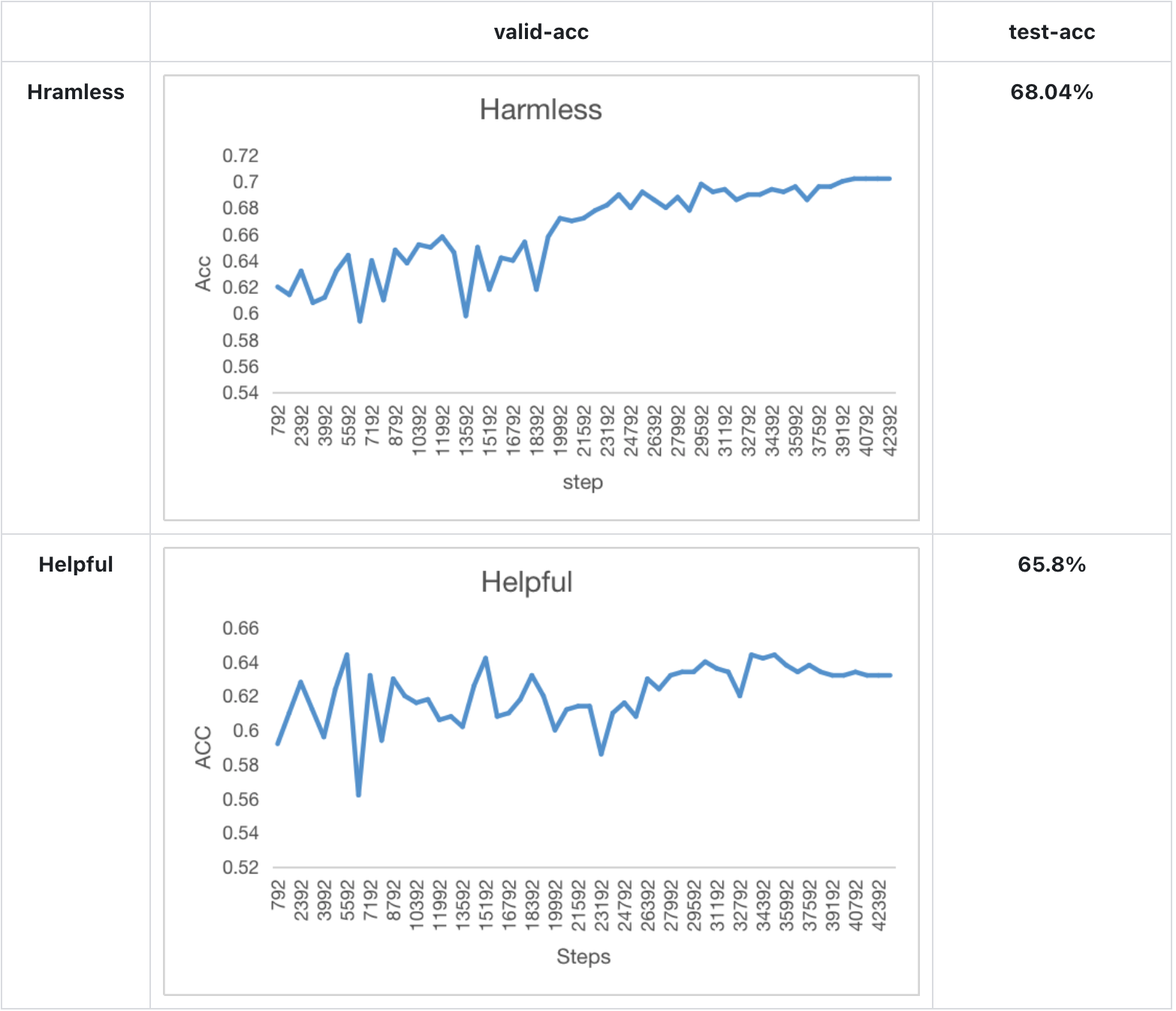
We also train the reward model based on LLaMA-7B, which reaches the ACC of 72.06% after 1 epoch, performing almost the same as Anthropic's best RM.
### Arg List
- --strategy: the strategy using for training, choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
- --model: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
- --pretrain: pretrain model, type=str, default=None
- --model_path: the path of rm model(if continue to train), type=str, default=None
- --save_path: path to save the model, type=str, default='output'
- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
- --max_epochs: max epochs for training, type=int, default=3
- --dataset: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
- --subset: subset of the dataset, type=str, default=None
- --batch_size: batch size while training, type=int, default=4
- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
- --loss_func: which kind of loss function, choices=['log_sig', 'log_exp']
- --max_len: max sentence length for generation, type=int, default=512
- --test: whether is only testing, if it's true, the dataset will be small
## Stage3 - Training model using prompts with RL
Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process, as shown below:
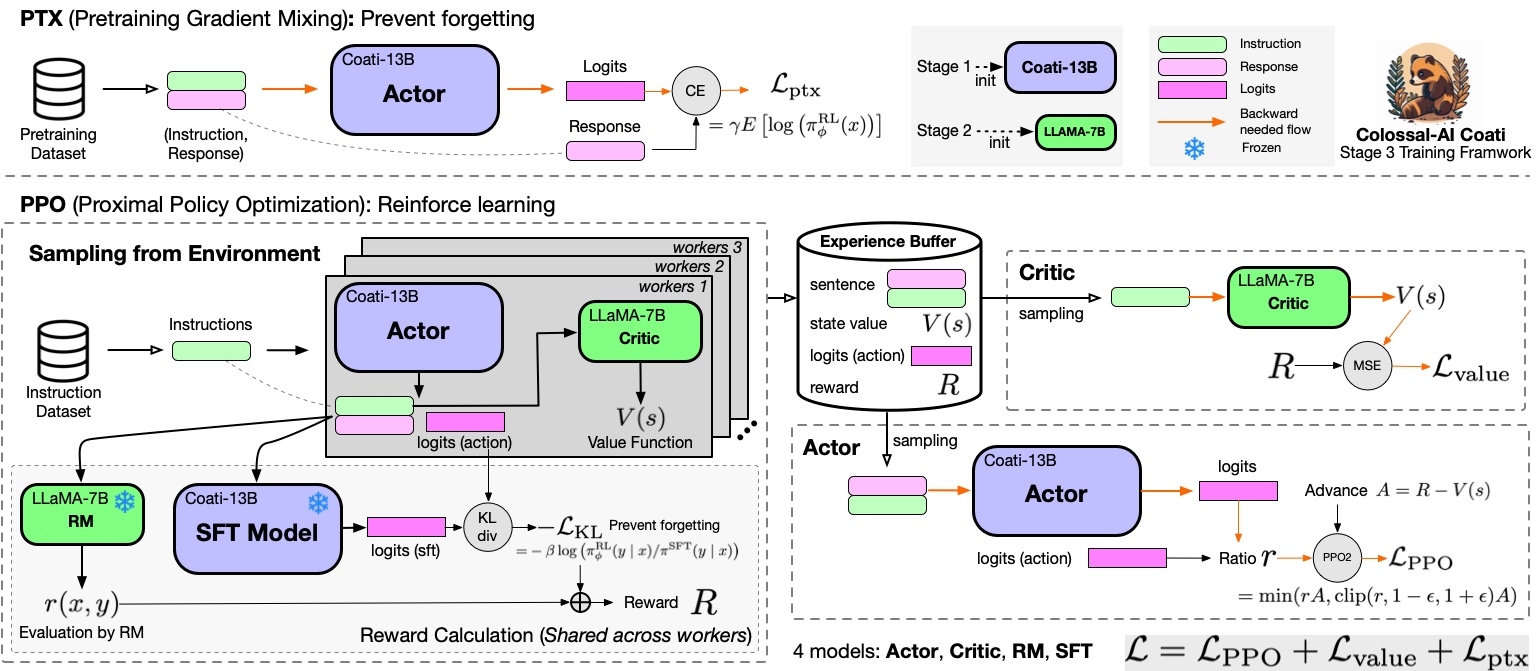
You can run the `examples/train_prompts.sh` to start PPO training.
You can also use the cmd following to start PPO training.
```
torchrun --standalone --nproc_per_node=4 train_prompts.py \
--pretrain "/path/to/LLaMa-7B/" \
--model 'llama' \
--strategy colossalai_zero2 \
--prompt_dataset /path/to/your/prompt_dataset \
--pretrain_dataset /path/to/your/pretrain_dataset \
--rm_pretrain /your/pretrain/rm/definition \
--rm_path /your/rm/model/path
```
Prompt dataset: the instruction dataset mentioned in the above figure which includes the instructions, e.g. you can use the [script](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/example_data_reformat.py) to reformat [seed_prompts_ch.jsonl](https://github.com/XueFuzhao/InstructionWild/blob/main/data/seed_prompts_ch.jsonl) or [seed_prompts_en.jsonl](https://github.com/XueFuzhao/InstructionWild/blob/main/data/seed_prompts_en.jsonl) in InstructionWild.
Pretrain dataset: the pretrain dataset including the instruction and corresponding response, e.g. you can use the [InstructWild Data](https://github.com/XueFuzhao/InstructionWild/tree/main/data) in stage 1 supervised instructs tuning.
### Arg List
- --strategy: the strategy using for training, choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
- --model: model type of actor, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
- --pretrain: pretrain model, type=str, default=None
- --rm_model: reward model type, type=str, choices=['gpt2', 'bloom', 'opt', 'llama'], default=None
- --rm_pretrain: pretrain model for reward model, type=str, default=None
- --rm_path: the path of rm model, type=str, default=None
- --save_path: path to save the model, type=str, default='output'
- --prompt_dataset: path of the prompt dataset, type=str, default=None
- --pretrain_dataset: path of the ptx dataset, type=str, default=None
- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
- --num_episodes: num of episodes for training, type=int, default=10
- --max_epochs: max epochs for training in one episode, type=int, default=5
- --max_timesteps: max episodes in one batch, type=int, default=10
- --update_timesteps: timesteps to update, type=int, default=10
- --train_batch_size: batch size while training, type=int, default=8
- --ptx_batch_size: batch size to compute ptx loss, type=int, default=1
- --experience_batch_size: batch size to make experience, type=int, default=8
- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
- --kl_coef: kl_coef using for computing reward, type=float, default=0.1
- --ptx_coef: ptx_coef using for computing policy loss, type=float, default=0.9
## Inference example - After Stage3
We support different inference options, including int8 and int4 quantization.
For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
## Attention
The examples are demos for the whole training process.You need to change the hyper-parameters to reach great performance.
#### data
- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
- [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
- [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
- [ ] [openai/webgpt_comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)
- [ ] [Dahoas/instruct-synthetic-prompt-responses](https://huggingface.co/datasets/Dahoas/instruct-synthetic-prompt-responses)
## Support Model
### GPT
- [x] GPT2-S (s)
- [x] GPT2-M (m)
- [x] GPT2-L (l)
- [x] GPT2-XL (xl)
- [x] GPT2-4B (4b)
- [ ] GPT2-6B (6b)
### BLOOM
- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
- [x] [BLOOM-7b](https://huggingface.co/bigscience/bloom-7b1)
- [ ] [BLOOM-175b](https://huggingface.co/bigscience/bloom)
### OPT
- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
- [x] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
- [x] [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b)
- [x] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
### [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md)
- [x] LLaMA-7B
- [x] LLaMA-13B
- [ ] LLaMA-33B
- [ ] LLaMA-65B
## Add your own models
If you want to support your own model in Coati, please refer the pull request for RoBERTa support as an example --[[chatgpt] add pre-trained model RoBERTa for RLHF stage 2 & 3](https://github.com/hpcaitech/ColossalAI/pull/3223), and submit a PR to us.
You should complete the implementation of four model classes, including Reward model, Critic model, LM model, Actor model
here are some example code for a NewModel named `Coati`.
if it is supported in huggingface [transformers](https://github.com/huggingface/transformers), you can load it by `from_pretrained`, o
r you can build your own model by yourself.
### Actor model
```
from ..base import Actor
from transformers.models.coati import CoatiModel
class CoatiActor(Actor):
def __init__(self,
pretrained: Optional[str] = None,
checkpoint: bool = False,
lora_rank: int = 0,
lora_train_bias: str = 'none') -> None:
if pretrained is not None:
model = CoatiModel.from_pretrained(pretrained)
else:
model = build_model() # load your own model if it is not support in transformers
super().__init__(model, lora_rank, lora_train_bias)
```
### Reward model
```
from ..base import RewardModel
from transformers.models.coati import CoatiModel
class CoatiRM(RewardModel):
def __init__(self,
pretrained: Optional[str] = None,
checkpoint: bool = False,
lora_rank: int = 0,
lora_train_bias: str = 'none') -> None:
if pretrained is not None:
model = CoatiModel.from_pretrained(pretrained)
else:
model = build_model() # load your own model if it is not support in transformers
value_head = nn.Linear(model.config.n_embd, 1)
value_head.weight.data.normal_(mean=0.0, std=1 / (model.config.n_embd + 1))
super().__init__(model, value_head, lora_rank, lora_train_bias)
```
### Critic model
```
from ..base import Critic
from transformers.models.coati import CoatiModel
class CoatiCritic(Critic):
def __init__(self,
pretrained: Optional[str] = None,
checkpoint: bool = False,
lora_rank: int = 0,
lora_train_bias: str = 'none') -> None:
if pretrained is not None:
model = CoatiModel.from_pretrained(pretrained)
else:
model = build_model() # load your own model if it is not support in transformers
value_head = nn.Linear(model.config.n_embd, 1)
value_head.weight.data.normal_(mean=0.0, std=1 / (model.config.n_embd + 1))
super().__init__(model, value_head, lora_rank, lora_train_bias)
```