mirror of https://github.com/hpcaitech/ColossalAI
[application] Update README (#6196)
* remove unused ray * remove unused readme * update readme * update readme * update * update * add link * update readme * update readme * fix link * update code * update cititaion * update * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * update readme * update project * add images * update link * update note --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>pull/6199/head
parent
d54642a263
commit
f8b9e88484
|
|
@ -7,32 +7,23 @@
|
|||
## Table of Contents
|
||||
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [What is ColossalChat and Coati ?](#what-is-colossalchat-and-coati-)
|
||||
- [What is ColossalChat?](#what-is-colossalchat)
|
||||
- [Online demo](#online-demo)
|
||||
- [Install](#install)
|
||||
- [Install the environment](#install-the-environment)
|
||||
- [Install the Transformers](#install-the-transformers)
|
||||
- [How to use?](#how-to-use)
|
||||
- [Introduction](#introduction)
|
||||
- [Supervised datasets collection](#step-1-data-collection)
|
||||
- [RLHF Training Stage1 - Supervised instructs tuning](#rlhf-training-stage1---supervised-instructs-tuning)
|
||||
- [RLHF Training Stage2 - Training reward model](#rlhf-training-stage2---training-reward-model)
|
||||
- [RLHF Training Stage3 - Training model with reinforcement learning by human feedback](#rlhf-training-stage3---proximal-policy-optimization)
|
||||
- [Alternative Option for RLHF: GRPO](#alternative-option-for-rlhf-group-relative-policy-optimization-grpo)
|
||||
- [Alternative Option For RLHF: DPO](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||
- [Alternative Option For RLHF: SimPO](#alternative-option-for-rlhf-simple-preference-optimization-simpo)
|
||||
- [Alternative Option For RLHF: ORPO](#alternative-option-for-rlhf-odds-ratio-preference-optimization-orpo)
|
||||
- [Alternative Option For RLHF: KTO](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||
- [SFT for DeepSeek V3/R1](#sft-for-deepseek-v3)
|
||||
- [Inference Quantization and Serving - After Training](#inference-quantization-and-serving---after-training)
|
||||
- [Coati7B examples](#coati7b-examples)
|
||||
- [Generation](#generation)
|
||||
- [Open QA](#open-qa)
|
||||
- [Limitation for LLaMA-finetuned models](#limitation)
|
||||
- [Limitation of dataset](#limitation)
|
||||
- [Alternative Option For RLHF: DPO](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||
- [Alternative Option For RLHF: SimPO](#alternative-option-for-rlhf-simple-preference-optimization-simpo)
|
||||
- [Alternative Option For RLHF: ORPO](#alternative-option-for-rlhf-odds-ratio-preference-optimization-orpo)
|
||||
- [Alternative Option For RLHF: KTO](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||
- [O1 Journey](#o1-journey)
|
||||
- [Inference with Self-refined MCTS](#inference-with-self-refined-mcts)
|
||||
- [SFT for DeepSeek V3/R1](#sft-for-deepseek-v3)
|
||||
- [FAQ](#faq)
|
||||
- [How to save/load checkpoint](#faq)
|
||||
- [How to train with limited resources](#faq)
|
||||
- [Invitation to open-source contribution](#invitation-to-open-source-contribution)
|
||||
- [Quick Preview](#quick-preview)
|
||||
- [Authors](#authors)
|
||||
|
|
@ -41,9 +32,9 @@
|
|||
|
||||
---
|
||||
|
||||
## What Is ColossalChat And Coati ?
|
||||
## What is ColossalChat?
|
||||
|
||||
[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) is the project to implement LLM with RLHF, powered by the [Colossal-AI](https://github.com/hpcaitech/ColossalAI) project.
|
||||
[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/ColossalChat) is a project to implement LLM with RLHF, powered by the [Colossal-AI](https://github.com/hpcaitech/ColossalAI).
|
||||
|
||||
Coati stands for `ColossalAI Talking Intelligence`. It is the name for the module implemented in this project and is also the name of the large language model developed by the ColossalChat project.
|
||||
|
||||
|
|
@ -54,8 +45,6 @@ The Coati package provides a unified large language model framework that has imp
|
|||
- Supervised instructions fine-tuning
|
||||
- Training reward model
|
||||
- Reinforcement learning with human feedback
|
||||
- Quantization inference
|
||||
- Fast model deploying
|
||||
- Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
|
||||
|
||||
<div align="center">
|
||||
|
|
@ -115,77 +104,16 @@ cd $COLOSSAL_AI_ROOT/applications/ColossalChat
|
|||
pip install .
|
||||
```
|
||||
|
||||
## How To Use?
|
||||
## Introduction
|
||||
|
||||
### RLHF Training Stage1 - Supervised Instructs Tuning
|
||||
|
||||
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. Here's a detailed guide on how to SFT your LLM with ColossalChat. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
#### Step 1: Data Collection
|
||||
The first step in Stage 1 is to collect a dataset of human demonstrations of the following format.
|
||||
|
||||
```json
|
||||
[
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "user",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
},
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you looking for practical joke ideas?"
|
||||
},
|
||||
]
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Once you have collected your SFT dataset, you will need to preprocess it. This involves four steps: data cleaning, data deduplication, formatting and tokenization. In this section, we will focus on formatting and tokenization.
|
||||
|
||||
In this code, we provide a flexible way for users to set the conversation template for formatting chat data using Huggingface's newest feature--- chat template. Please follow the [example guideline](./examples/README.md) on how to format and tokenize data.
|
||||
|
||||
#### Step 3: Training
|
||||
Choose a suitable model architecture for your task. Note that your model should be compatible with the tokenizer that you used to tokenize the SFT dataset. You can run [train_sft.sh](./examples/training_scripts/train_sft.sh) to start a supervised instructs fine-tuning. More details can be found in [example guideline](./examples/README.md).
|
||||
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
### RLHF Training Stage2 - Training Reward Model
|
||||
|
||||
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
|
||||
|
||||
#### Step 1: Data Collection
|
||||
Below shows the preference dataset format used in training the reward model.
|
||||
|
||||
```json
|
||||
[
|
||||
{"context": [
|
||||
{
|
||||
"from": "human",
|
||||
"content": "Introduce butterflies species in Oregon."
|
||||
}
|
||||
],
|
||||
"chosen": [
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "About 150 species of butterflies live in Oregon, with about 100 species are moths..."
|
||||
},
|
||||
],
|
||||
"rejected": [
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you interested in just the common butterflies? There are a few common ones which will be easy to find..."
|
||||
},
|
||||
]
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Similar to the second step in the previous stage, we format the reward data into the same structured format as used in step 2 of the SFT stage. You can run [prepare_preference_dataset.sh](./examples/data_preparation_scripts/prepare_preference_dataset.sh) to prepare the preference data for reward model training.
|
||||
|
||||
#### Step 3: Training
|
||||
You can run [train_rm.sh](./examples/training_scripts/train_rm.sh) to start the reward model training. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
### RLHF Training Stage3 - Proximal Policy Optimization
|
||||
|
||||
In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimization (PPO), which is the most complex part of the training process:
|
||||
|
|
@ -194,86 +122,26 @@ In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimi
|
|||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/stage-3.jpeg" width=800/>
|
||||
</p>
|
||||
|
||||
#### Step 1: Data Collection
|
||||
PPO uses two kind of training data--- the prompt data and the sft data (optional). The first dataset is mandatory, data samples within the prompt dataset ends with a line from "human" and thus the "assistant" needs to generate a response to answer to the "human". Note that you can still use conversation that ends with a line from the "assistant", in that case, the last line will be dropped. Here is an example of the prompt dataset format.
|
||||
|
||||
```json
|
||||
[
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "human",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
}
|
||||
]
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Data Preprocessing
|
||||
To prepare the prompt dataset for PPO training, simply run [prepare_prompt_dataset.sh](./examples/data_preparation_scripts/prepare_prompt_dataset.sh)
|
||||
|
||||
#### Step 3: Training
|
||||
You can run the [train_ppo.sh](./examples/training_scripts/train_ppo.sh) to start PPO training. Here are some unique arguments for PPO, please refer to the training configuration section for other training configuration. More detais can be found in [example guideline](./examples/README.md).
|
||||
|
||||
```bash
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--rm_pretrain $PRETRAINED_MODEL_PATH \ # reward model architectual
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--rm_checkpoint_path $REWARD_MODEL_PATH \ # reward model checkpoint path
|
||||
--prompt_dataset ${prompt_dataset[@]} \ # List of string, the prompt dataset
|
||||
--ptx_dataset ${ptx_dataset[@]} \ # List of string, the SFT data used in the SFT stage
|
||||
--ptx_batch_size 1 \ # batch size for calculate ptx loss
|
||||
--ptx_coef 0.0 \ # none-zero if ptx loss is enable
|
||||
--num_episodes 2000 \ # number of episodes to train
|
||||
--num_collect_steps 1 \
|
||||
--num_update_steps 1 \
|
||||
--experience_batch_size 8 \
|
||||
--train_batch_size 4 \
|
||||
--accumulation_steps 2
|
||||
```
|
||||
|
||||
Each episode has two phases, the collect phase and the update phase. During the collect phase, we will collect experiences (answers generated by actor), store those in ExperienceBuffer. Then data in ExperienceBuffer is used during the update phase to update parameter of actor and critic.
|
||||
|
||||
- Without tensor parallelism,
|
||||
```
|
||||
experience buffer size
|
||||
= num_process * num_collect_steps * experience_batch_size
|
||||
= train_batch_size * accumulation_steps * num_process
|
||||
```
|
||||
|
||||
- With tensor parallelism,
|
||||
```
|
||||
num_tp_group = num_process / tp
|
||||
experience buffer size
|
||||
= num_tp_group * num_collect_steps * experience_batch_size
|
||||
= train_batch_size * accumulation_steps * num_tp_group
|
||||
```
|
||||
|
||||
## Alternative Option For RLHF: Direct Preference Optimization (DPO)
|
||||
### Alternative Option For RLHF: Direct Preference Optimization (DPO)
|
||||
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in this [paper](https://arxiv.org/abs/2305.18290), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### DPO Training Stage1 - Supervised Instructs Tuning
|
||||
|
||||
Please refer the [sft section](#dpo-training-stage1---supervised-instructs-tuning) in the PPO part.
|
||||
|
||||
### DPO Training Stage2 - DPO Training
|
||||
#### Step 1: Data Collection & Preparation
|
||||
For DPO training, you only need the preference dataset. Please follow the instruction in the [preference dataset preparation section](#rlhf-training-stage2---training-reward-model) to prepare the preference data for DPO training.
|
||||
|
||||
#### Step 2: Training
|
||||
You can run the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) to start DPO training. More detais can be found in [example guideline](./examples/README.md).
|
||||
|
||||
## Alternative Option For RLHF: Simple Preference Optimization (SimPO)
|
||||
### Alternative Option For RLHF: Simple Preference Optimization (SimPO)
|
||||
Simple Preference Optimization (SimPO) from this [paper](https://arxiv.org/pdf/2405.14734) is similar to DPO but it abandons the use of the reference model, which makes the training more efficient. It also adds a reward shaping term called target reward margin to enhance training stability. It also use length normalization to better align with the inference process. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
## Alternative Option For RLHF: Odds Ratio Preference Optimization (ORPO)
|
||||
### Alternative Option For RLHF: Odds Ratio Preference Optimization (ORPO)
|
||||
Odds Ratio Preference Optimization (ORPO) from this [paper](https://arxiv.org/pdf/2403.07691) is a reference model free alignment method that use a mixture of SFT loss and a reinforcement leanring loss calculated based on odds-ratio-based implicit reward to makes the training more efficient and stable. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
## Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)
|
||||
### Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)
|
||||
We support the method introduced in the paper [KTO:Model Alignment as Prospect Theoretic Optimization](https://arxiv.org/pdf/2402.01306) (KTO). Which is a aligment method that directly maximize "human utility" of generation results. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
## Inference Quantization and Serving - After Training
|
||||
### Alternative Option For RLHF: Group Relative Policy Optimization (GRPO)
|
||||
We support the main algorithm used to train DeepSeek R1 model, a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### SFT for DeepSeek V3
|
||||
We support fine-tuning DeepSeek V3/R1 model with LoRA. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### Inference Quantization and Serving - After Training
|
||||
|
||||
We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
|
||||
|
||||
|
|
@ -282,213 +150,7 @@ We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inferen
|
|||
Online inference server scripts can help you deploy your own services.
|
||||
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
||||
|
||||
## O1 Journey
|
||||
### Inference with Self-refined MCTS
|
||||
We provide the implementation of MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models with Monte Carlo Tree Search.
|
||||
You can serve model using vLLM and update the config file in `Qwen32B_prompt_CFG` and then run the following script.
|
||||
```python
|
||||
from coati.reasoner.guided_search.mcts import MCTS
|
||||
from coati.reasoner.guided_search.prompt_store.qwen import Qwen32B_prompt_CFG
|
||||
|
||||
problem = "How Many R in 'Strawberry'"
|
||||
|
||||
search_tree = MCTS(problem=problem, max_simulations=8, cfg=Qwen32B_prompt_CFG)
|
||||
answer = search_tree.simulate()
|
||||
print(answer)
|
||||
```
|
||||
|
||||
## Coati7B examples
|
||||
|
||||
### Generation
|
||||
|
||||
<details><summary><b>E-mail</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>coding</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>regex</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Tex</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>writing</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Table</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
### Open QA
|
||||
|
||||
<details><summary><b>Game</b></summary>
|
||||
|
||||
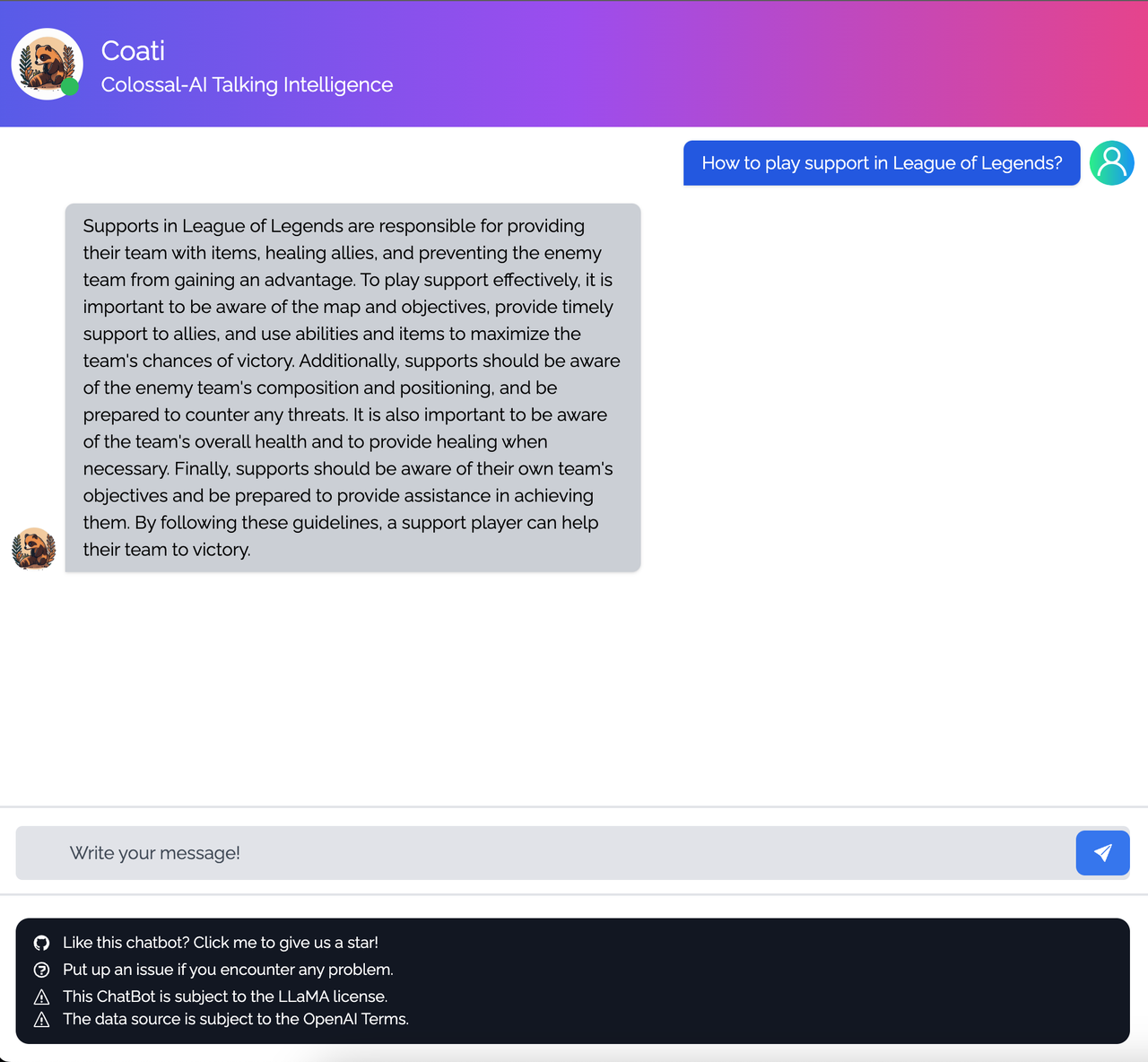
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Travel</b></summary>
|
||||
|
||||
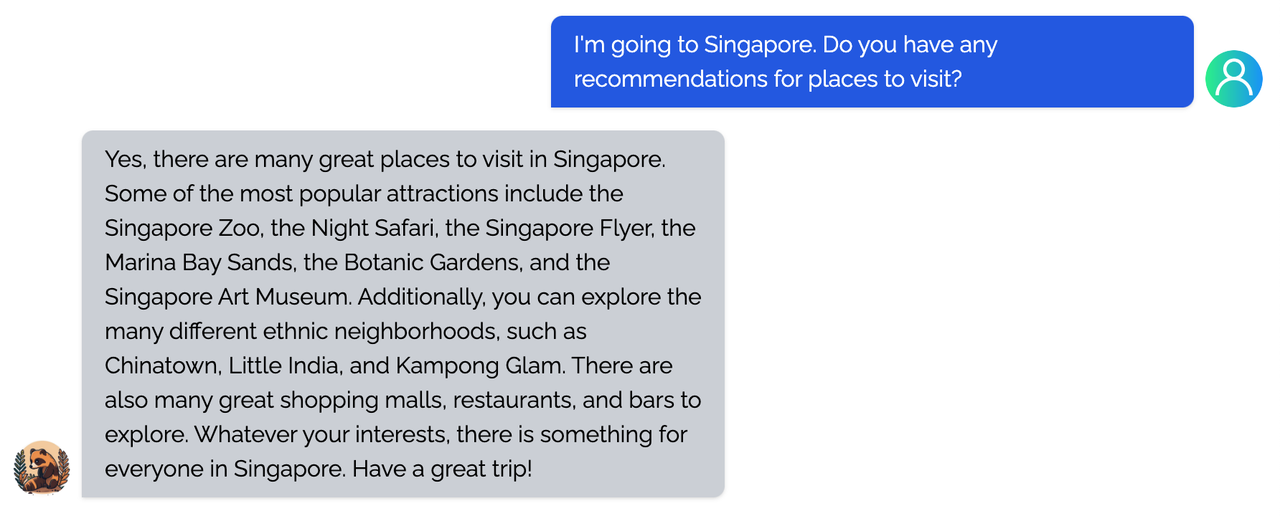
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Physical</b></summary>
|
||||
|
||||
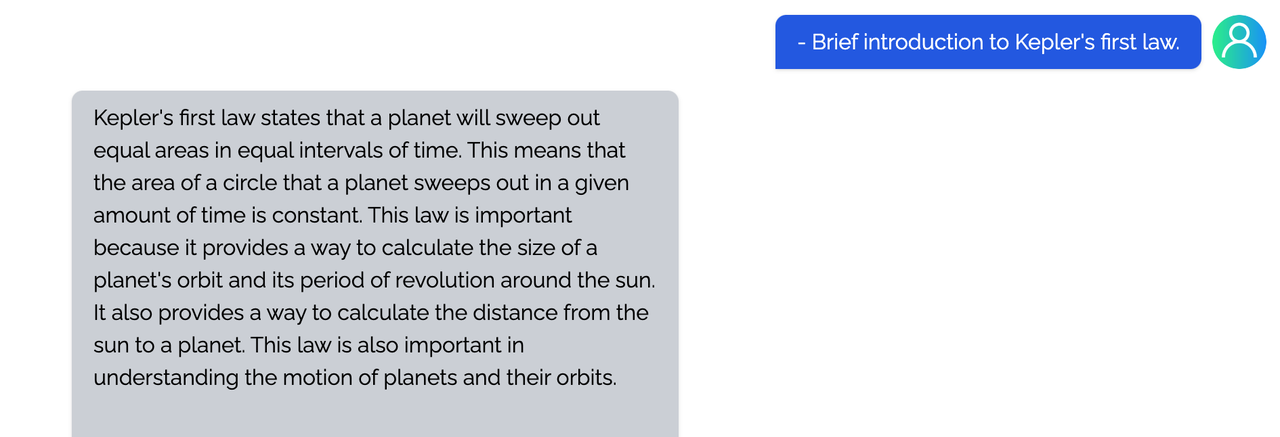
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Chemical</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Economy</b></summary>
|
||||
|
||||
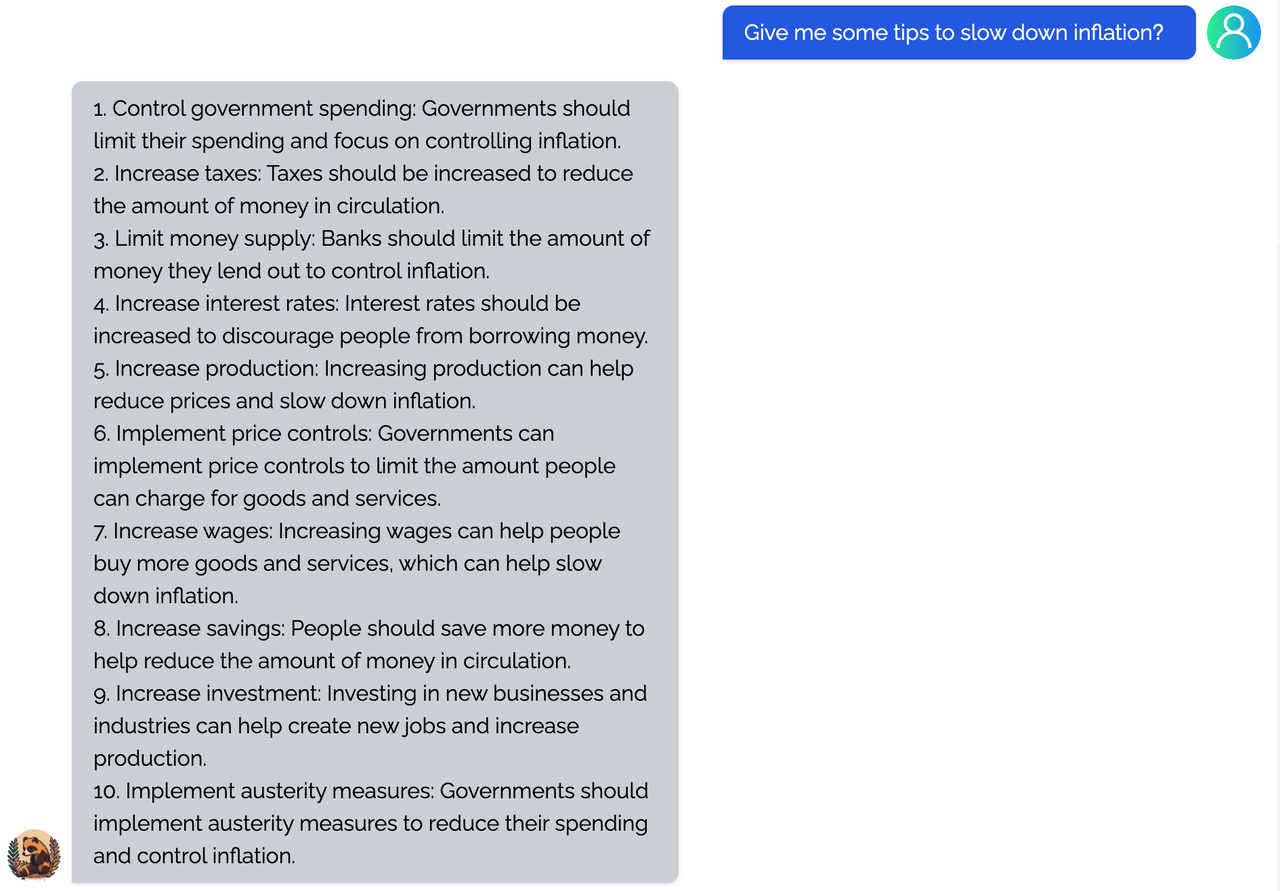
|
||||
|
||||
</details>
|
||||
|
||||
You can find more examples in this [repo](https://github.com/XueFuzhao/InstructionWild/blob/main/comparison.md).
|
||||
|
||||
### Limitation
|
||||
|
||||
<details><summary><b>Limitation for LLaMA-finetuned models</b></summary>
|
||||
- Both Alpaca and ColossalChat are based on LLaMA. It is hard to compensate for the missing knowledge in the pre-training stage.
|
||||
- Lack of counting ability: Cannot count the number of items in a list.
|
||||
- Lack of Logics (reasoning and calculation)
|
||||
- Tend to repeat the last sentence (fail to produce the end token).
|
||||
- Poor multilingual results: LLaMA is mainly trained on English datasets (Generation performs better than QA).
|
||||
</details>
|
||||
|
||||
<details><summary><b>Limitation of dataset</b></summary>
|
||||
- Lack of summarization ability: No such instructions in finetune datasets.
|
||||
- Lack of multi-turn chat: No such instructions in finetune datasets
|
||||
- Lack of self-recognition: No such instructions in finetune datasets
|
||||
- Lack of Safety:
|
||||
- When the input contains fake facts, the model makes up false facts and explanations.
|
||||
- Cannot abide by OpenAI's policy: When generating prompts from OpenAI API, it always abides by its policy. So no violation case is in the datasets.
|
||||
</details>
|
||||
|
||||
## SFT for DeepSeek V3
|
||||
|
||||
We add a script to supervised-fintune the DeepSeek V3/R1 model with LoRA. The script is located in `examples/training_scripts/lora_fintune.py`. The script is similar to the SFT script for Coati7B, but with a few differences. This script is compatible with Peft.
|
||||
|
||||
### Dataset preparation
|
||||
|
||||
This script receives JSONL format file as input dataset. Each line of dataset should be a list of chat dialogues. E.g.
|
||||
```json
|
||||
[{"role": "user", "content": "Hello, how are you?"}, {"role": "assistant", "content": "I'm doing great. How can I help you today?"}]
|
||||
```
|
||||
```json
|
||||
[{"role": "user", "content": "火烧赤壁 曹操为何不拨打119求救?"}, {"role": "assistant", "content": "因为在三国时期,还没有电话和现代的消防系统,所以曹操无法拨打119求救。"}]
|
||||
```
|
||||
|
||||
The dialogues can by multiple turns and it can contain system prompt. For more details, see the [chat_templating](https://huggingface.co/docs/transformers/main/chat_templating).
|
||||
|
||||
### Model weights preparation
|
||||
|
||||
We use bf16 weights for finetuning. If you downloaded fp8 DeepSeek V3/R1 weights, you can use the [script](https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/fp8_cast_bf16.py) to convert the weights to bf16 via GPU. For Ascend NPU, you can use this [script](https://gitee.com/ascend/ModelZoo-PyTorch/blob/master/MindIE/LLM/DeepSeek/DeepSeek-V2/NPU_inference/fp8_cast_bf16.py).
|
||||
|
||||
### Usage
|
||||
|
||||
After preparing the dataset and model weights, you can run the script with the following command:
|
||||
```bash
|
||||
colossalai run --hostfile path-to-host-file --nproc_per_node 8 lora_finetune.py --pretrained path-to-DeepSeek-R1-bf16 --dataset path-to-dataset.jsonl --plugin moe --lr 2e-5 --max_length 256 -g --ep 8 --pp 3 --batch_size 24 --lora_rank 8 --lora_alpha 16 --num_epochs 2 --warmup_steps 8 --tensorboard_dir logs --save_dir DeepSeek-R1-bf16-lora
|
||||
```
|
||||
|
||||
For more details of each argument, you can run `python lora_finetune.py --help`.
|
||||
|
||||
The sample command does not use CPU offload to get better throughput. The minimum hardware requirement for sample command is 32 ascend 910B NPUs (with `ep=8,pp=4`) or 24 H100/H800 GPUs (with `ep=8,pp=3`). If you enable CPU offload by `--zero_cpu_offload`, the hardware requirement can be further reduced.
|
||||
|
||||
## FAQ
|
||||
|
||||
<details><summary><b>How to save/load checkpoint</b></summary>
|
||||
|
||||
We have integrated the Transformers save and load pipeline, allowing users to freely call Hugging Face's language models and save them in the HF format.
|
||||
|
||||
- Option 1: Save the model weights, model config and generation config (Note: tokenizer will not be saved) which can be loaded using HF's from_pretrained method.
|
||||
```python
|
||||
# if use lora, you can choose to merge lora weights before saving
|
||||
if args.lora_rank > 0 and args.merge_lora_weights:
|
||||
from coati.models.lora import LORA_MANAGER
|
||||
|
||||
# NOTE: set model to eval to merge LoRA weights
|
||||
LORA_MANAGER.merge_weights = True
|
||||
model.eval()
|
||||
# save model checkpoint after fitting on only rank0
|
||||
booster.save_model(model, os.path.join(args.save_dir, "modeling"), shard=True)
|
||||
|
||||
```
|
||||
|
||||
- Option 2: Save the model weights, model config, generation config, as well as the optimizer, learning rate scheduler, running states (Note: tokenizer will not be saved) which are needed for resuming training.
|
||||
```python
|
||||
from coati.utils import save_checkpoint
|
||||
# save model checkpoint after fitting on only rank0
|
||||
save_checkpoint(
|
||||
save_dir=actor_save_dir,
|
||||
booster=actor_booster,
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
epoch=0,
|
||||
step=step,
|
||||
batch_size=train_batch_size,
|
||||
coordinator=coordinator,
|
||||
)
|
||||
```
|
||||
To load the saved checkpoint
|
||||
```python
|
||||
from coati.utils import load_checkpoint
|
||||
start_epoch, start_step, sampler_start_idx = load_checkpoint(
|
||||
load_dir=checkpoint_path,
|
||||
booster=booster,
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
)
|
||||
```
|
||||
</details>
|
||||
|
||||
<details><summary><b>How to train with limited resources</b></summary>
|
||||
|
||||
Here are some suggestions that can allow you to train a 7B model on a single or multiple consumer-grade GPUs.
|
||||
|
||||
`batch_size`, `lora_rank` and `grad_checkpoint` are the most important parameters to successfully train the model. To maintain a descent batch size for gradient calculation, consider increase the accumulation_step and reduce the batch_size on each rank.
|
||||
|
||||
If you only have a single 24G GPU. Generally, using lora and "zero2-cpu" will be sufficient.
|
||||
|
||||
`gemini` and `gemini-auto` can enable a single 24G GPU to train the whole model without using LoRA if you have sufficient CPU memory. But that strategy doesn't support gradient accumulation.
|
||||
|
||||
If you have multiple GPUs each has very limited VRAM, say 8GB. You can try the `3d` for the plugin option, which supports tensor parellelism, set `--tp` to the number of GPUs that you have.
|
||||
</details>
|
||||
|
||||
### Real-time progress
|
||||
|
||||
You will find our progress in github [project broad](https://github.com/orgs/hpcaitech/projects/17/views/1).
|
||||
|
||||
## Invitation to open-source contribution
|
||||
|
||||
Referring to the successful attempts of [BLOOM](https://bigscience.huggingface.co/) and [Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion), any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
|
||||
|
||||
You may contact us or participate in the following ways:
|
||||
|
|
@ -532,25 +194,17 @@ Thanks so much to all of our amazing contributors!
|
|||
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
|
||||
- Keep in a sufficiently high running speed
|
||||
|
||||
| Model Pair | Alpaca-7B ⚔ Coati-7B | Coati-7B ⚔ Alpaca-7B |
|
||||
|:-------------:|:--------------------:|:--------------------:|
|
||||
| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
|
||||
| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
|
||||
| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
|
||||
|
||||
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
|
||||
|
||||
## Authors
|
||||
|
||||
Coati is developed by ColossalAI Team:
|
||||
|
||||
- [ver217](https://github.com/ver217) Leading the project while contributing to the main framework.
|
||||
- [ver217](https://github.com/ver217) Leading the project while contributing to the main framework (System Lead).
|
||||
- [Tong Li](https://github.com/TongLi3701) Leading the project while contributing to the main framework (Algorithm Lead).
|
||||
- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored PPO version with updated acceleration framework. Add support for DPO, SimPO, ORPO.
|
||||
- [FrankLeeeee](https://github.com/FrankLeeeee) Providing ML infra support and also taking charge of both front-end and back-end development.
|
||||
- [htzhou](https://github.com/ht-zhou) Contributing to the algorithm and development for RM and PPO training.
|
||||
- [Fazzie](https://fazzie-key.cool/about/index.html) Contributing to the algorithm and development for SFT.
|
||||
- [ofey404](https://github.com/ofey404) Contributing to both front-end and back-end development.
|
||||
- [Wenhao Chen](https://github.com/CWHer) Contributing to subsequent code enhancements and performance improvements.
|
||||
- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored PPO version with updated acceleration framework. Add support for DPO, SimPO, ORPO.
|
||||
|
||||
The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
|
||||
- [Zangwei Zheng](https://github.com/zhengzangw)
|
||||
|
|
@ -559,7 +213,6 @@ The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contribute
|
|||
We also appreciate the valuable suggestions provided by [Jian Hu](https://github.com/hijkzzz) regarding the convergence of the PPO algorithm.
|
||||
|
||||
## Citations
|
||||
|
||||
```bibtex
|
||||
@article{Hu2021LoRALA,
|
||||
title = {LoRA: Low-Rank Adaptation of Large Language Models},
|
||||
|
|
@ -630,8 +283,22 @@ We also appreciate the valuable suggestions provided by [Jian Hu](https://github
|
|||
primaryClass={cs.CL},
|
||||
url={https://arxiv.org/abs/2403.07691},
|
||||
}
|
||||
@misc{shao2024deepseekmathpushinglimitsmathematical,
|
||||
title={DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models},
|
||||
author={Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Xiao Bi and Haowei Zhang and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
|
||||
year={2024},
|
||||
eprint={2402.03300},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CL},
|
||||
url={https://arxiv.org/abs/2402.03300},
|
||||
}
|
||||
@misc{logic-rl,
|
||||
author = {Tian Xie and Qingnan Ren and Yuqian Hong and Zitian Gao and Haoming Luo},
|
||||
title = {Logic-RL},
|
||||
howpublished = {https://github.com/Unakar/Logic-RL},
|
||||
note = {Accessed: 2025-02-03},
|
||||
year = {2025}
|
||||
}
|
||||
```
|
||||
|
||||
## Licenses
|
||||
|
||||
Coati is licensed under the [Apache 2.0 License](LICENSE).
|
||||
|
|
|
|||
|
|
@ -1,26 +0,0 @@
|
|||
import openai
|
||||
from openai.types.chat.chat_completion import ChatCompletion
|
||||
from openai.types.chat.chat_completion_message_param import ChatCompletionMessageParam
|
||||
|
||||
API_KEY = "Dummy API Key"
|
||||
|
||||
|
||||
def get_client(base_url: str | None = None) -> openai.Client:
|
||||
return openai.Client(api_key=API_KEY, base_url=base_url)
|
||||
|
||||
|
||||
def chat_completion(
|
||||
messages: list[ChatCompletionMessageParam],
|
||||
model: str,
|
||||
base_url: str | None = None,
|
||||
temperature: float = 0.8,
|
||||
**kwargs,
|
||||
) -> ChatCompletion:
|
||||
client = get_client(base_url)
|
||||
response = client.chat.completions.create(
|
||||
model=model,
|
||||
messages=messages,
|
||||
temperature=temperature,
|
||||
**kwargs,
|
||||
)
|
||||
return response
|
||||
|
|
@ -1,250 +0,0 @@
|
|||
"""
|
||||
Implementation of MCTS + Self-refine algorithm.
|
||||
|
||||
Reference:
|
||||
1. "Accessing GPT-4 level Mathematical Olympiad Solutions via Monte
|
||||
Carlo Tree Self-refine with LLaMa-3 8B: A Technical Report"
|
||||
2. https://github.com/BrendanGraham14/mcts-llm/
|
||||
3. https://github.com/trotsky1997/MathBlackBox/
|
||||
4. https://github.com/openreasoner/openr/blob/main/reason/guided_search/tree.py
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import math
|
||||
from collections import deque
|
||||
|
||||
import numpy as np
|
||||
import tqdm
|
||||
from coati.reasoner.guided_search.llm import chat_completion
|
||||
from coati.reasoner.guided_search.prompt_store.base import PromptCFG
|
||||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class MCTSNode(BaseModel):
|
||||
"""
|
||||
Node for MCTS.
|
||||
"""
|
||||
|
||||
answer: str
|
||||
parent: MCTSNode = None
|
||||
children: list[MCTSNode] = []
|
||||
num_visits: int = 0
|
||||
Q: int = 0
|
||||
rewards: list[int] = []
|
||||
|
||||
def expand_node(self, node) -> None:
|
||||
self.children.append(node)
|
||||
|
||||
def add_reward(self, reward: int) -> None:
|
||||
self.rewards.append(reward)
|
||||
self.Q = (np.min(self.rewards) + np.mean(self.rewards)) / 2
|
||||
|
||||
|
||||
class MCTS(BaseModel):
|
||||
"""
|
||||
Simulation of MCTS process.
|
||||
"""
|
||||
|
||||
problem: str
|
||||
max_simulations: int
|
||||
cfg: PromptCFG
|
||||
C: float = 1.4
|
||||
max_children: int = 2
|
||||
epsilon: float = 1e-5
|
||||
root: MCTSNode = None
|
||||
|
||||
def initialization(self):
|
||||
"""
|
||||
Root Initiation.
|
||||
"""
|
||||
# Simple answer as root. You can also use negative response such as "I do not know" as a response.
|
||||
base_answer = self.sample_base_answer()
|
||||
self.root = MCTSNode(answer=base_answer)
|
||||
self.self_evaluate(self.root)
|
||||
|
||||
def is_fully_expanded(self, node: MCTSNode):
|
||||
return len(node.children) >= self.max_children or any(child.Q > node.Q for child in node.children)
|
||||
|
||||
def select_node(self) -> MCTSNode:
|
||||
"""
|
||||
Select next node to explore.
|
||||
"""
|
||||
candidates: list[MCTSNode] = []
|
||||
to_explore = deque([self.root])
|
||||
|
||||
while to_explore:
|
||||
current_node = to_explore.popleft()
|
||||
if not self.is_fully_expanded(current_node):
|
||||
candidates.append(current_node)
|
||||
to_explore.extend(current_node.children)
|
||||
|
||||
if not candidates:
|
||||
return self.root
|
||||
|
||||
return max(candidates, key=self.compute_uct)
|
||||
|
||||
def self_evaluate(self, node: MCTSNode):
|
||||
"""
|
||||
Sample reward of the answer.
|
||||
"""
|
||||
reward = self.sample_reward(node)
|
||||
node.add_reward(reward)
|
||||
|
||||
def back_propagation(self, node: MCTSNode):
|
||||
"""
|
||||
Back propagate the value of the refined answer.
|
||||
"""
|
||||
parent = node.parent
|
||||
while parent:
|
||||
best_child_Q = max(child.Q for child in parent.children)
|
||||
parent.Q = (parent.Q + best_child_Q) / 2
|
||||
parent.num_visits += 1
|
||||
parent = parent.parent
|
||||
|
||||
def compute_uct(self, node: MCTSNode):
|
||||
"""
|
||||
Compute UCT.
|
||||
"""
|
||||
if node.parent is None:
|
||||
return -100
|
||||
return node.Q + self.C * math.sqrt(math.log(node.parent.num_visits + 1) / (node.num_visits + self.epsilon))
|
||||
|
||||
def simulate(self):
|
||||
self.initialization()
|
||||
for _ in tqdm.tqdm(range(self.max_simulations)):
|
||||
node = self.select_node()
|
||||
child = self.self_refine(node)
|
||||
node.expand_node(child)
|
||||
self.self_evaluate(child)
|
||||
self.back_propagation(child)
|
||||
|
||||
return self.get_best_answer()
|
||||
|
||||
def get_best_answer(self):
|
||||
to_visit = deque([self.root])
|
||||
best_node = self.root
|
||||
|
||||
while to_visit:
|
||||
current_node = to_visit.popleft()
|
||||
if current_node.Q > best_node.Q:
|
||||
best_node = current_node
|
||||
to_visit.extend(current_node.children)
|
||||
|
||||
return best_node.answer
|
||||
|
||||
def self_refine(self, node: MCTSNode):
|
||||
"""
|
||||
Refine node.
|
||||
"""
|
||||
critique_response = chat_completion(
|
||||
messages=[
|
||||
{
|
||||
"role": "system",
|
||||
"content": self.cfg.critic_system_prompt,
|
||||
},
|
||||
{
|
||||
"role": "user",
|
||||
"content": "\n\n".join(
|
||||
[
|
||||
f"<problem>\n{self.problem}\n</problem>",
|
||||
f"<current_answer>\n{node.answer}\n</current_answer>",
|
||||
]
|
||||
),
|
||||
},
|
||||
],
|
||||
model=self.cfg.model,
|
||||
base_url=self.cfg.base_url,
|
||||
max_tokens=self.cfg.max_tokens,
|
||||
)
|
||||
critique = critique_response.choices[0].message.content
|
||||
assert critique is not None
|
||||
refined_answer_response = chat_completion(
|
||||
messages=[
|
||||
{
|
||||
"role": "system",
|
||||
"content": self.cfg.refine_system_prompt,
|
||||
},
|
||||
{
|
||||
"role": "user",
|
||||
"content": "\n\n".join(
|
||||
[
|
||||
f"<problem>\n{self.problem}\n</problem>",
|
||||
f"<current_answer>\n{node.answer}\n</current_answer>",
|
||||
f"<critique>\n{critique}\n</critique>",
|
||||
]
|
||||
),
|
||||
},
|
||||
],
|
||||
model=self.cfg.model,
|
||||
base_url=self.cfg.base_url,
|
||||
max_tokens=self.cfg.max_tokens,
|
||||
)
|
||||
refined_answer = refined_answer_response.choices[0].message.content
|
||||
assert refined_answer is not None
|
||||
|
||||
return MCTSNode(answer=refined_answer, parent=node)
|
||||
|
||||
def sample_base_answer(self):
|
||||
response = chat_completion(
|
||||
messages=[
|
||||
{
|
||||
"role": "system",
|
||||
"content": self.cfg.base_system_prompt,
|
||||
},
|
||||
{
|
||||
"role": "user",
|
||||
"content": f"<problem>\n {self.problem} \n</problem> \nLet's think step by step",
|
||||
},
|
||||
],
|
||||
model=self.cfg.model,
|
||||
base_url=self.cfg.base_url,
|
||||
max_tokens=self.cfg.max_tokens,
|
||||
)
|
||||
assert response.choices[0].message.content is not None
|
||||
return response.choices[0].message.content
|
||||
|
||||
def sample_reward(self, node: MCTSNode):
|
||||
"""
|
||||
Calculate reward.
|
||||
"""
|
||||
messages = [
|
||||
{
|
||||
"role": "system",
|
||||
"content": self.cfg.evaluate_system_prompt,
|
||||
},
|
||||
{
|
||||
"role": "user",
|
||||
"content": "\n\n".join(
|
||||
[
|
||||
f"<problem>\n{self.problem}\n</problem>",
|
||||
f"<answer>\n{node.answer}\n</answer>",
|
||||
]
|
||||
),
|
||||
},
|
||||
]
|
||||
for attempt in range(3):
|
||||
try:
|
||||
response = chat_completion(
|
||||
messages=messages,
|
||||
model=self.cfg.model,
|
||||
base_url=self.cfg.base_url,
|
||||
max_tokens=self.cfg.max_tokens,
|
||||
)
|
||||
assert response.choices[0].message.content is not None
|
||||
return int(response.choices[0].message.content)
|
||||
except ValueError:
|
||||
messages.extend(
|
||||
[
|
||||
{
|
||||
"role": "assistant",
|
||||
"content": response.choices[0].message.content,
|
||||
},
|
||||
{
|
||||
"role": "user",
|
||||
"content": "Failed to parse reward as an integer.",
|
||||
},
|
||||
]
|
||||
)
|
||||
if attempt == 2:
|
||||
raise
|
||||
|
|
@ -1,11 +0,0 @@
|
|||
from pydantic import BaseModel
|
||||
|
||||
|
||||
class PromptCFG(BaseModel):
|
||||
model: str
|
||||
base_url: str
|
||||
max_tokens: int = 4096
|
||||
base_system_prompt: str
|
||||
critic_system_prompt: str
|
||||
refine_system_prompt: str
|
||||
evaluate_system_prompt: str
|
||||
|
|
@ -1,22 +0,0 @@
|
|||
"""
|
||||
Prompts for Qwen Series.
|
||||
"""
|
||||
|
||||
from coati.reasoner.guided_search.prompt_store.base import PromptCFG
|
||||
|
||||
Qwen32B_prompt_CFG = PromptCFG(
|
||||
base_url="http://0.0.0.0:8008/v1",
|
||||
model="Qwen2.5-32B-Instruct",
|
||||
base_system_prompt="The user will present a problem. Analyze and solve the problem in the following structure:\n"
|
||||
"Begin with [Reasoning Process] to explain the approach. \n Proceed with [Verification] to confirm the solution. \n Conclude with [Final Answer] in the format: 'Answer: [answer]'",
|
||||
critic_system_prompt="Provide a detailed and constructive critique of the answer, focusing on ways to improve its clarity, accuracy, and relevance."
|
||||
"Highlight specific areas that need refinement or correction, and offer concrete suggestions for enhancing the overall quality and effectiveness of the response.",
|
||||
refine_system_prompt="""# Instruction
|
||||
Refine the answer based on the critique. The response should begin with [reasoning process]...[Verification]... and end with [Final Answer].
|
||||
""",
|
||||
evaluate_system_prompt=(
|
||||
"Critically analyze this answer and provide a reward score between -100 and 100 based on strict standards."
|
||||
"The score should clearly reflect the quality of the answer."
|
||||
"Make sure the reward score is an integer. You should only return the score. If the score is greater than 95, return 95."
|
||||
),
|
||||
)
|
||||
|
|
@ -2,8 +2,6 @@
|
|||
|
||||
|
||||
## Table of Contents
|
||||
|
||||
|
||||
- [Examples](#examples)
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [Install Requirements](#install-requirements)
|
||||
|
|
@ -27,14 +25,14 @@
|
|||
- [Reward](#reward)
|
||||
- [KL Divergence](#approximate-kl-divergence)
|
||||
- [Note on PPO Training](#note-on-ppo-training)
|
||||
- [GRPO Training and DeepSeek R1 reproduction]
|
||||
- [GRPO Training and DeepSeek R1 reproduction](#grpo-training-and-deepseek-r1-reproduction)
|
||||
- [Alternative Option For RLHF: Direct Preference Optimization](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||
- [DPO Stage 1: Supervised Instruction Tuning](#dpo-training-stage1---supervised-instructs-tuning)
|
||||
- [DPO Stage 2: DPO Training](#dpo-training-stage2---dpo-training)
|
||||
- [Alternative Option For RLHF: Simple Preference Optimization](#alternative-option-for-rlhf-simple-preference-optimization)
|
||||
- [Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||
- [Alternative Option For RLHF: Odds Ratio Preference Optimization](#alternative-option-for-rlhf-odds-ratio-preference-optimization)
|
||||
- [List of Supported Models](#list-of-supported-models)
|
||||
- [SFT for DeepSeek V3](#sft-for-deepseek-v3)
|
||||
- [Hardware Requirements](#hardware-requirements)
|
||||
- [Inference example](#inference-example)
|
||||
- [Attention](#attention)
|
||||
|
|
@ -729,6 +727,8 @@ Answer: Yes, this happens and is well documented by other implementations. After
|
|||
## GRPO Training and DeepSeek R1 reproduction
|
||||
We support GRPO (Group Relative Policy Optimization), which is the reinforcement learning algorithm used in DeepSeek R1 paper. In this section, we will walk through GRPO training with an example trying to reproduce Deepseek R1's results in mathematical problem solving.
|
||||
|
||||
**Note: Currently, our PPO and GRPO pipelines are still under extensive development (integration with Ray and the inference engine). The speed is primarily limited by the rollout process, as we are using a naive generation approach without any acceleration. This experiment is focused solely on verifying the correctness of the GRPO algorithm. We will open-source the new version of code as soon as possible, so please stay tuned.**
|
||||
|
||||
### GRPO Model Selection
|
||||
We finally select the base version of [Qwen2.5-3B](https://huggingface.co/Qwen/Qwen2.5-3B). We also did experiments on the instruct version [Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) but the later one fails to explore more diversed output. We recommend to use base models (without SFT) and use a few SFT steps (see [SFT section](#rlhf-training-stage1---supervised-instructs-tuning)) to correct the base model's output format before GRPO.
|
||||
|
||||
|
|
@ -773,32 +773,20 @@ experience buffer size
|
|||
During roll out, we perform rebatching to prevent out of memory both before roll out and before calculating logits. Please choose a proper setting for the "inference_batch_size" and the "logits_forward_batch_size" based on your device.
|
||||
|
||||
### GRPO Result
|
||||
#### Reward
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/reward.png">
|
||||
</p>
|
||||
#### Reward and Response Length
|
||||
<div style="display: flex; justify-content: space-between;">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/reward.png" style="width: 48%;" />
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/token_cost.png" style="width: 48%;" />
|
||||
</div>
|
||||
|
||||
#### Response Length
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/token_cost.png">
|
||||
</p>
|
||||
#### Response Length Distribution (After Training) and Sample response
|
||||
<div style="display: flex; justify-content: space-between;">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/token_cost_eval.png" style="width: 48%;" />
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/sample.png" style="width: 48%;" />
|
||||
</div>
|
||||
|
||||
#### Response Length Distribution (After Training)
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/token_cost_eval.png">
|
||||
</p>
|
||||
|
||||
#### Sample Response
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/grpo/res.png">
|
||||
</p>
|
||||
|
||||
#### Note of Speed
|
||||
Currently, our PPO and GRPO pipeline are still under development. The speed is largely limited by the roll out speed as we use naive generation without any acceleration.
|
||||
|
||||
## Alternative Option For RLHF: Direct Preference Optimization
|
||||
|
||||
|
||||
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in the paper (available at [https://arxiv.org/abs/2305.18290](https://arxiv.org/abs/2305.18290)), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO.
|
||||
|
||||
|
||||
|
|
@ -884,8 +872,38 @@ For training, use the [train_kto.sh](./examples/training_scripts/train_orpo.sh)
|
|||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/KTO.png">
|
||||
</p>
|
||||
|
||||
## Hardware Requirements
|
||||
|
||||
### SFT for DeepSeek V3
|
||||
We add a script to supervised-fintune the DeepSeek V3/R1 model with LoRA. The script is located in `examples/training_scripts/lora_fintune.py`. The script is similar to the SFT script for Coati7B, but with a few differences. This script is compatible with Peft.
|
||||
|
||||
#### Dataset preparation
|
||||
|
||||
This script receives JSONL format file as input dataset. Each line of dataset should be a list of chat dialogues. E.g.
|
||||
```json
|
||||
[{"role": "user", "content": "Hello, how are you?"}, {"role": "assistant", "content": "I'm doing great. How can I help you today?"}]
|
||||
```
|
||||
```json
|
||||
[{"role": "user", "content": "火烧赤壁 曹操为何不拨打119求救?"}, {"role": "assistant", "content": "因为在三国时期,还没有电话和现代的消防系统,所以曹操无法拨打119求救。"}]
|
||||
```
|
||||
|
||||
The dialogues can by multiple turns and it can contain system prompt. For more details, see the [chat_templating](https://huggingface.co/docs/transformers/main/chat_templating).
|
||||
|
||||
#### Model weights preparation
|
||||
|
||||
We use bf16 weights for finetuning. If you downloaded fp8 DeepSeek V3/R1 weights, you can use the [script](https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/fp8_cast_bf16.py) to convert the weights to bf16 via GPU. For Ascend NPU, you can use this [script](https://gitee.com/ascend/ModelZoo-PyTorch/blob/master/MindIE/LLM/DeepSeek/DeepSeek-V2/NPU_inference/fp8_cast_bf16.py).
|
||||
|
||||
#### Usage
|
||||
|
||||
After preparing the dataset and model weights, you can run the script with the following command:
|
||||
```bash
|
||||
colossalai run --hostfile path-to-host-file --nproc_per_node 8 lora_finetune.py --pretrained path-to-DeepSeek-R1-bf16 --dataset path-to-dataset.jsonl --plugin moe --lr 2e-5 --max_length 256 -g --ep 8 --pp 3 --batch_size 24 --lora_rank 8 --lora_alpha 16 --num_epochs 2 --warmup_steps 8 --tensorboard_dir logs --save_dir DeepSeek-R1-bf16-lora
|
||||
```
|
||||
|
||||
For more details of each argument, you can run `python lora_finetune.py --help`.
|
||||
|
||||
The sample command does not use CPU offload to get better throughput. The minimum hardware requirement for sample command is 32 ascend 910B NPUs (with `ep=8,pp=4`) or 24 H100/H800 GPUs (with `ep=8,pp=3`). If you enable CPU offload by `--zero_cpu_offload`, the hardware requirement can be further reduced.
|
||||
|
||||
## Hardware Requirements
|
||||
For SFT, we recommend using zero2 or zero2-cpu for 7B model and tp is your model is extra large. We tested the VRAM consumption on a dummy dataset with a sequence length of 2048. In all experiments, we use H800 GPUs with 80GB VRAM and enable gradient checkpointing and flash attention.
|
||||
- 2 H800 GPU
|
||||
- zero2-cpu, micro batch size=4, VRAM Usage=22457.98 MB
|
||||
|
|
@ -942,35 +960,9 @@ For KTO, we recommend using zero2-cpu or zero2 plugin, We tested the VRAM consum
|
|||
- zero2_cpu, micro batch size=2, VRAM_USAGE=32443.22 MB
|
||||
- zero2, micro batch size=4, VRAM_USAGE=59307.97 MB
|
||||
|
||||
## List of Supported Models
|
||||
|
||||
For SFT, we support the following models/series:
|
||||
- Colossal-LLaMA-2
|
||||
- ChatGLM2
|
||||
- ChatGLM3 (only with zero2, zero2_cpu plugin)
|
||||
- Baichuan2
|
||||
- LLaMA2
|
||||
- Qwen1.5-7B-Chat (with transformers==4.39.1)
|
||||
- Yi-1.5
|
||||
|
||||
For PPO and DPO, we theoratically support the following models/series (without guarantee):
|
||||
- Colossal-LLaMA-2 (tested)
|
||||
- ChatGLM2
|
||||
- Baichuan2
|
||||
- LLaMA2 (tested)
|
||||
- Qwen1.5-7B-Chat (with transformers==4.39.1)
|
||||
- Yi-1.5
|
||||
|
||||
*-* The zero2, zero2_cpu plugin also support a wide range of chat models not listed above.
|
||||
|
||||
## Inference example
|
||||
|
||||
|
||||
We support different inference options, including int8 and int4 quantization.
|
||||
For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
||||
|
||||
|
||||
## Attention
|
||||
|
||||
|
||||
The examples are demos for the whole training process. You need to change the hyper-parameters to reach great performance.
|
||||
|
|
|
|||
|
|
@ -1,181 +0,0 @@
|
|||
import argparse
|
||||
import os
|
||||
import socket
|
||||
from functools import partial
|
||||
|
||||
import pandas as pd
|
||||
import ray
|
||||
from coati.quant import llama_load_quant, low_resource_init
|
||||
from coati.ray.detached_trainer_ppo import DetachedPPOTrainer
|
||||
from coati.ray.experience_maker_holder import ExperienceMakerHolder
|
||||
from coati.ray.utils import (
|
||||
get_actor_from_args,
|
||||
get_critic_from_args,
|
||||
get_reward_model_from_args,
|
||||
get_strategy_from_args,
|
||||
get_tokenizer_from_args,
|
||||
)
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoConfig
|
||||
from transformers.modeling_utils import no_init_weights
|
||||
|
||||
|
||||
def get_free_port():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
|
||||
s.bind(("", 0))
|
||||
return s.getsockname()[1]
|
||||
|
||||
|
||||
def get_local_ip():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
|
||||
s.connect(("8.8.8.8", 80))
|
||||
return s.getsockname()[0]
|
||||
|
||||
|
||||
def main(args):
|
||||
master_addr = str(get_local_ip())
|
||||
# trainer_env_info
|
||||
trainer_port = str(get_free_port())
|
||||
env_info_trainers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_trainers),
|
||||
"master_port": trainer_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_trainers)
|
||||
]
|
||||
|
||||
# maker_env_info
|
||||
maker_port = str(get_free_port())
|
||||
env_info_maker = {
|
||||
"local_rank": "0",
|
||||
"rank": "0",
|
||||
"world_size": "1",
|
||||
"master_port": maker_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer = get_tokenizer_from_args(args.model)
|
||||
|
||||
def trainer_model_fn():
|
||||
actor = get_actor_from_args(args.model, args.pretrain).half().cuda()
|
||||
critic = get_critic_from_args(args.model, args.critic_pretrain).half().cuda()
|
||||
return actor, critic
|
||||
|
||||
# configure Trainer
|
||||
trainer_refs = [
|
||||
DetachedPPOTrainer.options(name=f"trainer{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
experience_maker_holder_name_list=["maker1"],
|
||||
strategy_fn=partial(get_strategy_from_args, args.trainer_strategy),
|
||||
model_fn=trainer_model_fn,
|
||||
env_info=env_info_trainer,
|
||||
train_batch_size=args.train_batch_size,
|
||||
buffer_limit=16,
|
||||
eval_performance=True,
|
||||
debug=args.debug,
|
||||
update_lora_weights=not (args.lora_rank == 0),
|
||||
)
|
||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
||||
]
|
||||
|
||||
def model_fn():
|
||||
actor = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
||||
critic = get_critic_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
||||
reward_model = get_reward_model_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
||||
if args.initial_model_quant_ckpt is not None and args.model == "llama":
|
||||
# quantize initial model
|
||||
actor_cfg = AutoConfig.from_pretrained(args.pretrain)
|
||||
with low_resource_init(), no_init_weights():
|
||||
initial_model = get_actor_from_args(args.model, config=actor_cfg)
|
||||
initial_model.model = (
|
||||
llama_load_quant(
|
||||
initial_model.model, args.initial_model_quant_ckpt, args.quant_bits, args.quant_group_size
|
||||
)
|
||||
.cuda()
|
||||
.requires_grad_(False)
|
||||
)
|
||||
else:
|
||||
initial_model = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
||||
return actor, critic, reward_model, initial_model
|
||||
|
||||
# configure Experience Maker
|
||||
experience_holder_ref = ExperienceMakerHolder.options(name="maker1", num_gpus=1, max_concurrency=2).remote(
|
||||
detached_trainer_name_list=[f"trainer{i}" for i in range(args.num_trainers)],
|
||||
strategy_fn=partial(get_strategy_from_args, args.maker_strategy),
|
||||
model_fn=model_fn,
|
||||
env_info=env_info_maker,
|
||||
experience_batch_size=args.experience_batch_size,
|
||||
kl_coef=0.1,
|
||||
debug=args.debug,
|
||||
update_lora_weights=not (args.lora_rank == 0),
|
||||
# sync_models_from_trainers=True,
|
||||
# generation kwargs:
|
||||
max_length=512,
|
||||
do_sample=True,
|
||||
temperature=1.0,
|
||||
top_k=50,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
eval_performance=True,
|
||||
use_cache=True,
|
||||
)
|
||||
|
||||
# uncomment this function if sync_models_from_trainers is True
|
||||
# ray.get([
|
||||
# trainer_ref.sync_models_to_remote_makers.remote()
|
||||
# for trainer_ref in trainer_refs
|
||||
# ])
|
||||
|
||||
wait_tasks = []
|
||||
|
||||
total_steps = args.experience_batch_size * args.experience_steps // (args.num_trainers * args.train_batch_size)
|
||||
for trainer_ref in trainer_refs:
|
||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, args.update_steps, args.train_epochs))
|
||||
|
||||
dataset_size = args.experience_batch_size * 4
|
||||
|
||||
def build_dataloader():
|
||||
def tokenize_fn(texts):
|
||||
batch = tokenizer(texts, return_tensors="pt", max_length=96, padding="max_length", truncation=True)
|
||||
return {k: v.cuda() for k, v in batch.items()}
|
||||
|
||||
dataset = pd.read_csv(args.prompt_path)["prompt"]
|
||||
dataloader = DataLoader(dataset=dataset, batch_size=dataset_size, shuffle=True, collate_fn=tokenize_fn)
|
||||
return dataloader
|
||||
|
||||
wait_tasks.append(experience_holder_ref.workingloop.remote(build_dataloader, num_steps=args.experience_steps))
|
||||
|
||||
ray.get(wait_tasks)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--prompt_path", type=str, default=None)
|
||||
parser.add_argument("--num_trainers", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--trainer_strategy",
|
||||
choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_gemini_cpu", "colossalai_zero2_cpu"],
|
||||
default="ddp",
|
||||
)
|
||||
parser.add_argument("--maker_strategy", choices=["naive"], default="naive")
|
||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--critic_model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--critic_pretrain", type=str, default=None)
|
||||
parser.add_argument("--experience_steps", type=int, default=4)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
||||
parser.add_argument("--train_epochs", type=int, default=1)
|
||||
parser.add_argument("--update_steps", type=int, default=2)
|
||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
|
||||
parser.add_argument("--initial_model_quant_ckpt", type=str, default=None)
|
||||
parser.add_argument("--quant_bits", type=int, default=4)
|
||||
parser.add_argument("--quant_group_size", type=int, default=128)
|
||||
parser.add_argument("--debug", action="store_true")
|
||||
args = parser.parse_args()
|
||||
ray.init(namespace=os.environ["RAY_NAMESPACE"], runtime_env={"env_vars": dict(os.environ)})
|
||||
main(args)
|
||||
|
|
@ -1,201 +0,0 @@
|
|||
import argparse
|
||||
import os
|
||||
import socket
|
||||
from functools import partial
|
||||
|
||||
import pandas as pd
|
||||
import ray
|
||||
from coati.quant import llama_load_quant, low_resource_init
|
||||
from coati.ray.detached_trainer_ppo import DetachedPPOTrainer
|
||||
from coati.ray.experience_maker_holder import ExperienceMakerHolder
|
||||
from coati.ray.utils import (
|
||||
get_actor_from_args,
|
||||
get_critic_from_args,
|
||||
get_receivers_per_sender,
|
||||
get_reward_model_from_args,
|
||||
get_strategy_from_args,
|
||||
)
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoConfig, AutoTokenizer
|
||||
from transformers.modeling_utils import no_init_weights
|
||||
|
||||
|
||||
def get_free_port():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
|
||||
s.bind(("", 0))
|
||||
return s.getsockname()[1]
|
||||
|
||||
|
||||
def get_local_ip():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
|
||||
s.connect(("8.8.8.8", 80))
|
||||
return s.getsockname()[0]
|
||||
|
||||
|
||||
def main(args):
|
||||
master_addr = str(get_local_ip())
|
||||
# trainer_env_info
|
||||
trainer_port = str(get_free_port())
|
||||
env_info_trainers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_trainers),
|
||||
"master_port": trainer_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_trainers)
|
||||
]
|
||||
|
||||
# maker_env_info
|
||||
maker_port = str(get_free_port())
|
||||
env_info_makers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_makers),
|
||||
"master_port": maker_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_makers)
|
||||
]
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.pretrain)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
def model_fn():
|
||||
actor = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
||||
critic = get_critic_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
||||
reward_model = get_reward_model_from_args(args.model, args.critic_pretrain).requires_grad_(False).half().cuda()
|
||||
if args.initial_model_quant_ckpt is not None and args.model == "llama":
|
||||
# quantize initial model
|
||||
actor_cfg = AutoConfig.from_pretrained(args.pretrain)
|
||||
with low_resource_init(), no_init_weights():
|
||||
initial_model = get_actor_from_args(args.model, config=actor_cfg)
|
||||
initial_model.model = (
|
||||
llama_load_quant(
|
||||
initial_model.model, args.initial_model_quant_ckpt, args.quant_bits, args.quant_group_size
|
||||
)
|
||||
.cuda()
|
||||
.requires_grad_(False)
|
||||
)
|
||||
else:
|
||||
initial_model = get_actor_from_args(args.model, args.pretrain).requires_grad_(False).half().cuda()
|
||||
return actor, critic, reward_model, initial_model
|
||||
|
||||
# configure Experience Maker
|
||||
experience_holder_refs = [
|
||||
ExperienceMakerHolder.options(name=f"maker{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
detached_trainer_name_list=[
|
||||
f"trainer{x}"
|
||||
for x in get_receivers_per_sender(i, args.num_makers, args.num_trainers, allow_idle_sender=False)
|
||||
],
|
||||
strategy_fn=partial(get_strategy_from_args, args.maker_strategy),
|
||||
model_fn=model_fn,
|
||||
env_info=env_info_maker,
|
||||
kl_coef=0.1,
|
||||
debug=args.debug,
|
||||
update_lora_weights=not (args.lora_rank == 0),
|
||||
# sync_models_from_trainers=True,
|
||||
# generation kwargs:
|
||||
max_length=512,
|
||||
do_sample=True,
|
||||
temperature=1.0,
|
||||
top_k=50,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
eval_performance=True,
|
||||
use_cache=True,
|
||||
)
|
||||
for i, env_info_maker in enumerate(env_info_makers)
|
||||
]
|
||||
|
||||
def trainer_model_fn():
|
||||
actor = get_actor_from_args(args.model, args.pretrain, lora_rank=args.lora_rank).half().cuda()
|
||||
critic = get_critic_from_args(args.model, args.critic_pretrain, lora_rank=args.lora_rank).half().cuda()
|
||||
return actor, critic
|
||||
|
||||
# configure Trainer
|
||||
trainer_refs = [
|
||||
DetachedPPOTrainer.options(name=f"trainer{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
experience_maker_holder_name_list=[
|
||||
f"maker{x}"
|
||||
for x in get_receivers_per_sender(i, args.num_trainers, args.num_makers, allow_idle_sender=True)
|
||||
],
|
||||
strategy_fn=partial(get_strategy_from_args, args.trainer_strategy),
|
||||
model_fn=trainer_model_fn,
|
||||
env_info=env_info_trainer,
|
||||
train_batch_size=args.train_batch_size,
|
||||
buffer_limit=16,
|
||||
eval_performance=True,
|
||||
debug=args.debug,
|
||||
update_lora_weights=not (args.lora_rank == 0),
|
||||
)
|
||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
||||
]
|
||||
|
||||
dataset_size = args.experience_batch_size * 4
|
||||
|
||||
def build_dataloader():
|
||||
def tokenize_fn(texts):
|
||||
batch = tokenizer(texts, return_tensors="pt", max_length=96, padding="max_length", truncation=True)
|
||||
return {k: v.cuda() for k, v in batch.items()}
|
||||
|
||||
dataset = pd.read_csv(args.prompt_path)["prompt"]
|
||||
dataloader = DataLoader(dataset=dataset, batch_size=dataset_size, shuffle=True, collate_fn=tokenize_fn)
|
||||
return dataloader
|
||||
|
||||
# uncomment this function if sync_models_from_trainers is True
|
||||
# ray.get([
|
||||
# trainer_ref.sync_models_to_remote_makers.remote()
|
||||
# for trainer_ref in trainer_refs
|
||||
# ])
|
||||
|
||||
wait_tasks = []
|
||||
|
||||
for experience_holder_ref in experience_holder_refs:
|
||||
wait_tasks.append(experience_holder_ref.workingloop.remote(build_dataloader, num_steps=args.experience_steps))
|
||||
|
||||
total_steps = (
|
||||
args.experience_batch_size
|
||||
* args.experience_steps
|
||||
* args.num_makers
|
||||
// (args.num_trainers * args.train_batch_size)
|
||||
)
|
||||
for trainer_ref in trainer_refs:
|
||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, args.update_steps, args.train_epochs))
|
||||
|
||||
ray.get(wait_tasks)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--prompt_path", type=str, default=None)
|
||||
parser.add_argument("--num_makers", type=int, default=1)
|
||||
parser.add_argument("--num_trainers", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--trainer_strategy",
|
||||
choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_gemini_cpu", "colossalai_zero2_cpu"],
|
||||
default="ddp",
|
||||
)
|
||||
parser.add_argument("--maker_strategy", choices=["naive"], default="naive")
|
||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--critic_model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--critic_pretrain", type=str, default=None)
|
||||
parser.add_argument("--experience_steps", type=int, default=4)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
||||
parser.add_argument("--train_epochs", type=int, default=1)
|
||||
parser.add_argument("--update_steps", type=int, default=2)
|
||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
|
||||
parser.add_argument("--initial_model_quant_ckpt", type=str, default=None)
|
||||
parser.add_argument("--quant_bits", type=int, default=4)
|
||||
parser.add_argument("--quant_group_size", type=int, default=128)
|
||||
parser.add_argument("--debug", action="store_true")
|
||||
args = parser.parse_args()
|
||||
|
||||
ray.init(namespace=os.environ["RAY_NAMESPACE"], runtime_env={"env_vars": dict(os.environ)})
|
||||
main(args)
|
||||
|
|
@ -1 +0,0 @@
|
|||
ray
|
||||
|
|
@ -1,12 +0,0 @@
|
|||
#!/bin/bash
|
||||
|
||||
set -xe
|
||||
BASE=$(realpath $(dirname $0))
|
||||
|
||||
export RAY_NAMESPACE=admin
|
||||
export DATA=/data/scratch/chatgpt/prompts.csv
|
||||
|
||||
# install requirements
|
||||
pip install -r ${BASE}/requirements.txt
|
||||
|
||||
python ${BASE}/mmmt_prompt.py --prompt_path $DATA --num_makers 2 --num_trainers 2 --trainer_strategy colossalai_gemini --model opt --critic_model opt --pretrain facebook/opt-350m --critic_pretrain facebook/opt-125m --experience_batch_size 4 --train_batch_size 2
|
||||
Loading…
Reference in New Issue