# 流水并行
作者: Guangyang Lu, Hongxin Liu, Yongbin Li
**前置教程**
- [定义配置文件](../basics/define_your_config.md)
- [在训练中使用Engine和Trainer](../basics/engine_trainer.md)
- [并行配置](../basics/configure_parallelization.md)
**示例代码**
- [ColossalAI-Examples ResNet with pipeline](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/features/pipeline_parallel)
**相关论文**
- [Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training](https://arxiv.org/abs/2110.14883)
- [Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM](https://arxiv.org/abs/2104.04473)
- [GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism](https://arxiv.org/abs/1811.06965)
## 快速预览
在本教程中,你将学习如何使用流水并行。在 Colossal-AI 中, 我们使用 NVIDIA 推出的 1F1B 流水线。由于在本例中, 使用 ViT 和 ImageNet 太过庞大,因此我们使用 ResNet 和 CIFAR 为例.
## 目录
在本教程中,我们将介绍:
1. 介绍 1F1B 流水线;
2. 使用非交错和交错 schedule;
3. 使用流水线训练 ResNet。
## 认识 1F1B 流水线
首先,我们将向您介绍 GPipe,以便您更好地了解。
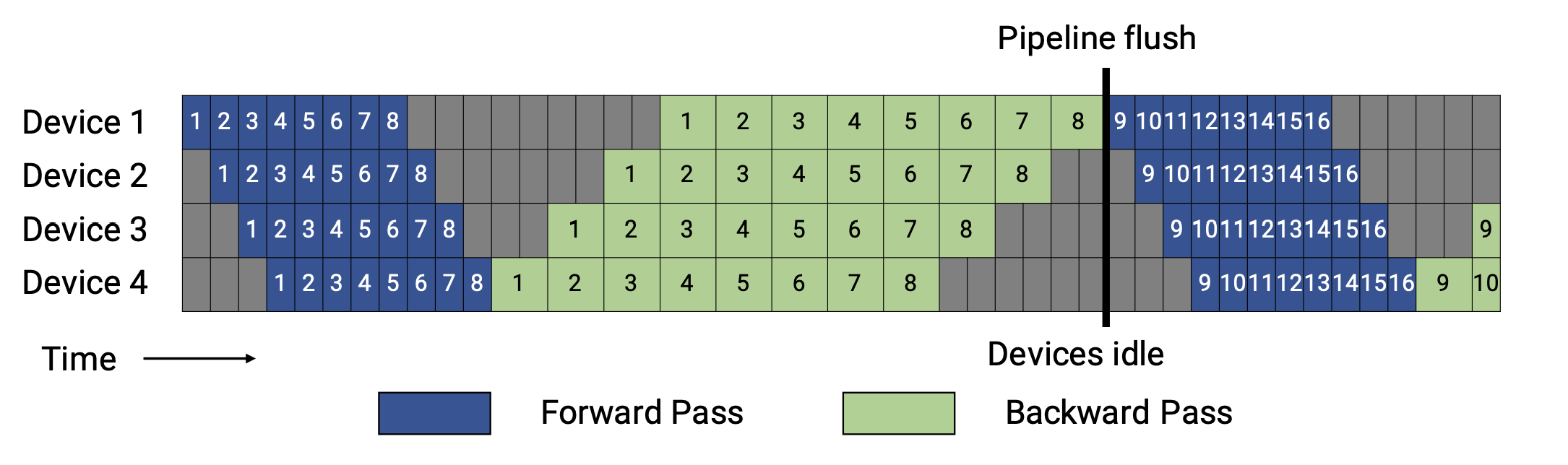 图1: GPipe,来自论文 Megatron-LM 。
正如你所看到的,对于 GPipe,只有当一个批次中所有 microbatches 的前向计算完成后,才会执行后向计算。
一般来说,1F1B(一个前向通道和一个后向通道)比 GPipe (在内存或内存和时间方面)更有效率。1F1B 流水线有两个 schedule ,非交错式和交错式,图示如下。
图1: GPipe,来自论文 Megatron-LM 。
正如你所看到的,对于 GPipe,只有当一个批次中所有 microbatches 的前向计算完成后,才会执行后向计算。
一般来说,1F1B(一个前向通道和一个后向通道)比 GPipe (在内存或内存和时间方面)更有效率。1F1B 流水线有两个 schedule ,非交错式和交错式,图示如下。
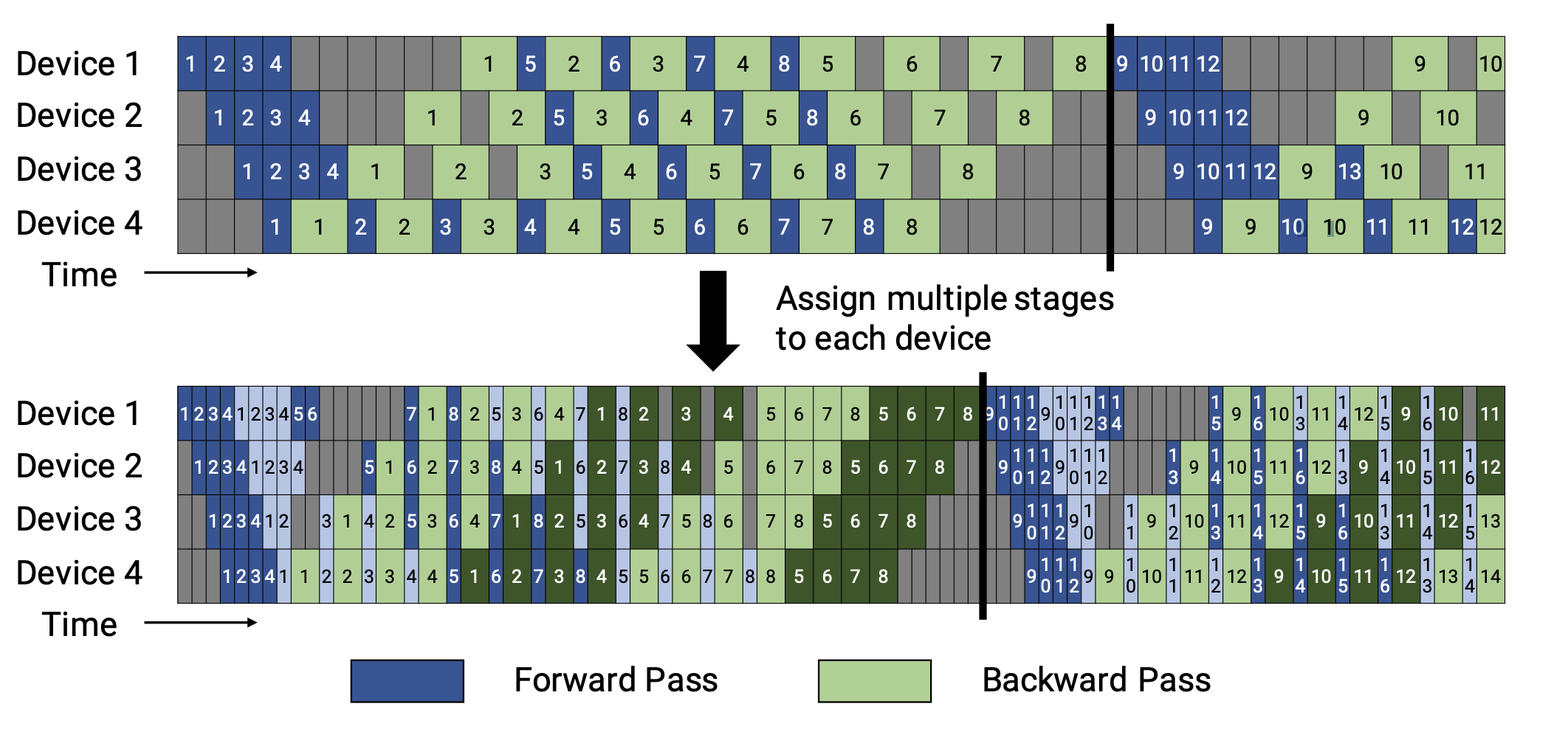 Figure2: 图片来自论文 Megatron-LM 。上面的部分显示了默认的非交错 schedule,底部显示的是交错的 schedule。
### 非交错 Schedule
非交错式 schedule 可分为三个阶段。第一阶段是热身阶段,处理器进行不同数量的前向计算。在接下来的阶段,处理器进行一次前向计算,然后是一次后向计算。处理器将在最后一个阶段完成后向计算。
这种模式比 GPipe 更节省内存。然而,它需要和 GPipe 一样的时间来完成一轮计算。
### 交错 Schedule
这个 schedule 要求**microbatches的数量是流水线阶段的整数倍**。
在这个 schedule 中,每个设备可以对多个层的子集(称为模型块)进行计算,而不是一个连续层的集合。具体来看,之前设备1拥有层1-4,设备2拥有层5-8,以此类推;但现在设备1有层1,2,9,10,设备2有层3,4,11,12,以此类推。
在该模式下,流水线上的每个设备都被分配到多个流水线阶段,每个流水线阶段的计算量较少。
这种模式既节省内存又节省时间。
## 使用schedule
在 Colossal-AI 中, 我们提供非交错(`PipelineSchedule`) 和交错(`InterleavedPipelineSchedule`)schedule。
你只需要在配置文件中,设置 `NUM_MICRO_BATCHES` 并在你想使用交错schedule的时候,设置 `NUM_CHUNKS`。 如果你确定性地知道每个管道阶段的输出张量的形状,而且形状都是一样的,你可以设置 `tensor_shape` 以进一步减少通信。否则,你可以忽略 `tensor_shape` , 形状将在管道阶段之间自动交换。 我们将会根据用户提供的配置文件,生成一个合适schedule来支持用户的流水并行训练。
## 使用流水线训练 ResNet
我们首先用Colossal PipelinableContext方式建立 `ResNet` 模型:
```python
import os
from typing import Callable, List, Optional, Type, Union
import torch
import torch.nn as nn
import colossalai
import colossalai.nn as col_nn
from colossalai.core import global_context as gpc
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.trainer import Trainer, hooks
from colossalai.utils import MultiTimer, get_dataloader
from colossalai.context import ParallelMode
from colossalai.pipeline.pipelinable import PipelinableContext
from titans.dataloader.cifar10 import build_cifar
from torchvision.models import resnet50
from torchvision.models.resnet import BasicBlock, Bottleneck, conv1x1
# Define some config
BATCH_SIZE = 64
NUM_EPOCHS = 2
NUM_CHUNKS = 1
CONFIG = dict(NUM_MICRO_BATCHES=4, parallel=dict(pipeline=2))
# Train
disable_existing_loggers()
parser = colossalai.get_default_parser()
args = parser.parse_args()
colossalai.launch_from_torch(backend=args.backend, config=CONFIG)
logger = get_dist_logger()
pipelinable = PipelinableContext()
# build model
with pipelinable:
model = resnet50()
```
给定切分顺序,module直接给出name,部分函数需要手动添加。
```python
exec_seq = [
'conv1', 'bn1', 'relu', 'maxpool', 'layer1', 'layer2', 'layer3', 'layer4', 'avgpool',
(lambda x: torch.flatten(x, 1), "behind"), 'fc'
]
pipelinable.to_layer_list(exec_seq)
```
将模型切分成流水线阶段。
```python
model = pipelinable.partition(NUM_CHUNKS, gpc.pipeline_parallel_size, gpc.get_local_rank(ParallelMode.PIPELINE))
```
我们使用`Trainer`训练`ResNet`:
```python
# build criterion
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# build dataloader
root = os.environ.get('DATA', './data')
train_dataloader, test_dataloader = build_cifar(BATCH_SIZE, root, padding=4, crop=32, resize=32)
lr_scheduler = col_nn.lr_scheduler.LinearWarmupLR(optimizer, NUM_EPOCHS, warmup_steps=1)
engine, train_dataloader, test_dataloader, lr_scheduler = colossalai.initialize(model, optimizer, criterion,
train_dataloader, test_dataloader,
lr_scheduler)
timer = MultiTimer()
trainer = Trainer(engine=engine, timer=timer, logger=logger)
hook_list = [
hooks.LossHook(),
hooks.AccuracyHook(col_nn.metric.Accuracy()),
hooks.LogMetricByEpochHook(logger),
hooks.LRSchedulerHook(lr_scheduler, by_epoch=True)
]
trainer.fit(train_dataloader=train_dataloader,
epochs=NUM_EPOCHS,
test_dataloader=test_dataloader,
test_interval=1,
hooks=hook_list,
display_progress=True)
```
我们使用 `2` 个流水段,并且 batch 将被切分为 `4` 个 micro batches。
Figure2: 图片来自论文 Megatron-LM 。上面的部分显示了默认的非交错 schedule,底部显示的是交错的 schedule。
### 非交错 Schedule
非交错式 schedule 可分为三个阶段。第一阶段是热身阶段,处理器进行不同数量的前向计算。在接下来的阶段,处理器进行一次前向计算,然后是一次后向计算。处理器将在最后一个阶段完成后向计算。
这种模式比 GPipe 更节省内存。然而,它需要和 GPipe 一样的时间来完成一轮计算。
### 交错 Schedule
这个 schedule 要求**microbatches的数量是流水线阶段的整数倍**。
在这个 schedule 中,每个设备可以对多个层的子集(称为模型块)进行计算,而不是一个连续层的集合。具体来看,之前设备1拥有层1-4,设备2拥有层5-8,以此类推;但现在设备1有层1,2,9,10,设备2有层3,4,11,12,以此类推。
在该模式下,流水线上的每个设备都被分配到多个流水线阶段,每个流水线阶段的计算量较少。
这种模式既节省内存又节省时间。
## 使用schedule
在 Colossal-AI 中, 我们提供非交错(`PipelineSchedule`) 和交错(`InterleavedPipelineSchedule`)schedule。
你只需要在配置文件中,设置 `NUM_MICRO_BATCHES` 并在你想使用交错schedule的时候,设置 `NUM_CHUNKS`。 如果你确定性地知道每个管道阶段的输出张量的形状,而且形状都是一样的,你可以设置 `tensor_shape` 以进一步减少通信。否则,你可以忽略 `tensor_shape` , 形状将在管道阶段之间自动交换。 我们将会根据用户提供的配置文件,生成一个合适schedule来支持用户的流水并行训练。
## 使用流水线训练 ResNet
我们首先用Colossal PipelinableContext方式建立 `ResNet` 模型:
```python
import os
from typing import Callable, List, Optional, Type, Union
import torch
import torch.nn as nn
import colossalai
import colossalai.nn as col_nn
from colossalai.core import global_context as gpc
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.trainer import Trainer, hooks
from colossalai.utils import MultiTimer, get_dataloader
from colossalai.context import ParallelMode
from colossalai.pipeline.pipelinable import PipelinableContext
from titans.dataloader.cifar10 import build_cifar
from torchvision.models import resnet50
from torchvision.models.resnet import BasicBlock, Bottleneck, conv1x1
# Define some config
BATCH_SIZE = 64
NUM_EPOCHS = 2
NUM_CHUNKS = 1
CONFIG = dict(NUM_MICRO_BATCHES=4, parallel=dict(pipeline=2))
# Train
disable_existing_loggers()
parser = colossalai.get_default_parser()
args = parser.parse_args()
colossalai.launch_from_torch(backend=args.backend, config=CONFIG)
logger = get_dist_logger()
pipelinable = PipelinableContext()
# build model
with pipelinable:
model = resnet50()
```
给定切分顺序,module直接给出name,部分函数需要手动添加。
```python
exec_seq = [
'conv1', 'bn1', 'relu', 'maxpool', 'layer1', 'layer2', 'layer3', 'layer4', 'avgpool',
(lambda x: torch.flatten(x, 1), "behind"), 'fc'
]
pipelinable.to_layer_list(exec_seq)
```
将模型切分成流水线阶段。
```python
model = pipelinable.partition(NUM_CHUNKS, gpc.pipeline_parallel_size, gpc.get_local_rank(ParallelMode.PIPELINE))
```
我们使用`Trainer`训练`ResNet`:
```python
# build criterion
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# build dataloader
root = os.environ.get('DATA', './data')
train_dataloader, test_dataloader = build_cifar(BATCH_SIZE, root, padding=4, crop=32, resize=32)
lr_scheduler = col_nn.lr_scheduler.LinearWarmupLR(optimizer, NUM_EPOCHS, warmup_steps=1)
engine, train_dataloader, test_dataloader, lr_scheduler = colossalai.initialize(model, optimizer, criterion,
train_dataloader, test_dataloader,
lr_scheduler)
timer = MultiTimer()
trainer = Trainer(engine=engine, timer=timer, logger=logger)
hook_list = [
hooks.LossHook(),
hooks.AccuracyHook(col_nn.metric.Accuracy()),
hooks.LogMetricByEpochHook(logger),
hooks.LRSchedulerHook(lr_scheduler, by_epoch=True)
]
trainer.fit(train_dataloader=train_dataloader,
epochs=NUM_EPOCHS,
test_dataloader=test_dataloader,
test_interval=1,
hooks=hook_list,
display_progress=True)
```
我们使用 `2` 个流水段,并且 batch 将被切分为 `4` 个 micro batches。