* add dist dropout in model * update docstring and bert policy with dropout * refactor basepolicy and sharded, update bert * update format * update gpt2 policy * update bert policy * remove unused code * update readme for new policy usage |
||
|---|---|---|
| .. | ||
| layer | ||
| model | ||
| policies | ||
| shard | ||
| utils | ||
| README.md | ||
| __init__.py | ||
README.md
⚡️ ShardFormer
📚 Table of Contents
🔗 Introduction
Shardformer is a module that automatically parallelizes the mainstream models in libraries such as HuggingFace and TIMM. This module aims to make parallelization hassle-free for users who are not from the system background.
🔨 Usage
The sample API usage is given below:
from colossalai.shardformer import ShardConfig, shard_model
from transformers import BertForMaskedLM
# create huggingface model as normal
model = BertForMaskedLM.from_pretrained("bert-base-uncased")
# make the huggingface model paralleled to ShardModel
# auto policy:
shardconfig = ShardConfig(
rank=rank,
world_size=world_size,
gather_output=True,
)
sharded_model = shard_model(model, config=shardconfig)
# custom policy:
from xxx import <POLICYCLASS>
sharded_model = shard_model(model, <POLICYCLASS>)
# do angthing as normal
...
🔮 Simple example
# inference
colossalai run --nproc_per_node 2 --master_port 29500 test.py --config config.py --mode inference
# train
colossalai run --nproc_per_node 2 --master_port 29500 test.py --config config.py --mode train
💡 Policy
If you wanna parallel the model in a custom way, just overwrite the policy class for the Hugging Face model. Please refer to any policy that we have pre-established, like bert policy or gpt2 policy.
You should do:
- Inherit Policy class
- Overwrite
argument_policymethod- In this method, you need to list which layers class you wanna modify and the attributes and parameters in those layers. Shardformer will replace all the layer belonging to the class you specified.
attr_dictis dict contains all the attributes need to be modified in this layer.param_funcsis a list contains some functions which will return the path of the weight and bias from the layer.
- Overwrite
inject_policymethod (Optional)- Shardformer will inject the model according to this method. If you need to modify the forward or backward progress (like distributed corssentropy loss in Bert) you need to overwrite this method.
- Overwrite or add the param functions
- These functions use a suffix to record the path of weight or bias for the layer.
- The return is a list contains some
Col_Layer,Row_LayerorDropout_Layerobjects, which means slice along col and row respectively or as dropout layer, refer to CLASSLayerfor more details.
- Overwrite
binding_policy(Optional)- Overwrite to specify Shardformer will bind some weight between layers, like embedding and unembedding layers.
- This function will return a dict, the key and value are the suffix of weight need to be binded.
More details can be found in shardformer/policies/basepolicy.py
from colossalai.shardformer.policies.basepolicy import Policy, Layer, Col_Layer, Row_Layer, Argument
class CustomPolicy(Policy):
@staticmethod
def argument_policy(model_config, shard_config: int) -> Dict[nn.Module, Argument]:
r"""
Return the dict for the modify policy, the key is the original layer class and the value is the
argument for the modify layer
Args:
model_config (:class:`tansformer.Config`): The config of transformer model
shard_config (:class:`ShardConfig`): The config for sharding model
Return:
Dict for the modify policy,
::
{
origin layer class1 (nn.Module): Argument(
attr_dict = {
argument1: value1,
argument2: value2,
...
},
param_funcs = [
staticmethod1,
staticmethod2,
...
]
),
origin layer class2 (nn.Module): Argument(
attr_dict = {
argument1: value1,
argument2: value2,
...
},
param_funcs = [
staticmethod1,
staticmethod2,
...
]
),
...
}
"""
raise NotImplementedError
@staticmethod
def inject_policy() -> Union[Tuple[nn.Module, nn.Module], None]:
r"""
Return the dict for the inject model
Return:
The injected model, key is the original model and value is the new shardmodel
::
(OrignModel, CustomModel)
in `CustomModel`, we can overwrite the forward and backward process
"""
return None
@staticmethod
def binding_policy() -> Union[Dict[str, str], None]:
r"""
Return the dict for the binding model, None means no need to bind
Return:
This method should return the binding relationship for some layers share the weight or bias,
the key and value is the suffix of the weight or bias of the model
::
return {
"bert.embeddings.word_embeddings.weight": "cls.predictions.decoder.weight",
}
"""
return None
@staticmethod
def attn_in() -> Union[List, None]:
r"""
Attention qkv layer
In this kind of method, we should return the list of ``Layer`` object, each ``Layer`` object should be
``Layer`` for no slicing, ``Col_Layer`` for col slicing, ``Row_Layer`` for row slicing. And the parameters
in ``Layer`` object can refer to the ``Layer`` class.
Returns:
List[Layer]: List of layer object, each layer is the new
"""
return None
@staticmethod
def attn_out() -> Union[List, None]:
r"""
Attention output projection layer
Returns:
List[Layer]: List of layer object
"""
return None
@staticmethod
def mlp_in() -> Union[List, None]:
r"""
h -> 4h mlp layer
Returns:
List[Layer]: List of layer object
"""
return None
@staticmethod
def mlp_out() -> Union[List, None]:
r"""
4h -> h mlp layer
Returns:
List[Layer]: List of layer object
"""
return None
@staticmethod
def embedding() -> Union[List, None]:
r"""
Partially slice the embedding layer
Return:
List[Layer]: List of layer object
"""
return None
@staticmethod
def unembedding() -> Union[List, None]:
r"""
Partially slice the embedding layer, None means there is no unembedding layer
Return:
List[Layer]: List of layer object
"""
return None
😊 Module
- Flowchart
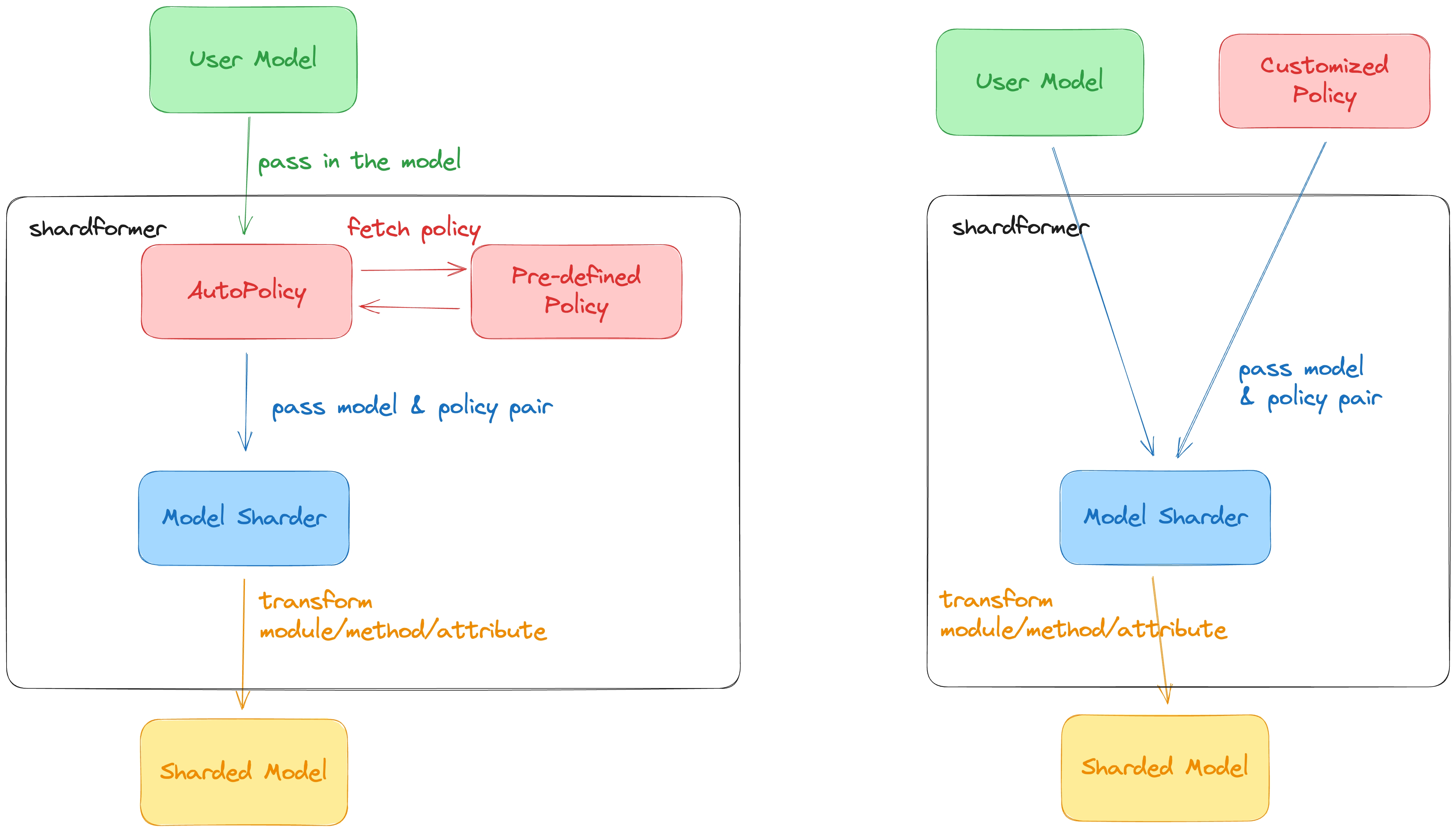
- Important Modules
-
CLASS
shard_model:This is the user api to use shardformer, just create a model from transformers and define a custom policy or use shardformer autopolicy to make a shard model.
-
CLASS
Layer:Parameters:
- suffix: (str): the suffix of the layer to indicate the attribute of the layer.
- replace_layer (:class:
colosalai.nn): The layer to replace the original layer - ignore (bool): Whether to ignore this layer if it is not in the model
- reversed (bool): Whether the weight in layer is reversed, commonly the weight in
torch.nn.Linearis [out, in], but in GPT2Conv1Dlayer is [in, out] which is reversed. - n_cast (int): The number of weight will cast to, like q, k, v in attention layer, n_cast should be 3. commonly in TP, we just chunk the weight with the number of devices, but in multi-head attention, we need to chunk the weight with the number of
devices * n\_head, and each device should have a part of Q, K and V weight.
This class is a base class used to specify the replacement policy and the suffix the layer for a particular layer.
CLASS
Col_Layer(Layer):- weight (str): The weight suffix of the layer
- bias (str): The bias suffix of the layer
- gather_output (bool): Whether the output of this layer can be gathered, like the last layer can be gathered, but most of the time, the intermediate layers of the model do not need to be gathered.
This class inherited from
Layer, representing the layer will be sliced along colum and indicate the attributes of weight and bias. SettingbiastoNonemeans ignoring bias, regardless of whether or not it originally exists.CLASS
Row_Layer(Layer):- weight (str): The weight suffix of the layer
- bias (str): The bias suffix of the layer
This class inherited from
Layer, representing the layer will be sliced along row. Just likeCol_Layerbut in tensor parrallel, there is no need to gather the output of layer sliced by row. -
CLASS
Policy:In Shardformer, this class holds significant importance as it defines the model partitioning methods, required parameter modifications, and model injection techniques all within a single Policy class.
-
Policy.attn_in()/attn_out()/mlp_in()/mlp_out()/embedding()/unembedding()......These functions define the partitioning methods of the parameters at different locations in the model. Each function returns a list of objects of Layer class that specify the replacement approach for these parameters. Shardformer also supports user-defined functions for modifying their models, in addition to the listed functions.
-
Policy.argument_policy()In this function, the user should use multiple dict to define which class of layers will require replacement. This includes the attributes and parameters that need to be modified or replaced. Attributes are stored in the form of a "suffix-string: value" dict, while parameters are stored via multiple static methods that return the replacement approach.
-
Policy.inject_policy()This function will return the injected model to replace the original model. The new model should be a nn.Module class which includes modified forward or backward functions or anything else.
-
Policy.binding_policy()This function will return the weight sharing information in the model in some dict. The key and value are both the suffixes of the shared parameters.
-
-
CLASS
ModelSharder(model, policy):This class helps shard the model, the parameter is the created transformers model and the custom policy. If custom policy is None, shardformer will automatically get already defined policy for the model.
-
ModelShard.inject_model()This function is used to inject the model to modify the forward and backward progress.
-
ModelShard.replace_layer()This function is used to replace the original layers with colossalai layer to make them paralleled and can do distributed communication.
-
ModelShard.bind_layer()This function is used to help different layers share weight or bias.
-
-
CLASS
Slicer:This class is used to slice tensor according to policy.
- DistCrossEntropy Loss
-
Overview
In order to reduce the communication size, caculate the crossentropy before all gather, refer to Megatron-LM, reduce the communication size from [batch_size * seq_length * vocab_size] to [batch_size * seq_length]. The origin loss function is:
loss = -\log(\frac{\exp(x[class])}{\sum_i\exp(x[i])})alse can be represented as:
loss = \log(\sum_i\exp(x[i])) - x[class] -
Step
-
First get the maximum logits across all the devices, make all the logist minus the maximun value to scale the value less than zero to avoid the value of exp being too large
-
Get a mask to mask the logits not in the local device
-
Caculate the loss according to the second formula
-