* init
* rename and remove useless func
* basic chunk
* add evoformer
* align evoformer
* add meta
* basic chunk
* basic memory
* finish basic inference memory estimation
* finish memory estimation
* fix bug
* finish memory estimation
* add part of index tracer
* finish basic index tracer
* add doc string
* add doc str
* polish code
* polish code
* update active log
* polish code
* add possible region search
* finish region search loop
* finish chunk define
* support new op
* rename index tracer
* finishi codegen on msa
* redesign index tracer, add source and change compute
* pass outproduct mean
* code format
* code format
* work with outerproductmean and msa
* code style
* code style
* code style
* code style
* change threshold
* support check_index_duplicate
* support index dupilictae and update loop
* support output
* update memory estimate
* optimise search
* fix layernorm
* move flow tracer
* refactor flow tracer
* format code
* refactor flow search
* code style
* adapt codegen to prepose node
* code style
* remove abandoned function
* remove flow tracer
* code style
* code style
* reorder nodes
* finish node reorder
* update run
* code style
* add chunk select class
* add chunk select
* code style
* add chunksize in emit, fix bug in reassgin shape
* code style
* turn off print mem
* add evoformer openfold init
* init openfold
* add benchmark
* add print
* code style
* code style
* init openfold
* update openfold
* align openfold
* use max_mem to control stratge
* update source add
* add reorder in mem estimator
* improve reorder efficeincy
* support ones_like, add prompt if fit mode search fail
* fix a bug in ones like, dont gen chunk if dim size is 1
* fix bug again
* update min memory stratege, reduce mem usage by 30%
* last version of benchmark
* refactor structure
* restruct dir
* update test
* rename
* take apart chunk code gen
* close mem and code print
* code format
* rename ambiguous variable
* seperate flow tracer
* seperate input node dim search
* seperate prepose_nodes
* seperate non chunk input
* seperate reorder
* rename
* ad reorder graph
* seperate trace flow
* code style
* code style
* fix typo
* set benchmark
* rename test
* update codegen test
* Fix state_dict key missing issue of the ZeroDDP (#2363)
* Fix state_dict output for ZeroDDP duplicated parameters
* Rewrite state_dict based on get_static_torch_model
* Modify get_static_torch_model to be compatible with the lower version (ZeroDDP)
* update codegen test
* update codegen test
* add chunk search test
* code style
* add available
* [hotfix] fix gpt gemini example (#2404)
* [hotfix] fix gpt gemini example
* [example] add new assertions
* remove autochunk_available
* [workflow] added nightly release to pypi (#2403)
* add comments
* code style
* add doc for search chunk
* [doc] updated readme regarding pypi installation (#2406)
* add doc for search
* [doc] updated kernel-related optimisers' docstring (#2385)
* [doc] updated kernel-related optimisers' docstring
* polish doc
* rename trace_index to trace_indice
* rename function from index to indice
* rename
* rename in doc
* [polish] polish code for get_static_torch_model (#2405)
* [gemini] polish code
* [testing] remove code
* [gemini] make more robust
* rename
* rename
* remove useless function
* [worfklow] added coverage test (#2399)
* [worfklow] added coverage test
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* add doc for trace indice
* [docker] updated Dockerfile and release workflow (#2410)
* add doc
* update doc
* add available
* change imports
* add test in import
* [workflow] refactored the example check workflow (#2411)
* [workflow] refactored the example check workflow
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* Update parallel_context.py (#2408)
* [hotfix] add DISTPAN argument for benchmark (#2412)
* change the benchmark config file
* change config
* revert config file
* rename distpan to distplan
* [workflow] added precommit check for code consistency (#2401)
* [workflow] added precommit check for code consistency
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* adapt new fx
* [workflow] added translation for non-english comments (#2414)
* [setup] refactored setup.py for dependency graph (#2413)
* change import
* update doc
* [workflow] auto comment if precommit check fails (#2417)
* [hotfix] add norm clearing for the overflow step (#2416)
* [examples] adding tflops to PaLM (#2365)
* [workflow]auto comment with test coverage report (#2419)
* [workflow]auto comment with test coverage report
* polish code
* polish yaml
* [doc] added documentation for CI/CD (#2420)
* [doc] added documentation for CI/CD
* polish markdown
* polish markdown
* polish markdown
* [example] removed duplicated stable diffusion example (#2424)
* [zero] add inference mode and its unit test (#2418)
* [workflow] report test coverage even if below threshold (#2431)
* [example] improved the clarity yof the example readme (#2427)
* [example] improved the clarity yof the example readme
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* [ddp] add is_ddp_ignored (#2434)
[ddp] rename to is_ddp_ignored
* [workflow] make test coverage report collapsable (#2436)
* [autoparallel] add shard option (#2423)
* [fx] allow native ckpt trace and codegen. (#2438)
* [cli] provided more details if colossalai run fail (#2442)
* [autoparallel] integrate device mesh initialization into autoparallelize (#2393)
* [autoparallel] integrate device mesh initialization into autoparallelize
* add megatron solution
* update gpt autoparallel examples with latest api
* adapt beta value to fit the current computation cost
* [zero] fix state_dict and load_state_dict for ddp ignored parameters (#2443)
* [ddp] add is_ddp_ignored
[ddp] rename to is_ddp_ignored
* [zero] fix state_dict and load_state_dict
* fix bugs
* [zero] update unit test for ZeroDDP
* [example] updated the hybrid parallel tutorial (#2444)
* [example] updated the hybrid parallel tutorial
* polish code
* [zero] add warning for ignored parameters (#2446)
* [example] updated large-batch optimizer tutorial (#2448)
* [example] updated large-batch optimizer tutorial
* polish code
* polish code
* [example] fixed seed error in train_dreambooth_colossalai.py (#2445)
* [workflow] fixed the on-merge condition check (#2452)
* [workflow] automated the compatiblity test (#2453)
* [workflow] automated the compatiblity test
* polish code
* [autoparallel] update binary elementwise handler (#2451)
* [autoparallel] update binary elementwise handler
* polish
* [workflow] automated bdist wheel build (#2459)
* [workflow] automated bdist wheel build
* polish workflow
* polish readme
* polish readme
* Fix False warning in initialize.py (#2456)
* Update initialize.py
* pre-commit run check
* [examples] update autoparallel tutorial demo (#2449)
* [examples] update autoparallel tutorial demo
* add test_ci.sh
* polish
* add conda yaml
* [cli] fixed hostname mismatch error (#2465)
* [example] integrate autoparallel demo with CI (#2466)
* [example] integrate autoparallel demo with CI
* polish code
* polish code
* polish code
* polish code
* [zero] low level optim supports ProcessGroup (#2464)
* [example] update vit ci script (#2469)
* [example] update vit ci script
* [example] update requirements
* [example] update requirements
* [example] integrate seq-parallel tutorial with CI (#2463)
* [zero] polish low level optimizer (#2473)
* polish pp middleware (#2476)
Co-authored-by: Ziyue Jiang <ziyue.jiang@gmail.com>
* [example] update gpt gemini example ci test (#2477)
* [zero] add unit test for low-level zero init (#2474)
* [workflow] fixed the skip condition of example weekly check workflow (#2481)
* [example] stable diffusion add roadmap
* add dummy test_ci.sh
* [example] stable diffusion add roadmap (#2482)
* [CI] add test_ci.sh for palm, opt and gpt (#2475)
* polish code
* [example] titans for gpt
* polish readme
* remove license
* polish code
* update readme
* [example] titans for gpt (#2484)
* [autoparallel] support origin activation ckpt on autoprallel system (#2468)
* [autochunk] support evoformer tracer (#2485)
support full evoformer tracer, which is a main module of alphafold. previously we just support a simplifed version of it.
1. support some evoformer's op in fx
2. support evoformer test
3. add repos for test code
* [example] fix requirements (#2488)
* [zero] add unit testings for hybrid parallelism (#2486)
* [hotfix] gpt example titans bug #2493
* polish code and fix dataloader bugs
* [hotfix] gpt example titans bug #2493 (#2494)
* [fx] allow control of ckpt_codegen init (#2498)
* [fx] allow control of ckpt_codegen init
Currently in ColoGraphModule, ActivationCheckpointCodeGen will be set automatically in __init__. But other codegen can't be set if so.
So I add an arg to control whether to set ActivationCheckpointCodeGen in __init__.
* code style
* [example] dreambooth example
* add test_ci.sh to dreambooth
* [autochunk] support autochunk on evoformer (#2497)
* Revert "Update parallel_context.py (#2408)"
This reverts commit
|
||
|---|---|---|
| .. | ||
| auto_parallel | ||
| hybrid_parallel | ||
| large_batch_optimizer | ||
| opt | ||
| sequence_parallel | ||
| .gitignore | ||
| README.md | ||
| download_cifar10.py | ||
| requirements.txt | ||
README.md
Colossal-AI Tutorial Hands-on
Introduction
Welcome to the Colossal-AI tutorial, which has been accepted as official tutorials by top conference SC, AAAI, PPoPP, etc.
Colossal-AI, a unified deep learning system for the big model era, integrates many advanced technologies such as multi-dimensional tensor parallelism, sequence parallelism, heterogeneous memory management, large-scale optimization, adaptive task scheduling, etc. By using Colossal-AI, we could help users to efficiently and quickly deploy large AI model training and inference, reducing large AI model training budgets and scaling down the labor cost of learning and deployment.
🚀 Quick Links
Colossal-AI | Paper | Documentation | Forum | Slack
Table of Content
- Multi-dimensional Parallelism
- Know the components and sketch of Colossal-AI
- Step-by-step from PyTorch to Colossal-AI
- Try data/pipeline parallelism and 1D/2D/2.5D/3D tensor parallelism using a unified model
- Sequence Parallelism
- Try sequence parallelism with BERT
- Combination of data/pipeline/sequence parallelism
- Faster training and longer sequence length
- Large Batch Training Optimization
- Comparison of small/large batch size with SGD/LARS optimizer
- Acceleration from a larger batch size
- Auto-Parallelism
- Parallelism with normal non-distributed training code
- Model tracing + solution solving + runtime communication inserting all in one auto-parallelism system
- Try single program, multiple data (SPMD) parallel with auto-parallelism SPMD solver on ResNet50
- Fine-tuning and Serving for OPT
- Try pre-trained OPT model weights with Colossal-AI
- Fine-tuning OPT with limited hardware using ZeRO, Gemini and parallelism
- Deploy the fine-tuned model to inference service
Discussion
Discussion about the Colossal-AI project is always welcomed! We would love to exchange ideas with the community to better help this project grow. If you think there is a need to discuss anything, you may jump to our Slack.
If you encounter any problem while running these tutorials, you may want to raise an issue in this repository.
🛠️ Setup environment
You should use conda to create a virtual environment, we recommend python 3.8, e.g. conda create -n colossal python=3.8. This installation commands are for CUDA 11.3, if you have a different version of CUDA, please download PyTorch and Colossal-AI accordingly.
# install torch
# visit https://pytorch.org/get-started/locally/ to download other versions
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
# install latest ColossalAI
# visit https://colossalai.org/download to download corresponding version of Colossal-AI
pip install colossalai==0.1.11rc3+torch1.12cu11.3 -f https://release.colossalai.org
You can run colossalai check -i to verify if you have correctly set up your environment 🕹️.

If you encounter messages like please install with cuda_ext, do let me know as it could be a problem of the distribution wheel. 😥
Then clone the Colossal-AI repository from GitHub.
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI/examples/tutorial
🔥 Multi-dimensional Hybrid Parallel with Vision Transformer
- Go to hybrid_parallel folder in the tutorial directory.
- Install our model zoo.
pip install titans
- Run with synthetic data which is of similar shape to CIFAR10 with the
-sflag.
colossalai run --nproc_per_node 4 train.py --config config.py -s
- Modify the config file to play with different types of tensor parallelism, for example, change tensor parallel size to be 4 and mode to be 2d and run on 8 GPUs.
☀️ Sequence Parallel with BERT
- Go to the sequence_parallel folder in the tutorial directory.
- Run with the following command
export PYTHONPATH=$PWD
colossalai run --nproc_per_node 4 train.py -s
- The default config is sequence parallel size = 2, pipeline size = 1, let’s change pipeline size to be 2 and try it again.
📕 Large batch optimization with LARS and LAMB
- Go to the large_batch_optimizer folder in the tutorial directory.
- Run with synthetic data
colossalai run --nproc_per_node 4 train.py --config config.py -s
😀 Auto-Parallel Tutorial
- Go to the auto_parallel folder in the tutorial directory.
- Install
pulpandcoin-or-cbcfor the solver.
pip install pulp
conda install -c conda-forge coin-or-cbc
- Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py -s
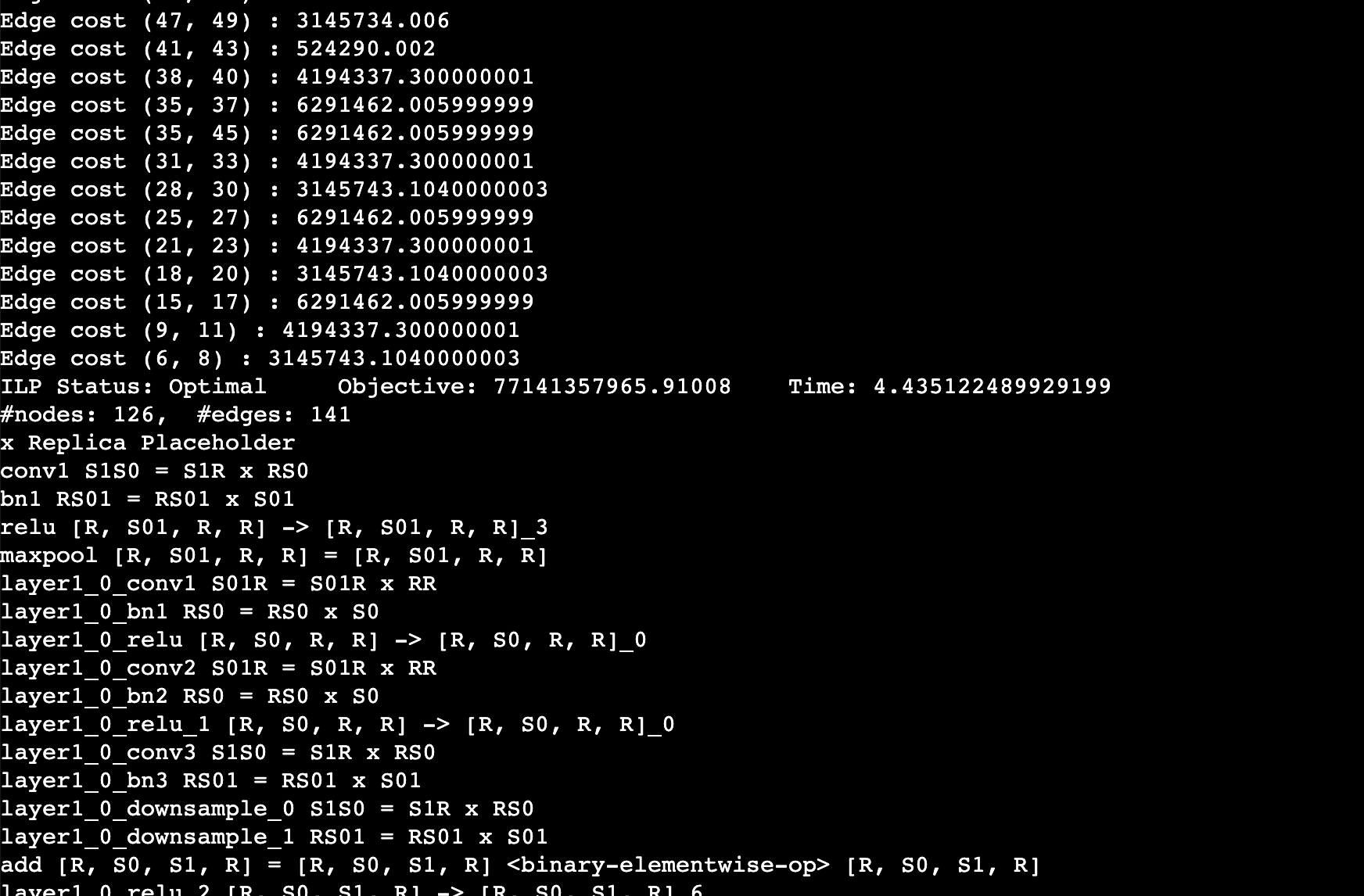
You should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, layer1_0_conv1 S01R = S01R X RR means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
🎆 Auto-Checkpoint Tutorial
- Stay in the
auto_parallelfolder. - Install the dependencies.
pip install matplotlib transformers
- Run a simple resnet50 benchmark to automatically checkpoint the model.
python auto_ckpt_solver_test.py --model resnet50
You should expect the log to be like this
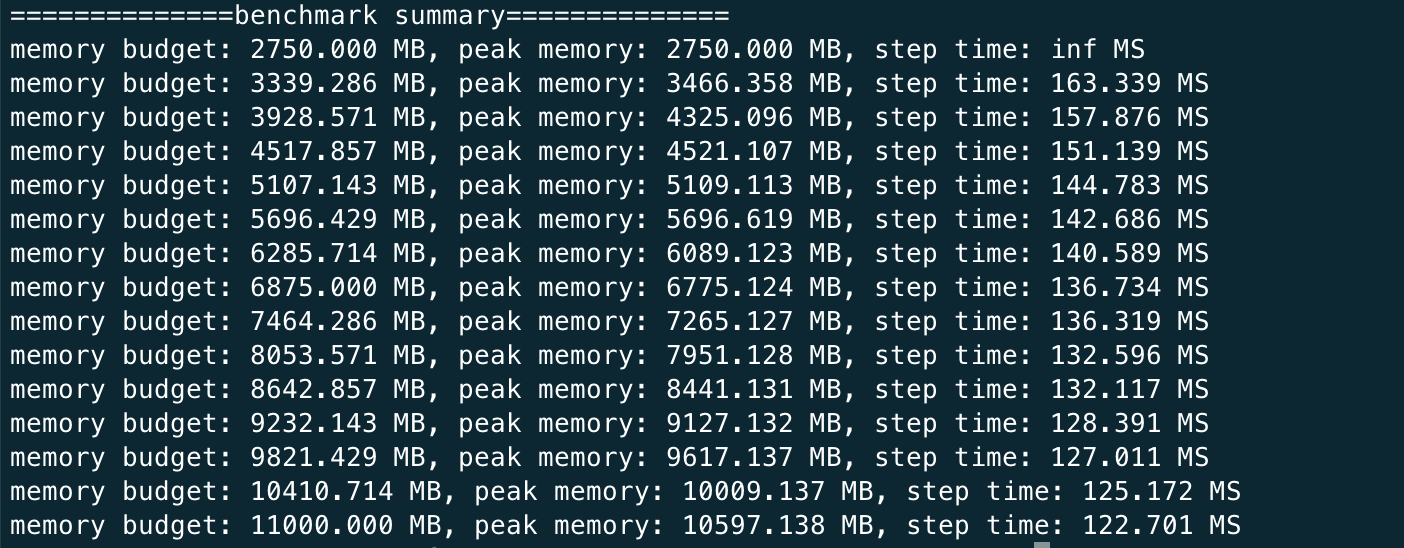
This shows that given different memory budgets, the model is automatically injected with activation checkpoint and its time taken per iteration. You can run this benchmark for GPT as well but it can much longer since the model is larger.
python auto_ckpt_solver_test.py --model gpt2
- Run a simple benchmark to find the optimal batch size for checkpointed model.
python auto_ckpt_batchsize_test.py
You can expect the log to be like

🚀 Run OPT finetuning and inference
- Install the dependency
pip install datasets accelerate
- Run finetuning with synthetic datasets with one GPU
bash ./run_clm_synthetic.sh
- Run finetuning with 4 GPUs
bash ./run_clm_synthetic.sh 16 0 125m 4
- Run inference with OPT 125M
docker hpcaitech/tutorial:opt-inference
docker run -it --rm --gpus all --ipc host -p 7070:7070 hpcaitech/tutorial:opt-inference
- Start the http server inside the docker container with tensor parallel size 2
python opt_fastapi.py opt-125m --tp 2 --checkpoint /data/opt-125m