mirror of https://github.com/hpcaitech/ColossalAI
[examples] polish AutoParallel readme (#3270)
parent
02b058032d
commit
fd6add575d
|
|
@ -45,6 +45,7 @@ colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
|
|||
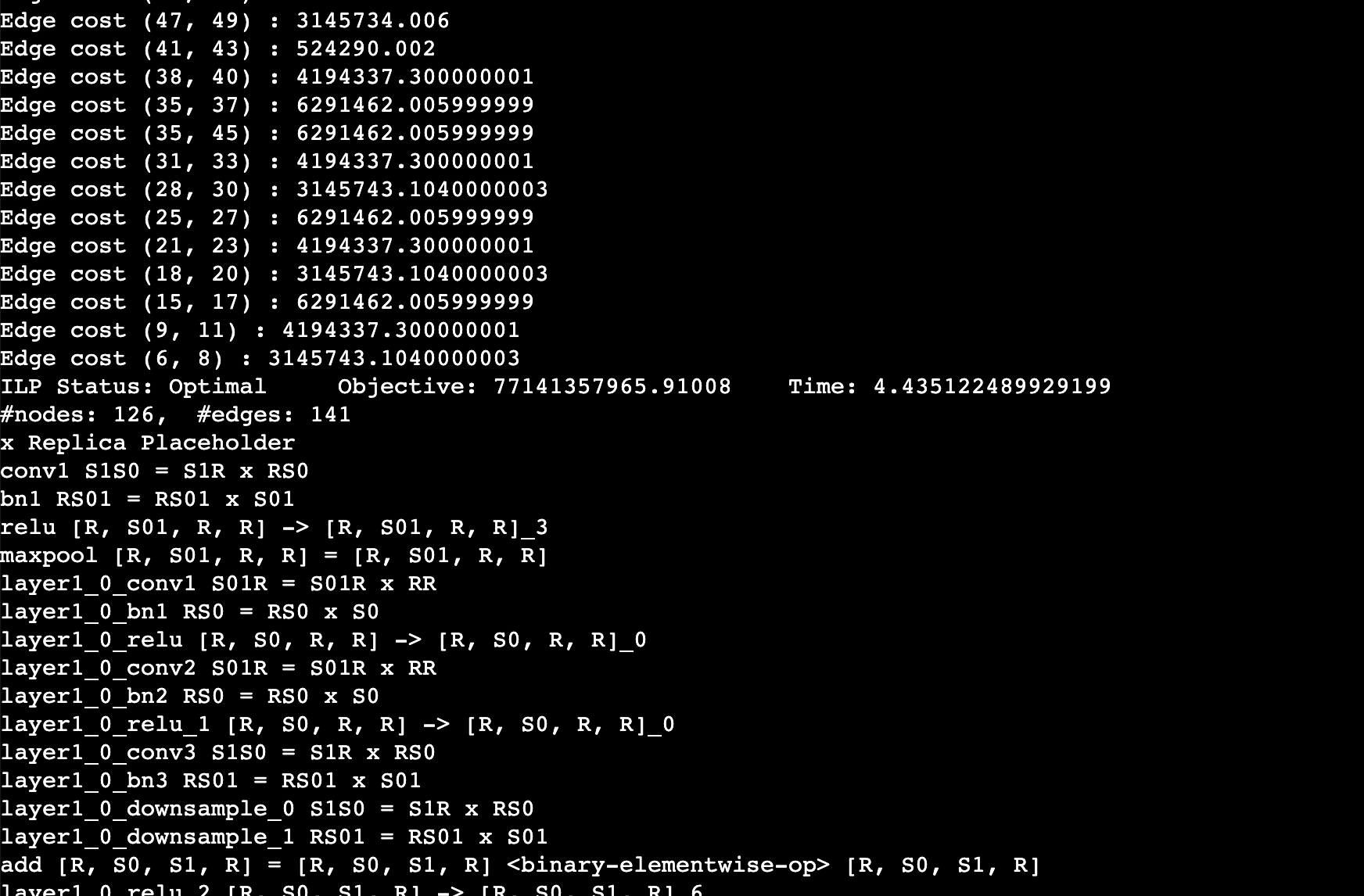
You should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, `layer1_0_conv1 S01R = S01R X RR` means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
|
||||
|
||||
|
||||
**Note: This experimental feature has been tested on torch 1.12.1 and transformer 4.22.2. If you are using other versions, you may need to modify the code to make it work.**
|
||||
|
||||
### Auto-Checkpoint Tutorial
|
||||
|
||||
|
|
|
|||
|
|
@ -1,7 +1,7 @@
|
|||
torch
|
||||
torch==1.12.1
|
||||
colossalai
|
||||
titans
|
||||
pulp
|
||||
datasets
|
||||
matplotlib
|
||||
transformers
|
||||
transformers==4.22.1
|
||||
|
|
|
|||
Loading…
Reference in New Issue