# Distributed Training
Author: Shenggui Li, Siqi Mai
## What is a distributed system?
Image source: Towards Data Science
A distributed system consists of multiple software components which run on multiple machines. For example, the traditional
database runs on a single machine. As the amount of data gets incredibly large, a single machine can no longer deliver desirable
performance to the business, especially in situations such as Black Friday where network traffic can be unexpectedly high.
To handle such pressure, modern high-performance database is designed to run on multiple machines, and they work together to provide
high throughput and low latency to the user.
One important evaluation metric for distributed system is scalability. For example, when we run an application on 4 machines,
we naturally expect that the application can run 4 times faster. However, due to communication overhead and difference in
hardware performance, it is difficult to achieve linear speedup. Thus, it is important to consider how to make the application
faster when we implement it. Algorithms of good design and system optimization can help to deliver good performance. Sometimes,
it is even possible to achieve linear and super-linear speedup.
## Why we need distributed training for machine learning?
Back in 2012, [AlexNet](https://arxiv.org/abs/1404.5997) won the champion of the ImageNet competition, and it was trained
on two GTX 580 3GB GPUs.
Today, most models that appear in the top AI conferences are trained on multiple GPUs. Distributed training is definitely
a common practice when researchers and engineers develop AI models. There are several reasons behind this trend.
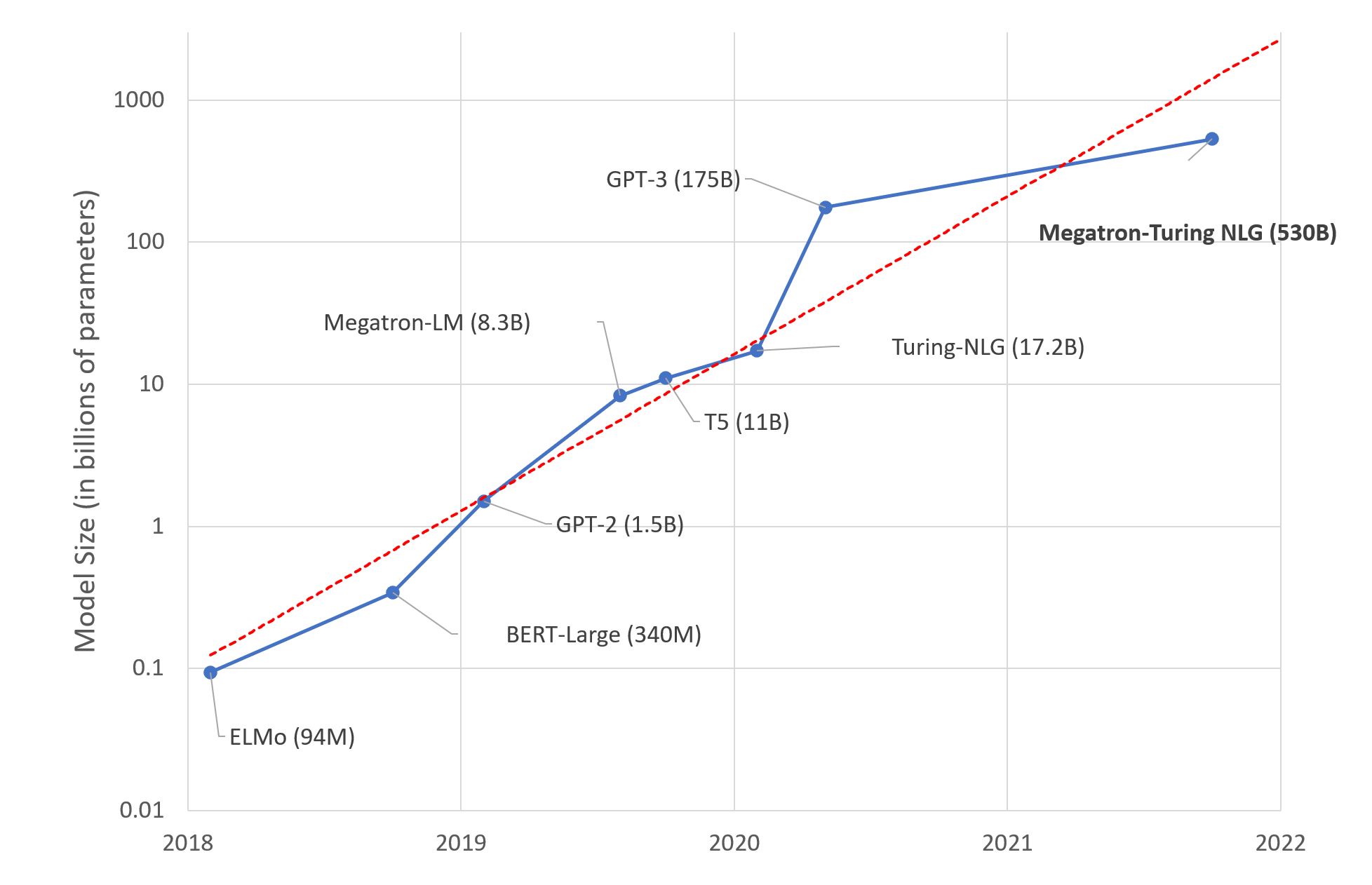
1. Model size increases rapidly. [ResNet50](https://arxiv.org/abs/1512.03385) has 20 million parameters in 2015,
[BERT-Large](https://arxiv.org/abs/1810.04805) has 345 million parameters in 2018,
[GPT-2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
has 1.5 billion parameters in 2018, and [GPT-3](https://arxiv.org/abs/2005.14165) has 175 billion parameters in 2020.
It is obvious that the model size grows exponentially with time. The current largest model has exceeded more than 1000
billion parameters. Super large models generally deliver more superior performance compared to their smaller counterparts.
Image source: HuggingFace
2. Dataset size increases rapidly. For most machine learning developers, MNIST and CIFAR10 datasets are often the first few
datasets on which they train their models. However, these datasets are very small compared to well-known ImageNet datasets.
Google even has its own (unpublished) JFT-300M dataset which has around 300 million images, and this is close to 300 times
larger than the ImageNet-1k dataset.
3. Computing power gets stronger. With the advancement in the semiconductor industry, graphics cards become more and more
powerful. Due to its larger number of cores, GPU is the most common compute platform for deep learning.
From K10 GPU in 2012 to A100 GPU in 2020, the computing power has increased several hundred times. This allows us to performance
compute-intensive tasks faster and deep learning is exactly such a task.
Nowadays, the model can be too large to fit into a single GPU, and the dataset can be large enough to train for a hundred
days on a single GPU. Only by training our models on multiple GPUs with different parallelization techniques, we are able
to speed up the training process and obtain results in a reasonable amount of time.
## Basic Concepts in Distributed Training
Distributed training requires multiple machines/GPUs. During training, there will be communication among these devices.
To understand distributed training better, there are several important terms to be made clear.
- host: host is the main device in the communication network. It is often required as an argument when initializing the
distributed environment.
- port: port here mainly refers to master port on the host for communication.
- rank: the unique ID given to a device in the network.
- world size: the number of devices in the network.
- process group: a process group is a communication network which include a subset of the devices. There is always a default
process group which contains all the devices. A subset devices can form a process group so that they only communicate among
the devices within the group.
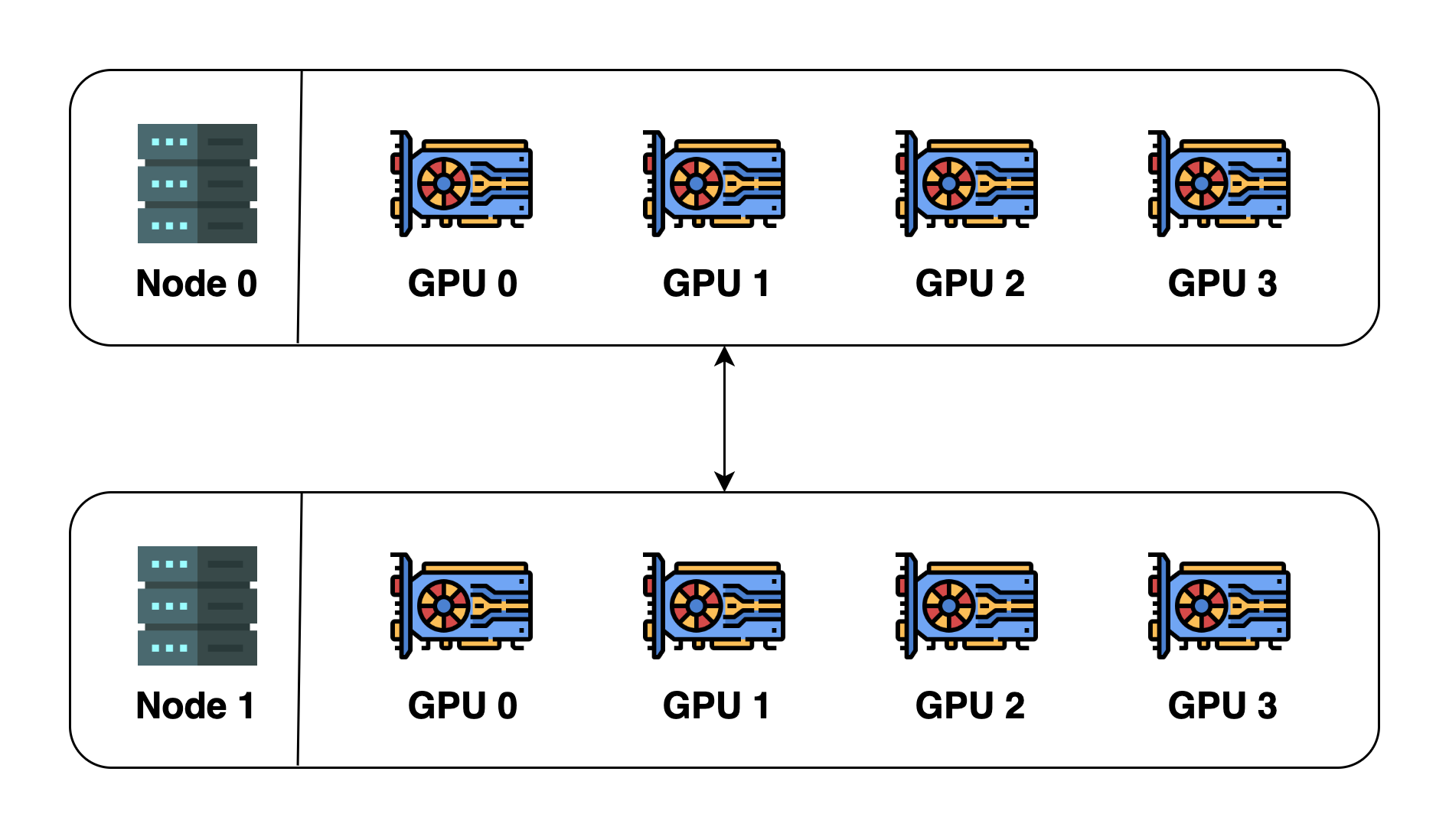
A distributed system example
To illustrate these concepts, let's assume we have 2 machines (also called nodes), and each machine has 4 GPUs. When we
initialize distributed environment over these two machines, we essentially launch 8 processes (4 processes on each machine)
and each process is bound to a GPU.
Before initializing the distributed environment, we need to specify the host (master address) and port (master port). In
this example, we can let host be node 0 and port be a number such as 29500. All the 8 processes will then look for the
address and port and connect to one another.
The default process group will then be created. The default process group has a world size of 8 and details are as follows:
| process ID | rank | Node index | GPU index |
| ---------- | ---- | ---------- | --------- |
| 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 |
| 2 | 2 | 0 | 2 |
| 3 | 3 | 0 | 3 |
| 4 | 4 | 1 | 0 |
| 5 | 5 | 1 | 1 |
| 6 | 6 | 1 | 2 |
| 7 | 7 | 1 | 3 |
We can also create a new process group. This new process group can contain any subset of the processes.
For example, we can create one containing only even-number processes, and the details of this new group will be:
| process ID | rank | Node index | GPU index |
| ---------- | ---- | ---------- | --------- |
| 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 2 |
| 4 | 2 | 1 | 0 |
| 6 | 3 | 1 | 2 |
**Please note that rank is relative to the process group and one process can have a different rank in different process
groups. The max rank is always `world size of the process group - 1`.**
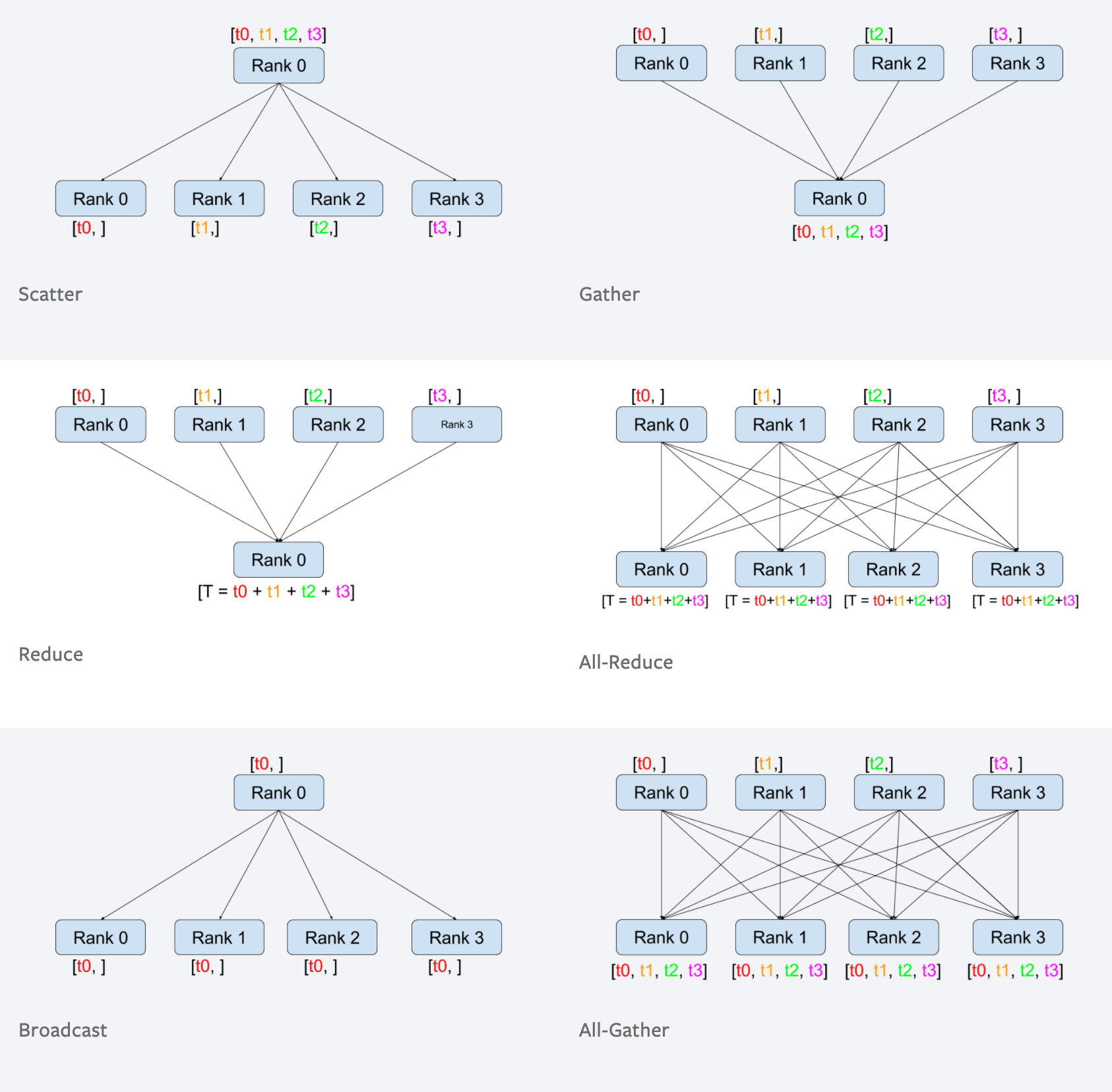
In the process group, the processes can communicate in two ways:
1. peer-to-peer: one process send data to another process
2. collective: a group of process perform operations such as scatter, gather, all-reduce, broadcast together.
Collective communication, source: PyTorch distributed tutorial