# RLHF - Colossal-AI
Implementation of RLHF (Reinforcement Learning with Human Feedback) powered by Colossal-AI. It supports distributed training and offloading, which can fit extremly large models. More details can be found in the [blog](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt).
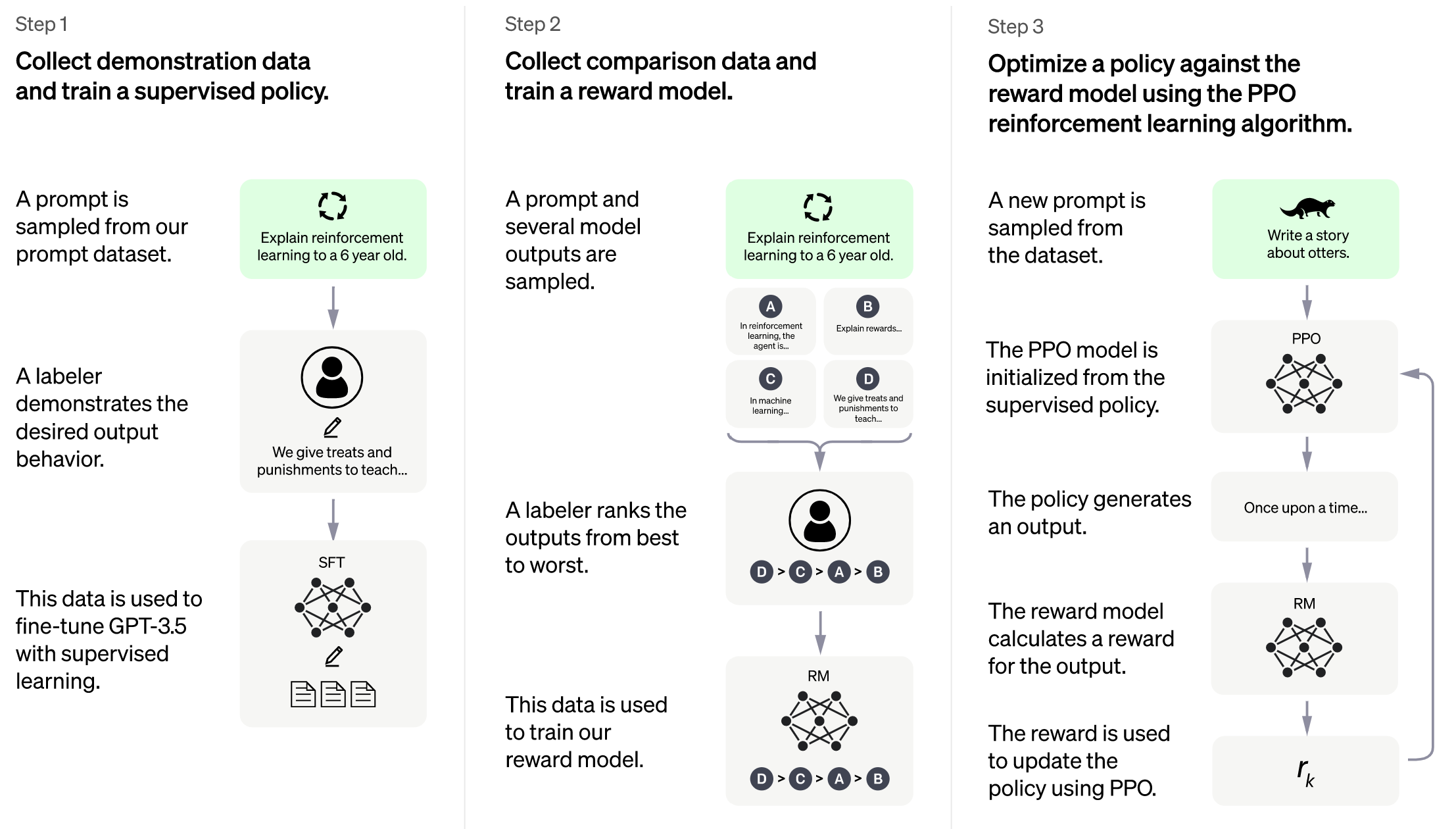
## Training process (step 3)
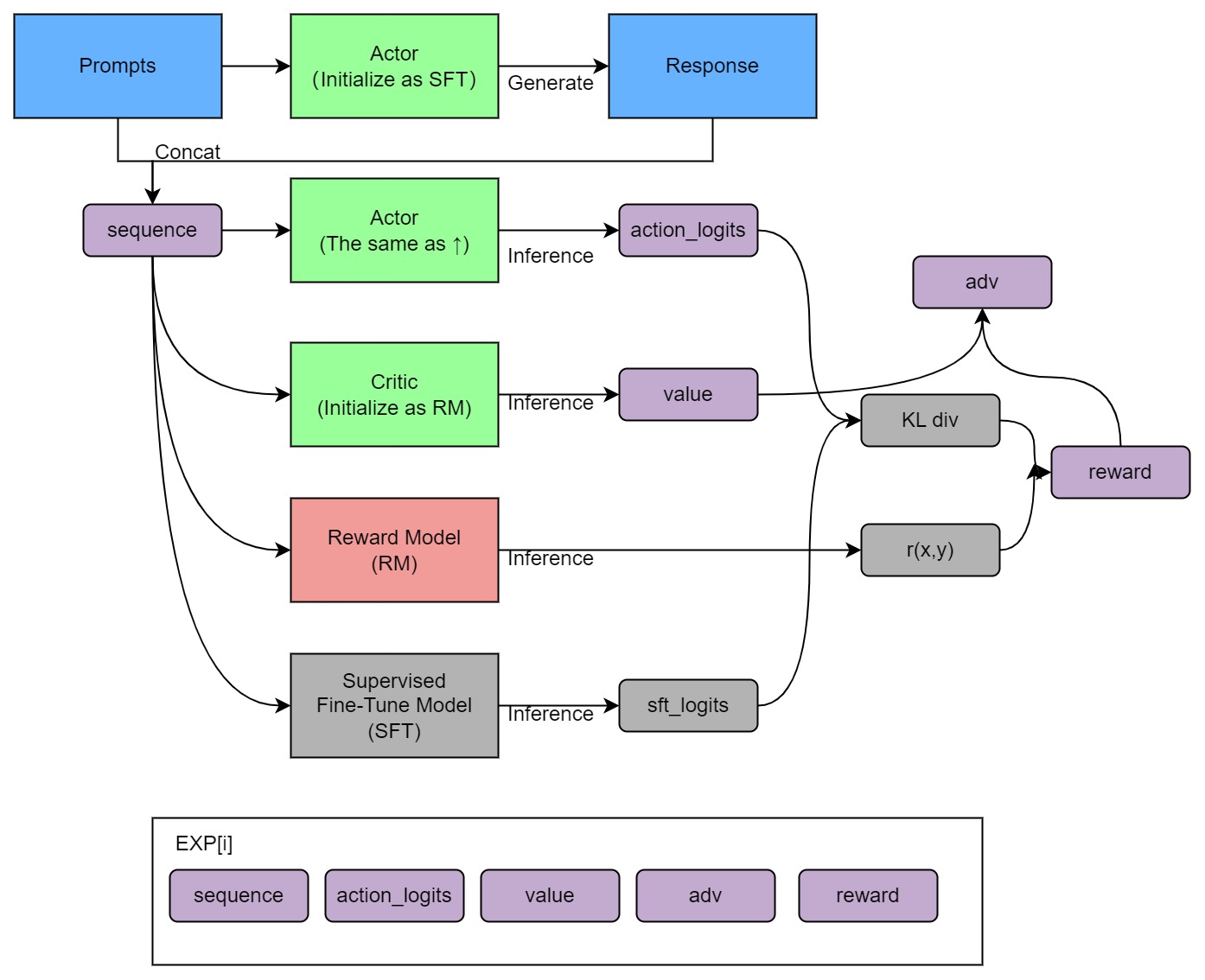
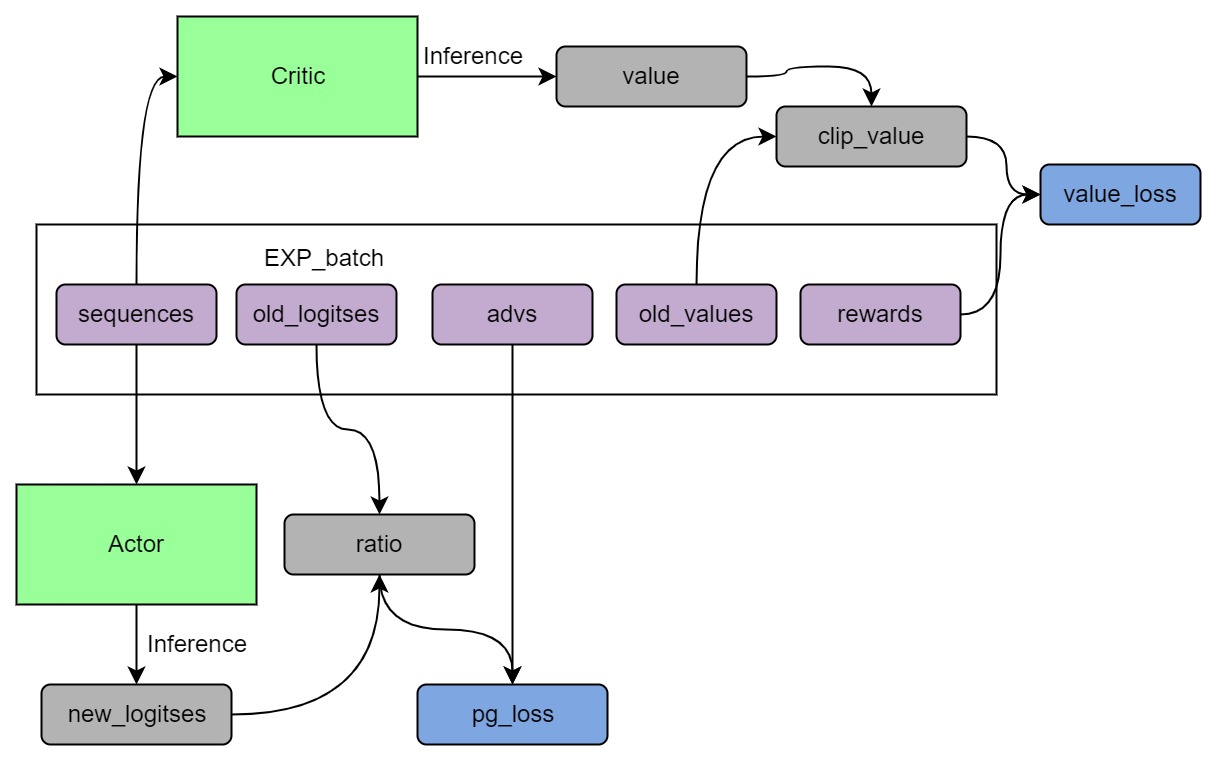
## Install
```shell
pip install .
```
## Usage
The main entrypoint is `Trainer`. We only support PPO trainer now. We support many training strategies:
- NaiveStrategy: simplest strategy. Train on single GPU.
- DDPStrategy: use `torch.nn.parallel.DistributedDataParallel`. Train on multi GPUs.
- ColossalAIStrategy: use Gemini and Zero of ColossalAI. It eliminates model duplication on each GPU and supports offload. It's very useful when training large models on multi GPUs.
Simplest usage:
```python
from chatgpt.trainer import PPOTrainer
from chatgpt.trainer.strategies import ColossalAIStrategy
strategy = ColossalAIStrategy()
with strategy.model_init_context():
# init your model here
actor = Actor()
critic = Critic()
trainer = PPOTrainer(actor = actor, critic= critic, strategy, ...)
trainer.fit(dataset, ...)
```
For more details, see `examples/`.
We also support training reward model with true-world data. See `examples/train_reward_model.py`.
## Todo
- [x] implement PPO training
- [x] implement training reward model
- [x] support LoRA
- [ ] implement PPO-ptx fine-tuning
- [ ] integrate with Ray
- [ ] support more RL paradigms, like Implicit Language Q-Learning (ILQL)
## Invitation to open-source contribution
Referring to the successful attempts of [BLOOM](https://bigscience.huggingface.co/) and [Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion), any and all developers and partners with computing powers, datasets, models are welcome to join and build an ecosystem with Colossal-AI, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
You may contact us or participate in the following ways:
1. Posting an [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose) or submitting a [PR](https://github.com/hpcaitech/ColossalAI/pulls) on GitHub
2. Join the Colossal-AI community on
[Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
and [WeChat](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your ideas.
3. Check out and fill in the [cooperation proposal](https://www.hpc-ai.tech/partners)
4. Send your proposal to email contact@hpcaitech.com
Thanks so much to all of our amazing contributors!
## Quick Preview

- Up to 7.73 times faster for single server training and 1.42 times faster for single-GPU inference
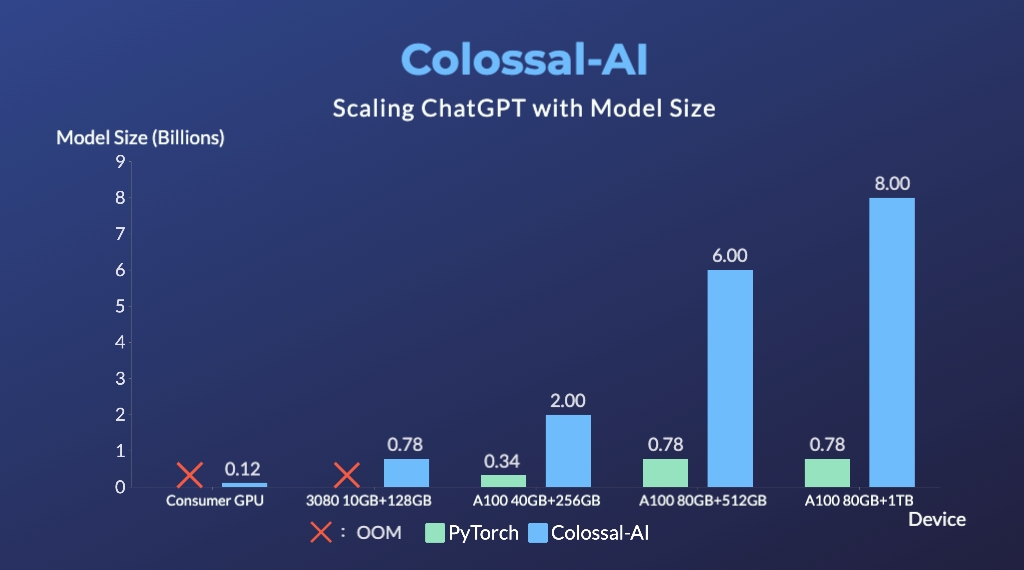
- Up to 10.3x growth in model capacity on one GPU
- A mini demo training process requires only 1.62GB of GPU memory (any consumer-grade GPU)
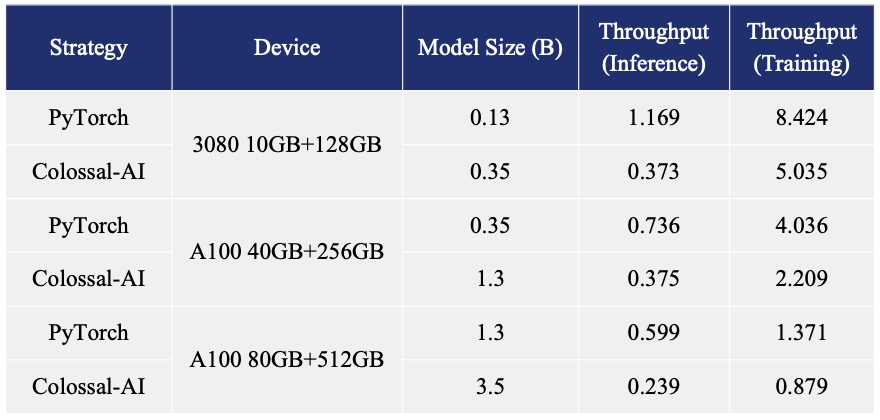
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
- Keep in a sufficiently high running speed
## Citations
```bibtex
@article{Hu2021LoRALA,
title = {LoRA: Low-Rank Adaptation of Large Language Models},
author = {Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen},
journal = {ArXiv},
year = {2021},
volume = {abs/2106.09685}
}
@article{ouyang2022training,
title={Training language models to follow instructions with human feedback},
author={Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others},
journal={arXiv preprint arXiv:2203.02155},
year={2022}
}
```