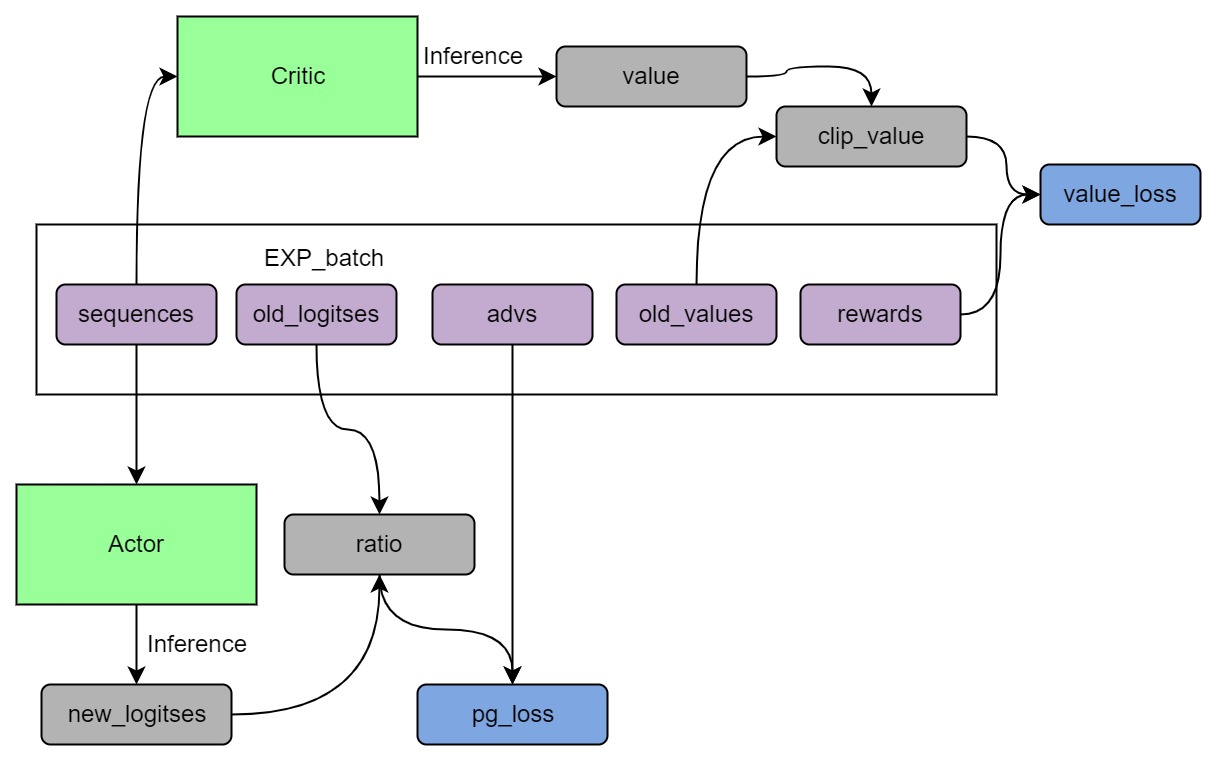
Training process (step 3)
Install
pip install .
Usage
The main entrypoint is Trainer. We only support PPO trainer now. We support many training strategies:
- NaiveStrategy: simplest strategy. Train on single GPU.
- DDPStrategy: use
torch.nn.parallel.DistributedDataParallel. Train on multi GPUs. - ColossalAIStrategy: use Gemini and Zero of ColossalAI. It eliminates model duplication on each GPU and supports offload. It's very useful when training large models on multi GPUs.
Simplest usage:
from chatgpt.trainer import PPOTrainer
from chatgpt.trainer.strategies import ColossalAIStrategy
from chatgpt.nn import GPTActor, GPTCritic, RewardModel
from copy import deepcopy
from colossalai.nn.optimizer import HybridAdam
strategy = ColossalAIStrategy()
with strategy.model_init_context():
# init your model here
# load pretrained gpt2
actor = GPTActor(pretrained='gpt2')
critic = GPTCritic()
initial_model = deepcopy(actor).cuda()
reward_model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).cuda()
actor_optim = HybridAdam(actor.parameters(), lr=5e-6)
critic_optim = HybridAdam(critic.parameters(), lr=5e-6)
# prepare models and optimizers
(actor, actor_optim), (critic, critic_optim), reward_model, initial_model = strategy.prepare(
(actor, actor_optim), (critic, critic_optim), reward_model, initial_model)
# load saved model checkpoint after preparing
strategy.load_model(actor, 'actor_checkpoint.pt', strict=False)
# load saved optimizer checkpoint after preparing
strategy.load_optimizer(actor_optim, 'actor_optim_checkpoint.pt')
trainer = PPOTrainer(strategy,
actor,
critic,
reward_model,
initial_model,
actor_optim,
critic_optim,
...)
trainer.fit(dataset, ...)
# save model checkpoint after fitting on only rank0
strategy.save_model(actor, 'actor_checkpoint.pt', only_rank0=True)
# save optimizer checkpoint on all ranks
strategy.save_optimizer(actor_optim, 'actor_optim_checkpoint.pt', only_rank0=False)
For more details, see examples/.
We also support training reward model with true-world data. See examples/train_reward_model.py.
FAQ
How to save/load checkpoint
To load pretrained model, you can simply use huggingface pretrained models:
# load OPT-350m pretrained model
actor = OPTActor(pretrained='facebook/opt-350m')
To save model checkpoint:
# save model checkpoint on only rank0
strategy.save_model(actor, 'actor_checkpoint.pt', only_rank0=True)
This function must be called after strategy.prepare().
For DDP strategy, model weights are replicated on all ranks. And for ColossalAI strategy, model weights may be sharded, but all-gather will be applied before returning state dict. You can set only_rank0=True for both of them, which only saves checkpoint on rank0, to save disk space usage. The checkpoint is float32.
To save optimizer checkpoint:
# save optimizer checkpoint on all ranks
strategy.save_optimizer(actor_optim, 'actor_optim_checkpoint.pt', only_rank0=False)
For DDP strategy, optimizer states are replicated on all ranks. You can set only_rank0=True. But for ColossalAI strategy, optimizer states are sharded over all ranks, and no all-gather will be applied. So for ColossalAI strategy, you can only set only_rank0=False. That is to say, each rank will save a cehckpoint. When loading, each rank should load the corresponding part.
Note that different stategy may have different shapes of optimizer checkpoint.
To load model checkpoint:
# load saved model checkpoint after preparing
strategy.load_model(actor, 'actor_checkpoint.pt', strict=False)
To load optimizer checkpoint:
# load saved optimizer checkpoint after preparing
strategy.load_optimizer(actor_optim, 'actor_optim_checkpoint.pt')
The Plan
- implement PPO fine-tuning
- implement training reward model
- support LoRA
- support inference
- open source the reward model weight
- support llama from facebook
- support BoN(best of N sample)
- implement PPO-ptx fine-tuning
- integrate with Ray
- support more RL paradigms, like Implicit Language Q-Learning (ILQL),
- support chain of throught by langchain
Real-time progress
You will find our progress in github project broad
Invitation to open-source contribution
Referring to the successful attempts of BLOOM and Stable Diffusion, any and all developers and partners with computing powers, datasets, models are welcome to join and build an ecosystem with Colossal-AI, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
You may contact us or participate in the following ways:
- Posting an issue or submitting a PR on GitHub
- Join the Colossal-AI community on Slack, and WeChat(微信) to share your ideas.
- Check out and fill in the cooperation proposal
- Send your proposal to email contact@hpcaitech.com
{kind=link}
Thanks so much to all of our amazing contributors!
Quick Preview

- Up to 7.73 times faster for single server training and 1.42 times faster for single-GPU inference
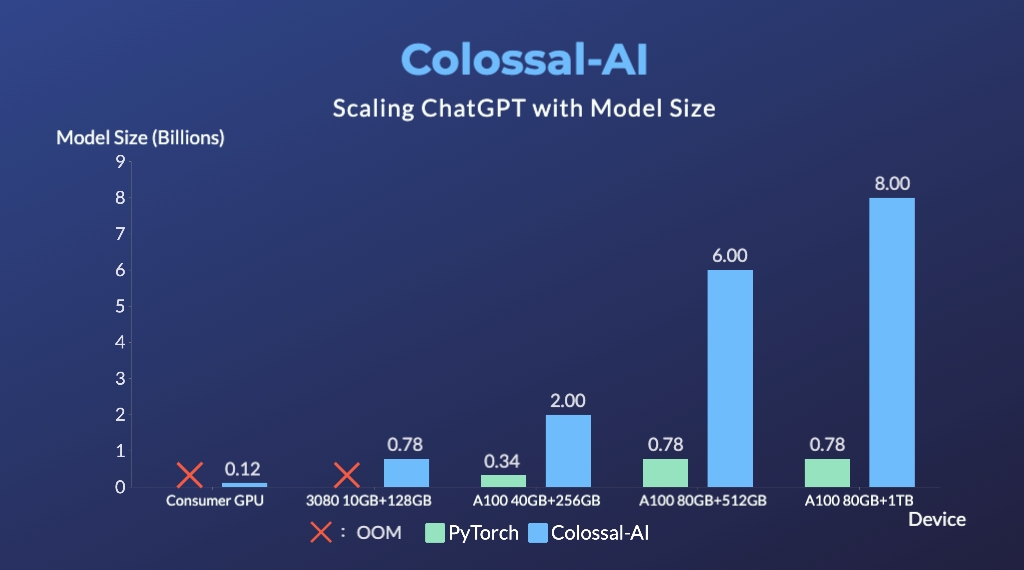
- Up to 10.3x growth in model capacity on one GPU
- A mini demo training process requires only 1.62GB of GPU memory (any consumer-grade GPU)
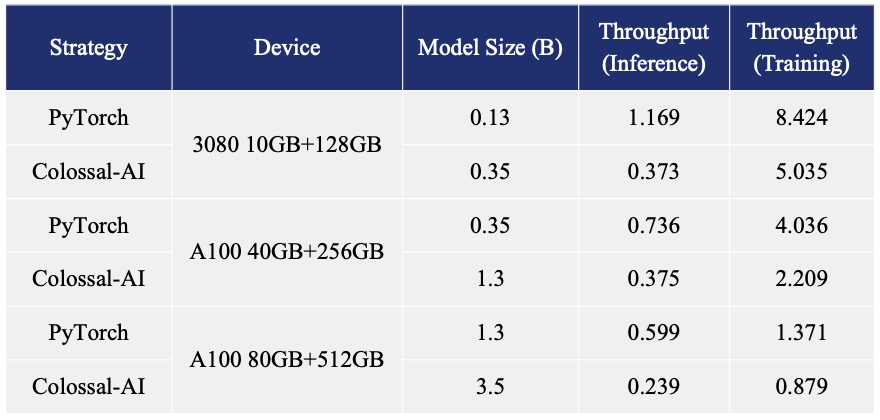
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
- Keep in a sufficiently high running speed
Citations
@article{Hu2021LoRALA,
title = {LoRA: Low-Rank Adaptation of Large Language Models},
author = {Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen},
journal = {ArXiv},
year = {2021},
volume = {abs/2106.09685}
}
@article{ouyang2022training,
title={Training language models to follow instructions with human feedback},
author={Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others},
journal={arXiv preprint arXiv:2203.02155},
year={2022}
}