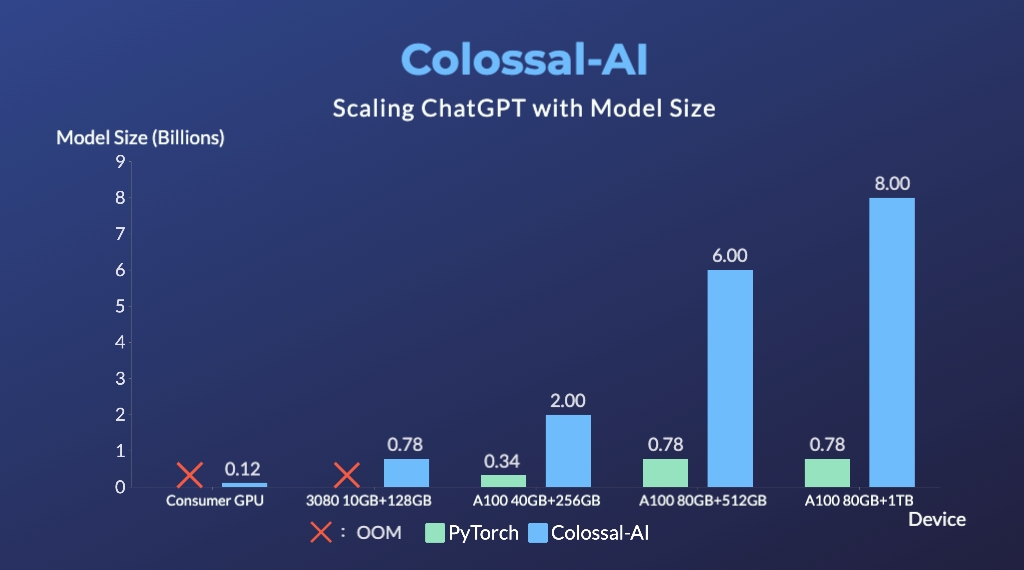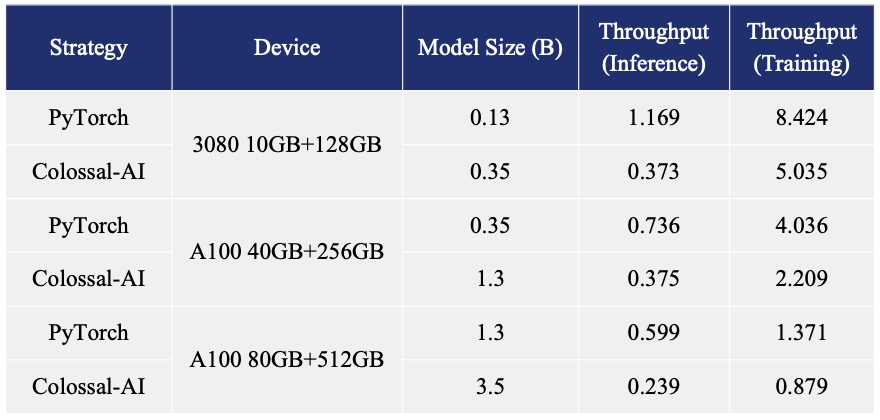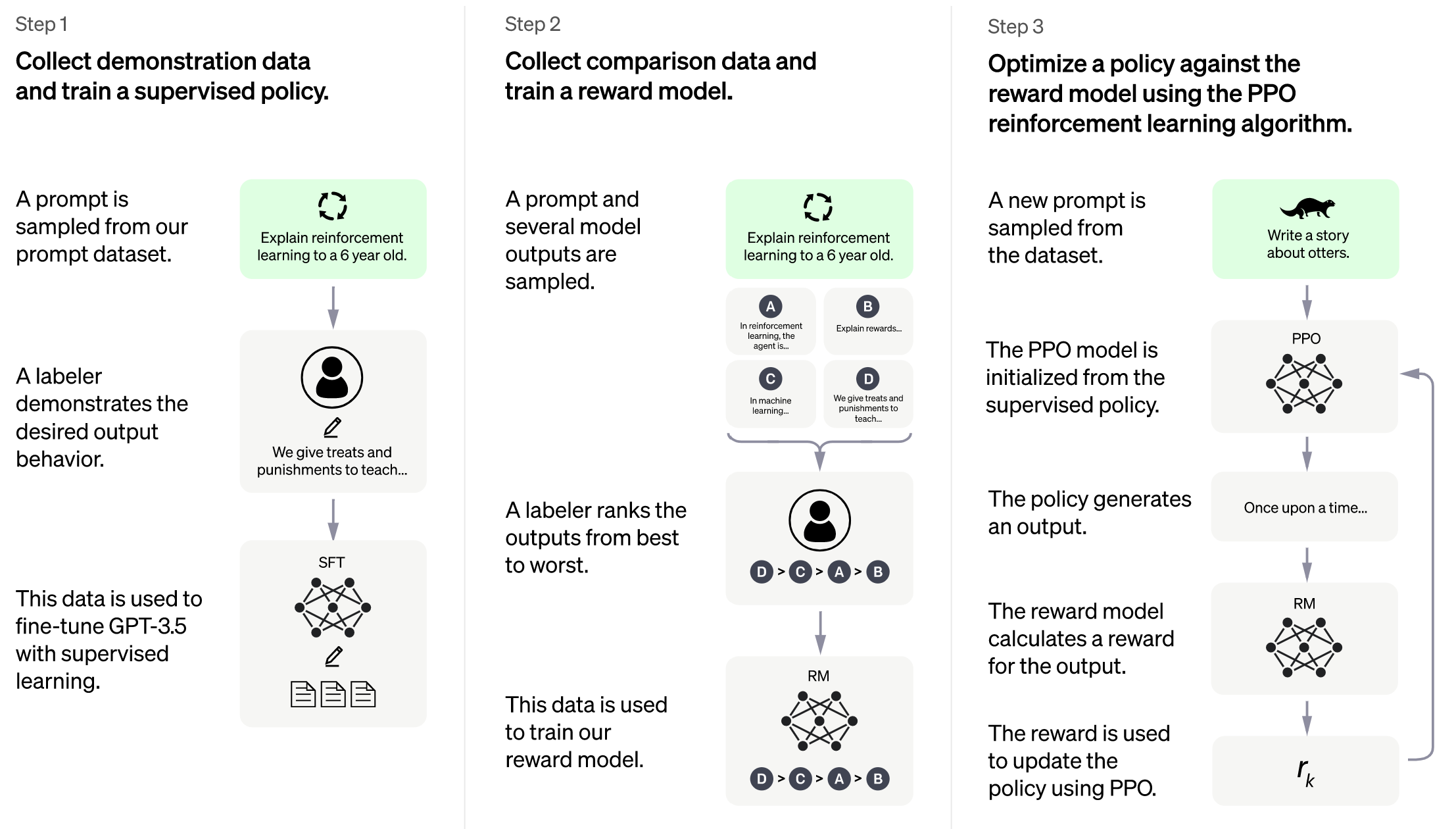
Image source: https://openai.com/blog/chatgpt
**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
More details can be found in the latest news.
- [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
- [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
## Online demo