* init
* rename and remove useless func
* basic chunk
* add evoformer
* align evoformer
* add meta
* basic chunk
* basic memory
* finish basic inference memory estimation
* finish memory estimation
* fix bug
* finish memory estimation
* add part of index tracer
* finish basic index tracer
* add doc string
* add doc str
* polish code
* polish code
* update active log
* polish code
* add possible region search
* finish region search loop
* finish chunk define
* support new op
* rename index tracer
* finishi codegen on msa
* redesign index tracer, add source and change compute
* pass outproduct mean
* code format
* code format
* work with outerproductmean and msa
* code style
* code style
* code style
* code style
* change threshold
* support check_index_duplicate
* support index dupilictae and update loop
* support output
* update memory estimate
* optimise search
* fix layernorm
* move flow tracer
* refactor flow tracer
* format code
* refactor flow search
* code style
* adapt codegen to prepose node
* code style
* remove abandoned function
* remove flow tracer
* code style
* code style
* reorder nodes
* finish node reorder
* update run
* code style
* add chunk select class
* add chunk select
* code style
* add chunksize in emit, fix bug in reassgin shape
* code style
* turn off print mem
* add evoformer openfold init
* init openfold
* add benchmark
* add print
* code style
* code style
* init openfold
* update openfold
* align openfold
* use max_mem to control stratge
* update source add
* add reorder in mem estimator
* improve reorder efficeincy
* support ones_like, add prompt if fit mode search fail
* fix a bug in ones like, dont gen chunk if dim size is 1
* fix bug again
* update min memory stratege, reduce mem usage by 30%
* last version of benchmark
* refactor structure
* restruct dir
* update test
* rename
* take apart chunk code gen
* close mem and code print
* code format
* rename ambiguous variable
* seperate flow tracer
* seperate input node dim search
* seperate prepose_nodes
* seperate non chunk input
* seperate reorder
* rename
* ad reorder graph
* seperate trace flow
* code style
* code style
* fix typo
* set benchmark
* rename test
* update codegen test
* Fix state_dict key missing issue of the ZeroDDP (#2363)
* Fix state_dict output for ZeroDDP duplicated parameters
* Rewrite state_dict based on get_static_torch_model
* Modify get_static_torch_model to be compatible with the lower version (ZeroDDP)
* update codegen test
* update codegen test
* add chunk search test
* code style
* add available
* [hotfix] fix gpt gemini example (#2404)
* [hotfix] fix gpt gemini example
* [example] add new assertions
* remove autochunk_available
* [workflow] added nightly release to pypi (#2403)
* add comments
* code style
* add doc for search chunk
* [doc] updated readme regarding pypi installation (#2406)
* add doc for search
* [doc] updated kernel-related optimisers' docstring (#2385)
* [doc] updated kernel-related optimisers' docstring
* polish doc
* rename trace_index to trace_indice
* rename function from index to indice
* rename
* rename in doc
* [polish] polish code for get_static_torch_model (#2405)
* [gemini] polish code
* [testing] remove code
* [gemini] make more robust
* rename
* rename
* remove useless function
* [worfklow] added coverage test (#2399)
* [worfklow] added coverage test
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* add doc for trace indice
* [docker] updated Dockerfile and release workflow (#2410)
* add doc
* update doc
* add available
* change imports
* add test in import
* [workflow] refactored the example check workflow (#2411)
* [workflow] refactored the example check workflow
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* Update parallel_context.py (#2408)
* [hotfix] add DISTPAN argument for benchmark (#2412)
* change the benchmark config file
* change config
* revert config file
* rename distpan to distplan
* [workflow] added precommit check for code consistency (#2401)
* [workflow] added precommit check for code consistency
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* polish code
* adapt new fx
* [workflow] added translation for non-english comments (#2414)
* [setup] refactored setup.py for dependency graph (#2413)
* change import
* update doc
* [workflow] auto comment if precommit check fails (#2417)
* [hotfix] add norm clearing for the overflow step (#2416)
* [examples] adding tflops to PaLM (#2365)
* [workflow]auto comment with test coverage report (#2419)
* [workflow]auto comment with test coverage report
* polish code
* polish yaml
* [doc] added documentation for CI/CD (#2420)
* [doc] added documentation for CI/CD
* polish markdown
* polish markdown
* polish markdown
* [example] removed duplicated stable diffusion example (#2424)
* [zero] add inference mode and its unit test (#2418)
* [workflow] report test coverage even if below threshold (#2431)
* [example] improved the clarity yof the example readme (#2427)
* [example] improved the clarity yof the example readme
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* polish workflow
* [ddp] add is_ddp_ignored (#2434)
[ddp] rename to is_ddp_ignored
* [workflow] make test coverage report collapsable (#2436)
* [autoparallel] add shard option (#2423)
* [fx] allow native ckpt trace and codegen. (#2438)
* [cli] provided more details if colossalai run fail (#2442)
* [autoparallel] integrate device mesh initialization into autoparallelize (#2393)
* [autoparallel] integrate device mesh initialization into autoparallelize
* add megatron solution
* update gpt autoparallel examples with latest api
* adapt beta value to fit the current computation cost
* [zero] fix state_dict and load_state_dict for ddp ignored parameters (#2443)
* [ddp] add is_ddp_ignored
[ddp] rename to is_ddp_ignored
* [zero] fix state_dict and load_state_dict
* fix bugs
* [zero] update unit test for ZeroDDP
* [example] updated the hybrid parallel tutorial (#2444)
* [example] updated the hybrid parallel tutorial
* polish code
* [zero] add warning for ignored parameters (#2446)
* [example] updated large-batch optimizer tutorial (#2448)
* [example] updated large-batch optimizer tutorial
* polish code
* polish code
* [example] fixed seed error in train_dreambooth_colossalai.py (#2445)
* [workflow] fixed the on-merge condition check (#2452)
* [workflow] automated the compatiblity test (#2453)
* [workflow] automated the compatiblity test
* polish code
* [autoparallel] update binary elementwise handler (#2451)
* [autoparallel] update binary elementwise handler
* polish
* [workflow] automated bdist wheel build (#2459)
* [workflow] automated bdist wheel build
* polish workflow
* polish readme
* polish readme
* Fix False warning in initialize.py (#2456)
* Update initialize.py
* pre-commit run check
* [examples] update autoparallel tutorial demo (#2449)
* [examples] update autoparallel tutorial demo
* add test_ci.sh
* polish
* add conda yaml
* [cli] fixed hostname mismatch error (#2465)
* [example] integrate autoparallel demo with CI (#2466)
* [example] integrate autoparallel demo with CI
* polish code
* polish code
* polish code
* polish code
* [zero] low level optim supports ProcessGroup (#2464)
* [example] update vit ci script (#2469)
* [example] update vit ci script
* [example] update requirements
* [example] update requirements
* [example] integrate seq-parallel tutorial with CI (#2463)
* [zero] polish low level optimizer (#2473)
* polish pp middleware (#2476)
Co-authored-by: Ziyue Jiang <ziyue.jiang@gmail.com>
* [example] update gpt gemini example ci test (#2477)
* [zero] add unit test for low-level zero init (#2474)
* [workflow] fixed the skip condition of example weekly check workflow (#2481)
* [example] stable diffusion add roadmap
* add dummy test_ci.sh
* [example] stable diffusion add roadmap (#2482)
* [CI] add test_ci.sh for palm, opt and gpt (#2475)
* polish code
* [example] titans for gpt
* polish readme
* remove license
* polish code
* update readme
* [example] titans for gpt (#2484)
* [autoparallel] support origin activation ckpt on autoprallel system (#2468)
* [autochunk] support evoformer tracer (#2485)
support full evoformer tracer, which is a main module of alphafold. previously we just support a simplifed version of it.
1. support some evoformer's op in fx
2. support evoformer test
3. add repos for test code
* [example] fix requirements (#2488)
* [zero] add unit testings for hybrid parallelism (#2486)
* [hotfix] gpt example titans bug #2493
* polish code and fix dataloader bugs
* [hotfix] gpt example titans bug #2493 (#2494)
* [fx] allow control of ckpt_codegen init (#2498)
* [fx] allow control of ckpt_codegen init
Currently in ColoGraphModule, ActivationCheckpointCodeGen will be set automatically in __init__. But other codegen can't be set if so.
So I add an arg to control whether to set ActivationCheckpointCodeGen in __init__.
* code style
* [example] dreambooth example
* add test_ci.sh to dreambooth
* [autochunk] support autochunk on evoformer (#2497)
* Revert "Update parallel_context.py (#2408)"
This reverts commit
|
||
|---|---|---|
| .. | ||
| configs | ||
| docker | ||
| ldm | ||
| scripts | ||
| LICENSE | ||
| README.md | ||
| environment.yaml | ||
| main.py | ||
| requirements.txt | ||
| setup.py | ||
| test_ci.sh | ||
| train_colossalai.sh | ||
| train_ddp.sh | ||
README.md
ColoDiffusion: Stable Diffusion with Colossal-AI
Acceleration of AIGC (AI-Generated Content) models such as Stable Diffusion v1 and Stable Diffusion v2.
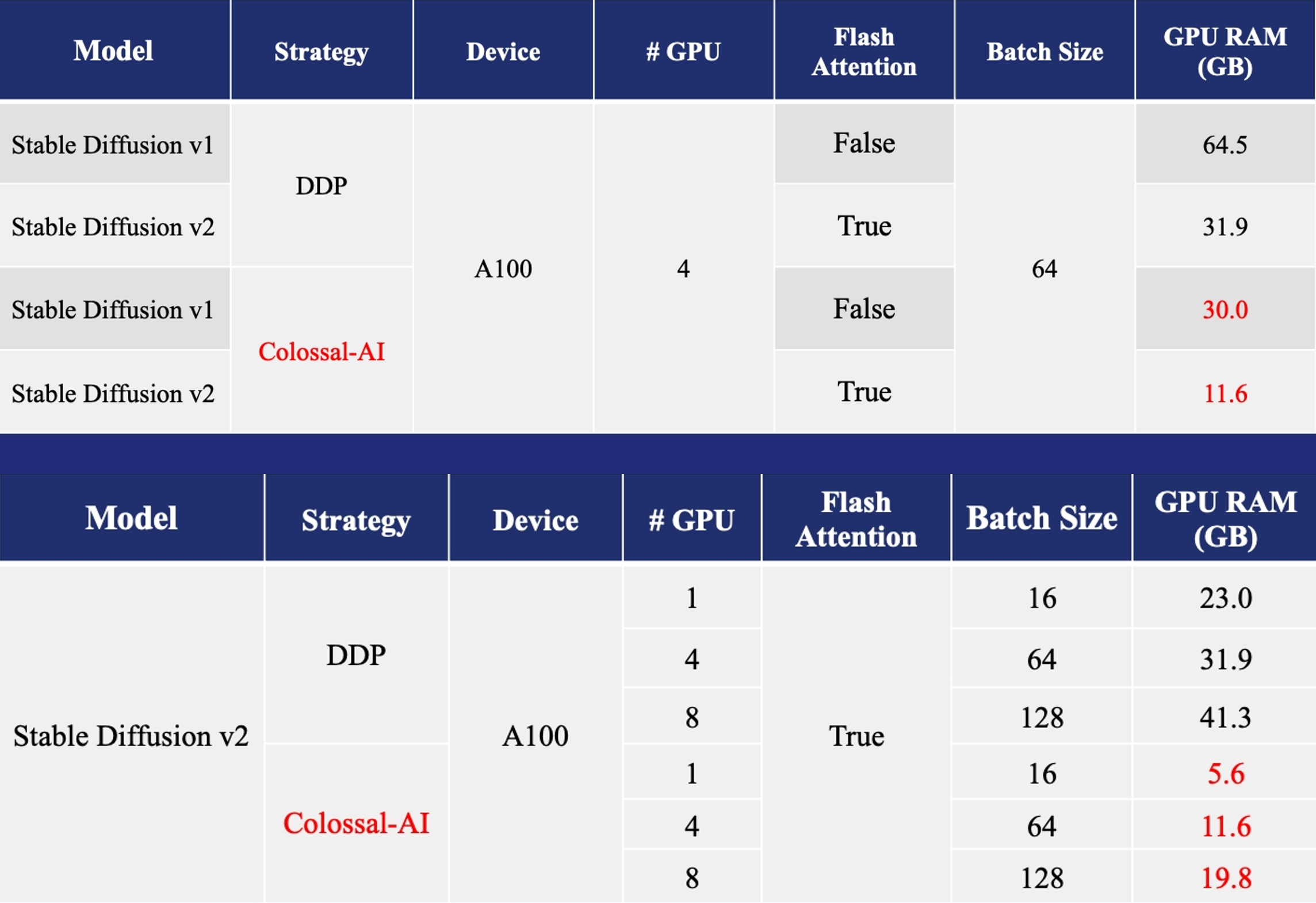
- Training: Reduce Stable Diffusion memory consumption by up to 5.6x and hardware cost by up to 46x (from A100 to RTX3060).

- DreamBooth Fine-tuning: Personalize your model using just 3-5 images of the desired subject.

- Inference: Reduce inference GPU memory consumption by 2.5x.
More details can be found in our blog of Stable Diffusion v1 and blog of Stable Diffusion v2.
Roadmap
This project is in rapid development.
- Train a stable diffusion model v1/v2 from scatch
- Finetune a pretrained Stable diffusion v1 model
- Inference a pretrained model using PyTorch
- Finetune a pretrained Stable diffusion v2 model
- Inference a pretrained model using TensoRT
Installation
Option #1: install from source
Step 1: Requirements
A suitable conda environment named ldm can be created
and activated with:
conda env create -f environment.yaml
conda activate ldm
You can also update an existing latent diffusion environment by running
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Step 2: install lightning
Install Lightning version later than 2022.01.04. We suggest you install lightning from source.
https://github.com/Lightning-AI/lightning.git
Step 3:Install Colossal-AI From Our Official Website
For example, you can install v0.1.12 from our official website.
pip install colossalai==0.1.12+torch1.12cu11.3 -f https://release.colossalai.org
Option #2: Use Docker
To use the stable diffusion Docker image, you can either build using the provided the Dockerfile or pull a Docker image from our Docker hub.
# 1. build from dockerfile
cd docker
docker build -t hpcaitech/diffusion:0.2.0 .
# 2. pull from our docker hub
docker pull hpcaitech/diffusion:0.2.0
Once you have the image ready, you can launch the image with the following command:
########################
# On Your Host Machine #
########################
# make sure you start your image in the repository root directory
cd Colossal-AI
# run the docker container
docker run --rm \
-it --gpus all \
-v $PWD:/workspace \
-v <your-data-dir>:/data/scratch \
-v <hf-cache-dir>:/root/.cache/huggingface \
hpcaitech/diffusion:0.2.0 \
/bin/bash
########################
# Insider Container #
########################
# Once you have entered the docker container, go to the stable diffusion directory for training
cd examples/images/diffusion/
# start training with colossalai
bash train_colossalai.sh
It is important for you to configure your volume mapping in order to get the best training experience.
- Mandatory, mount your prepared data to
/data/scratchvia-v <your-data-dir>:/data/scratch, where you need to replace<your-data-dir>with the actual data path on your machine. - Recommended, store the downloaded model weights to your host machine instead of the container directory via
-v <hf-cache-dir>:/root/.cache/huggingface, where you need to repliace the<hf-cache-dir>with the actual path. In this way, you don't have to repeatedly download the pretrained weights for everydocker run. - Optional, if you encounter any problem stating that shared memory is insufficient inside container, please add
-v /dev/shm:/dev/shmto yourdocker runcommand.
Download the model checkpoint from pretrained
stable-diffusion-v1-4
Our default model config use the weight from CompVis/stable-diffusion-v1-4
git lfs install
git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
stable-diffusion-v1-5 from runway
If you want to useed the Last stable-diffusion-v1-5 weight from runwayml
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
Dataset
The dataSet is from LAION-5B, the subset of LAION,
you should the change the data.file_path in the config/train_colossalai.yaml
Training
We provide the script train_colossalai.sh to run the training task with colossalai,
and can also use train_ddp.sh to run the training task with ddp to compare.
In train_colossalai.sh the main command is:
python main.py --logdir /tmp/ -t -b configs/train_colossalai.yaml
- you can change the
--logdirto decide where to save the log information and the last checkpoint.
Training config
You can change the trainging config in the yaml file
- devices: device number used for training, default 8
- max_epochs: max training epochs, default 2
- precision: the precision type used in training, default 16 (fp16), you must use fp16 if you want to apply colossalai
- more information about the configuration of ColossalAIStrategy can be found here
Finetune Example (Work In Progress)
Training on Teyvat Datasets
We provide the finetuning example on Teyvat dataset, which is create by BLIP generated captions.
You can run by config configs/Teyvat/train_colossalai_teyvat.yaml
python main.py --logdir /tmp/ -t -b configs/Teyvat/train_colossalai_teyvat.yaml
Inference
you can get yout training last.ckpt and train config.yaml in your --logdir, and run by
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
--outdir ./output \
--config path/to/logdir/checkpoints/last.ckpt \
--ckpt /path/to/logdir/configs/project.yaml \
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--use_int8 whether to use quantization method
--precision {full,autocast}
evaluate at this precision
Comments
-
Our codebase for the diffusion models builds heavily on OpenAI's ADM codebase , lucidrains, Stable Diffusion, Lightning and Hugging Face. Thanks for open-sourcing!
-
The implementation of the transformer encoder is from x-transformers by lucidrains.
-
The implementation of flash attention is from HazyResearch.
BibTeX
@article{bian2021colossal,
title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
journal={arXiv preprint arXiv:2110.14883},
year={2021}
}
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{dao2022flashattention,
title={FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
journal={arXiv preprint arXiv:2205.14135},
year={2022}
}