4.2 KiB
Pretraining LLaMA-1/2/3: best practices for building LLaMA-1/2/3-like base models
LLaMA3
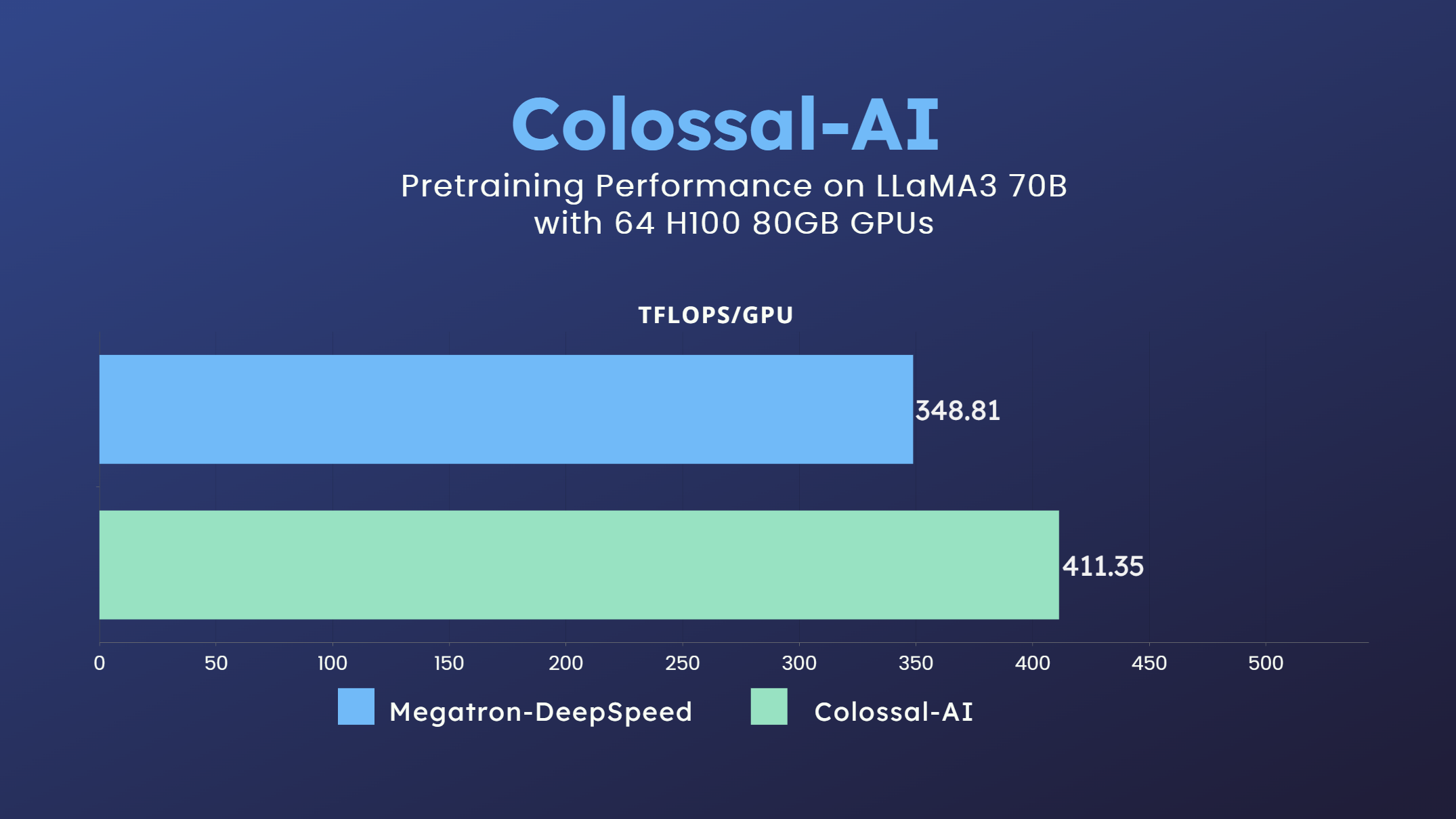
- 70 billion parameter LLaMA3 model training accelerated by 18%
LLaMA2
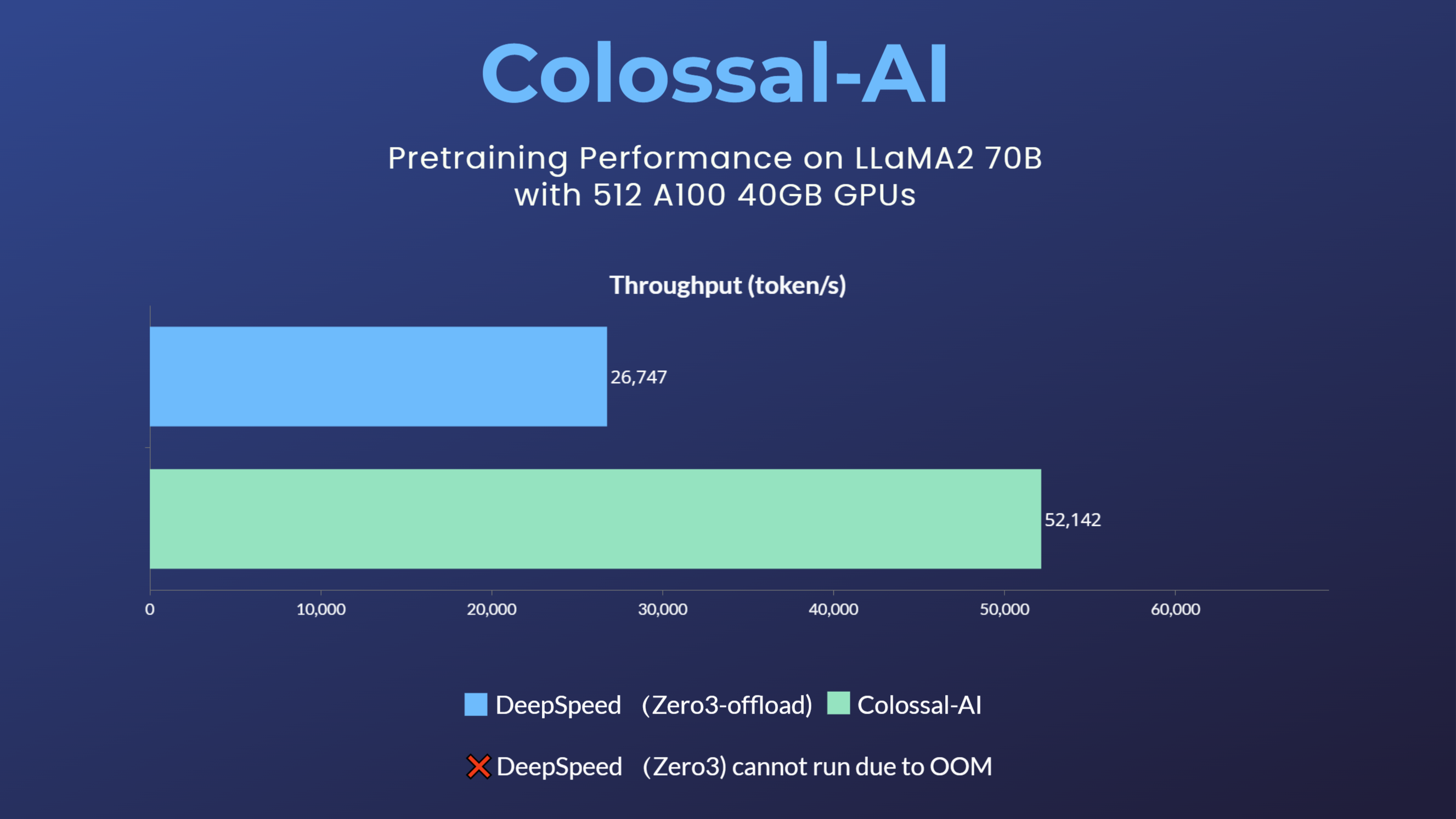
- 70 billion parameter LLaMA2 model training accelerated by 195% [blog]
LLaMA1
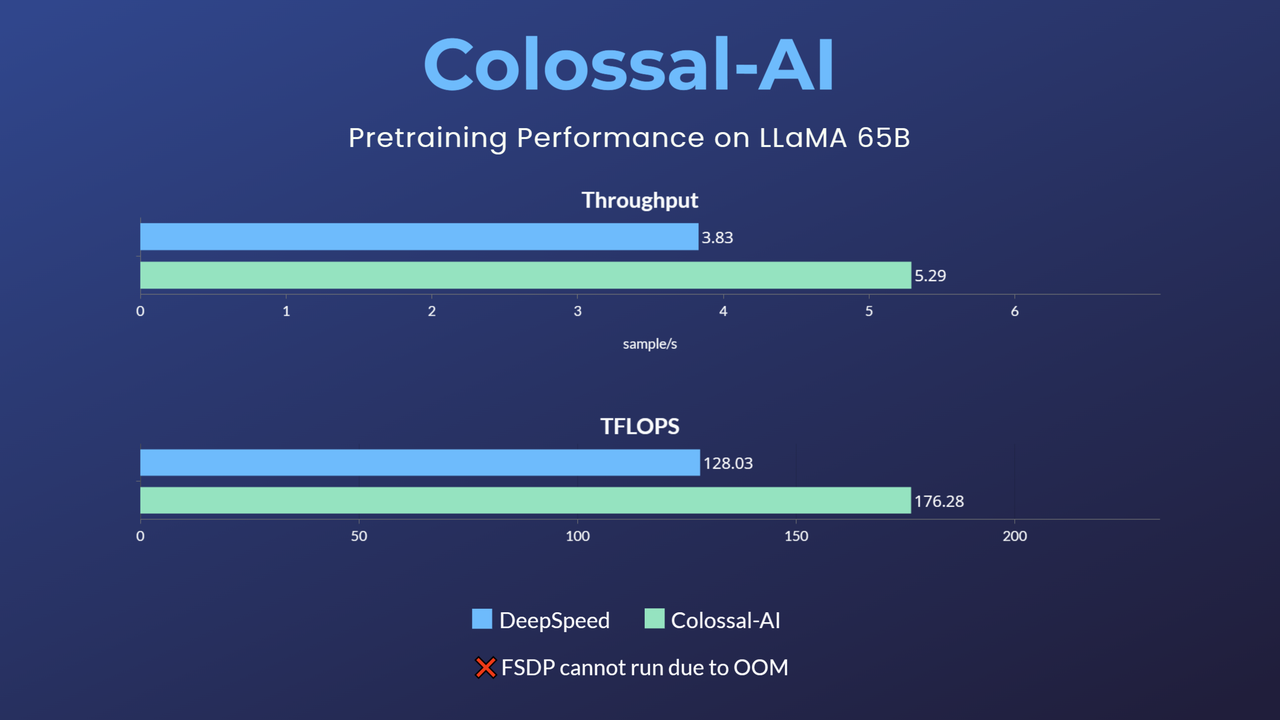
- 65-billion-parameter large model pretraining accelerated by 38% [blog]
Usage
⚠ This example only has benchmarking script. For training/finetuning, please refer to the applications/Colossal-LLaMA.
1. Installation
Please install the latest ColossalAI from source.
BUILD_EXT=1 pip install -U git+https://github.com/hpcaitech/ColossalAI
Then install other dependencies.
pip install -r requirements.txt
4. Shell Script Examples
For your convenience, we provide some shell scripts to run benchmark with various configurations.
You can find them in scripts/benchmark_7B and scripts/benchmark_70B directory. The main command should be in the format of:
colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
benchmark.py --OTHER_CONFIGURATIONS
Here we will show an example of how to run training
llama pretraining with gemini, batch_size=16, sequence_length=4096, gradient_checkpoint=True, flash_attn=True.
a. Running environment
This experiment was performed on 4 computing nodes with 32 A800/H800 80GB GPUs in total for LLaMA-1 65B or LLaMA-2 70B. The nodes are connected with RDMA and GPUs within one node are fully connected with NVLink.
b. Running command
cd scripts/benchmark_7B
First, put your host file (hosts.txt) in this directory with your real host ip or host name.
Here is a sample hosts.txt:
hostname1
hostname2
hostname3
hostname4
Then add environment variables to script if needed.
Finally, run the following command to start training:
bash gemini.sh
If you encounter out-of-memory(OOM) error during training with script gemini.sh, changing to script gemini_auto.sh might be a solution, since gemini_auto will set a upper limit on GPU memory usage through offloading part of the model parameters and optimizer states back to CPU memory. But there's a trade-off: gemini_auto.sh will be a bit slower, since more data are transmitted between CPU and GPU.
c. Results
If you run the above command successfully, you will get the following results:
max memory usage: 55491.10 MB, throughput: 24.26 samples/s, TFLOPS/GPU: 167.43.
Reference
@article{bian2021colossal,
title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
journal={arXiv preprint arXiv:2110.14883},
year={2021}
}
@software{openlm2023openllama,
author = {Geng, Xinyang and Liu, Hao},
title = {OpenLLaMA: An Open Reproduction of LLaMA},
month = May,
year = 2023,
url = {https://github.com/openlm-research/open_llama}
}
@software{together2023redpajama,
author = {Together Computer},
title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
month = April,
year = 2023,
url = {https://github.com/togethercomputer/RedPajama-Data}
}
@article{touvron2023llama,
title={Llama: Open and efficient foundation language models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}