[](https://www.colossalai.org/)
Colossal-AI: Making large AI models cheaper, faster, and more accessible
[](https://github.com/hpcaitech/ColossalAI/stargazers)
[](https://github.com/hpcaitech/ColossalAI/actions/workflows/build_on_schedule.yml)
[](https://colossalai.readthedocs.io/en/latest/?badge=latest)
[](https://www.codefactor.io/repository/github/hpcaitech/colossalai)
[](https://huggingface.co/hpcai-tech)
[](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack)
[](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png)
| [English](README.md) | [中文](docs/README-zh-Hans.md) |

Prof. James Demmel (UC Berkeley): Colossal-AI makes training AI models efficient, easy, and scalable.






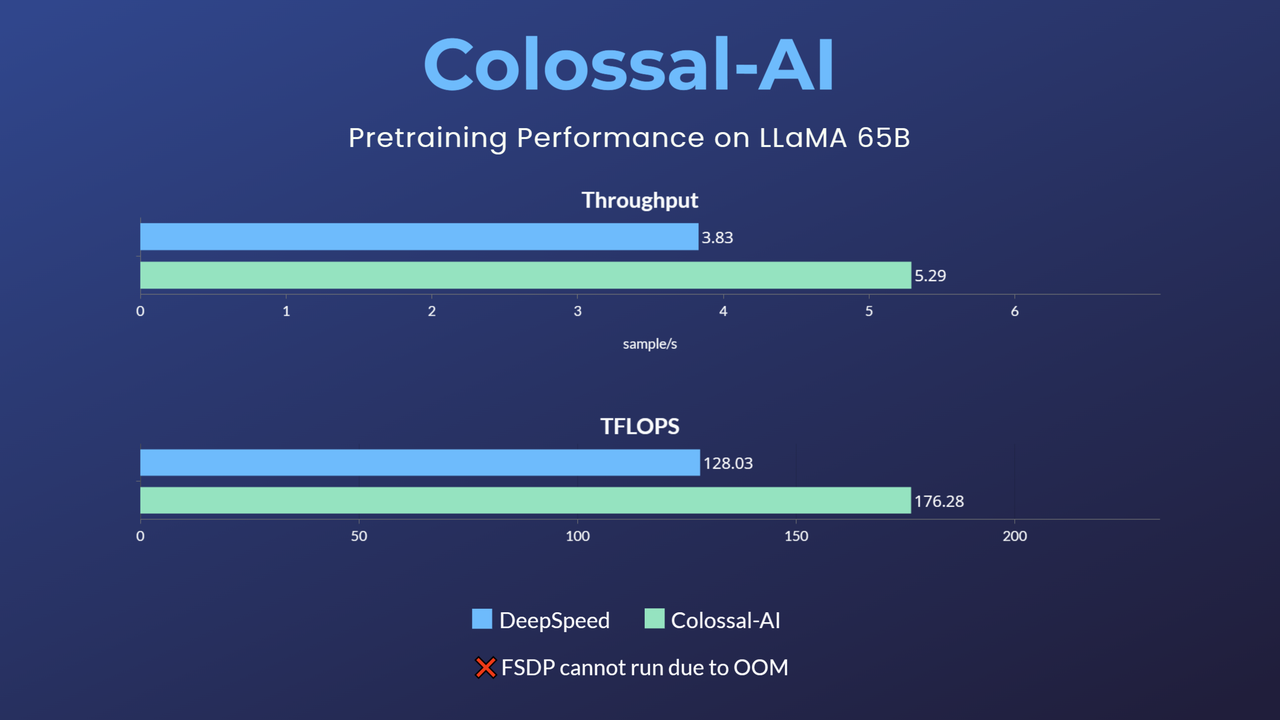
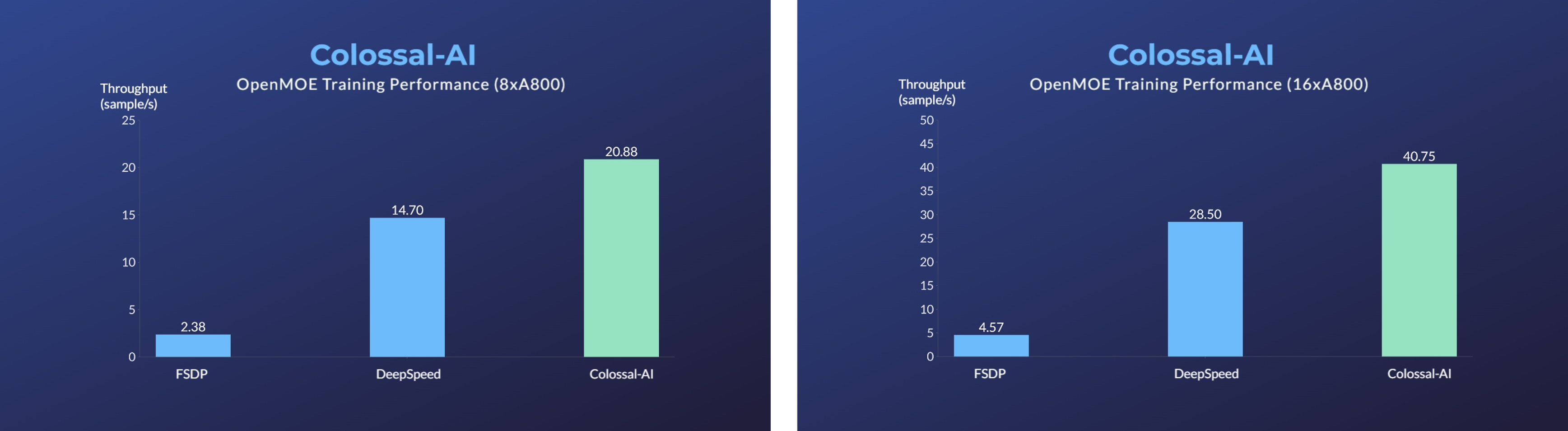
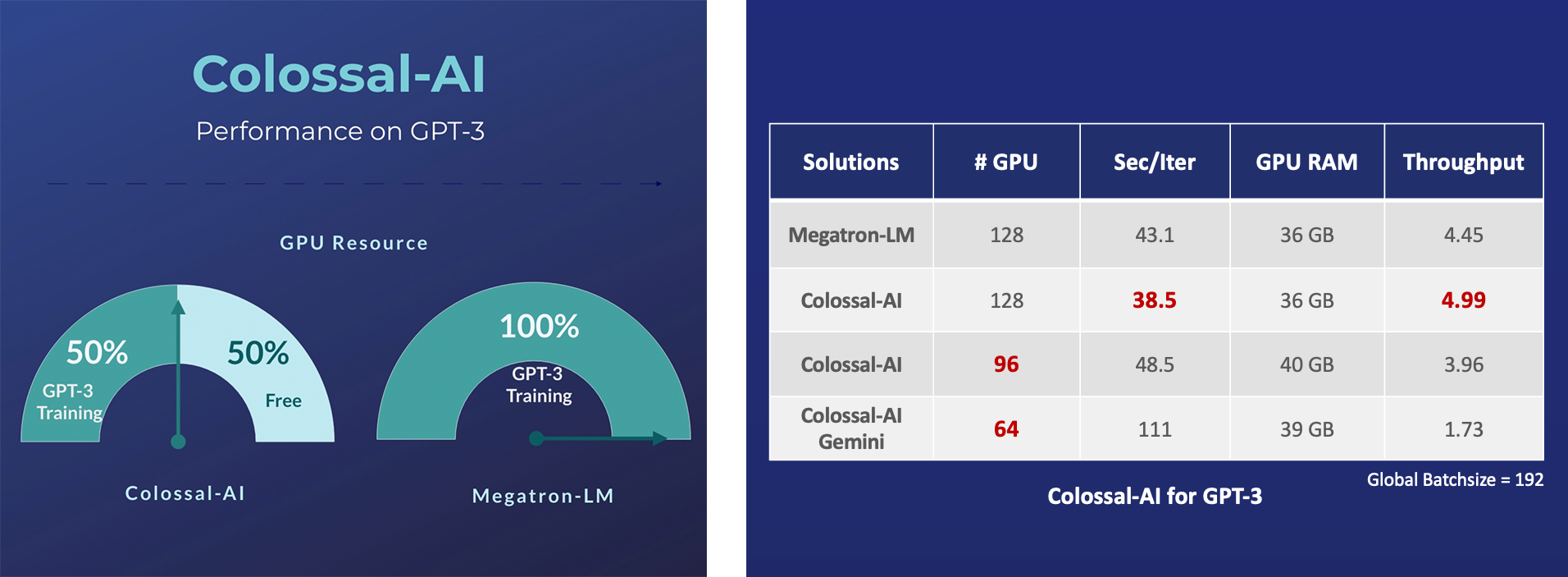
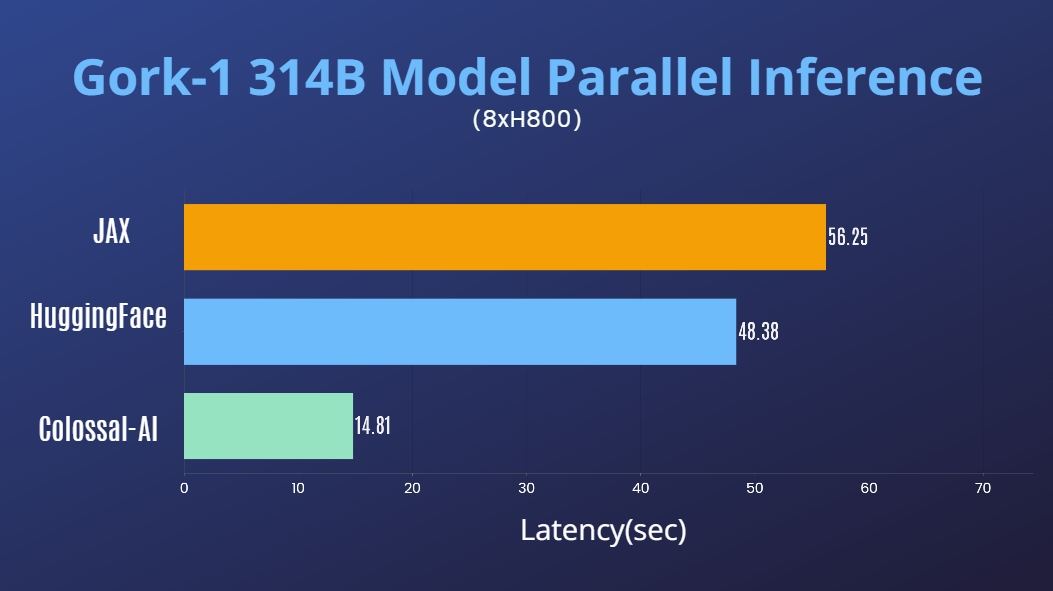
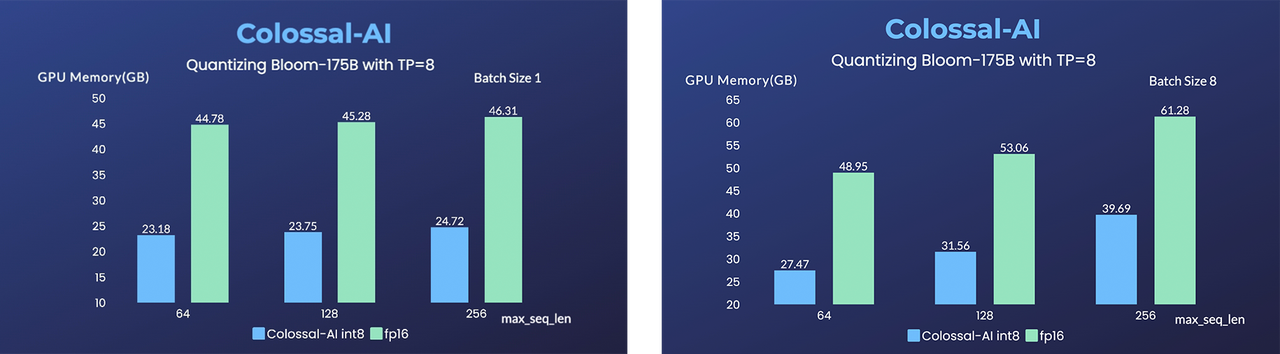
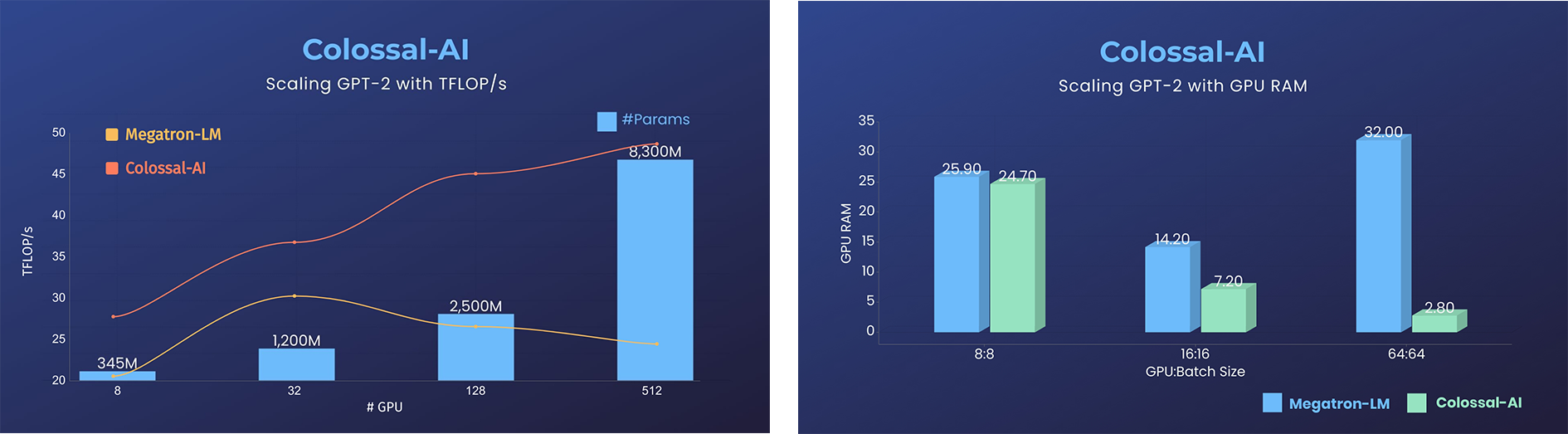 - 11x lower GPU memory consumption, and superlinear scaling efficiency with Tensor Parallelism
- 11x lower GPU memory consumption, and superlinear scaling efficiency with Tensor Parallelism
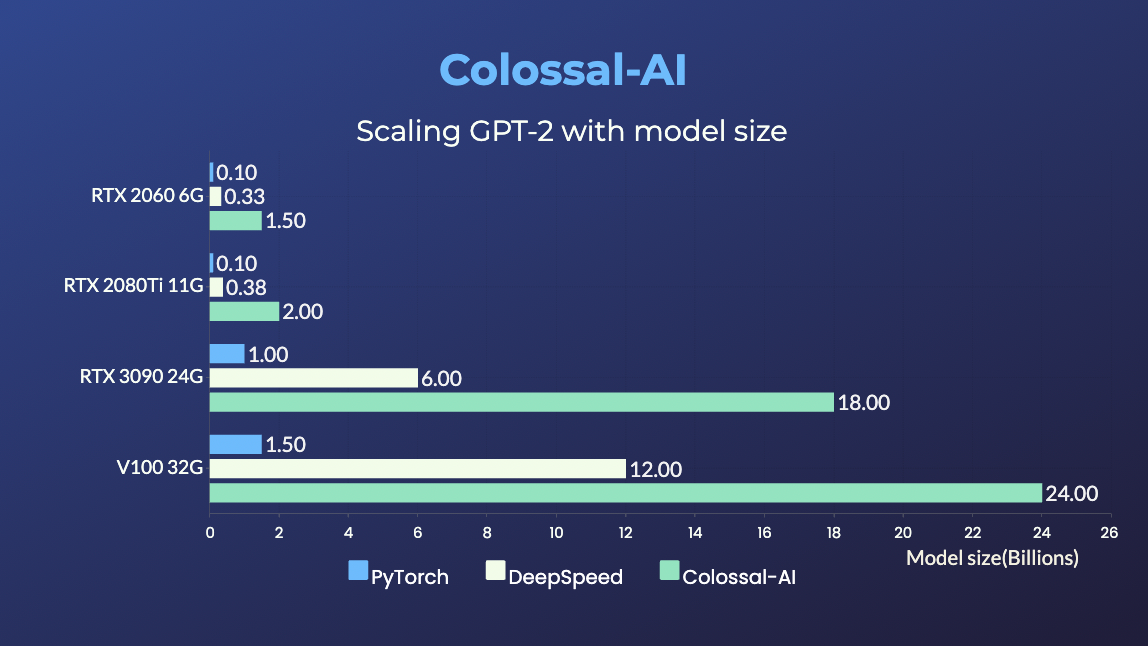
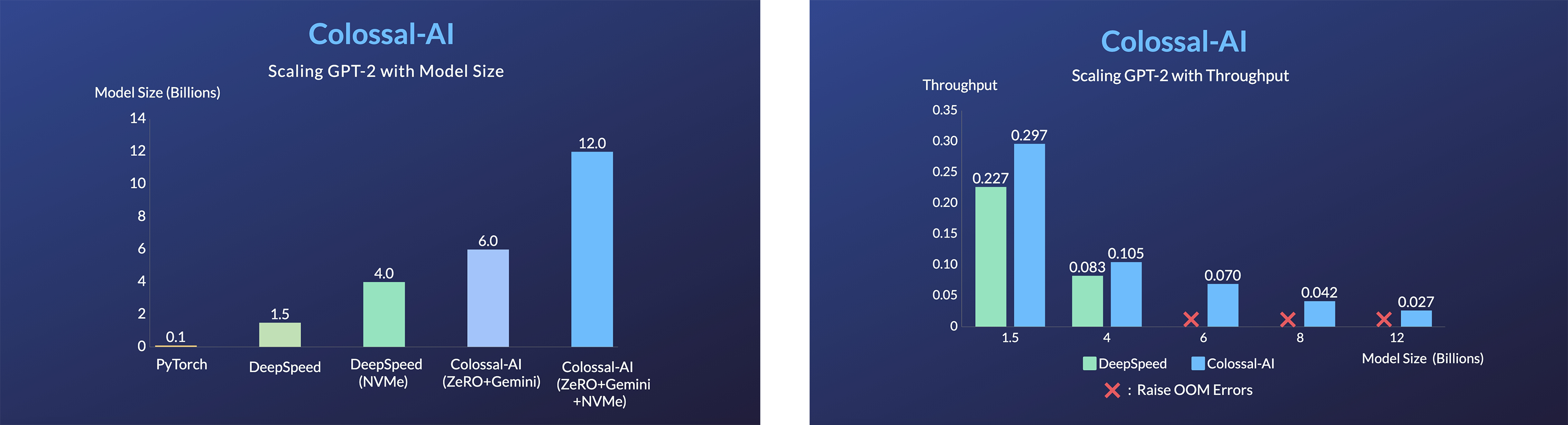
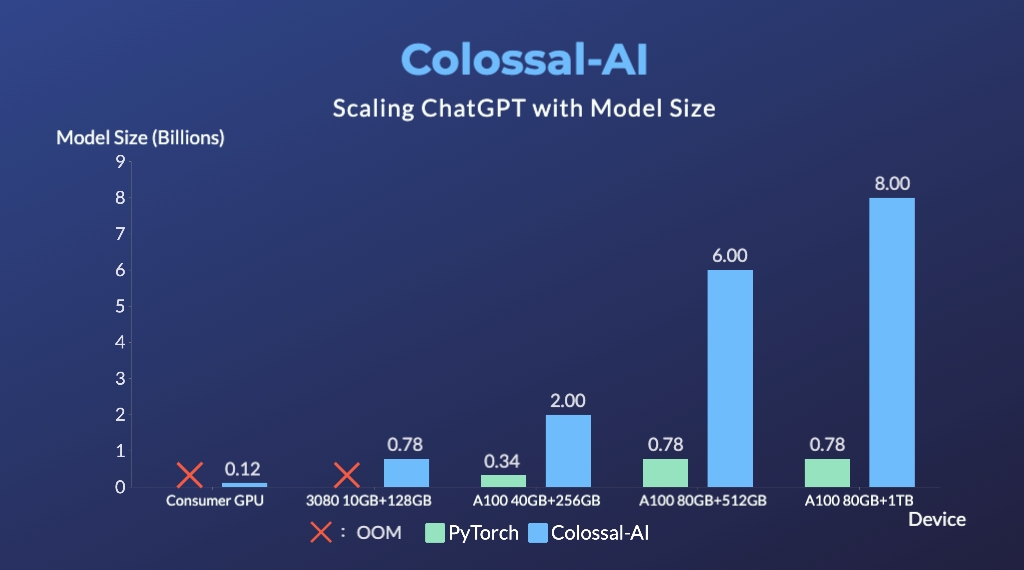
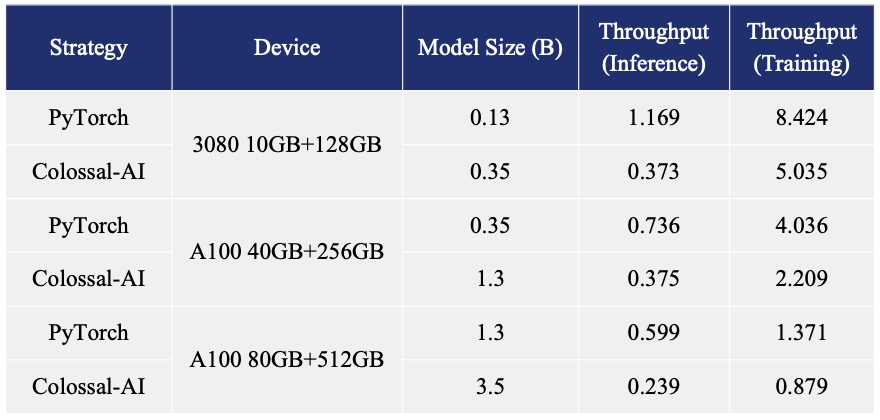
GPT-2.png) - 24x larger model size on the same hardware
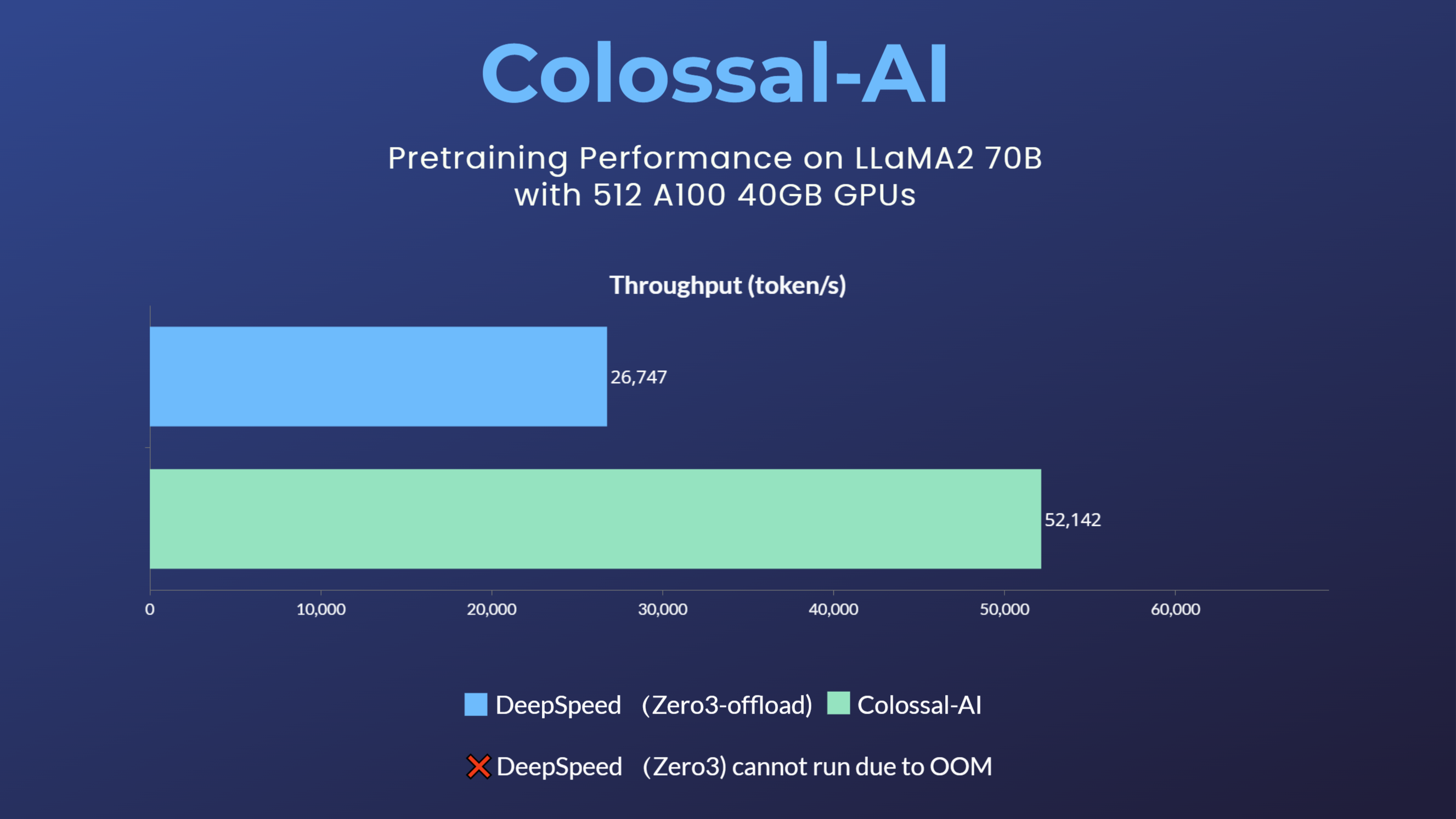
- over 3x acceleration
### BERT
- 24x larger model size on the same hardware
- over 3x acceleration
### BERT
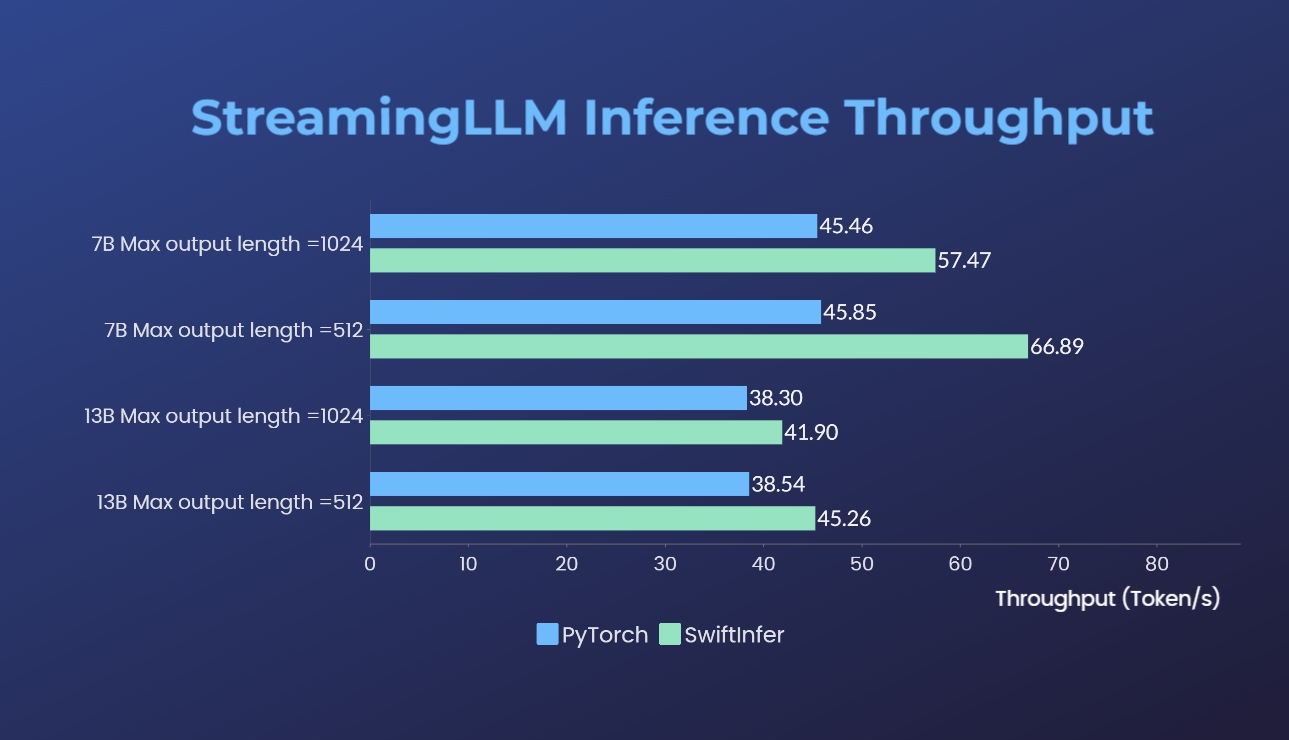
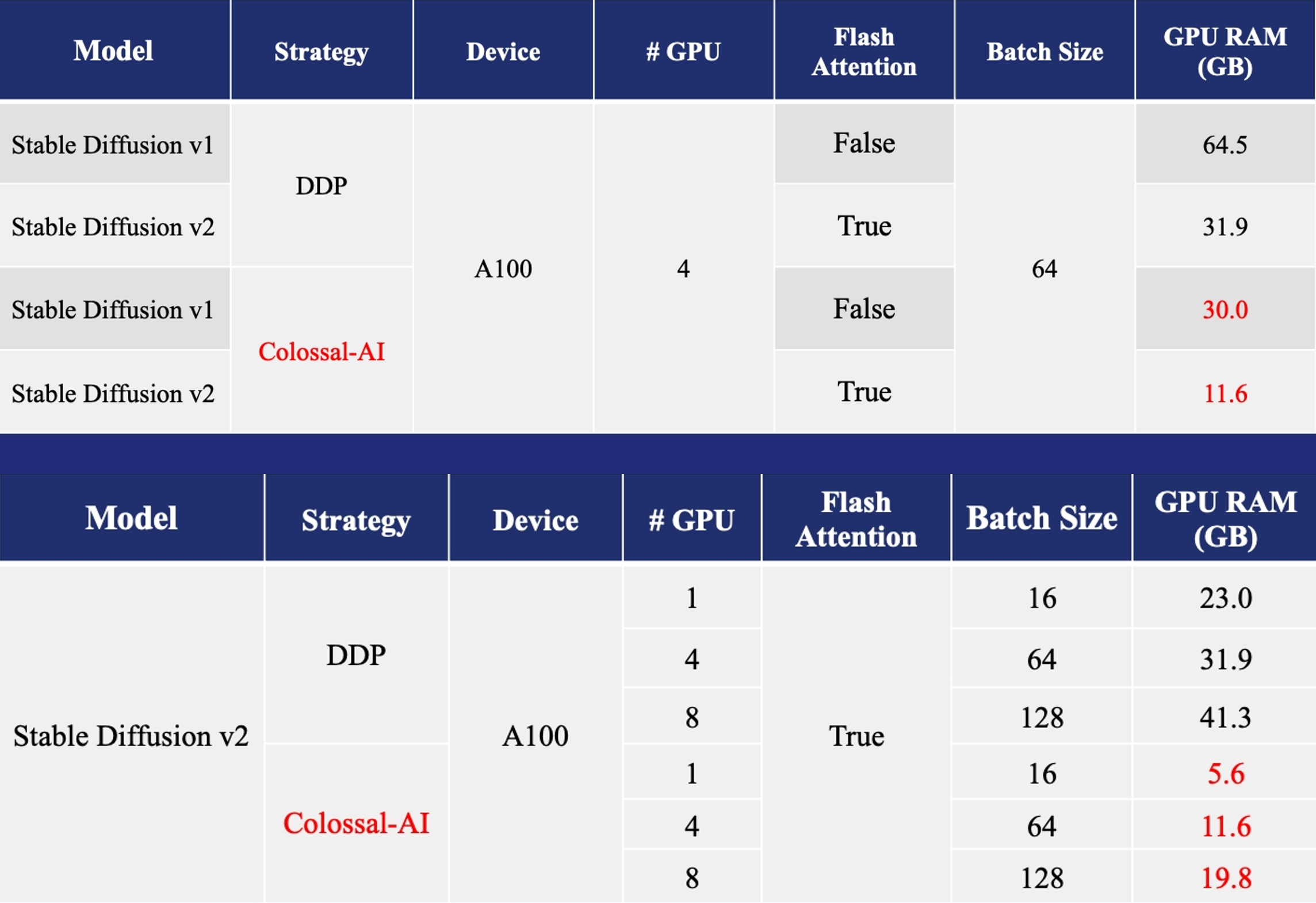
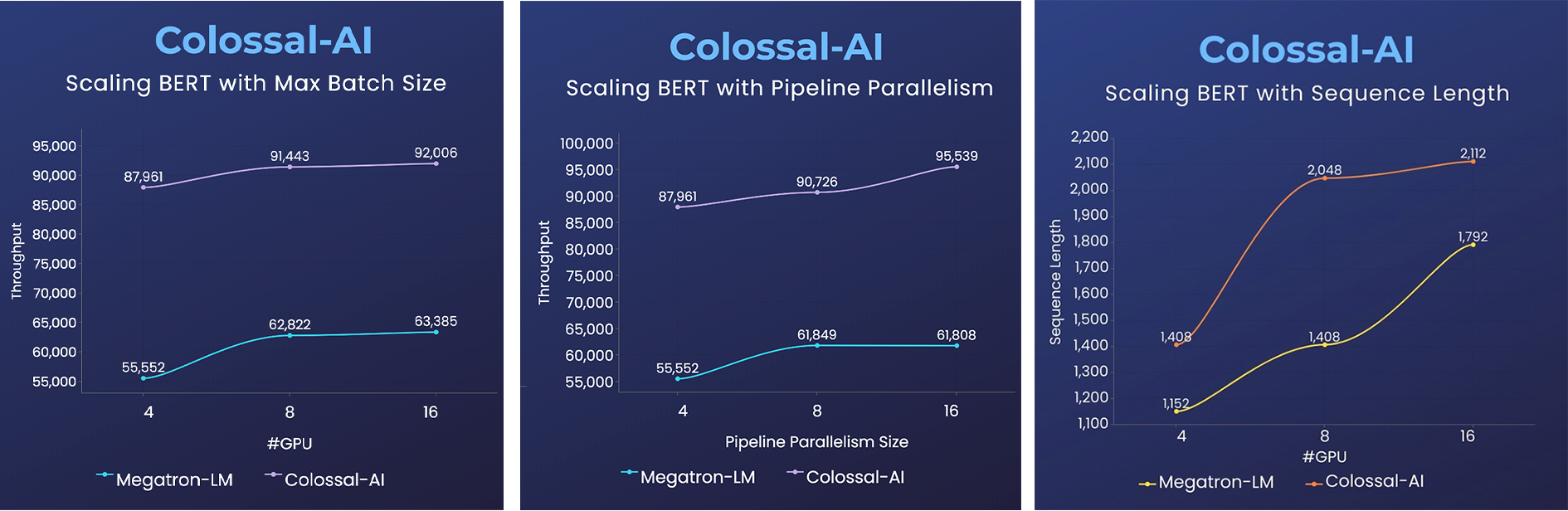 - 2x faster training, or 50% longer sequence length
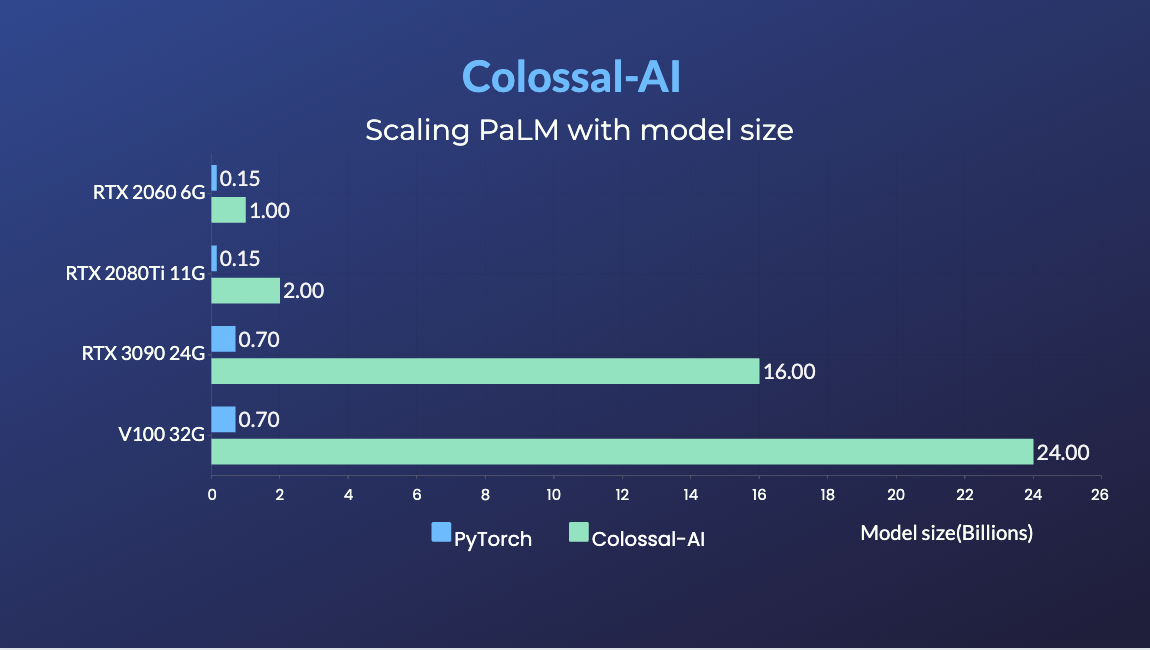
### PaLM
- [PaLM-colossalai](https://github.com/hpcaitech/PaLM-colossalai): Scalable implementation of Google's Pathways Language Model ([PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html)).
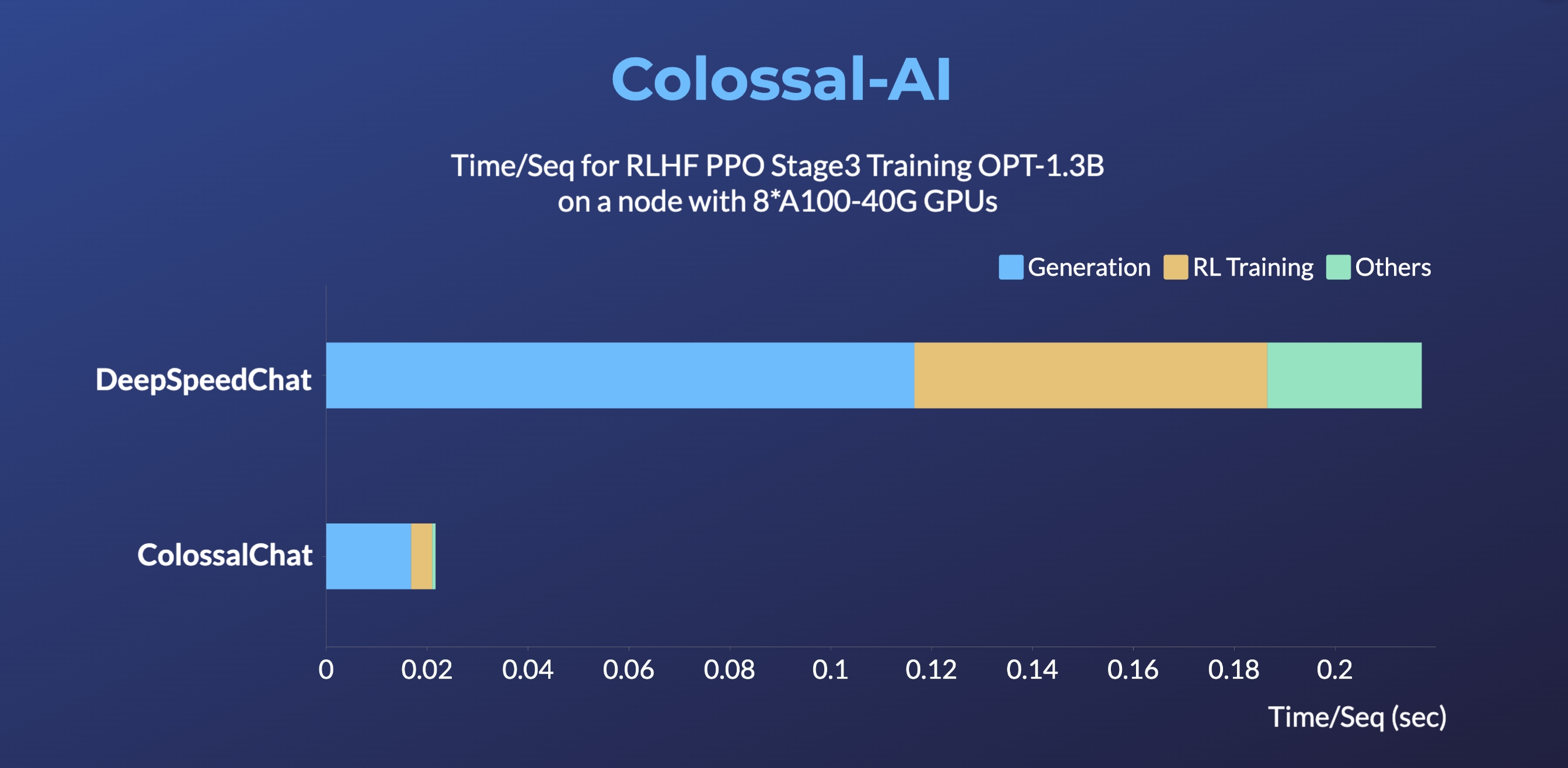
### OPT
- 2x faster training, or 50% longer sequence length
### PaLM
- [PaLM-colossalai](https://github.com/hpcaitech/PaLM-colossalai): Scalable implementation of Google's Pathways Language Model ([PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html)).
### OPT
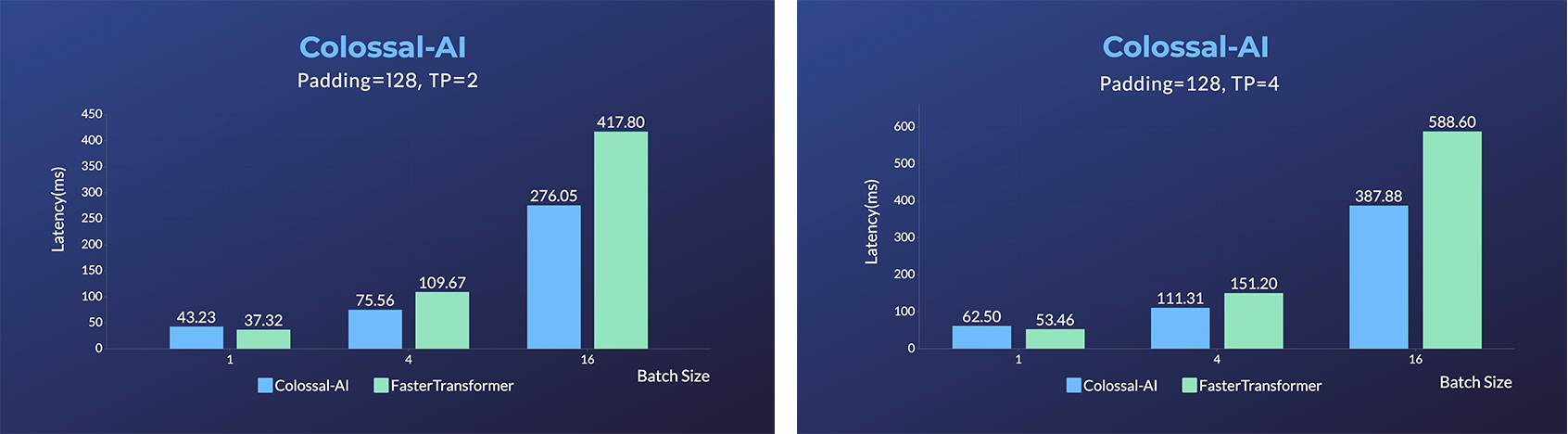
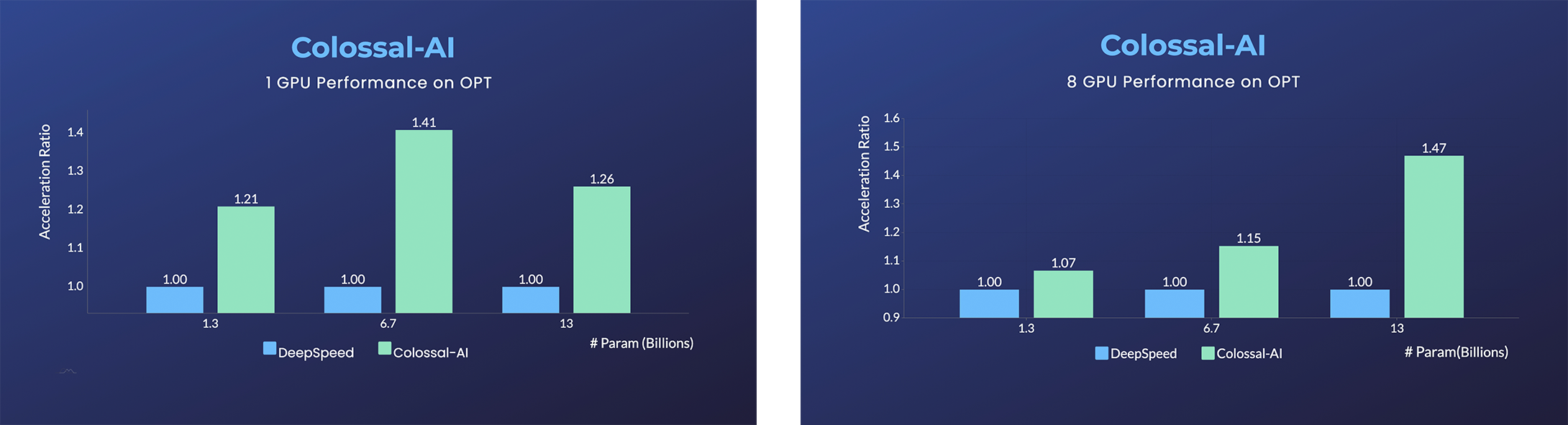 - [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because of public pre-trained model weights.
- 45% speedup fine-tuning OPT at low cost in lines. [[Example]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[Online Serving]](https://colossalai.org/docs/advanced_tutorials/opt_service)
Please visit our [documentation](https://www.colossalai.org/) and [examples](https://github.com/hpcaitech/ColossalAI/tree/main/examples) for more details.
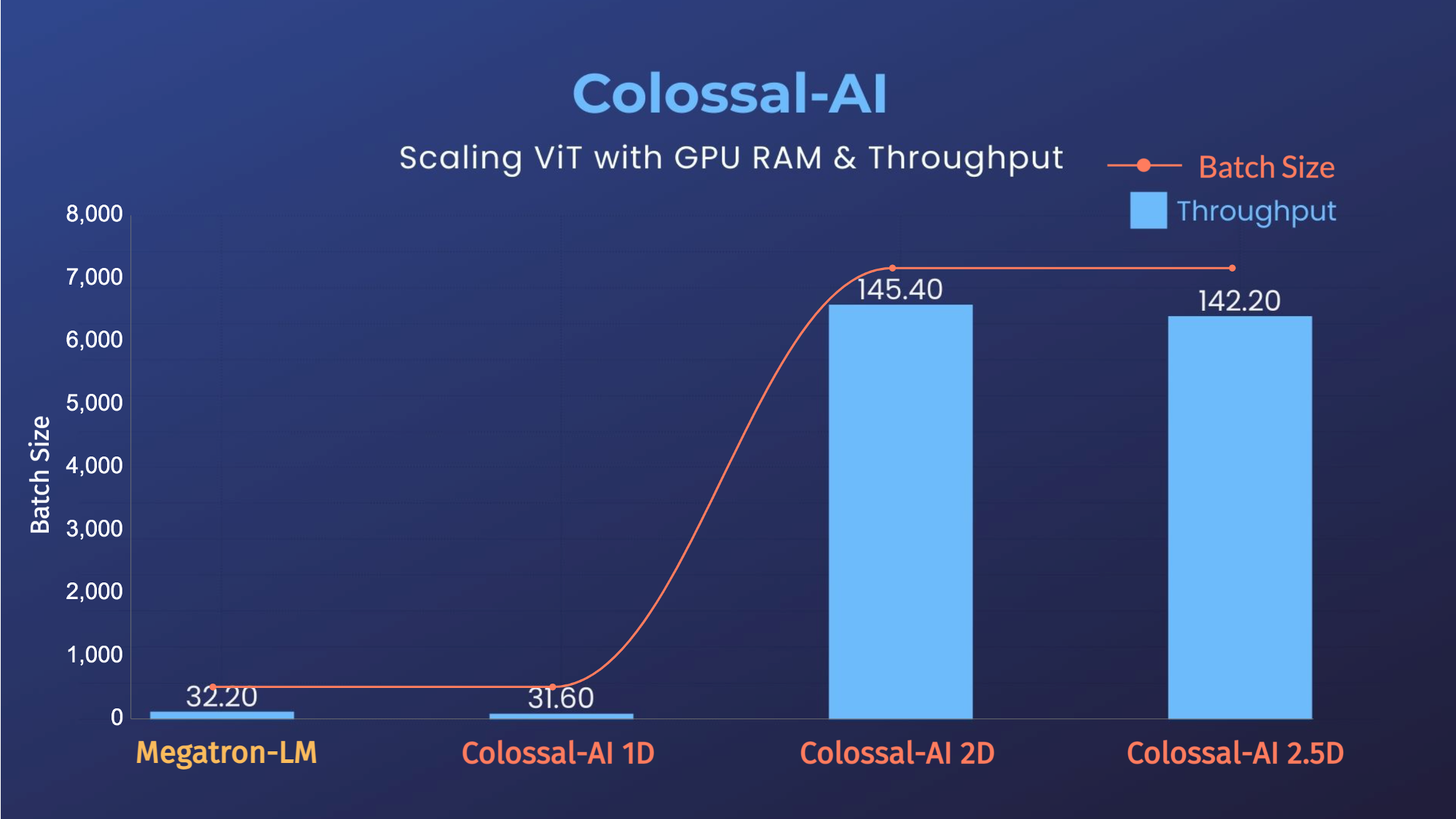
### ViT
- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because of public pre-trained model weights.
- 45% speedup fine-tuning OPT at low cost in lines. [[Example]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/opt) [[Online Serving]](https://colossalai.org/docs/advanced_tutorials/opt_service)
Please visit our [documentation](https://www.colossalai.org/) and [examples](https://github.com/hpcaitech/ColossalAI/tree/main/examples) for more details.
### ViT