* update configuration of chatglm and add support in coati * add unit test & update chatglm default config & fix bos index issue * remove chatglm due to oom * add dataset pkg in requirement-text * fix parameter issue in test_models * add ref in tokenize & rm unnessary parts * separate source & target tokenization in chatglm * add unit test to chatglm * fix test dataset issue * update truncation of chatglm * fix Colossalai version * fix colossal ai version in test |
||
|---|---|---|
| .. | ||
| benchmarks | ||
| coati | ||
| evaluate | ||
| examples | ||
| inference | ||
| tests | ||
| .gitignore | ||
| LICENSE | ||
| README.md | ||
| pytest.ini | ||
| requirements-test.txt | ||
| requirements.txt | ||
| setup.py | ||
| version.txt | ||
README.md

ColossalChat
Table of Contents
- Table of Contents
- What is ColossalChat and Coati ?
- Online demo
- Install
- How to use?
- Coati7B examples
- FAQ
- The Plan
- Invitation to open-source contribution
- Quick Preview
- Authors
- Citations
- Licenses
What is ColossalChat and Coati ?
ColossalChat is the project to implement LLM with RLHF, powered by the Colossal-AI project.
Coati stands for ColossalAI Talking Intelligence. It is the name for the module implemented in this project and is also the name of the large language model developed by the ColossalChat project.
The Coati package provides a unified large language model framework that has implemented the following functions
- Supports comprehensive large-model training acceleration capabilities for ColossalAI, without requiring knowledge of complex distributed training algorithms
- Supervised datasets collection
- Supervised instructions fine-tuning
- Training reward model
- Reinforcement learning with human feedback
- Quantization inference
- Fast model deploying
- Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
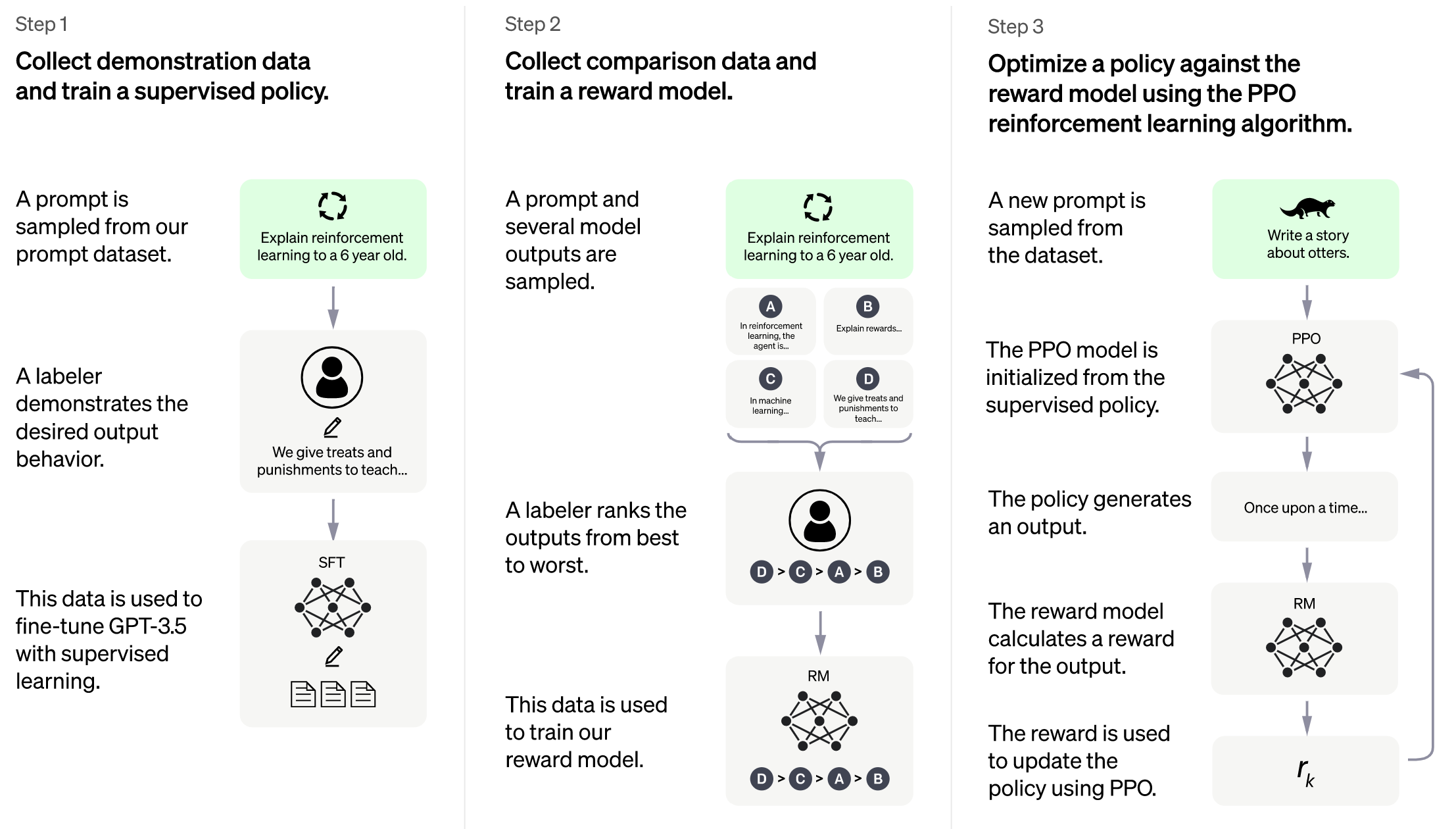
Image source: https://openai.com/blog/chatgpt
As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.
More details can be found in the latest news.
- [2023/03] ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline
- [2023/02] Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory
Online demo

ColossalChat: An open-source solution for cloning ChatGPT with a complete RLHF pipeline. [code] [blog] [demo] [tutorial]
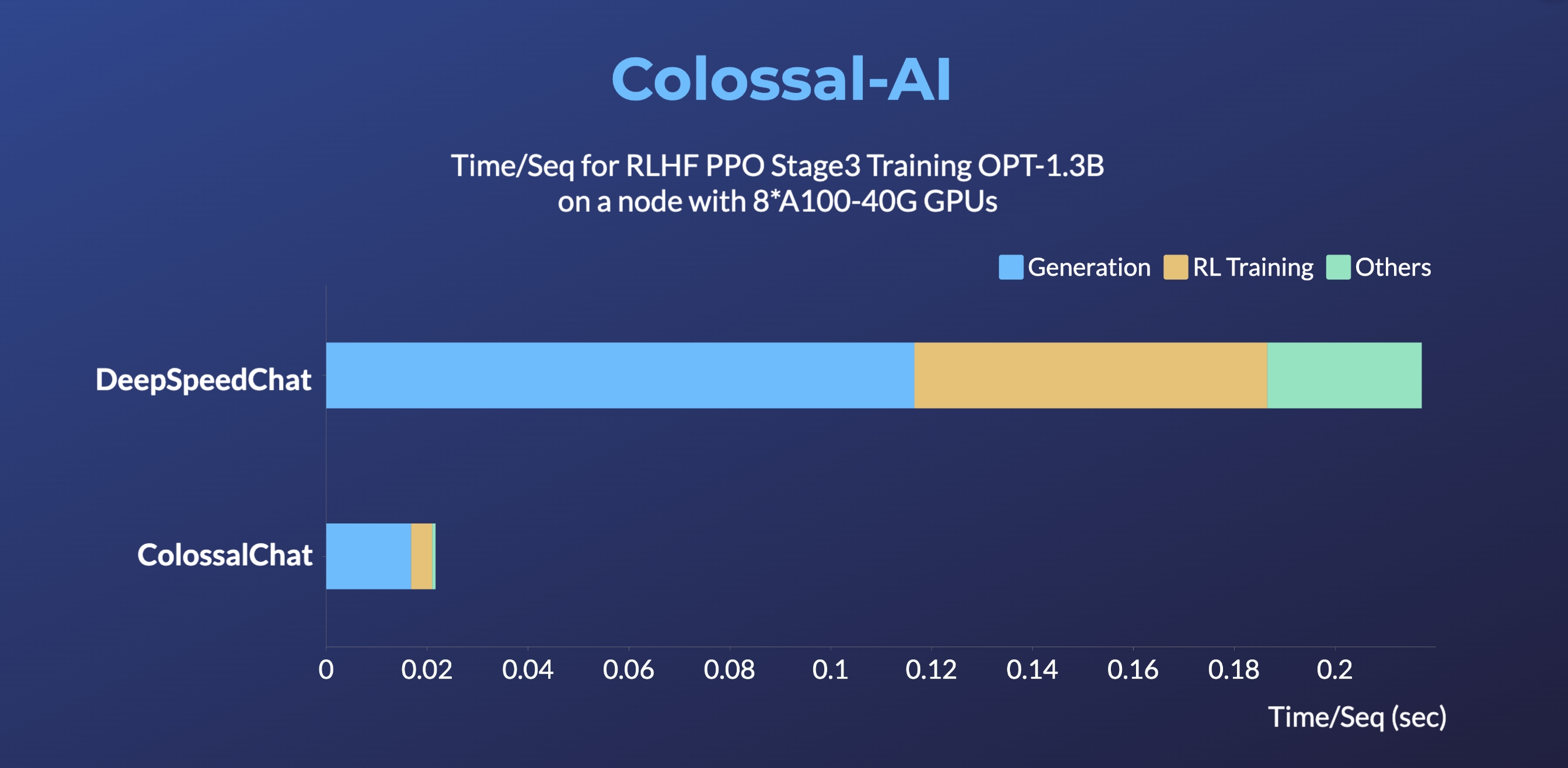
DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command:
torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32
Install
Install the environment
conda create -n coati
conda activate coati
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI/applications/Chat
pip install .
Install the Transformers
pip install transformers==4.30.2
How to use?
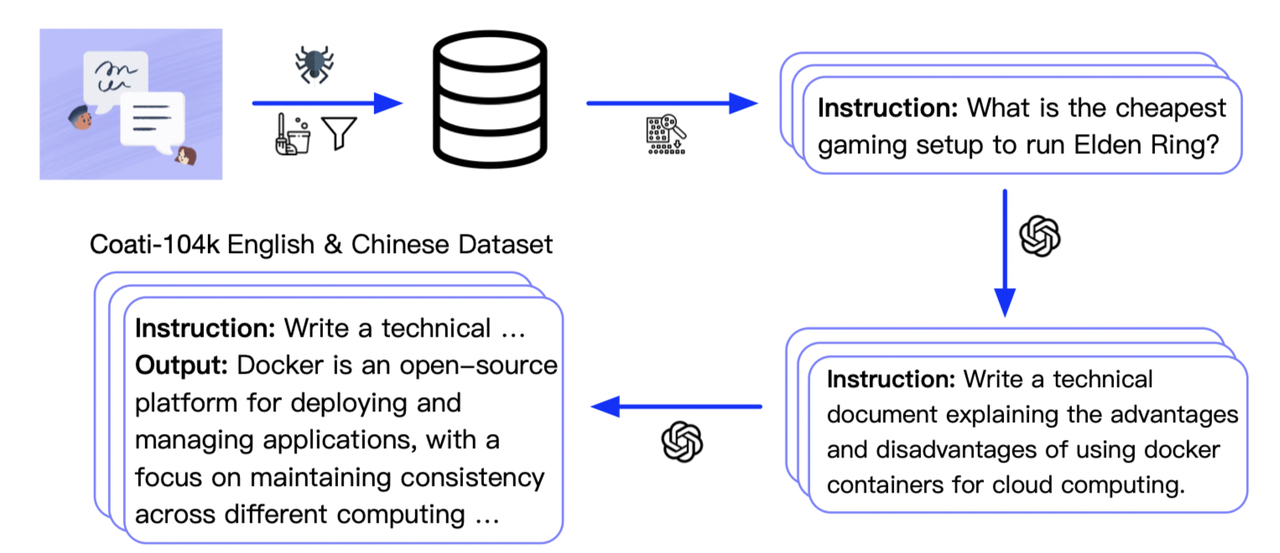
Supervised datasets collection
We collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo InstructionWild and in this file.
Here is how we collected the data
RLHF Training Stage1 - Supervised instructs tuning
Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model.
You can run the examples/train_sft.sh to start a supervised instructs fine-tuning.
[Stage1 tutorial video]
Note: the supervised dataset follows the following format,
[
{
"instruction": "Provide a list of the top 10 most popular mobile games in Asia",
"input": "",
"output": "The top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved",
"id": 0
},
...
]
RLHF Training Stage2 - Training reward model
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model
You can run the examples/train_rm.sh to start a reward model training.
[Stage2 tutorial video]
RLHF Training Stage3 - Training model with reinforcement learning by human feedback
Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process:
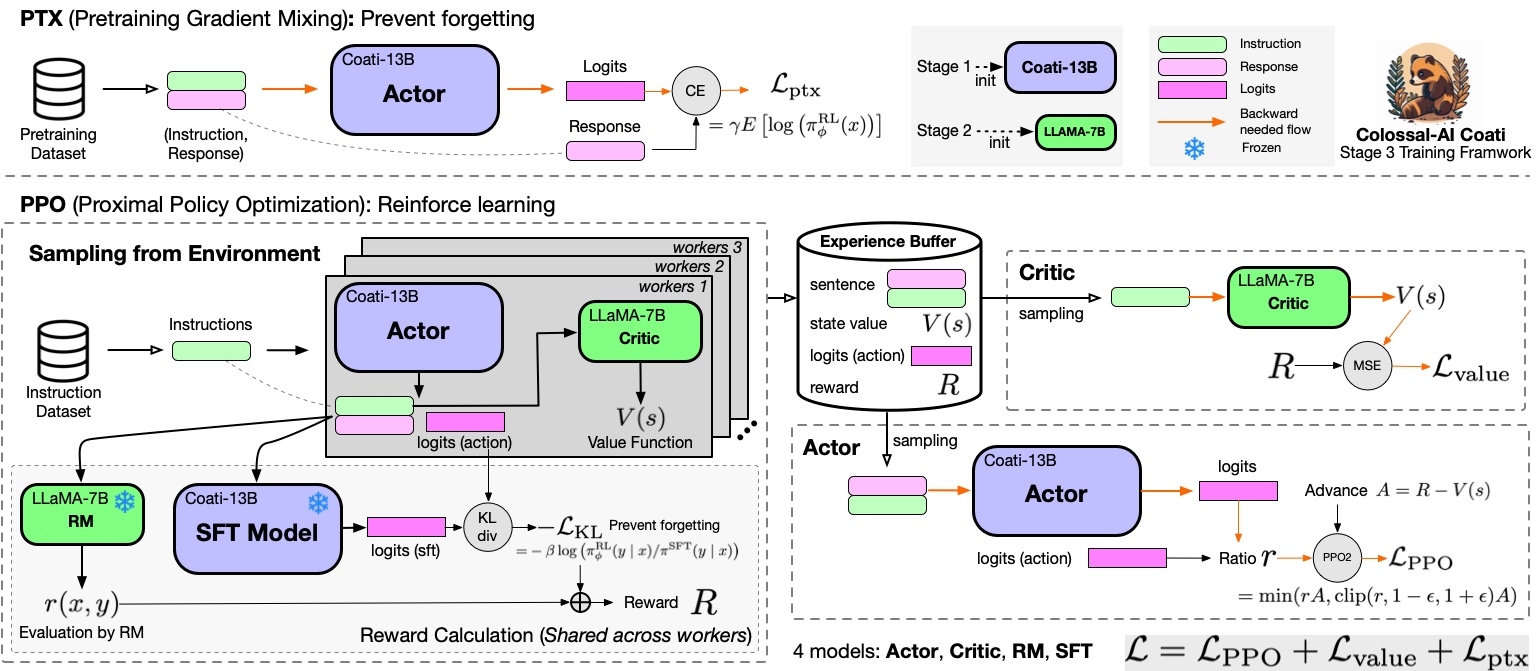
You can run the examples/train_prompts.sh to start training PPO with human feedback.
[Stage3 tutorial video]
Note: the required datasets follow the following format,
-
pretrain dataset[ { "instruction": "Provide a list of the top 10 most popular mobile games in Asia", "input": "", "output": "The top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved", "id": 0 }, ... ] -
prompt dataset[ { "instruction": "Edit this paragraph to make it more concise: \"Yesterday, I went to the store and bought some things. Then, I came home and put them away. After that, I went for a walk and met some friends.\"", "id": 0 }, { "instruction": "Write a descriptive paragraph about a memorable vacation you went on", "id": 1 }, ... ]
For more details, see examples/.
Inference Quantization and Serving - After Training
We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inference.
Online inference server scripts can help you deploy your own services.
For more details, see inference/.
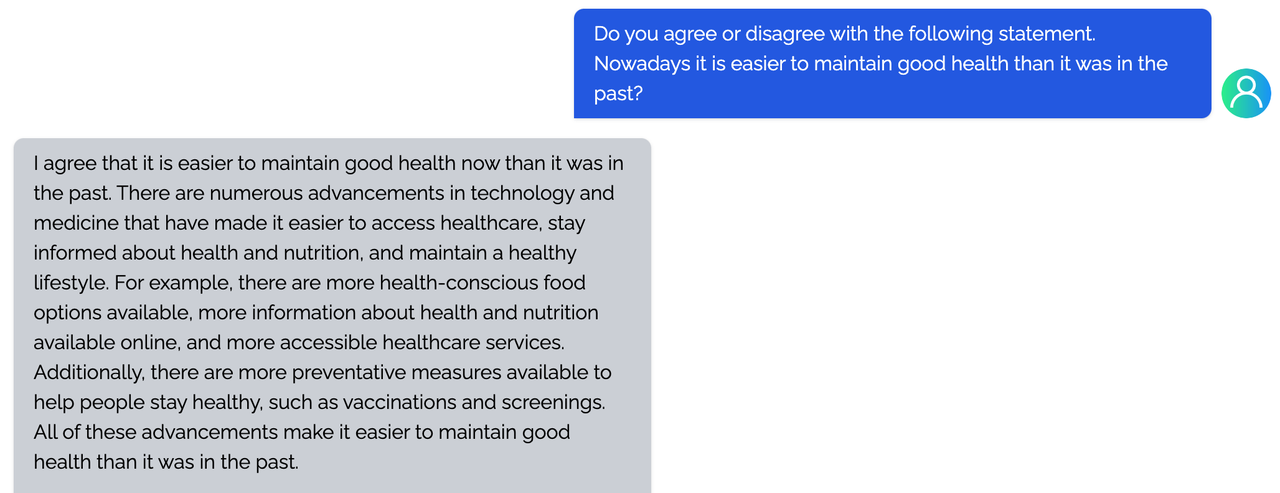
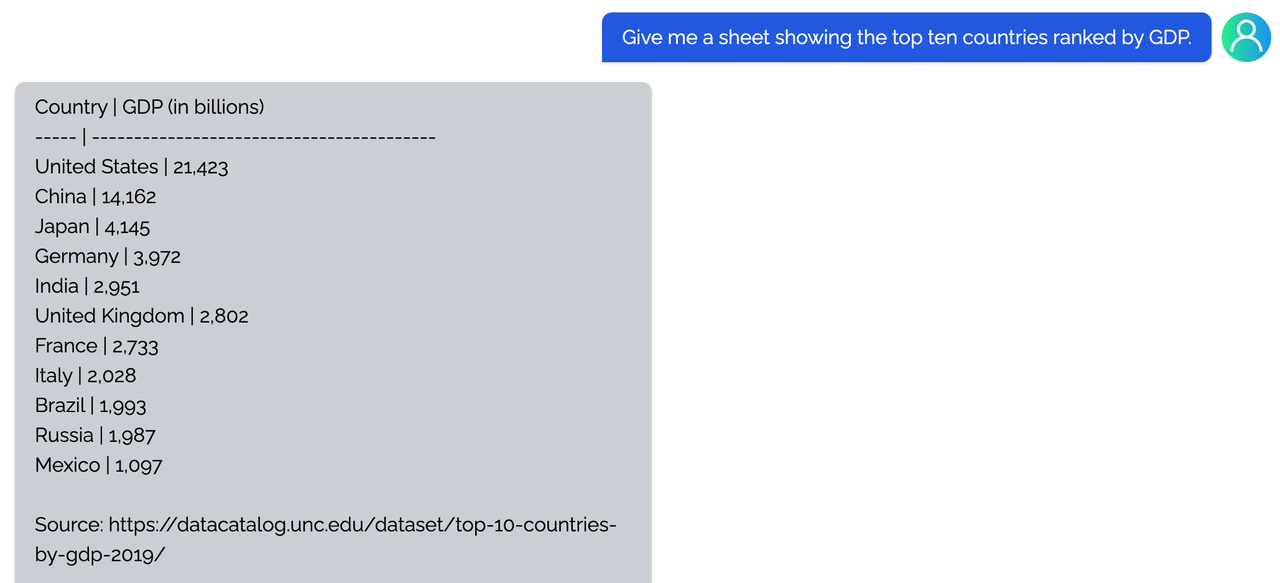
Coati7B examples
Generation
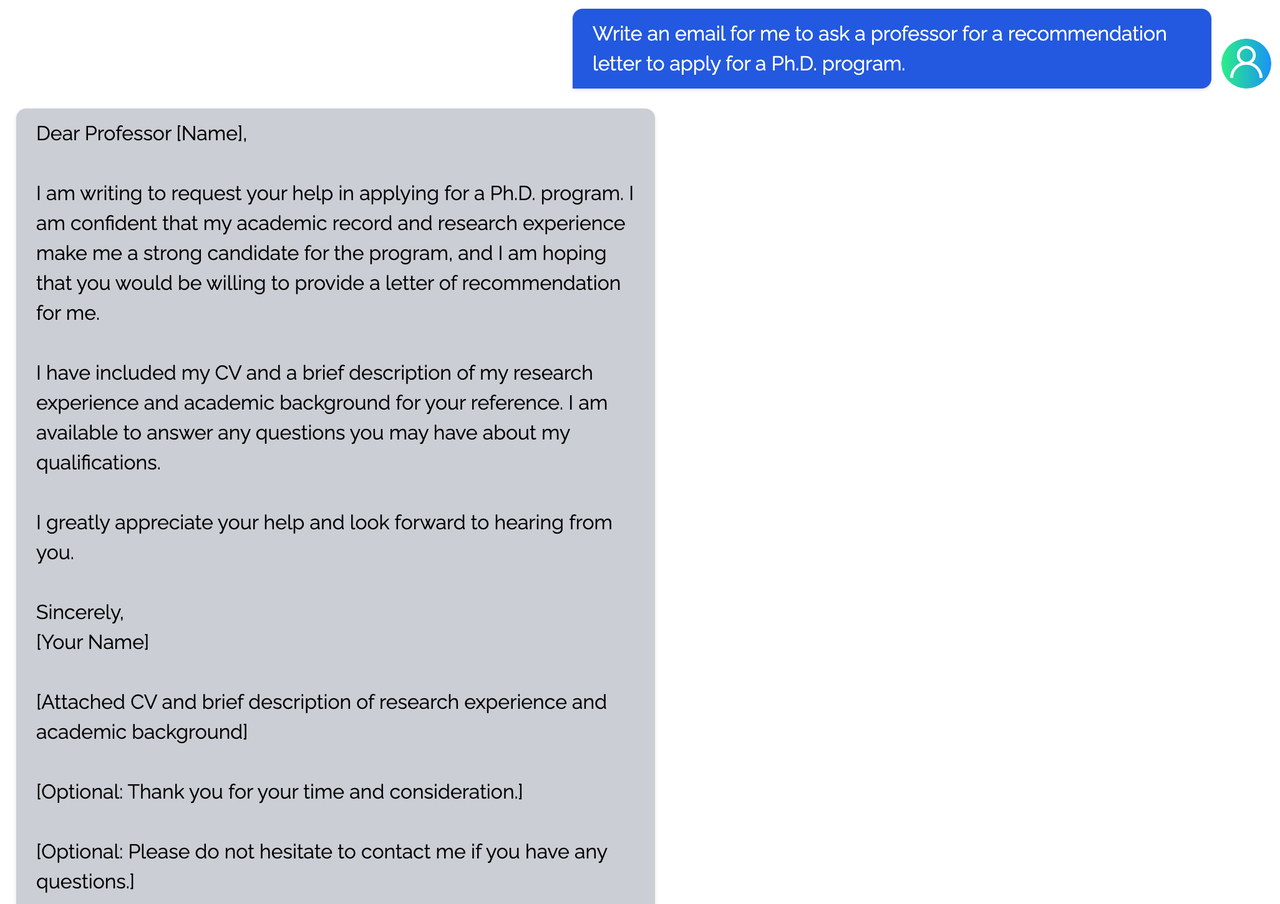
coding
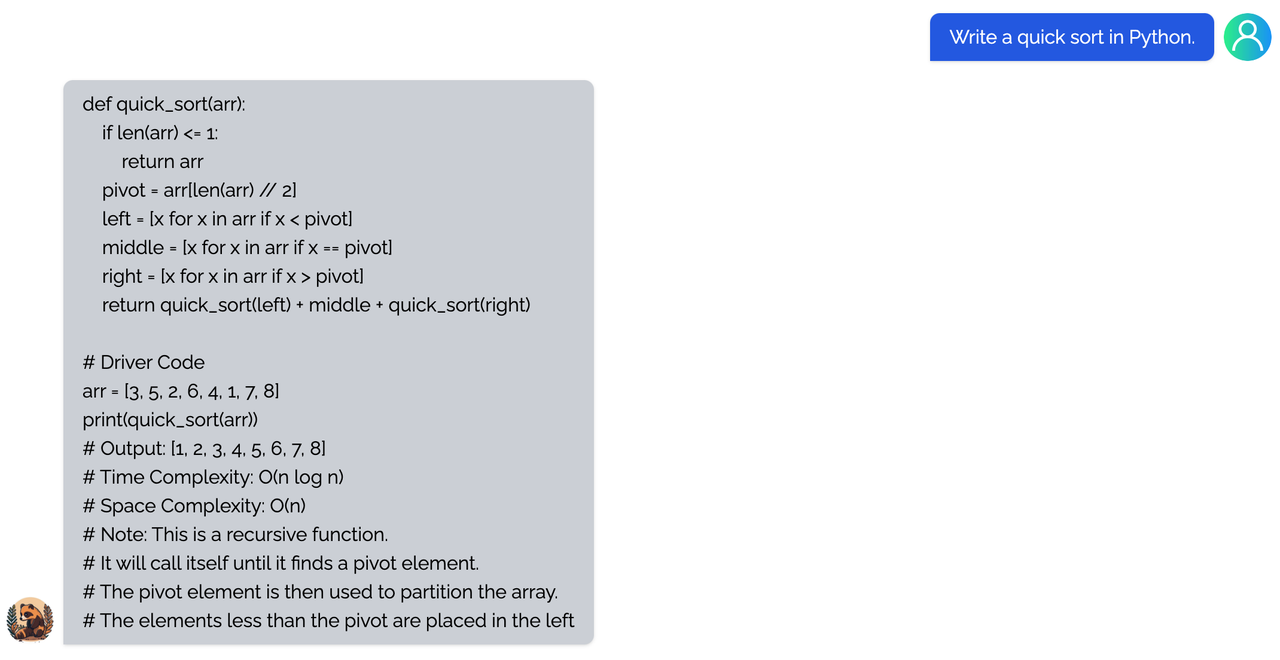
regex

Tex

writing
Table
Open QA
Game
Travel
Physical
Chemical

Economy
You can find more examples in this repo.
Limitation
Limitation for LLaMA-finetuned models
- Both Alpaca and ColossalChat are based on LLaMA. It is hard to compensate for the missing knowledge in the pre-training stage. - Lack of counting ability: Cannot count the number of items in a list. - Lack of Logics (reasoning and calculation) - Tend to repeat the last sentence (fail to produce the end token). - Poor multilingual results: LLaMA is mainly trained on English datasets (Generation performs better than QA).Limitation of dataset
- Lack of summarization ability: No such instructions in finetune datasets. - Lack of multi-turn chat: No such instructions in finetune datasets - Lack of self-recognition: No such instructions in finetune datasets - Lack of Safety: - When the input contains fake facts, the model makes up false facts and explanations. - Cannot abide by OpenAI's policy: When generating prompts from OpenAI API, it always abides by its policy. So no violation case is in the datasets.FAQ
How to save/load checkpoint
We have integrated the Transformers save and load pipeline, allowing users to freely call Hugging Face's language models and save them in the HF format.
from coati.models.llama import LlamaLM
from coati.trainer import SFTTrainer
model = LlamaLM(pretrained=args.pretrain)
tokenizer = AutoTokenizer.from_pretrained(args.pretrain)
(model, optim) = strategy.prepare((model, optim))
trainer = SFTTrainer(model=model,
strategy=strategy,
optim=optim,
train_dataloader=train_dataloader,
eval_dataloader=eval_dataloader,
batch_size=args.batch_size,
max_epochs=args.max_epochs,
accumulation_steps=args.accumulation_steps
)
trainer.fit()
# this saves in pytorch format
strategy.save_model(model, args.save_path, only_rank0=True)
# this saves in HF format
strategy.save_pretrained(model, args.save_path, only_rank0=True, tokenizer=tokenizer)
How to train with limited resources
Here are some examples that can allow you to train a 7B model on a single or multiple consumer-grade GPUs.
If you only have a single 24G GPU, you can use the following script. batch_size, lora_rank and grad_checkpoint are the most important parameters to successfully train the model.
// [INFO]: MAX GPU MEMORY ALLOCATED: 19148.9345703125 MB
torchrun --standalone --nproc_per_node=1 train_sft.py \
--pretrain "/path/to/LLaMa-7B/" \
--model 'llama' \
--strategy ddp \
--save_path /path/to/Coati-7B \
--dataset /path/to/data.json \
--batch_size 1 \
--accumulation_steps 8 \
--lr 2e-5 \
--max_datasets_size 512 \
--max_epochs 1 \
--lora_rank 16 \
--grad_checkpoint
colossalai_gemini strategy can enable a single 24G GPU to train the whole model without using LoRA if you have sufficient CPU memory. You can use the following script.
torchrun --standalone --nproc_per_node=1 train_sft.py \
--pretrain "/path/to/LLaMa-7B/" \
--model 'llama' \
--strategy colossalai_gemini \
--save_path /path/to/Coati-7B \
--dataset /path/to/data.json \
--batch_size 1 \
--accumulation_steps 8 \
--lr 2e-5 \
--max_datasets_size 512 \
--max_epochs 1 \
--grad_checkpoint
If you have 4x32 GB GPUs, you can even train the whole 7B model using our colossalai_zero2_cpu strategy! The script is given as follows.
torchrun --standalone --nproc_per_node=4 train_sft.py \
--pretrain "/path/to/LLaMa-7B/" \
--model 'llama' \
--strategy colossalai_zero2_cpu \
--save_path /path/to/Coati-7B \
--dataset /path/to/data.json \
--batch_size 1 \
--accumulation_steps 8 \
--lr 2e-5 \
--max_datasets_size 512 \
--max_epochs 1 \
--grad_checkpoint
The Plan
- implement PPO fine-tuning
- implement training reward model
- support LoRA
- support inference
- support llama from facebook
- implement PPO-ptx fine-tuning
- integrate with Ray
- support more RL paradigms, like Implicit Language Q-Learning (ILQL),
- support chain-of-thought by langchain
Real-time progress
You will find our progress in github project broad.
Invitation to open-source contribution
Referring to the successful attempts of BLOOM and Stable Diffusion, any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
You may contact us or participate in the following ways:
- Leaving a Star ⭐ to show your like and support. Thanks!
- Posting an issue, or submitting a PR on GitHub follow the guideline in Contributing.
- Join the Colossal-AI community on Slack, and WeChat(微信) to share your ideas.
- Send your official proposal to email contact@hpcaitech.com
{kind=link}
Thanks so much to all of our amazing contributors!
Quick Preview
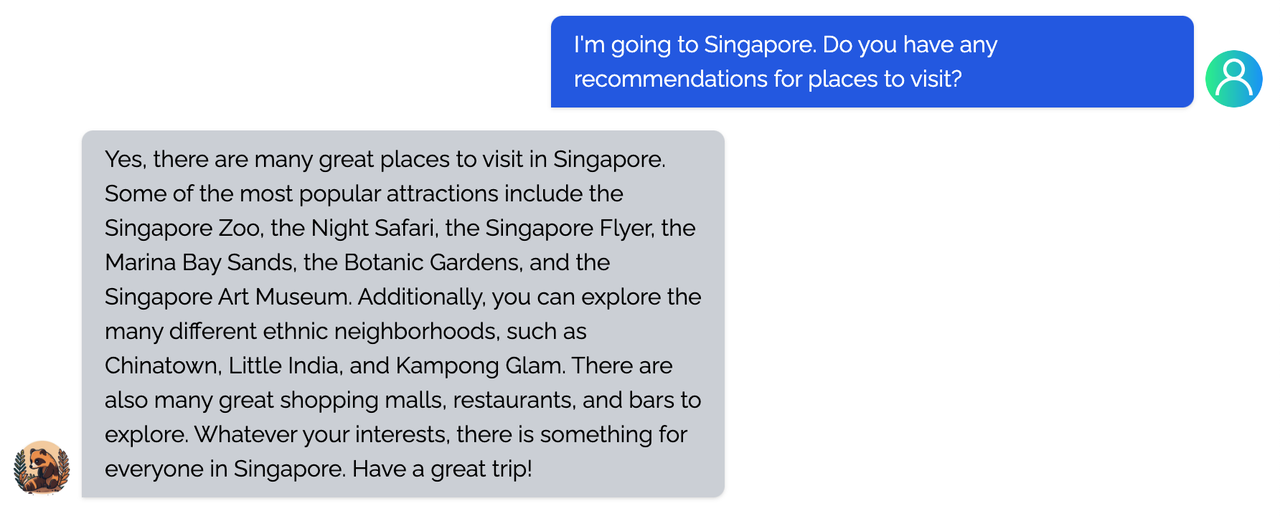

- Up to 7.73 times faster for single server training and 1.42 times faster for single-GPU inference
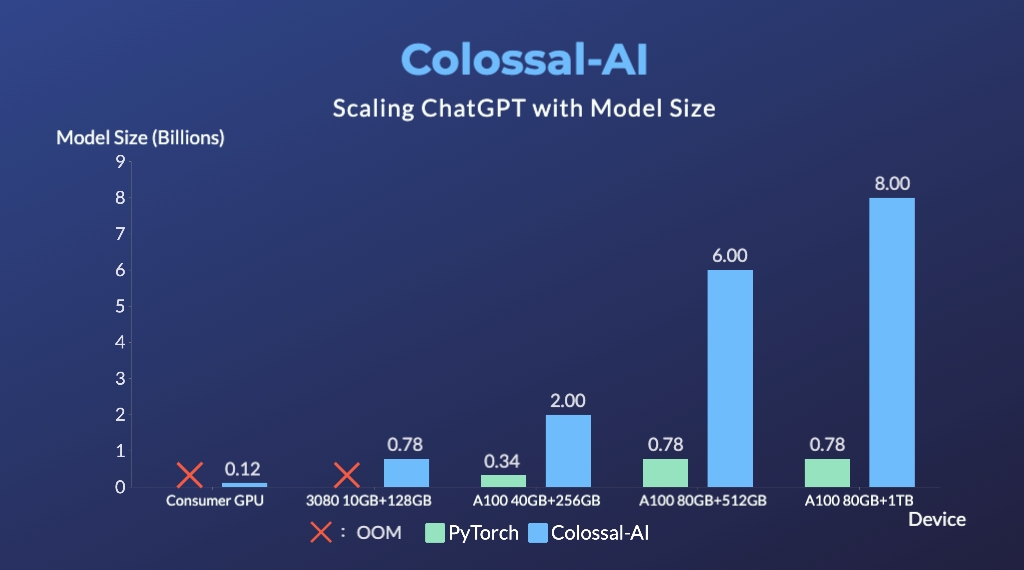
- Up to 10.3x growth in model capacity on one GPU
- A mini demo training process requires only 1.62GB of GPU memory (any consumer-grade GPU)
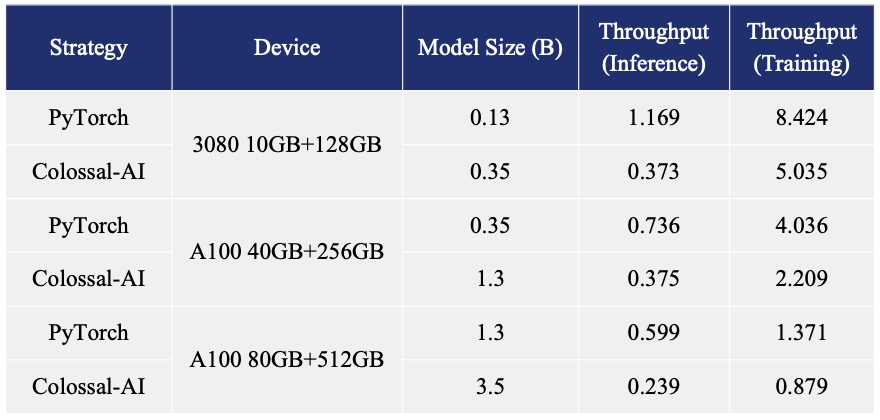
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
- Keep in a sufficiently high running speed
| Model Pair | Alpaca-7B ⚔ Coati-7B | Coati-7B ⚔ Alpaca-7B |
|---|---|---|
| Better Cases | 38 ⚔ 41 | 45 ⚔ 33 |
| Win Rate | 48% ⚔ 52% | 58% ⚔ 42% |
| Average Score | 7.06 ⚔ 7.13 | 7.31 ⚔ 6.82 |
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
Authors
Coati is developed by ColossalAI Team:
The Phd student from (HPC-AI) Lab also contributed a lot to this project.
Citations
@article{Hu2021LoRALA,
title = {LoRA: Low-Rank Adaptation of Large Language Models},
author = {Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen},
journal = {ArXiv},
year = {2021},
volume = {abs/2106.09685}
}
@article{ouyang2022training,
title={Training language models to follow instructions with human feedback},
author={Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others},
journal={arXiv preprint arXiv:2203.02155},
year={2022}
}
@article{touvron2023llama,
title={LLaMA: Open and Efficient Foundation Language Models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
@misc{instructionwild,
author = {Fuzhao Xue and Zangwei Zheng and Yang You },
title = {Instruction in the Wild: A User-based Instruction Dataset},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/XueFuzhao/InstructionWild}},
}
Licenses
Coati is licensed under the Apache 2.0 License.