[](https://www.colossalai.org/)
An integrated large-scale model training system with efficient parallelization techniques.
[](https://github.com/hpcaitech/ColossalAI/actions/workflows/build.yml)
[](https://colossalai.readthedocs.io/en/latest/?badge=latest)
[](https://www.codefactor.io/repository/github/hpcaitech/colossalai)
[](https://huggingface.co/hpcai-tech)
[](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w)
[](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png)
| [English](README.md) | [中文](README-zh-Hans.md) |
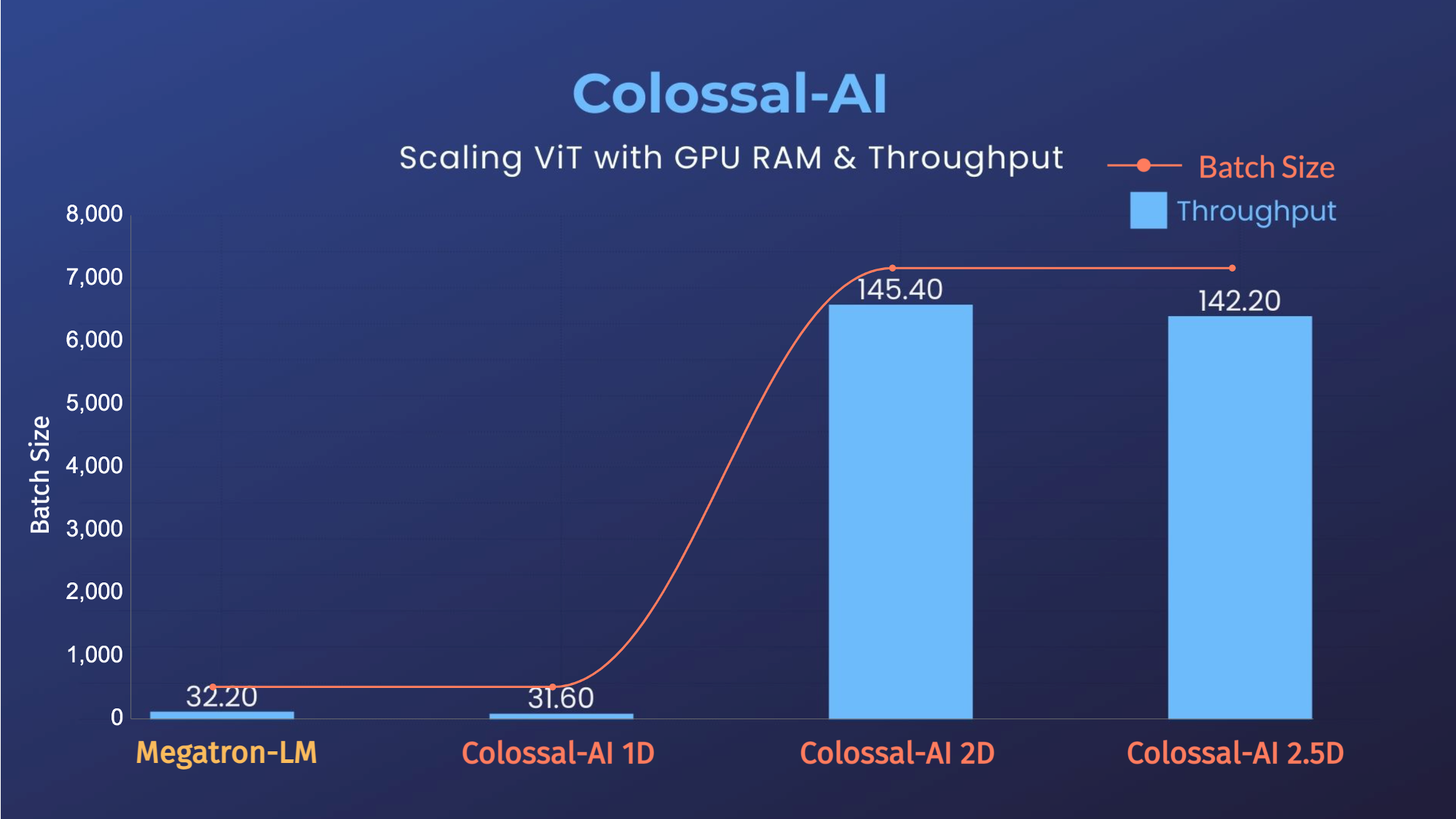 - 14x larger batch size, and 5x faster training for Tensor Parallelism = 64
### GPT-3
- 14x larger batch size, and 5x faster training for Tensor Parallelism = 64
### GPT-3
 - Save 50% GPU resources, and 10.7% acceleration
### GPT-2
- Save 50% GPU resources, and 10.7% acceleration
### GPT-2
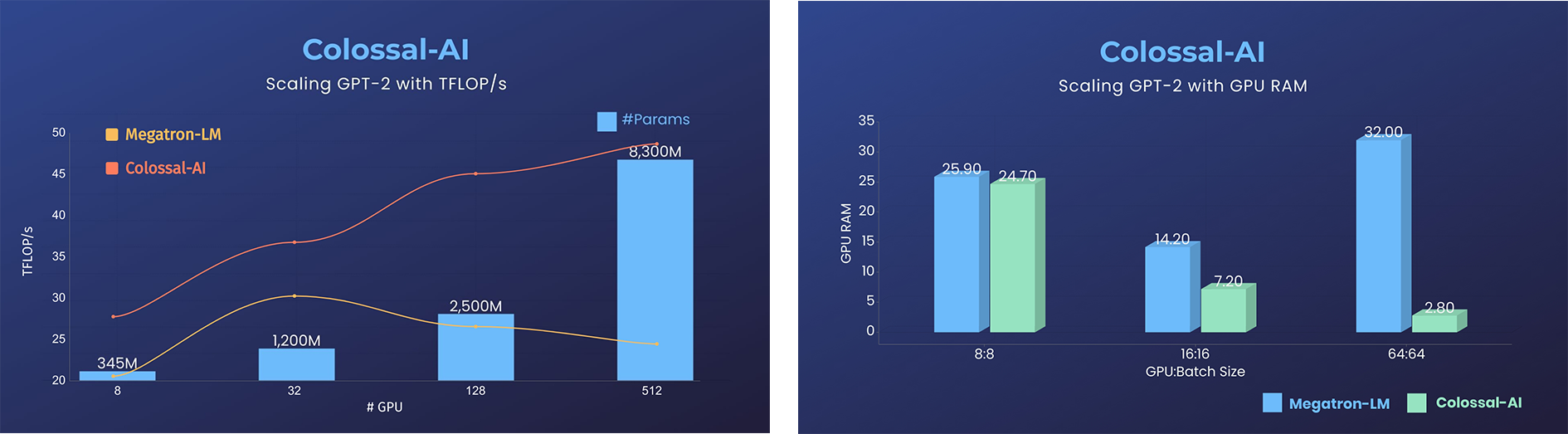 - 11x lower GPU memory consumption, and superlinear scaling efficiency with Tensor Parallelism
- 11x lower GPU memory consumption, and superlinear scaling efficiency with Tensor Parallelism
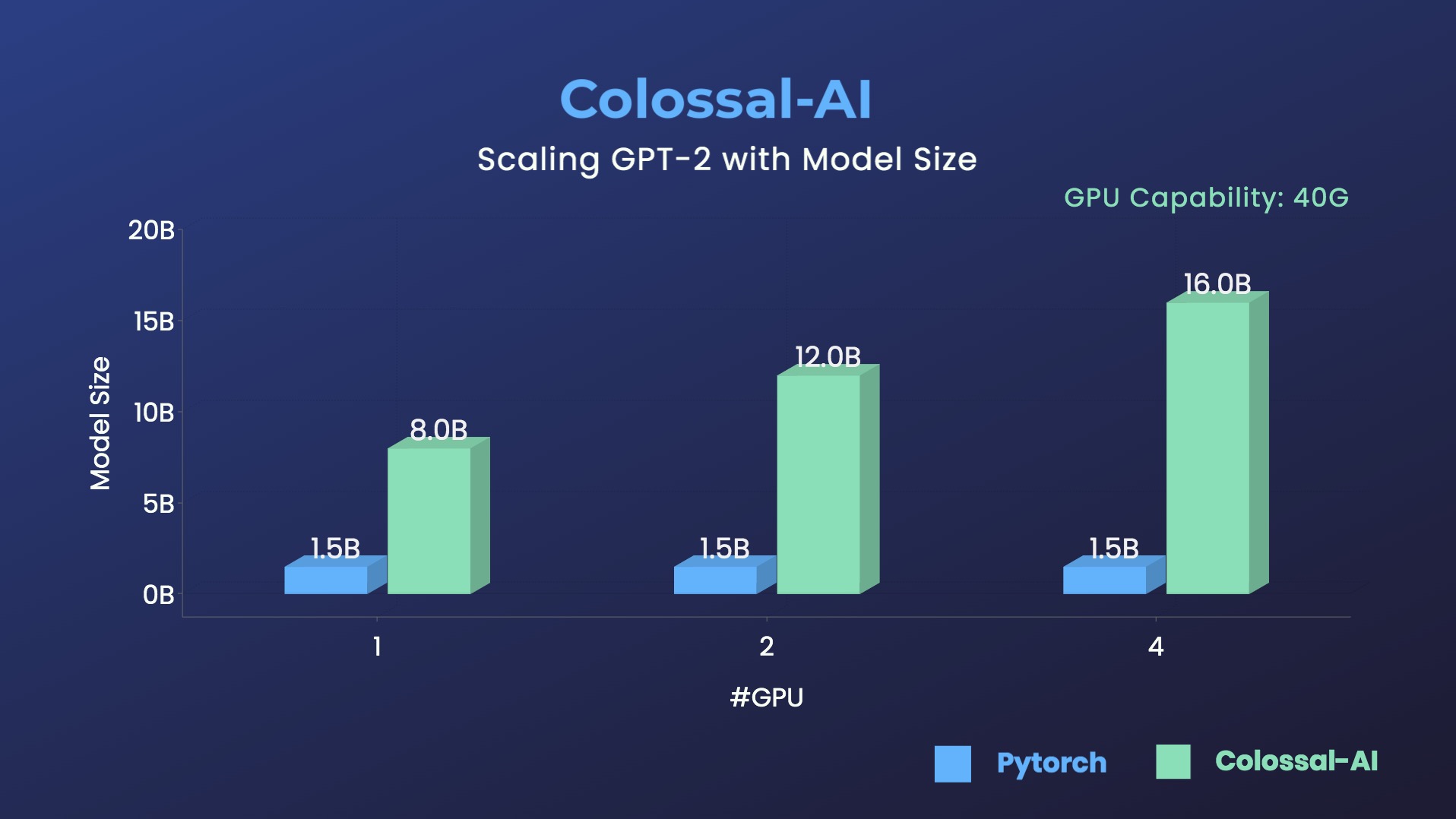 - 10.7x larger model size on the same hardware
### BERT
- 10.7x larger model size on the same hardware
### BERT
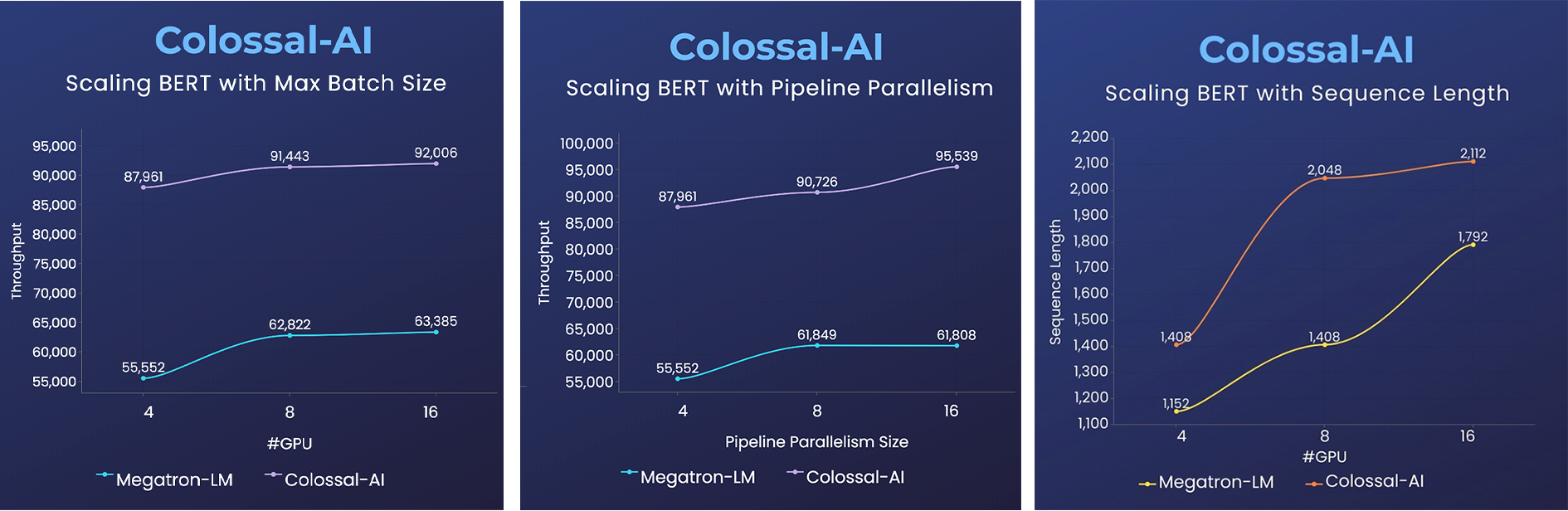 - 2x faster training, or 50% longer sequence length
Please visit our [documentation and tutorials](https://www.colossalai.org/) for more details.
## Installation
### PyPI
```bash
pip install colossalai
```
This command will install CUDA extension if your have installed CUDA, NVCC and torch.
If you don't want to install CUDA extension, you should add `--global-option="--no_cuda_ext"`, like:
```bash
pip install colossalai --global-option="--no_cuda_ext"
```
If you want to use `ZeRO`, you can run:
```bash
pip install colossalai[zero]
```
### Install From Source
> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to create an issue if you encounter any problems. :-)
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# install dependency
pip install -r requirements/requirements.txt
# install colossalai
pip install .
```
If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
```shell
pip install --global-option="--no_cuda_ext" .
```
## Use Docker
Run the following command to build a docker image from Dockerfile provided.
```bash
cd ColossalAI
docker build -t colossalai ./docker
```
Run the following command to start the docker container in interactive mode.
```bash
docker run -ti --gpus all --rm --ipc=host colossalai bash
```
## Community
Join the Colossal-AI community on [Forum](https://github.com/hpcaitech/ColossalAI/discussions),
[Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
and [WeChat](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your suggestions, feedback, and questions with our engineering team.
## Contributing
If you wish to contribute to this project, please follow the guideline in [Contributing](./CONTRIBUTING.md).
Thanks so much to all of our amazing contributors!
- 2x faster training, or 50% longer sequence length
Please visit our [documentation and tutorials](https://www.colossalai.org/) for more details.
## Installation
### PyPI
```bash
pip install colossalai
```
This command will install CUDA extension if your have installed CUDA, NVCC and torch.
If you don't want to install CUDA extension, you should add `--global-option="--no_cuda_ext"`, like:
```bash
pip install colossalai --global-option="--no_cuda_ext"
```
If you want to use `ZeRO`, you can run:
```bash
pip install colossalai[zero]
```
### Install From Source
> The version of Colossal-AI will be in line with the main branch of the repository. Feel free to create an issue if you encounter any problems. :-)
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
# install dependency
pip install -r requirements/requirements.txt
# install colossalai
pip install .
```
If you don't want to install and enable CUDA kernel fusion (compulsory installation when using fused optimizer):
```shell
pip install --global-option="--no_cuda_ext" .
```
## Use Docker
Run the following command to build a docker image from Dockerfile provided.
```bash
cd ColossalAI
docker build -t colossalai ./docker
```
Run the following command to start the docker container in interactive mode.
```bash
docker run -ti --gpus all --rm --ipc=host colossalai bash
```
## Community
Join the Colossal-AI community on [Forum](https://github.com/hpcaitech/ColossalAI/discussions),
[Slack](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w),
and [WeChat](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your suggestions, feedback, and questions with our engineering team.
## Contributing
If you wish to contribute to this project, please follow the guideline in [Contributing](./CONTRIBUTING.md).
Thanks so much to all of our amazing contributors!