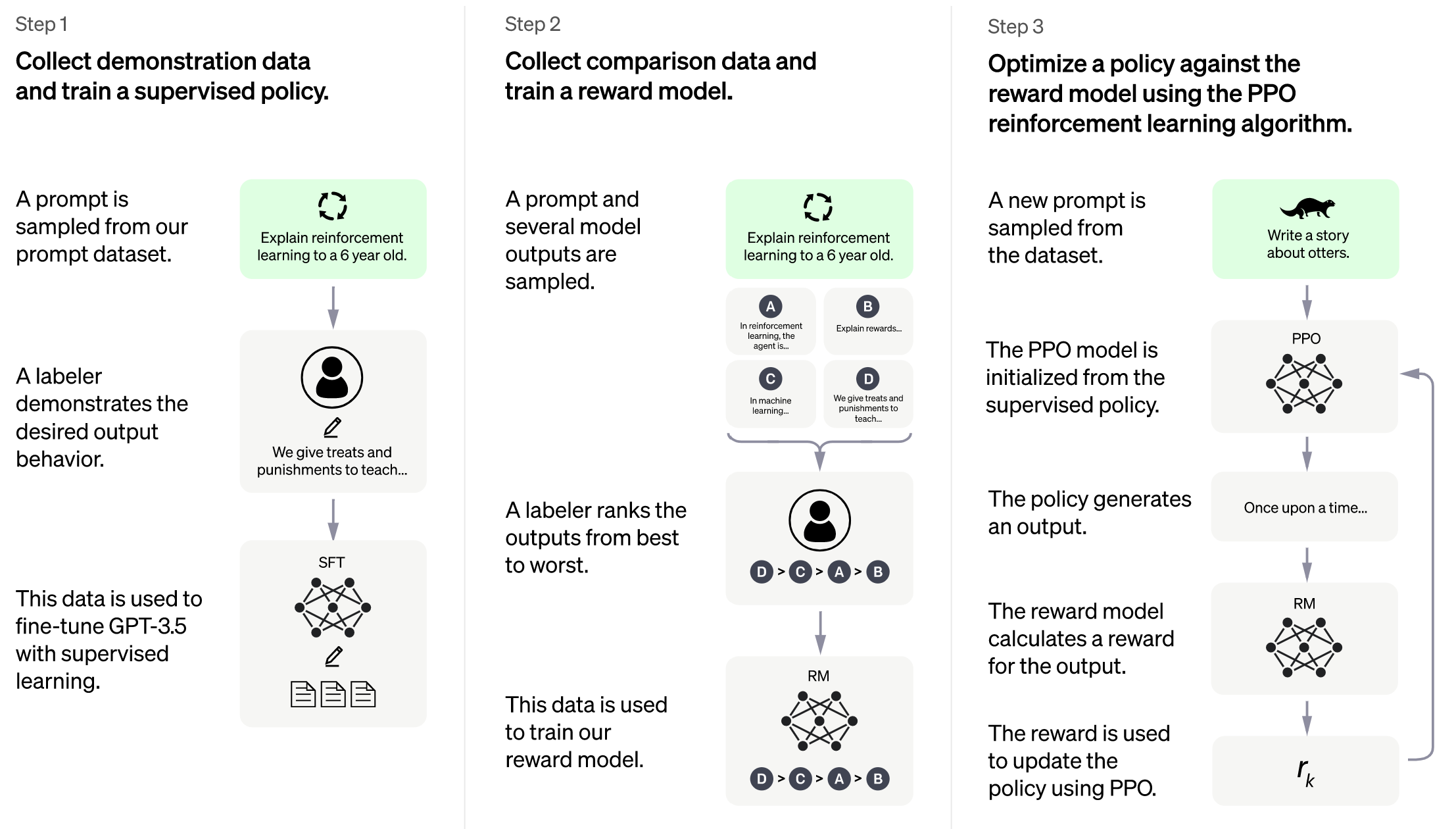
Image source: https://openai.com/blog/chatgpt
**As Colossa-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
More details can be found in the latest news.
* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
## Online demo
You can experience the performance of Coati7B on this page.
[chat.colossalai.org](https://chat.colossalai.org/)
Due to resource constraints, we will only provide this service from 29th Mar 2023 to 5 April 2023. However, we have provided the inference code in the [inference](./inference/) folder. The WebUI will be open-sourced soon as well.
> Warning: Due to model and dataset size limitations, Coati is just a baby model, Coati7B may output incorrect information and lack the ability for multi-turn dialogue. There is still significant room for improvement.
## Install
### Install the environment
```shell
conda create -n coati
conda activate coati
pip install .
```
### Install the Transformers
Given Hugging Face hasn't officially supported the LLaMA models, We fork a branch of Transformers that can be compatible with our code
```shell
git clone https://github.com/hpcaitech/transformers
cd transformers
pip install .
```
## How to use?
### Supervised datasets collection
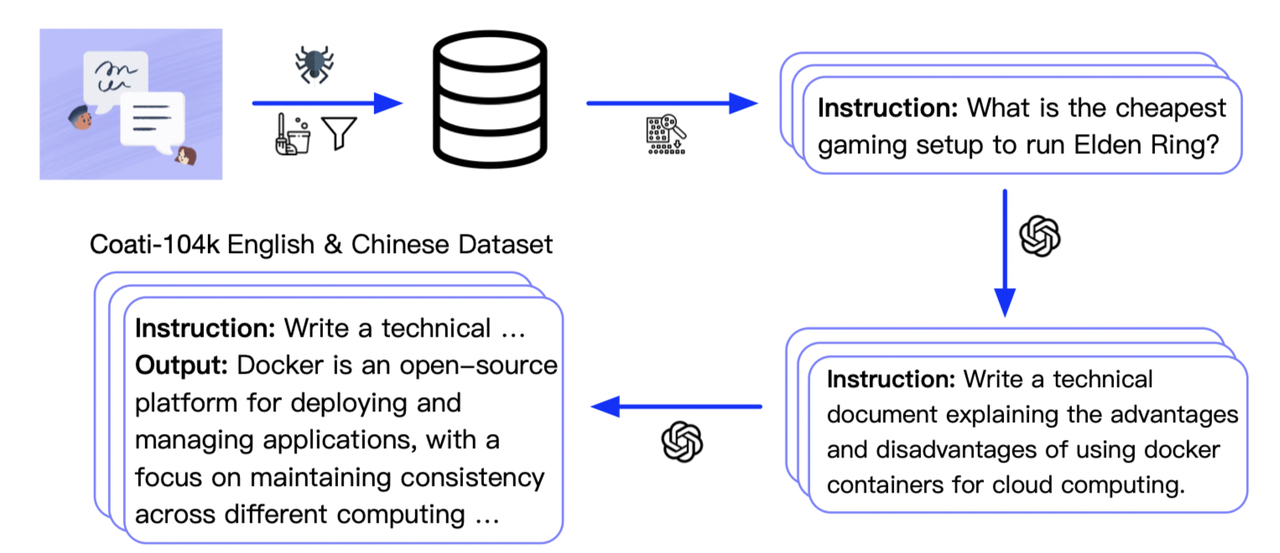
we colllected 104K bilingual dataset of Chinese and English, and you can find the datasets in this repo
[InstructionWild](https://github.com/XueFuzhao/InstructionWild)
Here is how we collected the data